深度神经网络 分布式训练 动手学深度学习v2
Posted AI架构师易筋
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度神经网络 分布式训练 动手学深度学习v2相关的知识,希望对你有一定的参考价值。




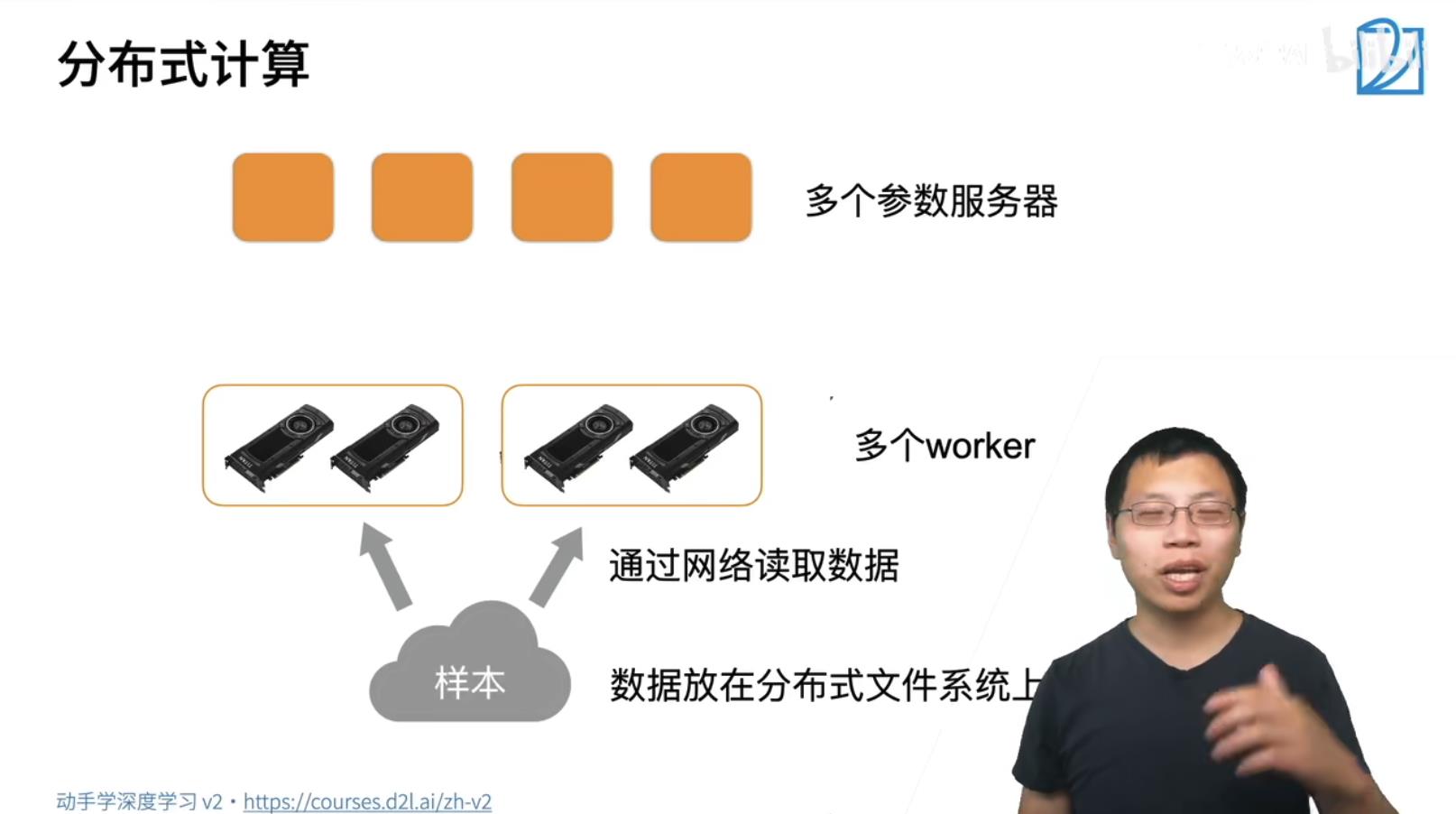
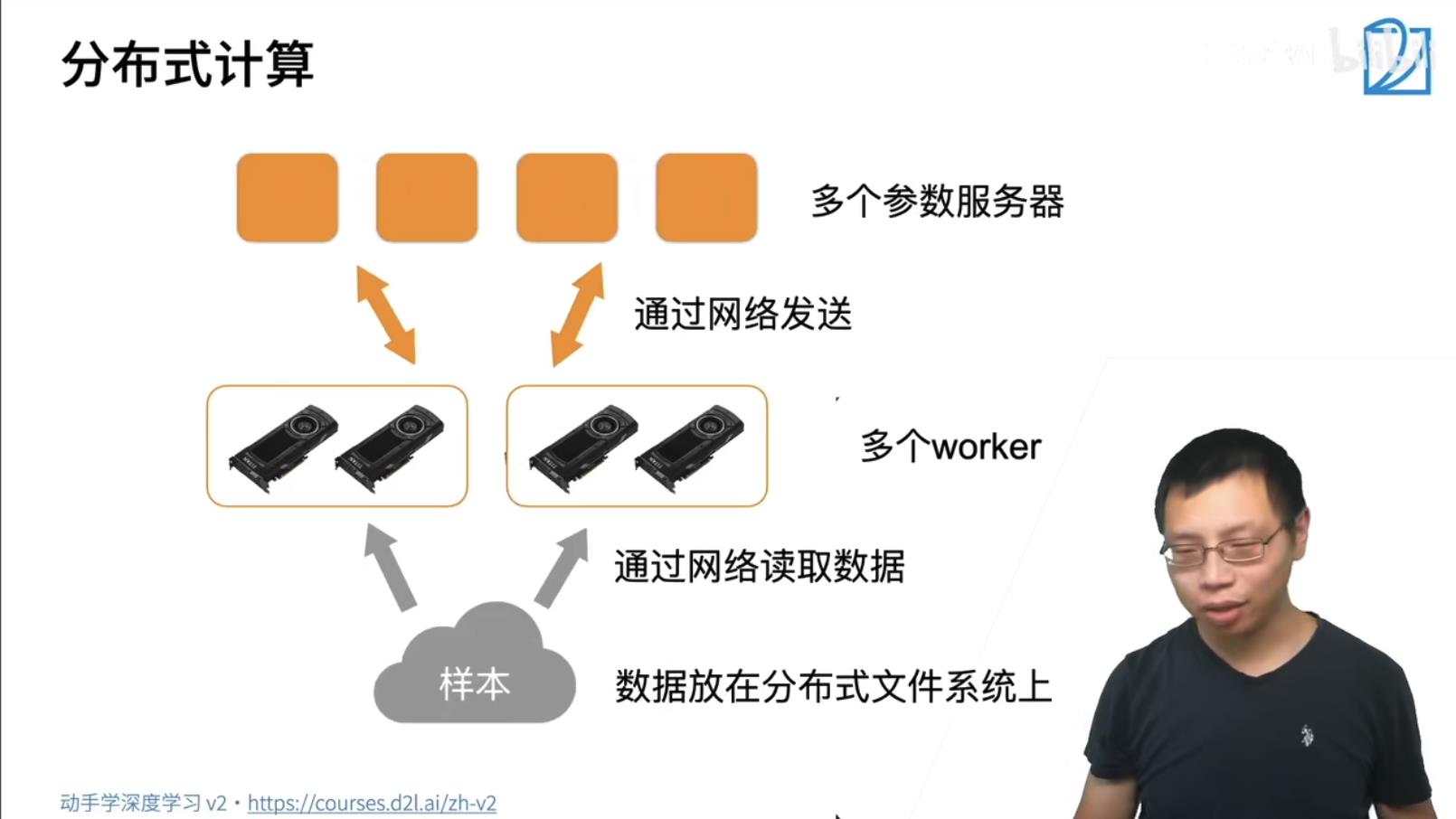
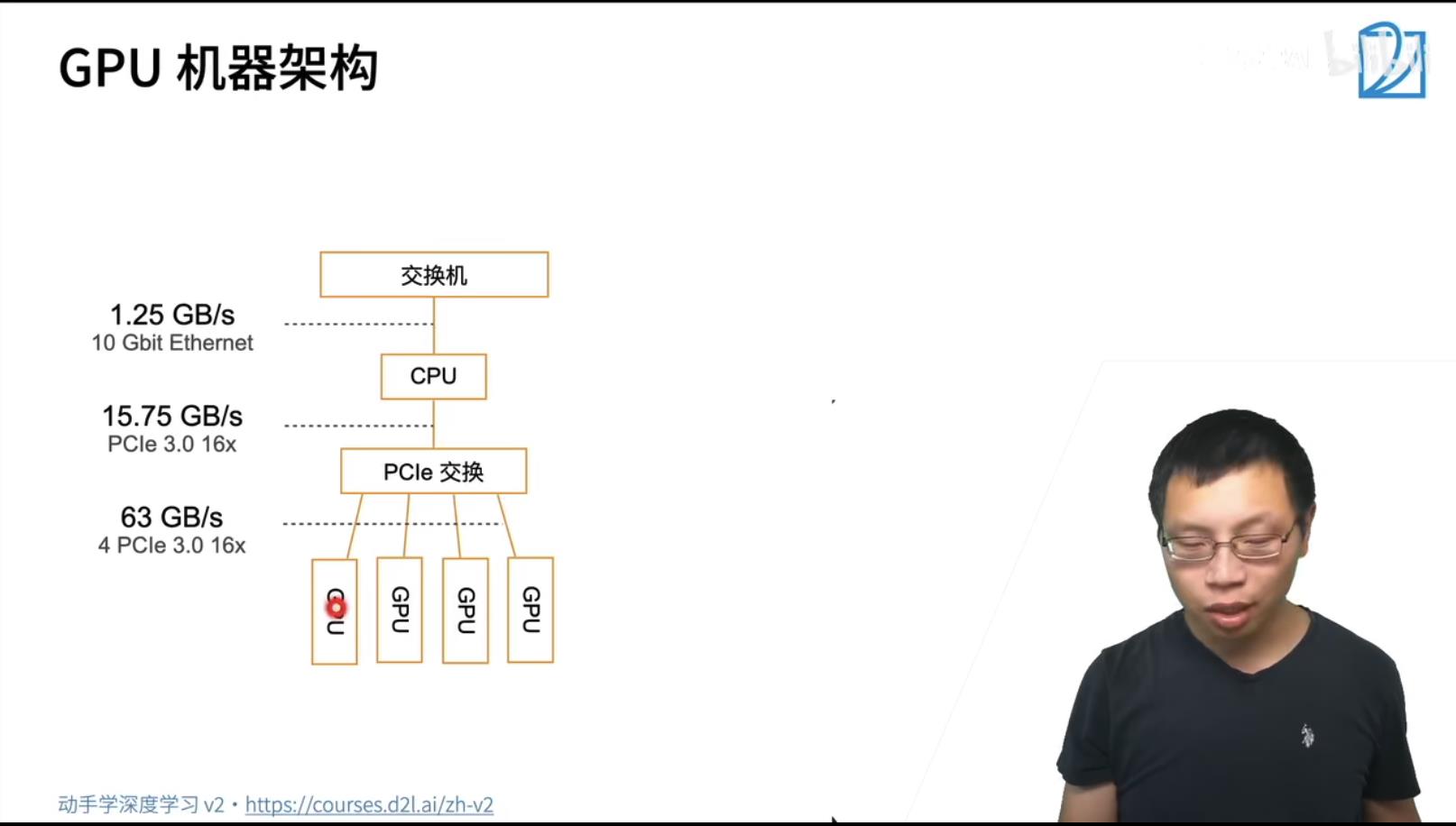
GPU到GPU的多条通讯带宽PCIe在63GB/s, GPU到CPU的通信只有一条带宽PCIe在15.75GB/s, 跨机器通信通过内部网络通信速度在于1.25GB/s. 所以优先在GPU内部处理数据,次优先级是传递到CPU,最差优先级是跨机器计算。


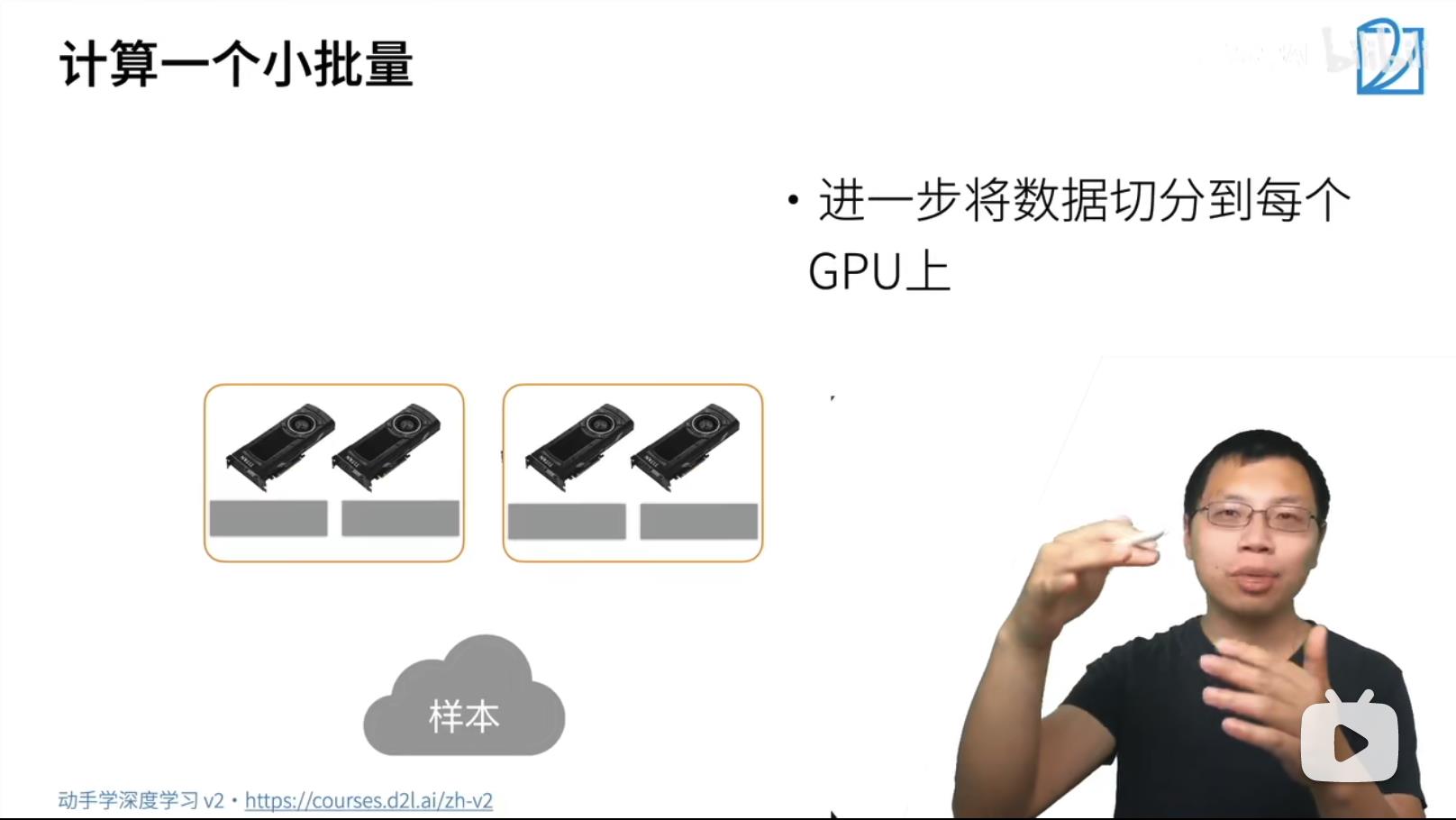

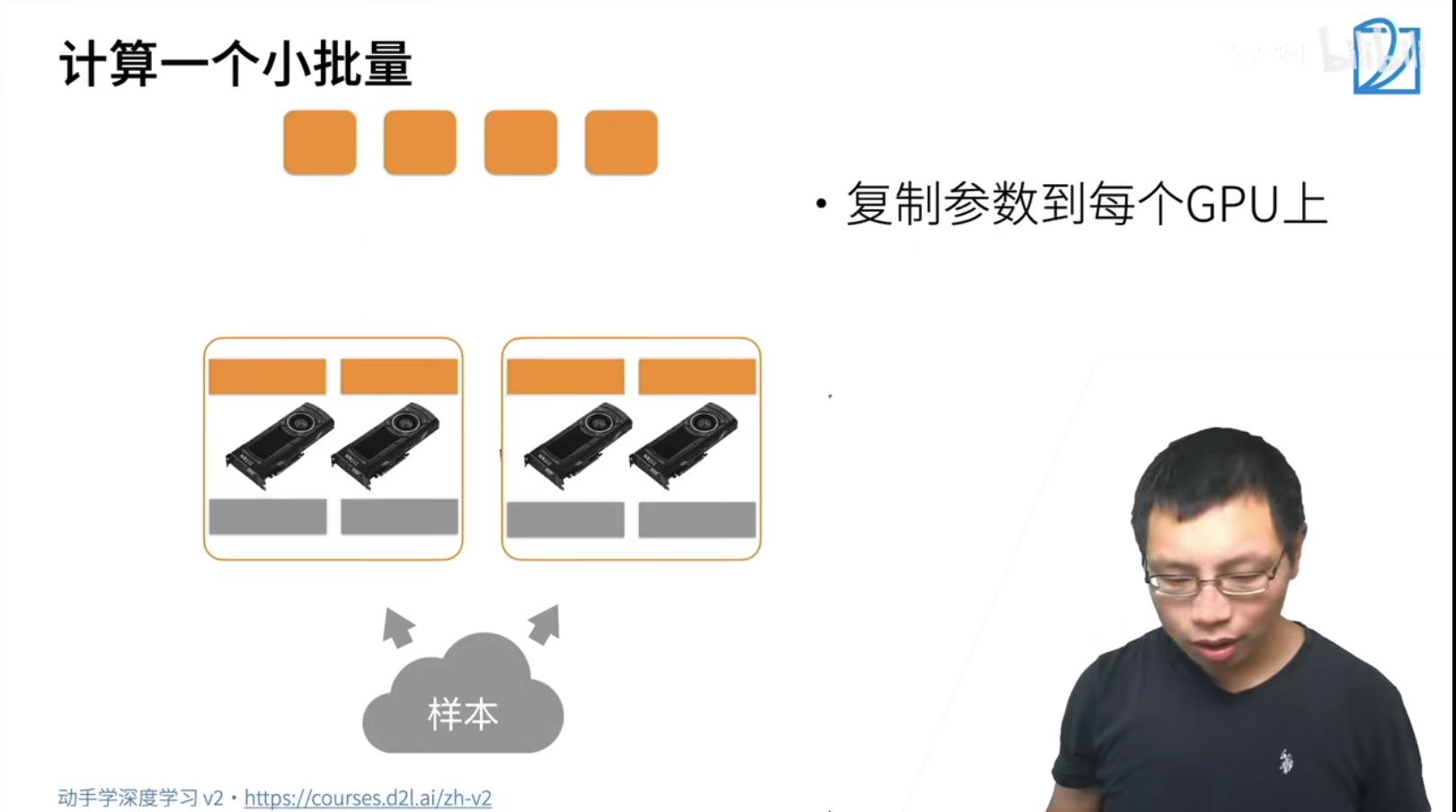

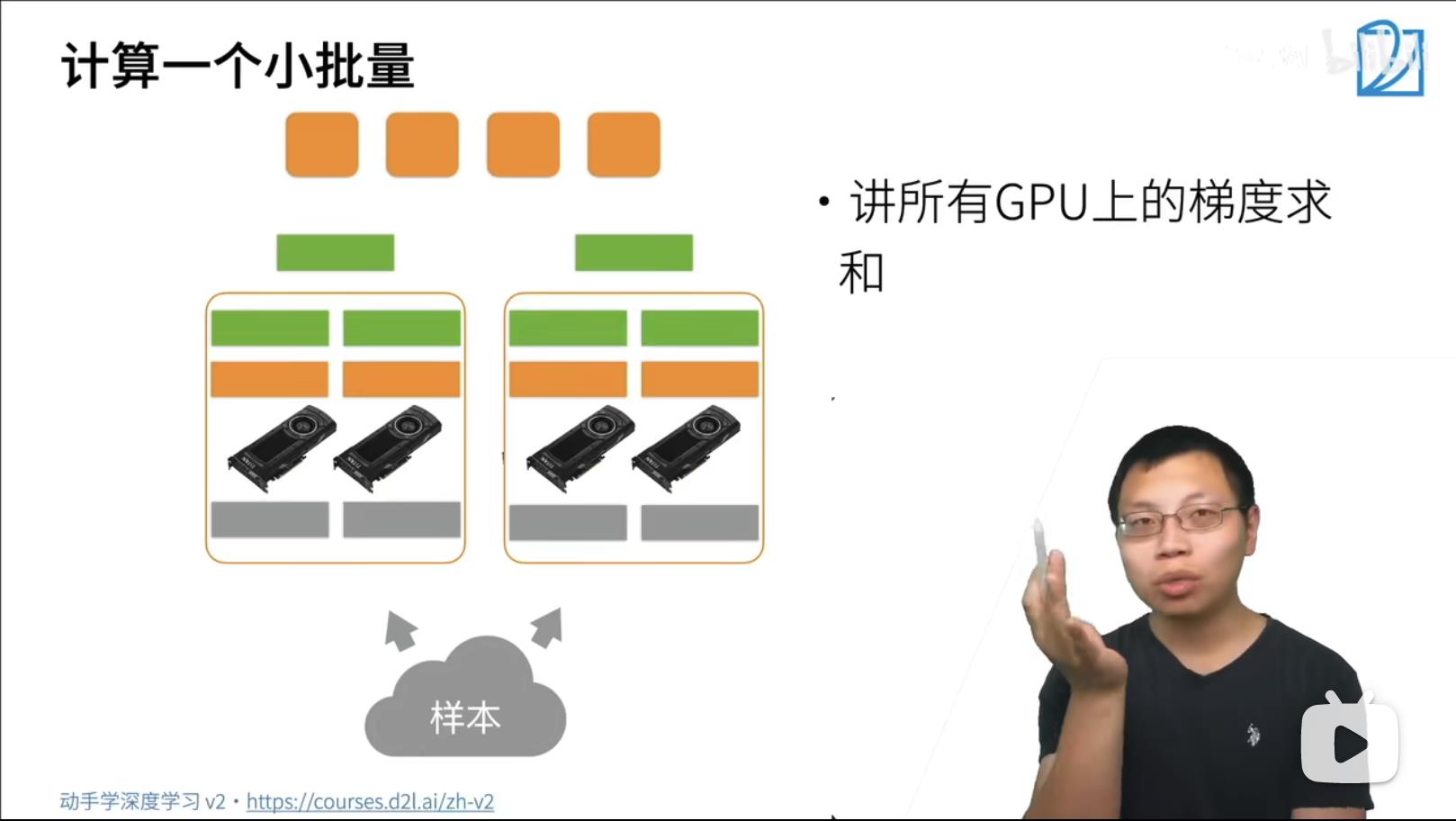
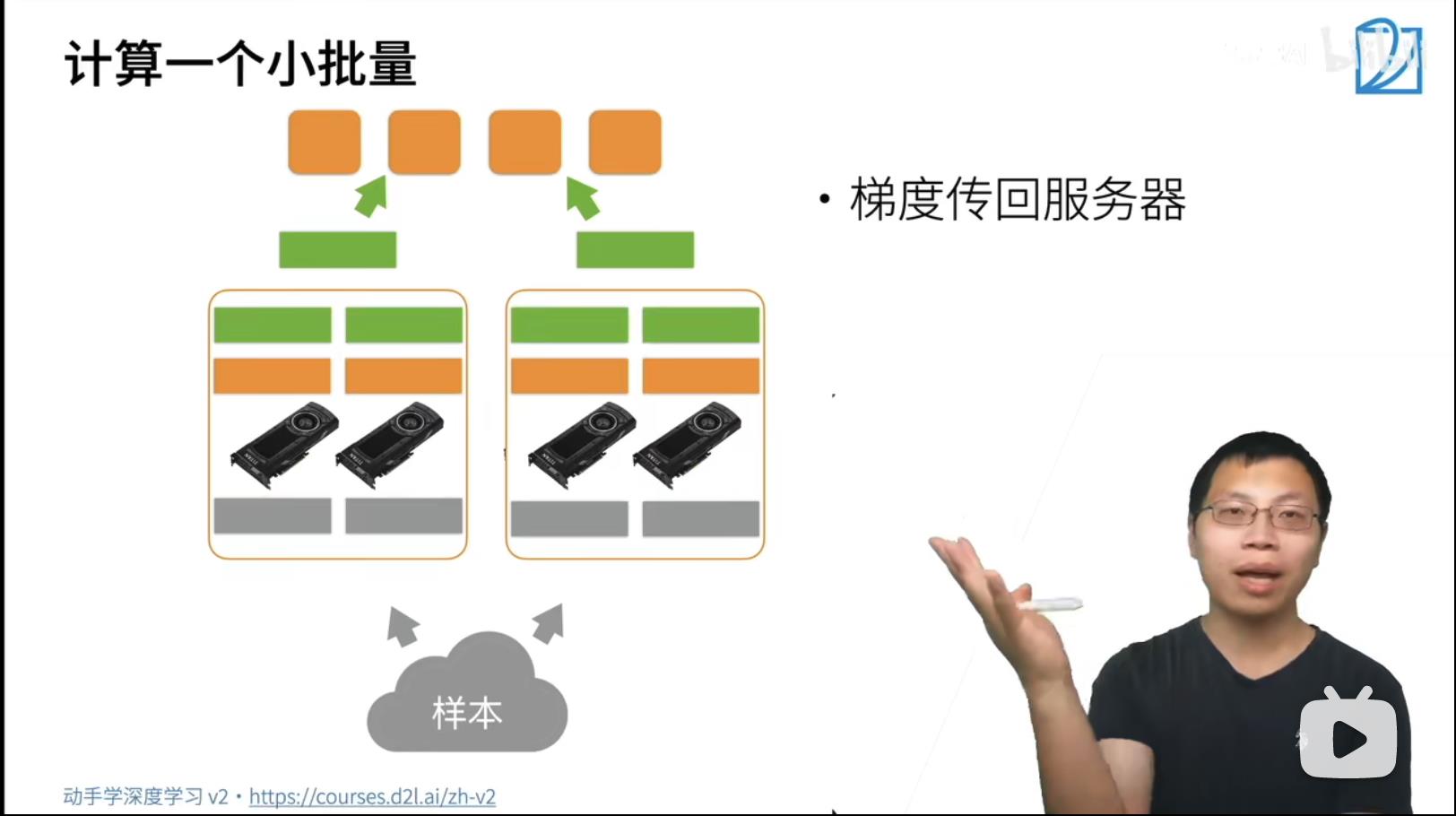

SGD Synchronize GD




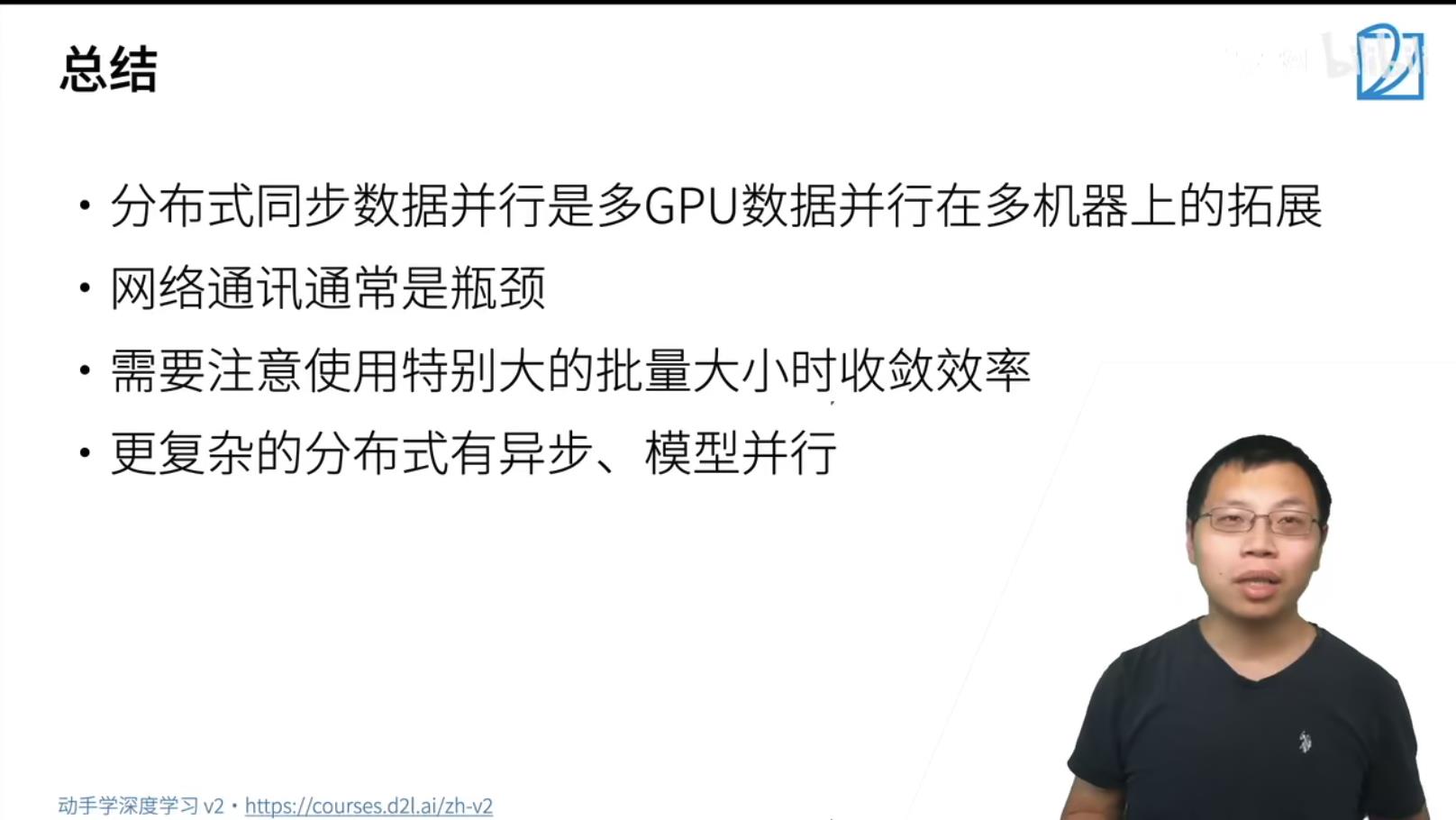
-
- batchSize越大,训练的有效性曲线是下降的。batchSize的数据在diverse 多样性的情况下,数据越多,学习到的特征也是更多的,所以训练的有效性会更好。
参考
https://www.bilibili.com/video/BV1jU4y1G7iu?p=1
以上是关于深度神经网络 分布式训练 动手学深度学习v2的主要内容,如果未能解决你的问题,请参考以下文章