轻松玩转自动机器学习AutoML:H2O Flow
Posted Python学习与数据挖掘
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了轻松玩转自动机器学习AutoML:H2O Flow相关的知识,希望对你有一定的参考价值。
想想我们每次创建机器学习模型时,编写多行代码是不是很累!虽然这里给大家总结了一个建立机器学习模型的万能模版,但还是累啊!
有没有想过,如果我们可以通过鼠标点击来构建机器学习模型会变得多么容易和高效?H2O Flow 为所有此类问题提供了解决方案!
H2O Flow 简介
H2O是一个开源机器学习和人工智能平台。它支持名为 Flow 的基于 Web 的界面。H2O Flow可用于创建各种类型的机器学习模型,而无需编写任何代码。我们可以简单地点击来构建机器学习管道。它具有对 R、Python、Scala 的 API 支持。
AutoML(自动化机器学习)是自动化了建模过程,这使数据科学家能够专注于机器学习管道的其他关键方面,例如特征工程和模型部署。
H2O flow安装
从官方页面H2O Download page[1]下载最新版本的软件。首先需要确保服务器自带了Java环境,因为H2O 的底层就是Java。
在有Java环境下,直接在上面的下载链接中,找到最新的h2o flow安装包,上述5个服务,除了Driverless AI其它皆开源,然后我们将其scp到服务器上,解压然后直接用命令启动就行了:
unzip h2o-3.34.0.7.zip
cd h2o-3.34.0.7/
java -jar h2o.jar
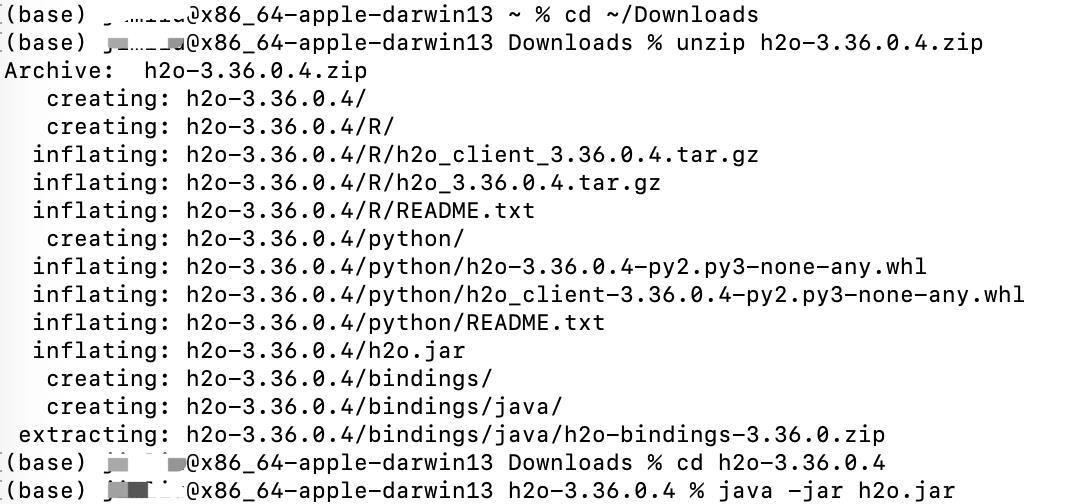
如果没有问题,它最后的日志里会提供一个地址,http://localhost:54323,进入这个地址,就能直接进入h2o flow页面,没有密码验证

在浏览器页面显示如下图所示。首先你可能会想到 Flow 的设计方式与 Jupyter 笔记本非常相似。右侧面板是帮助部分,对初学者来说很有见地。

上面的Assistance分别为:
importFiles(读取数据集)
importSqlTables(读取SQL表)
getFrames(查看已经读取的数据集)
SplitFrame(将一个数据集分成多份数据集)
mergeFrame(将两个数据集进行列组合或行组合)
getModels(查看所有训练好的模型)
getGrids(查看网格搜索的结果)
getPredicitons(查看模型预测结果)
getJobs(查看目前模型训练的任务)
runAutoML(自动建模)
buildModel(手动建立模型)
importModel(从本地读取模型)
predict(使用模型进行预测)
他们的步骤和正常的建模过程一样,有一定前置顺序,比如说如果没有相应的数据集,直接点最后的predict是没办法找到相关记录与模型进行的,它的下拉列表里没有任何可选择model与dataset,所以要玩好这个web,确实是需要下一番力气去学习,这里我引出官方更为详细的README[2],是一个可查阅的手册。
数据加载
我们将使用免费提供的数据集[3]。这些数据涉及银行的直接营销活动,基于多个特征,我们需要预测其客户的注册情况。
现在开始创建我们自己的 Flow notebook。注意顶部工具栏上的“+”按钮。我们可以使用它来插入单元格。就像 Jupyter notebook 一样,我们可以为想要编写的任何文本包含降价单元格。
单击导入文件选项并指定数据文件的位置并开始导入。我们还可以从 HDFS 和 S3 存储桶等其他来源导入文件。
在 H2O 流中导入数据有多种方式:
- 点击
Help按钮在菜单下方的assist me按钮行中,然后单击importFiles链接。在自动完成的搜索输入字段中输入文件路径,然后按Enter。从搜索结果中选择文件并单击“**全部添加”**链接进行确认。
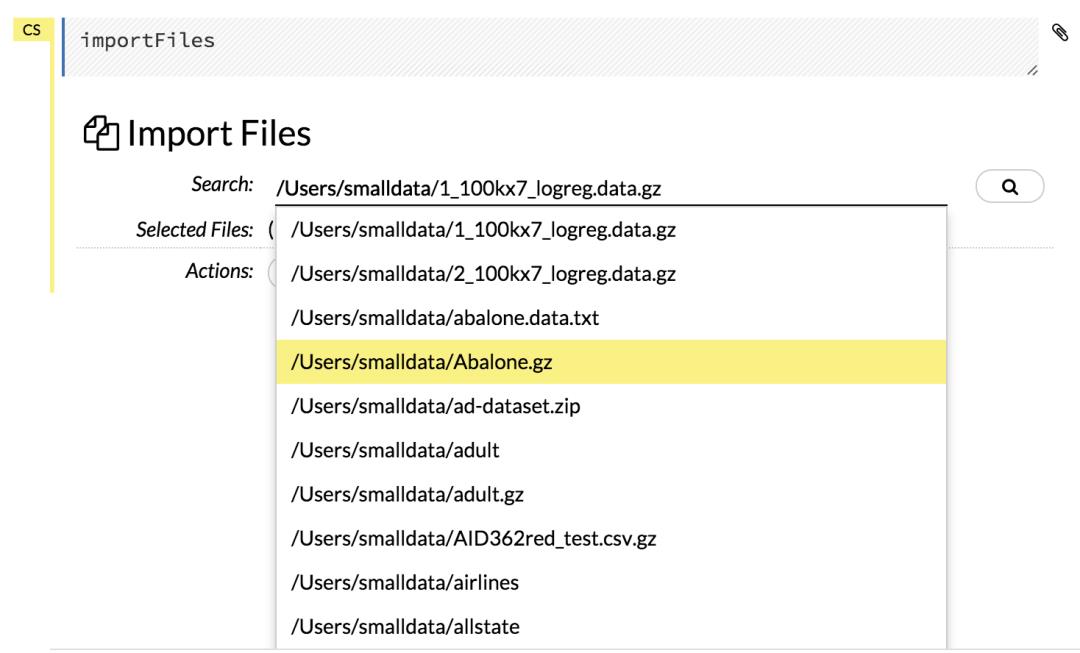
Flow_Import_AutoSuggest
- 在空白单元格中,选择CS格式,然后输入
importFiles ["path/filename.format"](其中path/filename.format代表文件的完整文件路径,包括完整的文件名。文件路径可以是本地文件路径,也可以是网站地址。
数据解析
数据解析是指定义模式。解析猜测器会自动为我们检测模式。我们可以根据需要随意更改任何列。我们可以将分类数据类型更改为数值数据类型,在这里我们可以将“day”列更改为 enum,因为一周只有 7 天。
我们预测客户是否会注册定期存款,因此这是一个二元分类问题。
通常在构建机器学习模型之前,对分类数据应用 one-hot 编码,但 Flow 为我们提供了自动 one-hot 编码功能。继续点击 Parse,等解析完成后,我们可以查看细化后的数据,包括大小、列和行。
数据探索
探索和可视化数据中,可以选择用于单独可视化它们的列。可以获得数字列的分布或分类列的频率计数。
我们可以看到“age”列的特征和摘要以及频率分布。
这里可以看到“y”列的分布。通过可视化目标列,可以看出存在高度的类不平衡。
同样,我们也可以检查其他列。
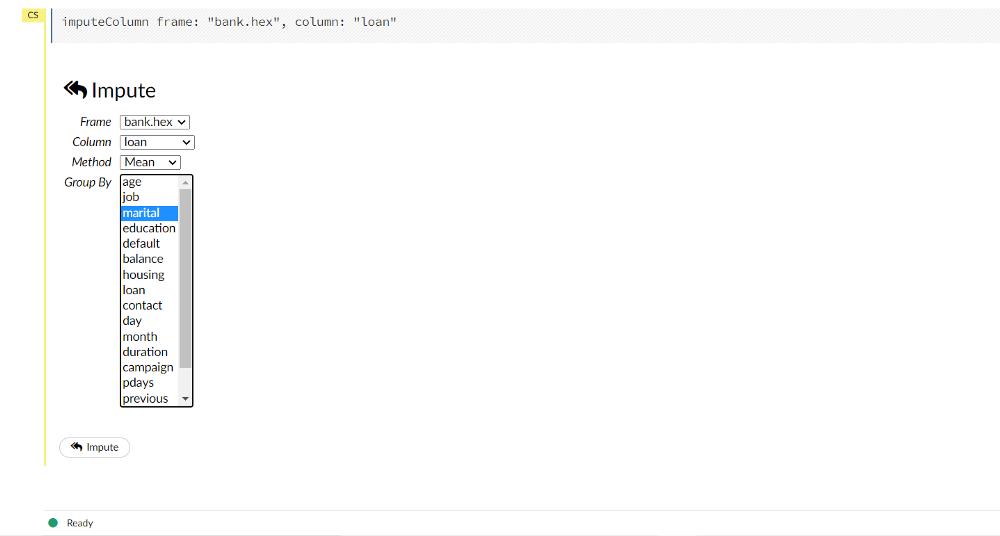
Flow 提供了用于估算数据的功能。这在将通过缺失值进行拟合线性模型的情况下很有用。提供了许多用于插补的方法。默认方法设置为_mean_
拆分训练和测试集
在开始训练模型之前,我们需要将数据拆分为训练集和测试集。我们可以通过从工具栏导航到data -> split frame来实现这一点。
注意训练集和测试集的默认拆分时间分别为 75:25。这个可以根据需要修改。将拆分重命名为"training_set"和"test_set"。
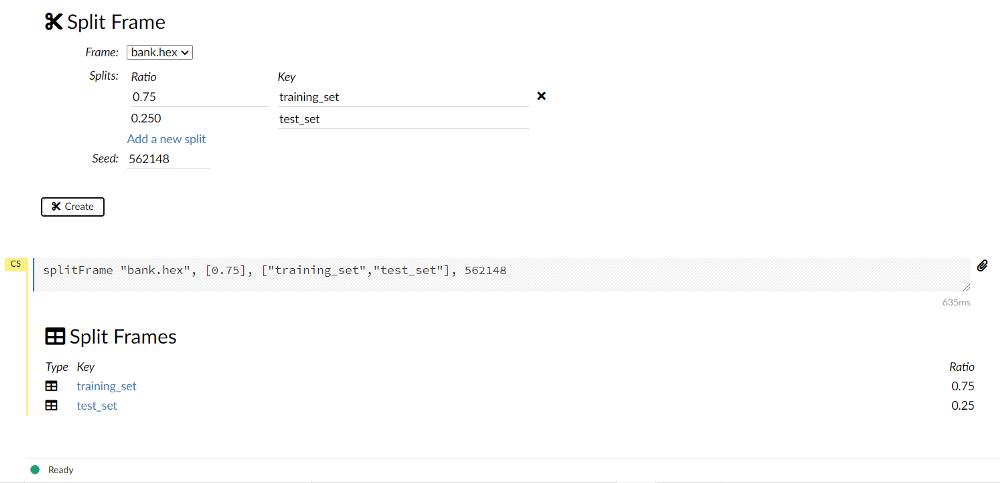
split
可以通过选择框架单独检查每个数据集

trainset
通过AutoML构建模型
AutoML 训练各种类型的模型,包括 GLM随机森林、分布式随机森林、极端随机森林、深度学习、 XGboost和 stack集成模型。它还提供了一个排行榜,其中所有模型都按一些指标排序。
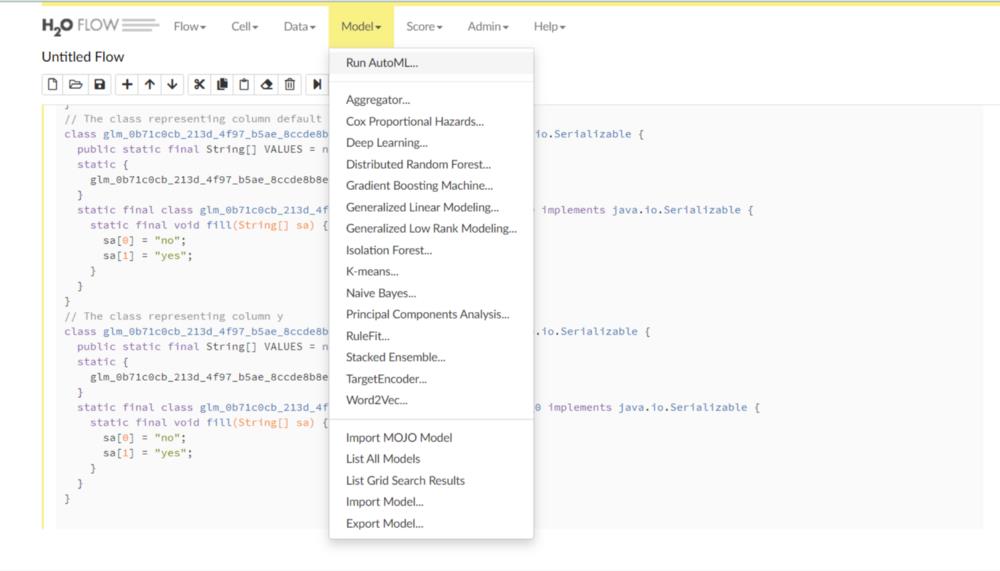
AutoML
可以分别选择 training_frame, response_frame 和 validation_frame作为 "training_set"、"y" 和 "test_set"。我们可以忽略其他选项,因为它们用于添加高级功能。
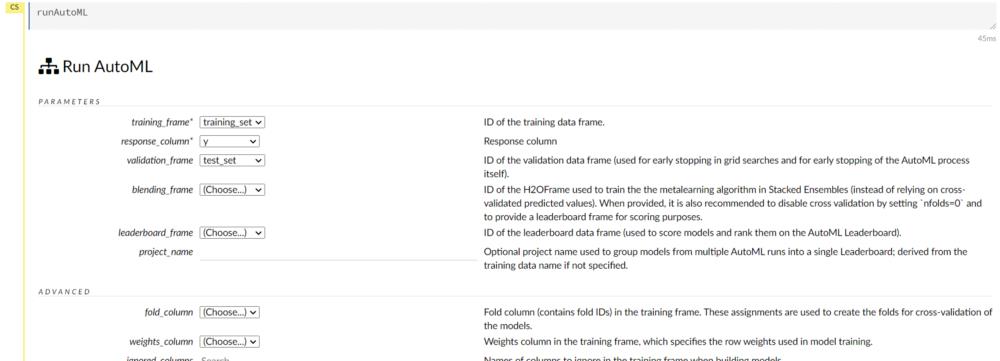
Frame
交叉验证数默认为 5。由于我们有一个类不平衡的情况,我们可以选择平衡类选项。
如果我们知道某些模型不相关,我们也可以排除它们。将 max_runtime_seconds 更改为 300 秒。AutoML 训练模型直到 max_runtime_seconds 之后它将停止。默认设置为 3600 秒。

max_runtime_seconds
最后,我们可以通过选择"build models"选项开始构建模型。有一个选项可以在训练时查看模型的实时更新。我们还可以通过图形表示实时查看评分历史。
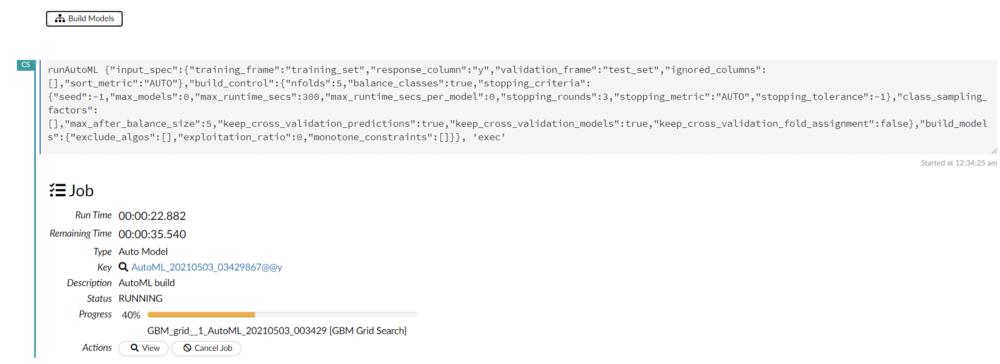
build models
模型探索
由于我们指定了max_runtime_seconds,因此训练过程将需要五分钟。Job完成后,我们可以导航到模型排行榜。
AutoML 训练的所有模型都根据性能按排序顺序显示。这种情况下,XGboost模型是性能最好的模型。
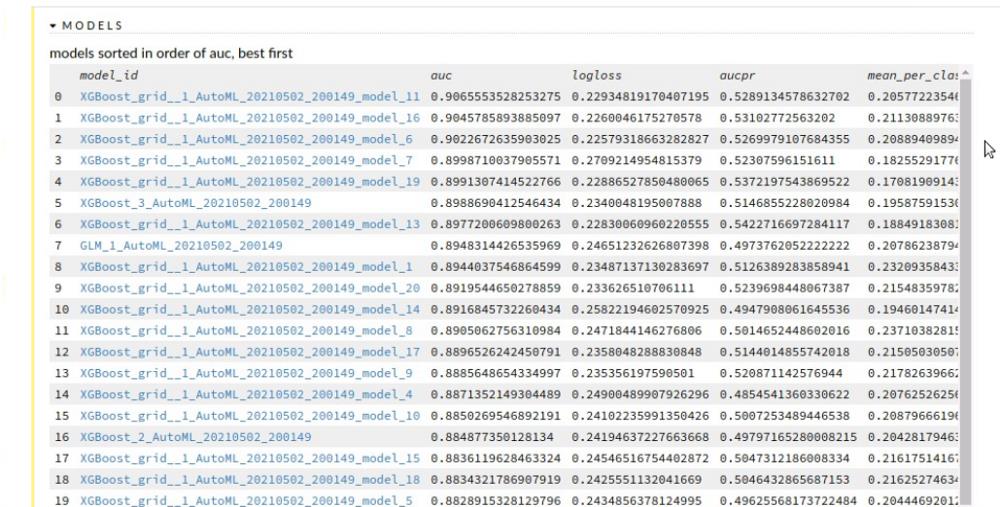
排行榜
AutoML 提供可用于模型探索的各种指标的可视化。我们可以点击曲线了解更多详情。

可视化
我们还可以检查变量的重要性。我们可以看到持续时间变量具有高度的预测性,并被该模型使用。
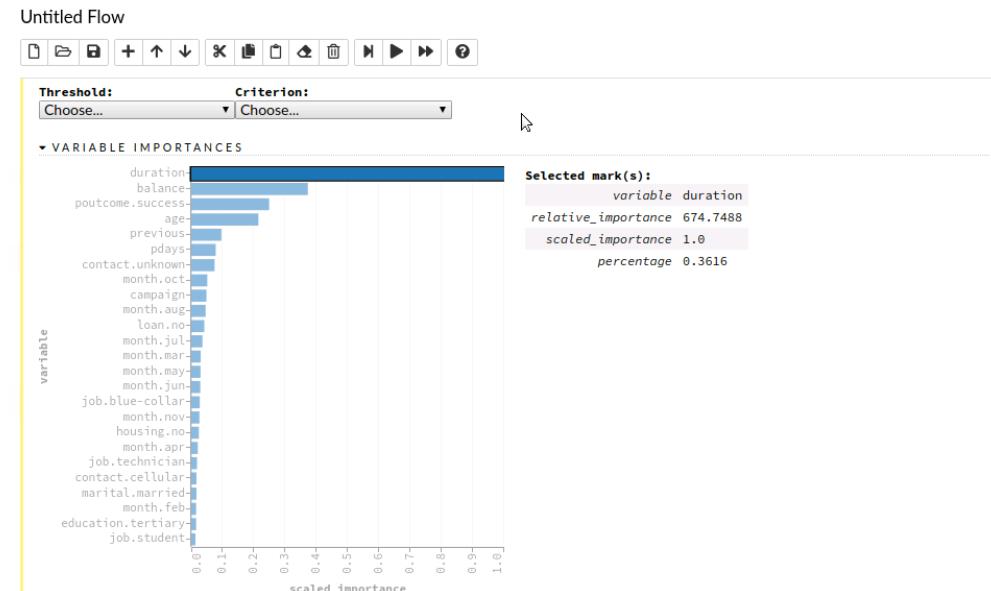
重要性
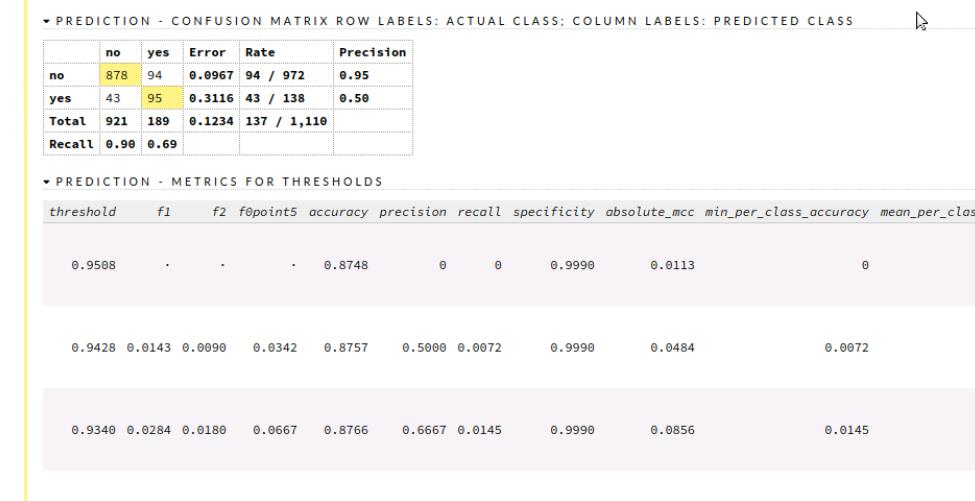
混淆矩阵提供了各种评价指标,例如相关性,因此也很重要。我们还可以突出显示特定变量并查看它们。
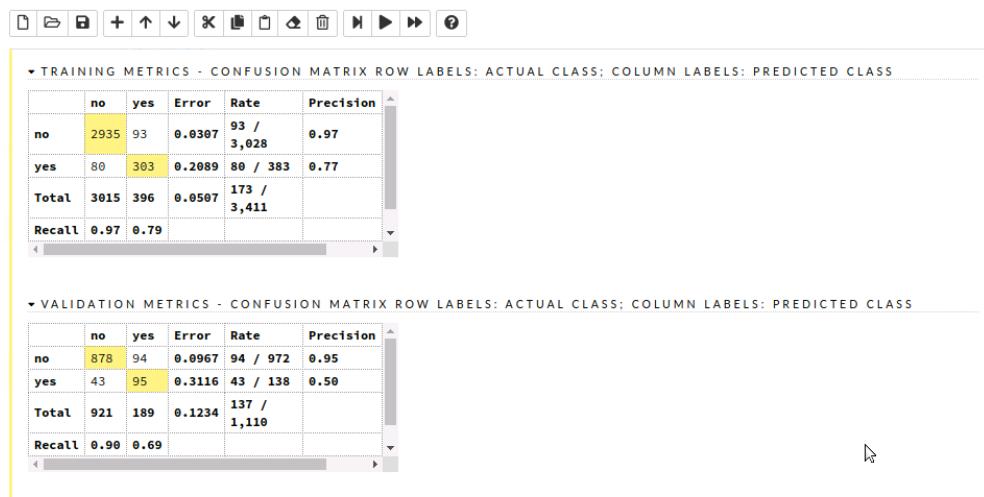
混淆矩阵
预测
在我们对所选模型感到满意后,我们可以继续进行预测。
首先从工具栏中选择预测选项,然后选择要使用的模型,然后选择验证框架。现在只需单击预测按钮,我们就可以查看预测值以及各种评估指标,例如均方误差。
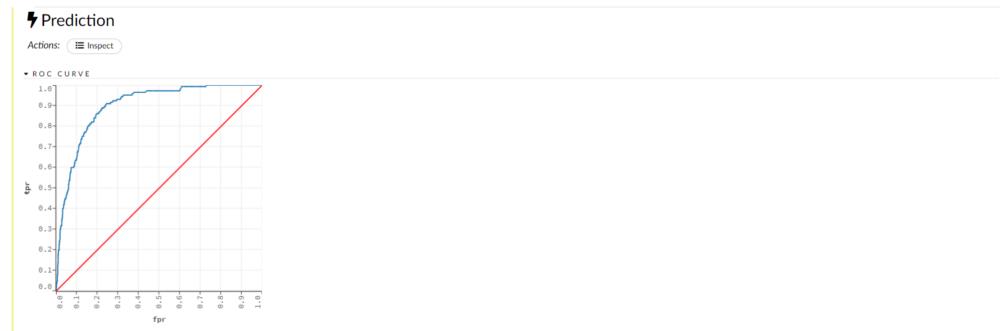

我们可以看到混淆矩阵并分析我们的结果以及各种指标和图形表示。

到这里,我们便成功学会了简单使用 基于 Web 的 UI 的 H2O Flow 中H2O,并且无需编写任何代码即可训练和可视化模型!通过本文的学习,简单了解和使用 AutoML 将机器学习建模可能会比较容易。但如果你希望更加深入地研究 H2O Flow ,我建议研究下官方文档。
推荐文章
以上是关于轻松玩转自动机器学习AutoML:H2O Flow的主要内容,如果未能解决你的问题,请参考以下文章