树的那些破事~模板小结
Posted Huterox
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了树的那些破事~模板小结相关的知识,希望对你有一定的参考价值。
文章目录
前言
这里主要记录一些和树相关的内容,一些常见的关于树的算法。
开始之前谢铭这个老哥:(BoyC啊)
一个灰常流批的大佬,上天入地,无所不能,摸着这个老哥的屁股过河,美滋滋~
演示语言
为了方便理解,本次还是采用Python来进行演示,原因的话很简单,主要是,首先在PTA这个平台,Python的评测速度要比java快,然后是输入问题,java的输入有很多坑,没有Python快。最后一点是,Python代码很明朗。会java 的看Python没有门槛,但是反过来,就不好说了。
树的定义
在此之前我先说一下关于树的定义,这里还是采用最直接的表示方法,使用链表法也就是这样的。
注意点
我们所有的数组的下标都是从0开始的,切记!(在本篇博文中)然后由于我的习惯问题,先序,前序都是一个玩意。
class Node:
value = None
left = None
right = None
def __init__(self,value):
self.value = value
树的遍历
这个咱们主要介绍5个遍历模板。
首先是咱们的前中后遍历,然后是咱们的先序遍历,之后是层次遍历,最后是遍历树的深度。
这一块的代码都比较好记,好写。
先序遍历
根左右
def XianXu (root):
if(root==None):
return
print(root.value)
XianXu(root.left)
XianXU(root.right)
中序遍历
左根右
def XianXu (root):
if(root==None):
return
XianXu(root.left)
print(root.value)
XianXU(root.right)
后序遍历
左右根
def XianXu (root):
if(root==None):
return
XianXu(root.left)
XianXU(root.right)
print(root.value)
这块的话,记住这个顺序,待会有妙用。
层次遍历
这个的话就是稍微复杂一点点,需要使用到队列。
在Python里面的话,可以直接使用list实现一个队列。很爽。
quque = []
def cengci(root):
queue.append(root)
while (len(queue) != 0):
current = queue.pop(0)
print(current.value)#这里look here
if (current.left):
queue.append(current.left)
if (current.right):
queue.append(current.right)
判断深度
这个也是简单的
def shendu(root):
if(root==None):
return 0
return max(shendu(root.left,root.right))+1
这个代码呢,不太好理解,你可以这样理解,就是这个函数 shendu()就是用来获取一棵树的深度的,一个树有左右子树,那么只需要获取两个子树的深度加上当前的这个深度就这颗树的深度。当某一个节点为空的时候,到头了,自然深度就是0,上一个过来的节点是叶子节点。
树的构建(通过已知的序(先,中,后))
树的构建有很多种,要么是森林转为树,要么树转森林,等等,这里先来简单一点的,通过已知的序来创建一颗树,原来什么数据结构书上还有直接通过一个数组来创建的,那个就没必要说了,很简单。
先序+中序
首先明确一点哈,如果不是特殊的树,例如二叉搜索树,在没有中序的情况下,是无法建立一颗树的。
这个前面,我是说过的,但是那个模板是没有优化的,今天也是结合一个哥们(BoyC啊)的思路,做一个小结。
为什么需要中序,才能建树原因的话,可以参考这张图

这个是由于树的创建流程决定的。
需要中序来确定,那个左右子树的位置,然后通过前序,或者后序,来判断子树根节点的位置。
除非你的树很特别,你能够在不需要别的排序数组的情况下,知道它的根节点,或者左右子树的位置。
先解释一下参数的含义,从左到右
先序数组
中序数组
一开始根节点在先序数组的位置(默认当然是0)
start 中序数组的初始位置(为了划分左右子树)
end 中序数组的末尾位置
def creatTreeByPre(pre,ino,root,start,end):
if(start>end):
return
i = start #找出根节点在中序数组的位置,然后就可以划分左右子树了
while(i<end and ino[i]!=pre[root]):
i+=1
root = Node(pre[root])
root.left=creatTreeByPre(pre,ino,root+1,start,i-1)
root.right=creatTreeByPre(pre,ino,root+i+1-start,i+1,end):
return root
这个注意的是这个右子树的根节点在前序排序里面的下标的推导:root+i+1-start
这里的都是从0开始小标哈。
后序+中序
def createTreePro(pro, ino, root, start, end):
if(start>end):
return
i = start
while (i < end and ino[i] != pro[root]):
i +=1
Root = Node(pro[root])
Root.left = createTreePro(pro,ino,root-1-end+i, start, i - 1)
Root.right = createTreePro(pro,ino,root - 1, i + 1, end)
return Root
这里和前面几乎一样但是区别就是,在后序里面推导左子树的根节点,因为后序是从后面开始作为根节点的。
二叉搜索树+先序
前面说,我们之所以要中序是为了划分左右子树。
但是二插搜索树比较特殊。
我们可以直接通过这玩意的性质,去划分。
这了的话咱们结合具体的题目来看。然后再来慢慢解释

这道题目就是比较特殊的点。
首先我们先不考虑什么叫做:镜像
我们就看看怎么根据前面的模板去构建这颗树
来我们先看看刚才的从先序+中序的代码
def creatTreeByPre(pre,ino,root,start,end):
if(start>end):
return
i = start #找出根节点在中序数组的位置,然后就可以划分左右子树了
while(i<end and ino[i]!=pre[root]):
i+=1
root = Node(pre[root])
root.left=creatTreeByPre(pre,ino,root+1,start,i-1)
root.right=creatTreeByPre(pre,ino,root+i+1-start,start,end):
return root
现在我们改一下,如何通过这种特殊条件去建立一棵树。
现在我们只有先序,所以参数设定上面只有四个参数
然后,由于先序,我们发现start 其实就是 root 所以 现在只需要三个参数
所以此时是
def CreatTree(pre,start,end):
pass
start ,end 是左右子树的位置,
如何找,很简单,用性质呀。这个是搜索二叉树。
这里为了方便,我们把start 参数 end 参数 叫做 l,r表示左右
def CreatTree(pre,l,r):
if(l>r):
return
l_end = l+1
r_start = r
while(l_end<=r and pre[l_end]<pre[l]):
l_end+=1
while(r_start>l and pre[r_start]>=pre[l]):
r_start-=1
#此时我们就通过这种方式,利用性质确定了左右子树的边界不过(注意加一,减-)
root = Node(pre[l])
root.left=CreatTree(pre,l+1,l_end-1)
root.right=CreatTree(pre,r_start+1,r)
return root
看到没有,其实是类似的,重点是确定根节点,然后这里比较特殊的是,左右子树的划分都在前序数组里面,然后边界就是根节点的位置(在前序里面)
镜像翻转
这里的还不够,注意到题目里面,说要那个有镜像的,拿这个啥意思呢,其实就是左子树变成右子树。换个位置就可以了。
接下来我们来看到完整AC 代码
#由于是前序排列,所以第一个就是根节点,并且,是一个二叉排序树,如果是这样的话
#我们只需要按照dfs一直往下找就看可以了,想要后续也简单,直接把搜索到的最左边的保存起来就可以了
#利用搜索二叉树的性质,我们可以很快在前序遍历表里面找到左右子树
N = int(input())
Pre = [int(i) for i in input().split()]
Pre.append(0)
Pro = []
def dfs(Pre,l,r,flag):
if(l>r):
return 0
l_end = l+1
r_start = r
if(flag):
#假设是二叉树
#先找左子树,因为是前驱,根左右,所以的话 l_end<=r是一定的如果只有俩个节点
#一定是根,左
while(l_end<=r and Pre[l_end]<Pre[l]):
l_end+=1
while(r_start>l and Pre[r_start]>=Pre[l]):
r_start-=1
else:
#假设不是,是个镜像,那就说明是反过来的
while(l_end<=r and Pre[l_end]>=Pre[l]):
l_end+=1
while(r_start>l and Pre[r_start] < Pre[l]):
r_start-=1
#左右根,Pre[l]不就是相当于根节点了呗
dfs(Pre,l+1,l_end-1,flag)
dfs(Pre,r_start+1,r,flag)
Pro.append(Pre[l])
#判断是不是
dfs(Pre,0,N-1,True)
def show():
print("YES")
res = ""
for i in Pro:
res+=str(i)+" "
print(res[:-1])
if(len(Pro)==N):
show()
else:
Pro.clear()
dfs(Pre,0,N-1,False)
if(len(Pro)==N):
show()
else:
print("NO")
不建树已知中序和某个序获取另一个序
这个意思还是上面那个题目的意思,要拿到后序遍历的数组。
按照道理 ,我们可能是要建立一颗树,然后在来个后序遍历,但是这里你看那个AC代码我也没有搞是吧。原因的话在这儿

按照顺序,如果这个题目换一下,给的是后序的,让你求先序。
那么你根据规则,先序是 根左右,你把 Pro.append(Pre[l]) 给我放到最上面就行了。
存储结构优化
前面我们是通过这个玩意
class Node:
value = None
left = None
right = None
def __init__(self,value):
self.value = value
来存储我们的树的节点的,但是怎么说有点麻烦。主要是创建对象的时候需要消耗内存,而且,我们完全按照这个树的结构去存储的话,如果我想要获取某一个叶子节点的话,我就只能通过根节点去遍历,哪怕我知道那个叶子节点的父节点,也没有用,因为我拿不到那个父节点的内存地址,除非我把它都存起来了。如果是这样的话,那么我觉得也没有必要使用这个Node结构了。我们直接使用数组去维护算了。
不过这里考虑到要维护三个数组,比较繁琐,所以这里来个容易理解的使用字典,hashmap存储(但是多了就不好维护了,我先前做一个题目维护了四个字典,还是Python写的很痛苦,只是为了优化一点点查询的时间,而且我一般是在写图的时候用这个,写那个无向图,矩阵的话太那啥了,不过Python可以直接那样写,应该不会超,java的话拿样干必超)
这块主要说思路,因为写的话还是很好办的。
数组存树
这里需要三个数组,然后通过下标把数组联系起来,需要三个数组的原因是因为我们有三个信息要维护,value,left ,next

这个一目了然,但是三个数组多少维护有点费劲。
所以还有一个就是Hash法
Hash 法
这个的话,依然是需要Node来存储的,区别是直接先初始化,这样会快很多。我们同样表示上面那颗树。
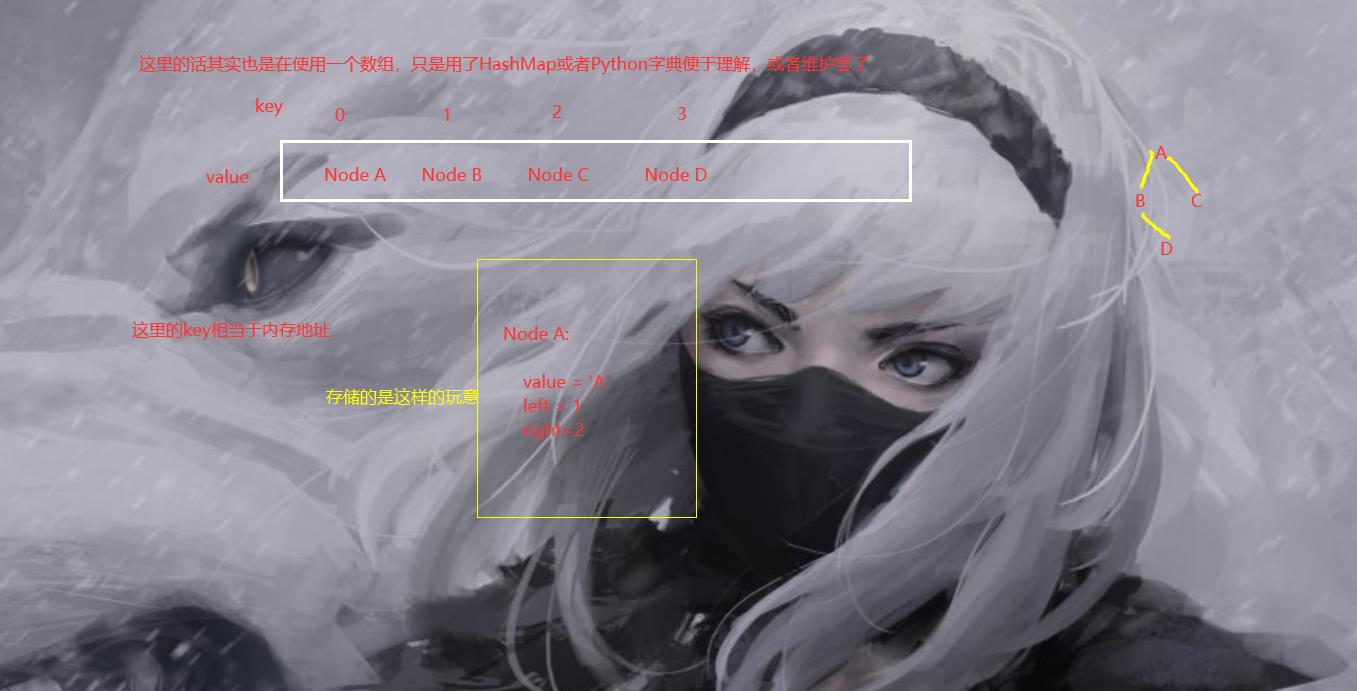
这样一来也会稍微快一点,毕竟可以一次性初始化,一次性开辟和多次开辟是不一样的消耗。尤其是对Java来说,new 已经够慢了,虽然反射更慢,最快克隆。 而且说句实话,能用Python就Python,java 一个Scanner就把你坑住了了,C++,我不会,不熟悉,而且那玩意比Python难写多了。对于输入少,比较考验数据结构,没有精度问题的时候,在直接使用java,不过不知道为啥,可能是PTA这个平台的问题,同样的情况下,java 实现的往100+ms跑了,但是 Python 的就几十ms 。是不是把编译时间算上去了,咱们不知道,不过由于这个特性,所以,java 不敢写暴力,我Python阔以。
以上是关于树的那些破事~模板小结的主要内容,如果未能解决你的问题,请参考以下文章