大数据量的处理方案(递归)
Posted 稗子酒
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据量的处理方案(递归)相关的知识,希望对你有一定的参考价值。
在日常工作中,如果遇到数据量特别大的情况下,要将数据全部渲染到页面上,这时候可能会出现请求数据失败或者浏览器加载时间过长的问题,如果不适用路由懒加载或者组件懒加载,有没有什么办法可以将大量的数据去进行渲染的同时也不会出现加载缓慢的情况呢?
所以先看一段代码
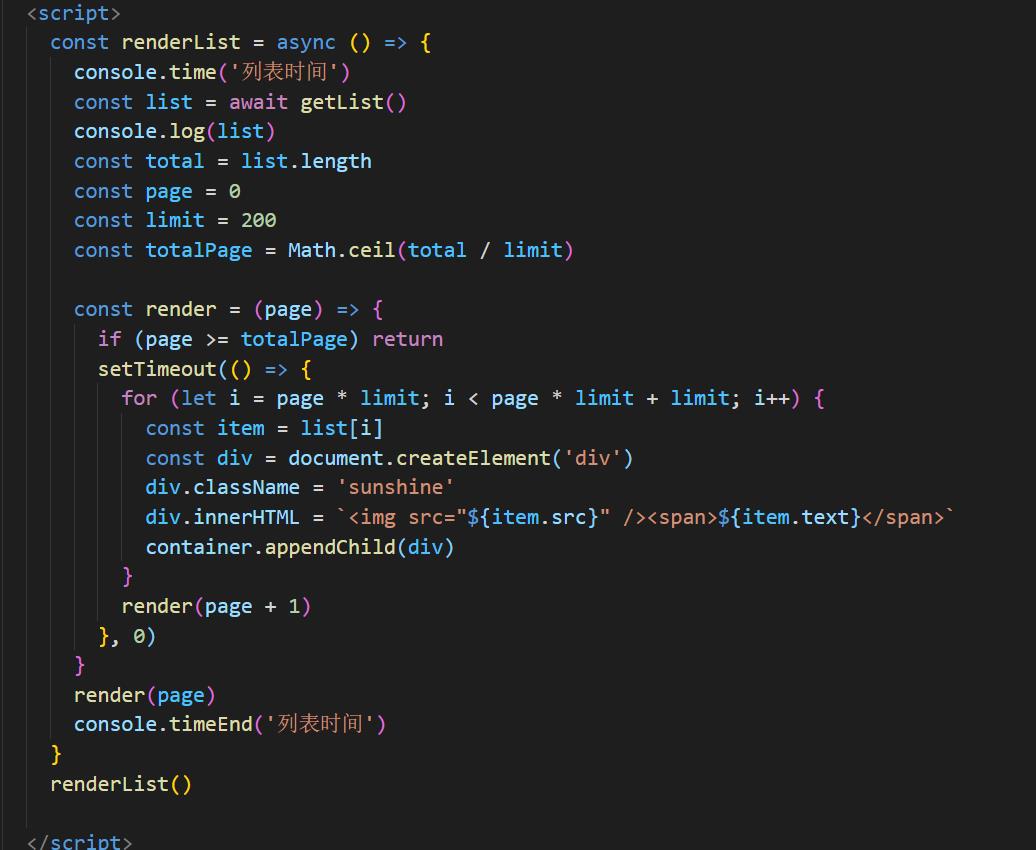
下面逐一对上面的代码进行解读
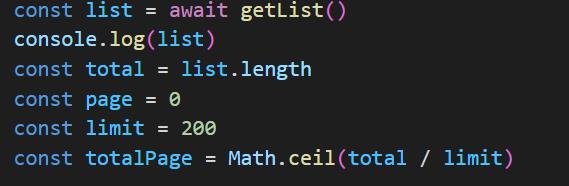
首先我们假设getlist()这个请求获取到的是十万条数据,当拿到这十万条数据之后,首先做的第一步便是将这十万条数据按两百条一页进行分页处理,我们来算一下,按两百条每页去处理,总共会处理出来500页,为什么需要使用math.ceil()去进行一个浮点数的天花板数取值呢,如果刚好拿到的数据不是一个整数,咱们来假设,一共有十万零一条数据,那应该是多少页呢,如果最后一页没有200条,咱也不能将数据丢了,所以需要进行一个浮点数的天花板数取值.所以一共就有501页数据
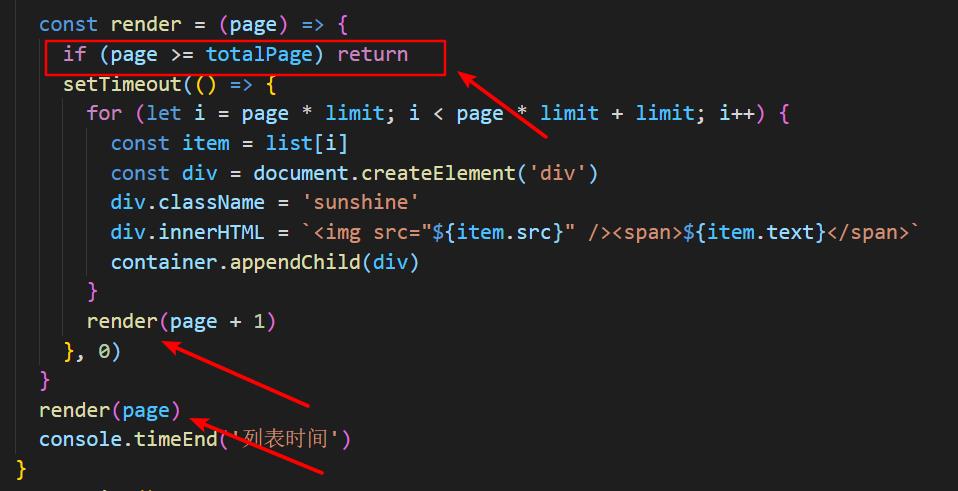
下面第二步咱们来看看这一段代码,首先箭头标注的地方仔细看一下,是不是一个递归加上它的终止条件,当我们去调用这个函数的时候,咱们来模拟一下代码的运行过程

当这个写出来的时候,代码讲解基本上已经讲解完了,当去调用这个render函数的时候,传进去的page是0,用0与分页的500去对比,得到的是false,函数不会return结束,继续去进行for循环,当它走完for循环的时候,已经将199条数据渲染到页面上了,这时候,浏览器的加载缓慢问题不就解决了吗,然后当循环走完之后,又去调用了自己,这时候传入的page就是1了,用1与分页的500去对比,得到的是false,函数不会return结束,继续去进行for循环当page以1走完下一轮循环的时候,可以往页面上渲染,200-399条数据,然后以此类推下去,当所有的数据全部渲染完毕的时候,用户未必会看完这么多,代码的执行速度其实很快

最后再来说一下这个定时器,在js中分为同步代码和异步代码,同步代码的执行机制是一条一条依次执行,如果上一条没有执行完,是不会去执行下一条代码,但是异步代码会同步执行,并不会阻碍其他代码的执行,可以想象成手机的后台,当挂在后台的时候,程序依旧在执行,依旧占用着内存,依旧会耗电,但是有一个好处就是不会阻碍其他代码的执行,所以这里使用了延时器,去进行代码的异步执行和页面的渲染,但是又不是真正需要去进行延时执行,所以设置延时时为0,虽然为0也会有几毫秒的误差,但是相较于整体来讲,所带来的影响还是比较小的
所以,就可以实现数据量太大也可以进行页面的渲染和浏览器的正常运行,这整段代码的精髓可能就在分页以及递归的书写,加上延时器的巧妙运用.
以上是关于大数据量的处理方案(递归)的主要内容,如果未能解决你的问题,请参考以下文章