某易跟帖频道,接口溯源分析,反爬新技巧,必掌握一下
Posted 梦想橡皮擦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了某易跟帖频道,接口溯源分析,反爬新技巧,必掌握一下相关的知识,希望对你有一定的参考价值。
📢📢📢📢📢📢
💗 你正在阅读 【梦想橡皮擦】 的博客
👍 阅读完毕,可以点点小手赞一下
🌻 发现错误,直接评论区中指正吧
📆 橡皮擦的第 621 篇原创博客
畅销专栏,打折促销中~
文章目录
⛳️ 实战场景
本篇博客的目标站点跟网易有关,以下是详细的描述信息。
- 目标站点:https%3A%2F%2Fcomment.tie.163.com%2FH5GDH6RA0552DNJF.html;
- 站点名称:\\u7f51\\u6613\\u8ddf\\u5e16
本次抓取的前提是假设你可以采集到列表页数据,列表页如下所示:
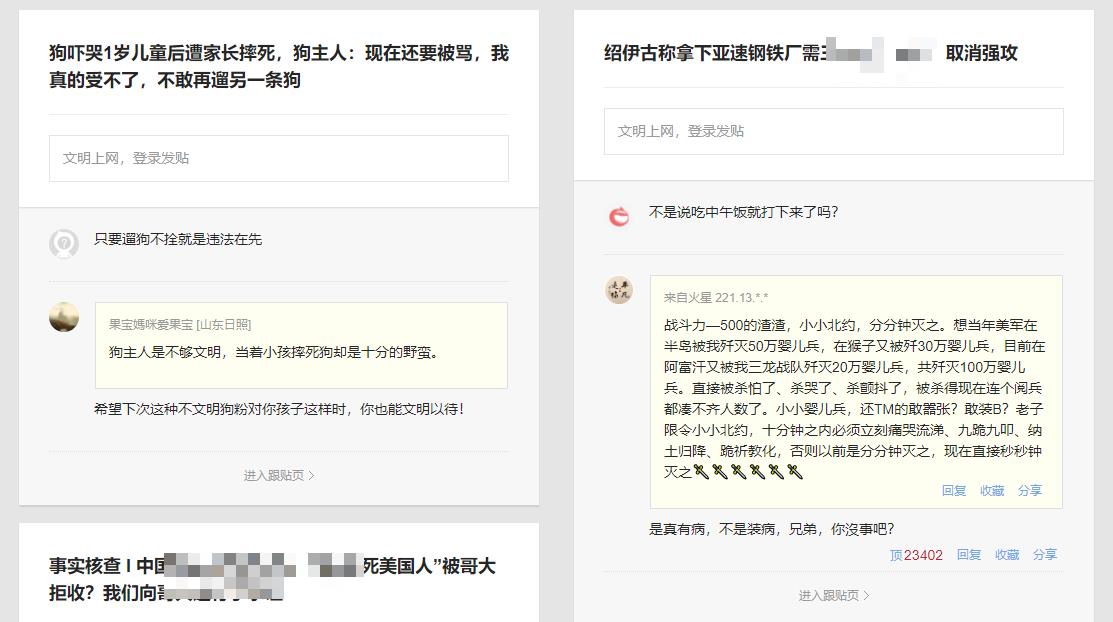
点击任意热帖,进入评论页,通过开发者工具捕获到如下信息。
- 请求地址:
https://Python脱敏处理163.com/api/v1/products/a2869674571f77b5a0867c3d71db5856/threads/H5GDH6RA0552DNJF/comments/newList?ibc=newspc&limit=30&showLevelThreshold=72&headLimit=1&tailLimit=2&offset=90&callback=jsonp_1650620067890&_=1650620067891 - 请求方式:GET
使用浏览器直接访问接口,可以获取到数据,但是其中涉及两个值需要进行分析,分别如下所示:
a2869674571f77b5a0867c3d71db5856:一个 md5 加密之后的值,被加密参数未知;H5GDH6RA0552DNJF:含义未知。
编写简单的请求代码,查看代码中是否有时间相关的密处理。
import requests
res = requests.get('https://Python脱敏处理163.com/api/v1/products/a2869674571f77b5a0867c3d71db5856/threads/H5GDH6RA0552DNJF/comments/newList?ibc=newspc&limit=30&showLevelThreshold=72&headLimit=1&tailLimit=2&offset=30&callback=jsonp_1650621196302&_=1650621196303')
print(res.text)
数据直接返回了,看起来用不到复杂的解密技巧了,其中相关参数我们都能直接获取。
下面我们还是要找一下上文提及的两个参数,到底是如何计算得来的。
⛳️ 参数解密
由于该请求是 GET 请求,所以无法添加 XHR 断点,本篇博客学习一个新的断点添加方式。
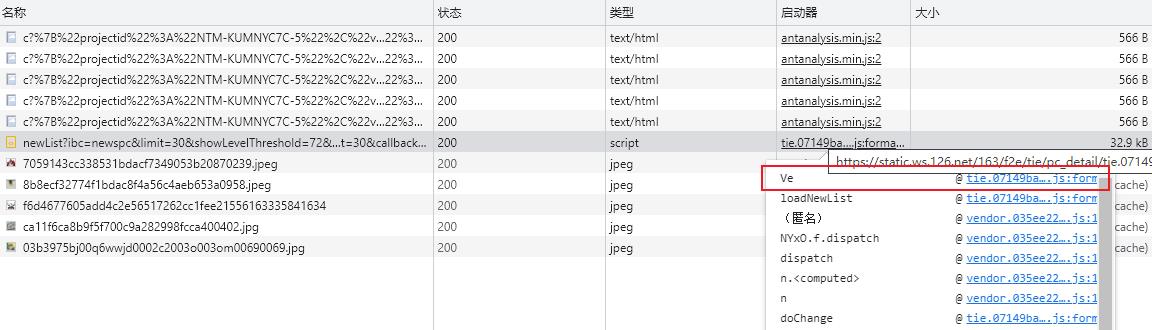
鼠标移动到启动器上,直接点击 JS 文件,跳转到指定位置,添加断点,然后刷新页面即可。
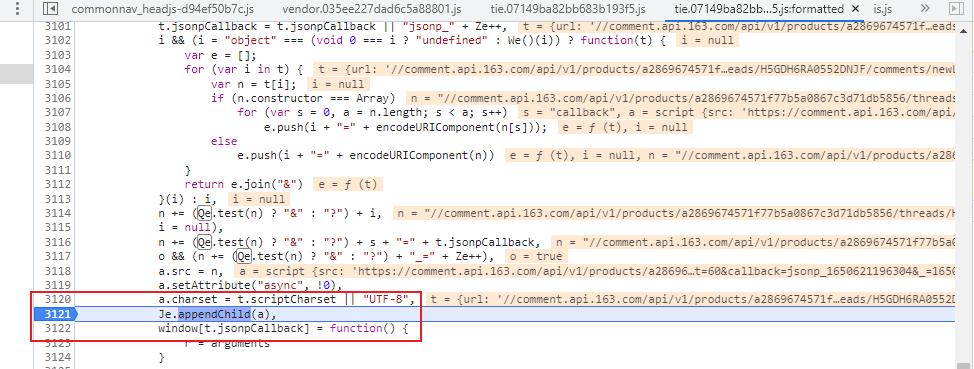
上图中的断点是随意添加的,学习过程中你可以根据情况设置。
接下来查看调用堆栈,在函数头部显示请求链接已经生成,断点前移,重新刷新页面。

通过上图可以看到,t.url 已经存在数据,所以该变量的赋值操作还要靠前。
在堆栈中点击相关操作,可以看到 url 生成的位置如下所示。
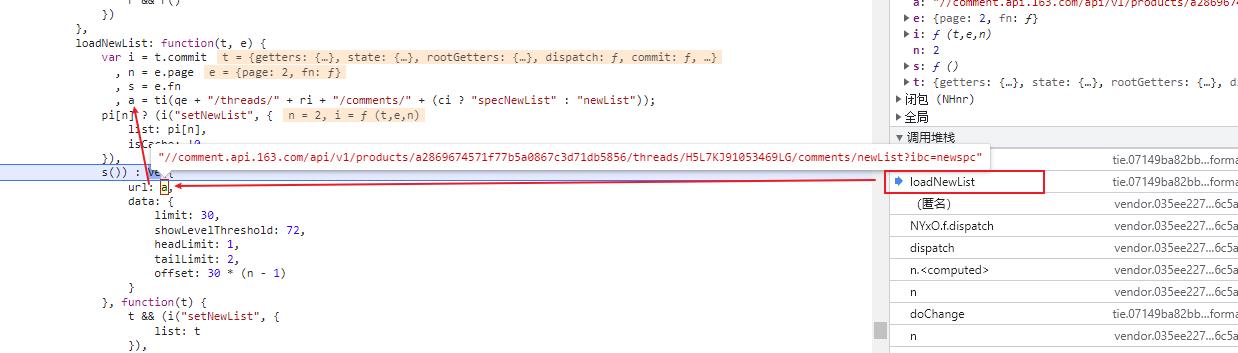
在变量 a 的位置添加新的断点,预期是进入 ti() 函数。
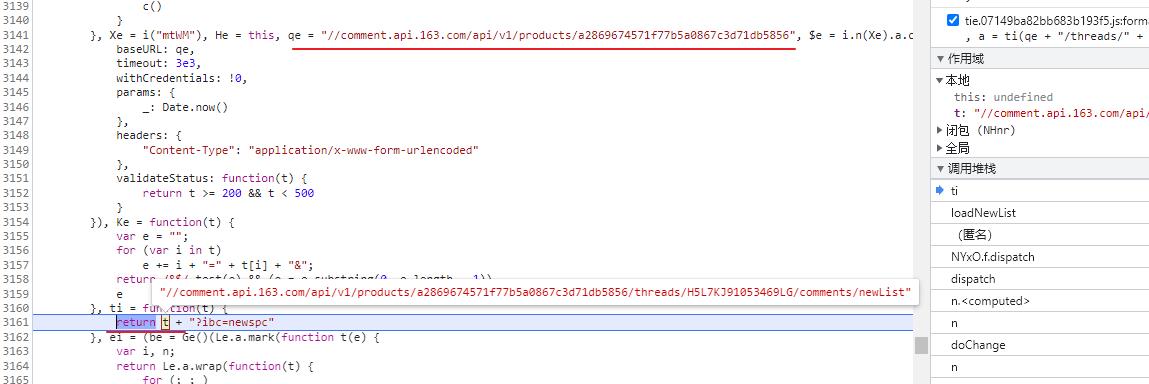
最终的结果出现了,在 ti() 函数上面发现了变量 qe 的赋值,这里竟然写死了请求地址,实在有点出乎意料。
这时就剩下唯一的加密变量 ri 还未处理,向上查找该值的复制位置,最终发现如下所示:
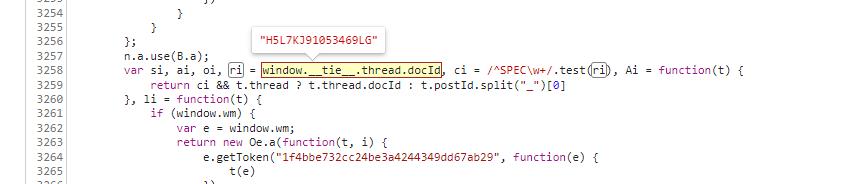
ri 变量的值为 window.__tie__.thread.docId,该值存在一个 docId,猜测是文档 ID,基于此,反复核对之后,发现就是新闻的 ID 号,问题解决了。
接下来的代码编写就交给你了。
总结
本篇博客希望你能掌握通过网络快速添加断点,这一反爬调试技巧。
📣📣📣📣📣📣
右下角有个大拇指,点赞的漂亮加倍
欢迎大家订阅专栏:
⭐️ ⭐️ 《Python 爬虫 120》⭐️ ⭐️
以上是关于某易跟帖频道,接口溯源分析,反爬新技巧,必掌握一下的主要内容,如果未能解决你的问题,请参考以下文章