DRN :A Deep Reinforcement Learning Framework for News Recommendation论文解读
Posted 白水baishui
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DRN :A Deep Reinforcement Learning Framework for News Recommendation论文解读相关的知识,希望对你有一定的参考价值。
文章目录
1. 论文贡献
该论文提出了一个基于DQN的推荐框架,用于解决以下3个问题:
- 当前的推荐系统很难动态地推荐新闻
新闻的动态性表现在两个方面:(1)新闻的时效性强,新闻内容很容易过时;(2)用户对不同新闻的兴趣会随着时间的推移而不断变化。 - 当前的强化方法利用的用户反馈信息不足
大多数方法只将新闻是否被点击,或者用户对新闻的评分作为用户反馈,这是不够的。 - 当前的推荐系统总是向用户推荐类似的项目
如果推荐系统总是推送相同的东西,会导致用户的兴趣下降,因此需要提高推荐多样性。
解决方法是:
- 采用DQN的强化方法,可以综合考虑当前的奖励和未来的奖励;
- 将用户与应用程序的交互频率作为一种用户的主动反馈;
- 采用了DBGD(Dueling Bandit Gradient Descent)探索策略,用于随机选择浏览项附近的其他项目,既提升了推荐的多样性,同时这种探索策略可以避免推荐完全不相关的项目(例如, ϵ \\epsilon ϵ贪婪策略可能会推荐出完全不相关的项目),从而保持更好的推荐准确性。
2. 模型架构
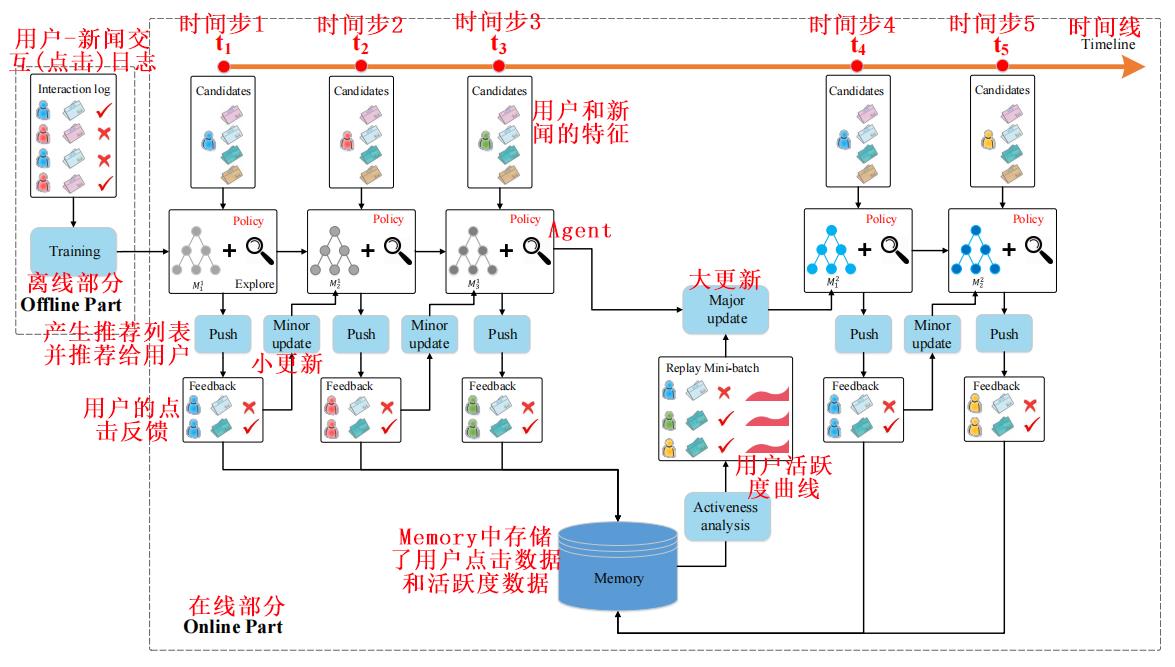
小更新只用用户点击数据对主网络和目标网络进行更新;
大更新同时用用户点击数据和用户活跃度对主网络进行更新。
2.1. 特征构造
论文构造了以下四个特征用于预测用户是否会点击一个特定的新闻:
- 新闻特征
新闻标题、供稿人、排名、实体名称、分类类别、主题类别,以及过去1小时、6小时、24小时、1周和1年的点击计数。 - 用户特征
用户分别在1小时、6小时、24小时、1周和1年内点击过的新闻及其特征。 - 用户-新闻交互特征
用户与某条新闻之间的交互记录。 - 上下文特征
用户获取新闻时的背景信息,包括时间、日期和新闻的新鲜度(请求新闻时间和新闻发布时间之间的差值)。
这些特征将作为状态
s
s
s 被输入DQN进行训练,但在本论文中,Q函数被设计为V函数(价值函数)与A函数(优势函数)的组合:
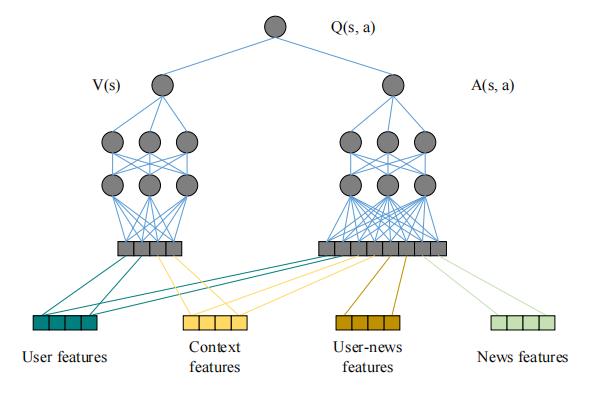
如图所示,用户特征和上下文特征被输入V函数,用户特征、上下文特征、用户-新闻交互特征和新闻特征被输入A函数。
优势函数 A ( s , a ) A(s,a) A(s,a) 表示在状态 s s s 下,某动作 a a a 做出后的价值相对于平均价值 V ( s ) V(s) V(s)而言的差值: A ( s , a ) = Q ( s , a ) − V ( s ) A(s,a)=Q(s,a)-V(s) A(s,a)=Q(s,a)−V(s) Q ( s , a ) = A ( s , a ) + V ( s ) Q(s,a)=A(s,a)+V(s) Q(s,a)=A(s,a)+V(s)把 Q Q Q值分为价值函数 V V V和优势函数 A A A来训练有助于提高策略的学习效率,更容易地发现那个动作 a a a 更好。
2.2. 深度强化学习模型
奖励公式定义为: y s , a = Q ( s , a ) = r i m m e d i a t e + γ r f u t u r e y_s,a=Q(s,a)=r_immediate+\\gamma r_future ys,a=Q(s,a)=rimmediate+γrfuture其中,状态 s s s 是上下文特征和用户特征 ;动作 a a a 是用户-新闻交互特征和新闻特征 ; r i m m e d i a t e r_immediate rimmediate 表示当前状态时的立即奖励(用户是否点击此新闻); r f u t u r e r_future rfuture 表示对未来奖励的预测; γ \\gamma γ 是折扣因子。
以上公式在DQN中表示为: y s , a , t = r a , t + 1 + γ Q ( s a , t + 1 , arg max a ′ Q ( s a , t + 1 , a ′ ; W t ) ; W t ′ ) y_s,a,t=r_a,t+1+\\gamma Q\\Bigl(s_a,t+1,\\argmax_a'Q(s_a,t+1,a';\\mathsfW_t);\\mathsfW_t'\\Bigr) ys,a,t=ra,t+1+γQ(sa,t+1,a′argmaxQ(sa,t+1,a′;Wt);Wt′)其中, r a , t + 1 r_a,t+1 ra,t+1表示采取动作 a a a 后获得的立即奖励, t + 1 t+1 t+1是因为奖励总是延迟一个时间步的; W t \\mathsfW_t Wt和 W t ′ \\mathsfW_t' Wt′分别的DQN的主网络和目标网络(探索网络)的参数; a ′ a' a′是DQN估计的在状态 s a , t + 1 s_a,t+1 sa,t+1时的动作;在一定次数的迭代后, W t ′ \\mathsfW_t' Wt′将被更新到 W t \\mathsfW_t Wt
2.3. 用户的主动反馈
论文将用户与应用程序交互的频率作为用户的主动反馈信息,与用户是否点击某些推荐项一起作为用户反馈信息。
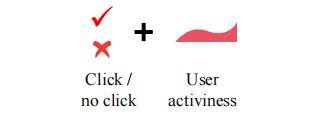
论文使用生存模型来建模用户的主动反馈。生存分析用于估计用户的返回时间,假设 t t t 是当前时间, T T T 是下一次用户返回的时间,那么衰减率可以被定义为: λ ( t ) = lim d t → 0 P r t ⩽ T < t + d t ∣ T ⩾ t d t \\lambda(t)=\\lim_\\mathsfdt\\to 0\\fracPr\\t\\leqslant T < t+\\mathsfdt\\quad|\\quad T\\geqslant t\\\\mathsfdt λ(t)=dt→0limdtPrt⩽T<t+dt∣T⩾t该公式表示当返回时间与当前时间的差值 T − t T-t T−t 越大时,衰减率越大;当 T − t T-t T−t 越小时,衰减率越小,即用户返回的概率越大。为了简化问题,论文设定 λ ( t ) \\lambda(t) λ(t)为一个固定的参数 λ 0 \\lambda_0 λ0,也就是每个用户的衰减率被定义为恒定值。
那么, t t t 时间后用户的活跃度可以定义为: S ( 0 ) = 0.5 S(0)=0.5 S(0)=0.5 S ( t ) = e − ∫ 0 t λ ( x ) d x ⩽ 1 S(t)=e^-\\int_0^t\\lambda(x)\\mathsfdx\\leqslant 1 S(t)=e−∫0tλ(x)dx⩽1
则用户活跃度从当前点降为0所用的时间 T 0 T_0 T0 (即用户存活期)可以表示为: T 0 = ∫ 0 ∞ S ( t ) d t T_0=\\int_0^\\infty S(t)\\mathsfdt T0=∫0∞S(t)dt
每当应用程序检测到用户的返回时,就将这个用户的活跃度加上一个特定值: S ( t ) = S ( t ) + S a S(t)=S(t)+S_a S(t)=S(t)+Sa。
论文将上述的几个参数分别设定为:
λ
0
=
1.2
×
1
0
−
5
\\lambda_0=1.2 \\times 10^−5
λ0=1.2×10−5每秒;
S
以上是关于DRN :A Deep Reinforcement Learning Framework for News Recommendation论文解读的主要内容,如果未能解决你的问题,请参考以下文章