深度学习100例 | 第42天:音乐的识别与分类
Posted K同学啊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习100例 | 第42天:音乐的识别与分类相关的知识,希望对你有一定的参考价值。
- 🔗 运行环境:python3
- 🚩 作者:K同学啊
- 🥇 选自专栏:《深度学习100例》
- 🔥 精选专栏:《新手入门深度学习》
- 📚 推荐专栏:《Matplotlib教程》
- 🧿 优秀专栏:《Python入门100题》
🚀 我的环境:
- 语言环境:Python3.6.5
- 编译器:jupyter notebook
- 深度学习环境:TensorFlow2.4.1
- 本文数据:公众号(K同学啊)内回复
DL+42可以获取数据 - 项目代码:已全部放在文中,按顺序copy即可
如果你是一名深度学习小白可以先看看我这个专门为你写的专栏:《小白入门深度学习》
我们的代码流程图如下所示:

文章目录
一、准备工作
大家好,我是K同学啊!
继上一篇文章后,这一篇文章我将继续带大家进一步探索深度学习在语音识别方面的应用,文本最后的识别准确率高达93.11%。
音乐是一种艺术形式和文化活动,其媒介是按时组织的、有规律的声波。它的基本要素包括强弱、调性、时长、音色等。由这些基本要素相互结合,形成音乐的常用的“形式要素”,例如:节奏、曲调、和声,以及力度、速度、调式、曲式、织体等。构成音乐的形式要素,就是音乐的表现手段。不同类型音乐可能会强调或忽略其中的某些元素。
音乐的创作、表现、意义甚至定义都根据文化和社会背景而有所不同。长期以来,人们一直在尝试理解声音以及一首歌曲与另一首歌曲的区别。如何可视化声音。是什么让一种音调与另一种不同。
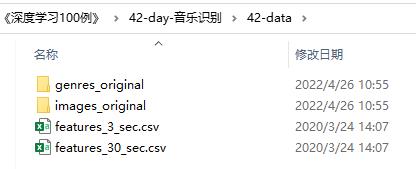
数据集介绍
- genres_original:音频原文件
- images_original:音频对应的频谱图像
- features_3_sec.csv:已经提取好的特征数据(3秒)(我们将使用的文件)
- features_30_sec.csv:已经提取好的特征数据(30秒)
方法介绍
- 有 3 种从音频文件中提取特征的基本方法:
a) 使用音频文件的 mffcs 数据
b) 使用音频的频谱图图像,然后将其转换为数据点(就像对图像所做的那样)。这可以使用 Librosa 的 mel_spectogram 函数轻松完成
c) 结合这两个特征来构建更好的模型。 (需要大量时间来读取和提取数据)。 - 我选择使用第二种方法。
- 标签已转换为分类数据以进行分类。
- CNN 已被用作对数据进行分类的主要层
1. 导入所需的库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline # 作用是内嵌画图,省略掉plt.show()这一步,直接显示图像
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.model_selection import GridSearchCV
from sklearn.preprocessing import MinMaxScaler
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, Flatten, Dense, MaxPool2D, Dropout
from tensorflow.keras.utils import to_categorical
import tensorflow as tf
import os,glob,skimage,librosa
import librosa.display
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
2. 数据展示
import IPython.display as ipd
audio_fp = './42-data/genres_original/blues/blues.00000.wav'
dataSample, sampling_rate = librosa.load(audio_fp)
ipd.Audio(dataSample, rate=sampling_rate)

import librosa.display as lplt
plt.figure(figsize=(10,3))
lplt.waveshow(dataSample)
plt.show()

plt.figure(figsize=(10, 3))
D = librosa.amplitude_to_db(np.abs(librosa.stft(dataSample)), ref=np.max)
librosa.display.specshow(D, y_axis='linear')
plt.colorbar(format='%+2.0f dB')
plt.title('Linear-frequency power spectrogram')
plt.show()

二、数据集构建
这里采用已经提取好的音频数据特征直接构建数据集。
dataframe = pd.read_csv('./42-data/features_3_sec.csv')
dataframe.head()

classNames = list(set(dataframe['label']))
X = dataframe.drop(['filename','length','label'], axis = 1)
Y_ = [classNames.index(i) for i in dataframe['label']]
Y = to_categorical(Y_)
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, random_state = 1, test_size=0.25)
X.shape, Y.shape
((9990, 57), (9990, 10))
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train = pd.DataFrame(scaler.fit_transform(X_train), columns=X_train.columns)
X_test = pd.DataFrame(scaler.transform(X_test), columns=X_train.columns)
三、模型构建&训练
from tensorflow import keras
def keras_model(optimizer='adam', init='glorot_uniform'):
model = keras.models.Sequential([
keras.layers.Dense(1024, activation='relu', kernel_initializer=init, input_shape=(X_train.shape[1],)),
keras.layers.Dropout(0.4),
keras.layers.BatchNormalization(),
keras.layers.Dense(512, activation='relu', kernel_initializer=init),
keras.layers.Dropout(0.4),
keras.layers.BatchNormalization(),
keras.layers.Dense(256, activation='relu', kernel_initializer=init),
keras.layers.Dropout(0.4),
keras.layers.BatchNormalization(),
keras.layers.Dense(128, kernel_initializer=init, activation='relu'),
keras.layers.Dropout(0.4),
keras.layers.BatchNormalization(),
keras.layers.Dense(64, kernel_initializer=init, activation='relu'),
keras.layers.Dropout(0.4),
keras.layers.BatchNormalization(),
keras.layers.Dense(10, activation='softmax'),
])
model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=['accuracy'])
return model
model = keras_model()
# 打印网络结构
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 1024) 59392
_________________________________________________________________
dropout (Dropout) (None, 1024) 0
_________________________________________________________________
batch_normalization (BatchNo (None, 1024) 4096
_________________________________________________________________
dense_1 (Dense) (None, 512) 524800
_________________________________________________________________
dropout_1 (Dropout) (None, 512) 0
_________________________________________________________________
batch_normalization_1 (Batch (None, 512) 2048
_________________________________________________________________
dense_2 (Dense) (None, 256) 131328
_________________________________________________________________
dropout_2 (Dropout) (None, 256) 0
_________________________________________________________________
batch_normalization_2 (Batch (None, 256) 1024
_________________________________________________________________
dense_3 (Dense) (None, 128) 32896
_________________________________________________________________
dropout_3 (Dropout) (None, 128) 0
_________________________________________________________________
batch_normalization_3 (Batch (None, 128) 512
_________________________________________________________________
dense_4 (Dense) (None, 64) 8256
_________________________________________________________________
dropout_4 (Dropout) (None, 64) 0
_________________________________________________________________
batch_normalization_4 (Batch (None, 64) 256
_________________________________________________________________
dense_5 (Dense) (None, 10) 650
=================================================================
Total params: 765,258
Trainable params: 761,290
Non-trainable params: 3,968
_________________________________________________________________
history = model.fit(X_train, Y_train, epochs = 100, batch_size = 128, validation_data = (X_test, Y_test))
Epoch 1/100
59/59 [==============================] - 2s 8ms/step - loss: 2.1960 - accuracy: 0.2573 - val_loss: 1.5879 - val_accuracy: 0.4500
Epoch 2/100
59/59 [==============================] - 0s 5ms/step - loss: 1.6304 - accuracy: 0.4359 - val_loss: 1.2863 - val_accuracy: 0.5781
......
59/59 [==============================] - 0s 5ms/step - loss: 0.1210 - accuracy: 0.9648 - val_loss: 0.3021 - val_accuracy: 0.9271
Epoch 100/100
59/59 [==============================] - 0s 5ms/step - loss: 0.1074 - accuracy: 0.9701 - val_loss: 0.2937 - val_accuracy: 0.9311
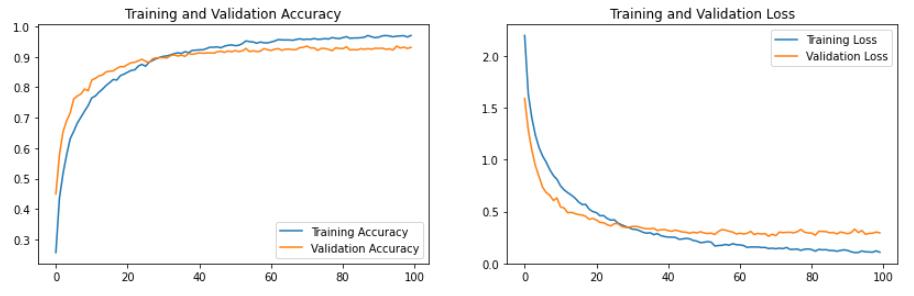
四、模型评估
predictions = model.predict(X_test)
score = model.evaluate(X_test, Y_test)
print(score)
79/79 [==============================] - 0s 1ms/step - loss: 0.2938 - accuracy: 0.9311
[0.2937540113925934, 0.9311448931694031]
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(len(acc))
plt.figure(figsize=(14, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()

以上是关于深度学习100例 | 第42天:音乐的识别与分类的主要内容,如果未能解决你的问题,请参考以下文章