Redis基础认识内存式NoSQL数据库及简单使用Redis
Posted 虎鲸不是鱼
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis基础认识内存式NoSQL数据库及简单使用Redis相关的知识,希望对你有一定的参考价值。
Redis基础(一)认识内存式NoSQL数据库及简单使用Redis
NoSQL与RDBMS
RDBMS就是关系型数据库管理系统,常见的mysql、SQL Server、Oracle就属于这种模型。∵可以体现数据之间的关系,支持事务,可以保证业务完整性和稳定性,小数据量时性能也较好,一般用作业务性数据存储系统。
但是!!!高并发时,分布式服务器的许多访问同时操作RDBMS,分分钟宕机。。。
此时就需要缓冲机制实现数据库的高并发。这些工具(Redis、HBase、MongoDB)就是NoSQL【不是字面的不是SQL,而是Not only SQL:非关系型数据库】,常用于高并发高性能场景下的数据缓存/数据库存储。
NoSQL读写速度非常快,并发量非常高,但是高并发是通过读写内存实现的,相对读写硬盘的RDBMS不稳定,对事务性的支持也不太友好。NoSQL的语法也不像SQL那么统一,每种SQL都有自己的语法和命令。
NoSQL可以实现读写分离,例如:
读请求:不读取MySQL,读取Redis;
写请求:直接写到MySQL。
由于正常情况大部分业务都是读多写少,读取不稳定但是写入稳定,总体来看稳定性影响不大,但是性能提升很大。当然必要时也可以使用另一个Redis缓冲,解决写入时的高并发。
Redis简介
Redis官网介绍Redis:
Redis is an open source (BSD licensed), in-memory data structure store, used as a database, cache, and message broker. Redis provides data structures such as strings, hashes, lists, sets, sorted sets with range queries, bitmaps, hyperloglogs, geospatial indexes, and streams. Redis has built-in replication, Lua scripting, LRU eviction, transactions, and different levels of on-disk persistence, and provides high availability via Redis Sentinel and automatic partitioning with Redis Cluster.
看不懂的可以看中文的。Redis有中文文档,对新手很友好:
Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。 它支持多种类型的数据结构,如 字符串(strings), 散列(hashes), 列表(lists), 集合(sets), 有序集合(sorted sets) 与范围查询, bitmaps, hyperloglogs 和 地理空间(geospatial) 索引半径查询。 Redis 内置了 复制(replication),LUA脚本(Lua scripting), LRU驱动事件(LRU eviction),事务(transactions) 和不同级别的 磁盘持久化(persistence), 并通过 Redis哨兵(Sentinel)和自动 分区(Cluster)提供高可用性(high availability)。
网站长的差不多,直接看中文的命令指导或者从中文网站下载,都没问题。
Redis是用地球最强的C语言写的,可以操作硬件,性能很好。且是基于内存实现数据的读写,读写很快。其是分布式的,拓展性和稳定性很好。支持事务,拥有各种丰富的数据结构。
数据库用于永久性存储,大数据领域可以将高性能读写结果存储/采集在HDFS中。
缓存是临时性存储,在业务系统中缓存可以避免数据库性能不够引发的宕机。
消息中间件也就是消息队列MQ,Redis一般不用。
数据结构
Redis的所有数据都是以KV键值对的形式存在的。
K作为唯一标识符,唯一标识一条数据,固定为String类型。
V真正存储数据,有多种类型(String、Hash、List、Set、Zset、BitMap、HypeLogLog)。
Redis类似Java中的Map集合:
Map<String,T> = Redis存储
写就是指定KV,读只需要给定K。
数据类型
举个栗子:
| Key | Value类型 | Value值 | 应用场景 |
|---|---|---|---|
| pv_20200101 | String | 10000 | 一般用于存储单个数据指标的结果 |
| person001 | Hash | name:laoer,age:20 sex female | 用于存储整个对象所有属性值 |
| uv | List | 100,200,300,100,600 | 有序允许重复的集合,每天获取最后一个值 |
| uv_20200101 | Set | userid1,userid2,userid3,userid4…… | 无序且不重复的集合,直接通过长度得到UV |
| top10_product | Zset | 10000-牙膏,9999-玩具,9998-电视…… | 有序不可重复的集合,统计TopN |
| user_filter | BitMap | 0101010101010000000011010 | 将一个字符串构建位,通过0和1来标记每一位 |
| product_20200101 | HyperLogLog | productid1,id2…… | 类似于Set集合,底层实现原理不一样,数据量大的情况下,性能会更好 |
String类型
KV:【String,String】,类似于Java中Map集合的一条KV。
Hash类型
KV:【String,Map集合】:Map集合的嵌套,Map集合中的元素是无序的:
K V
person1 name=zhangsan,age=18,sex=1,addr=shanghai
person2 name=lisi,age=18,sex=1,addr=shanghai
List类型
KV:【String,List】:有序且可重复。
Set类型
KV:【String,Set】:无序且不重复。
Zset类型
KV:【String,TreeMap集合】:Value也类似于Map集合,但是TreeMap是有序的Map集合,故Zset是有序且不可重复的。
命令
通用命令
keys:列举当前数据库的所有key:
keys * 列举所有key
keys a* 列举所有a开头的key
del K:删除某个key:
del s1 删除key=s1的KV键值对
exists K:判断某个key是否存在:
exists s1 判断是否有s1这个键存在
type K:判断某个key对应的value的类型(key都是String类型的,这条命令当然也就不是判断key自己的类型):
type s1 判断key=s1的键值对的value的类型
expire K t(过期时间):设置某个key的过期时间(计时结束后该kv对会被自动删除):
expire s1 10 10秒后删除s1的键值对
ttl K:查看某个key剩余的存活时间(倒计时场景经常用):
ttl s1 查看s1的kv对的剩余存活时间,删除后再次执行是负数
select N:切换数据库:
select 1 切换数据库为db1
move K N:将某个kv对移动到某个数据库中:
move s1 1 将(默认db0,切换后为当前db)数据库中的s1的键值对数据移动到db1中
flushdb:清空当前数据库的所有key。
flushall:清空所有数据库的所有key。
String类型的常用命令
set:给String类型的Value的进行赋值或者更新:set K V;
get:读取String类型的Value的值:get K;
mset:用于批量写多个String类型的KV:mset K1 V1 K2 V2 ……;
mget:用于批量读取String类型的Value:mget K1 K2 K3 ……;
setnx:只能用于新增数据,当K不存在时可以进行新增(搭配expire来使用,可以构建抢占锁):setnx K V;
incr:用于对数值类型的字符串进行递增,递增1:incr K;
incrby:指定对数值类型的字符串增长固定的步长:incrby K N;
decr:对数值类型的数据进行递减,递减1:decr K;
decrby:按照指定步长进行递减:decrby K N;
incrbyfloat:基于浮点数递增(C语言浮点数会丢失精度):incrbyfloat K N;
strlen:统计字符串的长度:strlen K;
getrange:用于截取字符串:getrange s2 startnum endnum;
Hash类型的常用命令
hset:用于为某个K添加一个属性:hset K k v;
hget:用于获取某个K的某个属性的值:hget K k;
hmset:批量的为某个K赋予新的属性:hmset K k1 v1 k2 v2 ……;
hmget:批量的获取某个K的多个属性的值:hmget K k1 k2 k3……;
hgetall:获取所有属性的值:hgetall K;
hdel:删除某个属性:hdel K k1 k2 ……;
hlen:统计K对应的Value总的属性的个数:hlen K;
hexists:判断这个K的V中是否包含这个属性:hexists K k;
hvals:获取所有属性的value:hvals K;
List类型的常用命令
lpush:将每个元素放到集合的左边,左序放入:lpush K e1 e2 e3……;
rpush:将每个元素放到集合的右边,右序放入:rpush K e1 e2 e3……;
lrange:通过下标的范围来获取元素的数据(从左往右的下标从0开始【0 5】,从右往左的下标从-1开始【-5 -1】,∴一定是从小的到大的下标:lrange K 0 -1:所有元素):lrange K startnum endnum;
llen:统计集合的长度:llen K;
lpop:删除左边的一个元素:lpop K;
rpop:删除右边的一个元素:rpop K;
Set类型的常用命令
sadd:添加元素到Set集合中:sadd K e1 e2 e3 e4 e5……;
smembers:查看Set集合的所有成员:smembers K;
sismember:判断是否包含这个成员:sismember K e1;
srem:删除其中某个元素:srem K e;
scard:统计集合长度:scard K;
sunion:取两个集合的并集:sunion K1 K2;
sinter:取两个集合的交集:sinter K1 K2;
Zset类型的常用命令
zadd:用于添加元素到Zset集合中:zadd K score1 k1 score2 k2 ……;
zrange:范围查询(默认按照key的降序排列,使用withscores会显示key的内容):zrange K start end [withscores];
zrevrange:倒序查询:zrevrange K start end [withscores];
zrem:移除一个元素:zrem K k1;
zcard:统计集合长度:zcard K;
zscore:获取评分(获取value对应的key):zscore K k;
BitMap类型的常用命令
通过一个String对象的存储空间来构建位图,每位(bit)当然只能表示0/1。学过嵌入式的都很容易理解:
Redis的一个String最大为512MB(512MB也就是2^(9+10+10)Byte,再*8换算后为2^(9+10+10+3)bit,换句话说,Redis的String是32位的,不是64位或者8位16位。32位(西门子PLC称之VW,双字)=4字节(西门子PLC称之VB,字节)。
和数组的下标一样,BitMap也是从0开始的(不需要关心大小端的问题),使用时,每一位默认都=0,也可以直接操作使得置0和置1。C语言可以直接操作寄存器的好处就体现出来了!!!如果使用位图的某一位来对应用户id,读取数据时,发现用户id就将该id对应的的那一位置位,结束后计数位图中1的个数就是UV!!!也不需要SQL中DISTINCT去重!!!
setbit:修改某一位的值:set K 脚标 1;
getbit:查看某一位的值:getbit K 角标;
bitcount:统计位图中1的个数(2个脚标是字节数):bitcount K startnum endnum;
bitop:位图的按位运算(and与、or或、not取反、xor异或):bitop and bit3 bit1 bit2是把bit1和bit2相与的结果放到bit3;
HyperLogLog类型的常用命令
对!!!没看错,就是2个Log。
HyperLogLog类似Set集合,用于实现数据的去重,但是底层实现原理不同,适合于大数据量的情况下使用(存在误差率)。
pfadd:添加元素:pfadd K e1 e2 e3......;
pfcount:统计个数:pfcount K;
pfmerge:实现集合合并:pfmerge pfrs K1 K2......;
Windows版Redis
部署
随便找个Redis低版本的试试,测试用,哪个版本都差不多。
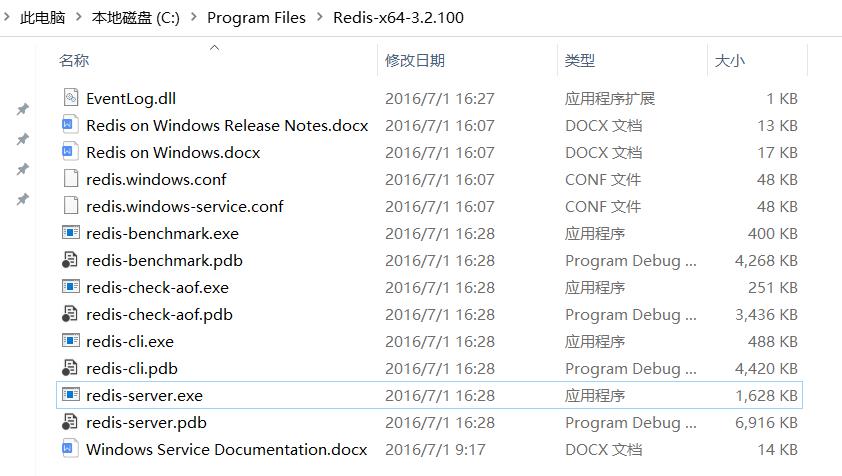
搞到手的是个Zip包,和常规的软件一样,解压缩就能用。。。笔者选择解压到C盘,路径纯英文即可。里边有这些玩意儿:
| 目录/文件 | 备注 |
|---|---|
| redis-benchmark.exe | redis的性能测试工具 |
| redis-check-aof.exe | aof文件的检查和修复工具 |
| redis-check-dump.exe | rdb文件的检查和修复工具 |
| redis-cli.exe | client 客户端访问命令 |
| redis-server.exe | 服务器启动程序 |
| redis.window.conf | 配置文件,这是个文本文件 |
测试
当然是先启动server才能启动client。。。先双击redis-server.exe,首次使用Win10会阻挠,需要同意使用网络:

发现Redis使用的是6379端口。如果服务端闪退,就搞个bat脚本强制按照配置文件的内容来启动:
redis-server.exe redis.windows.conf

这个脚本需要放到解压的文件夹里才能正常使用,都懂的。。。
双击redis-cli.exe可以启动客户端:

很“智能”,刚输入set就提醒可以修改后边的参数。。。比shell体验好多了。。。
127.0.0.1:6379> set s1 hadoop
OK
127.0.0.1:6379> keys *
1) "s1"
127.0.0.1:6379> set s2 hive
OK
127.0.0.1:6379> keys *
1) "s1"
2) "s2"
127.0.0.1:6379> get s1
"hadoop"
127.0.0.1:6379> get s2
"hive"
127.0.0.1:6379>
keys * 就是SQL中的SELECT*。
桌面工具
这年头连SQLite都有很多客户端,Redis当然也有很多种客户端(Redis Desktop Manager、RedisStudio、RedisClient等),笔者随便玩玩:
正常的下一步安装。。。
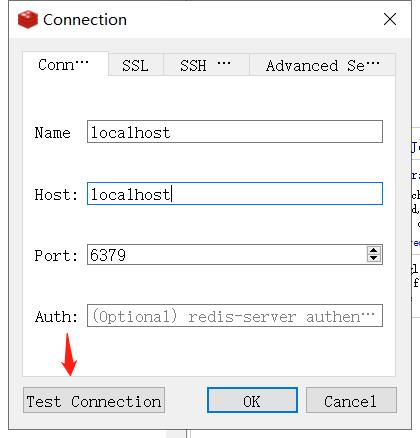
选用连接本机(localhost就是127.0.0.1),之后就出现了和SQLite Studio的差不多的树形结构:

可以看出Redis默认有db0~db15攻击16个数据库,且默认使用的是db0数据库,也能看到之前配置的数据。
一般是Linux用Redis,Windows貌似用的不多。。。
Linux版Redis
部署
先安装到一台机再说。上传安装包:
cd /export/software/
rz
解包:
tar -zxvf redis-3.2.8.tar.gz -C /export/server/
由于Redis是地球最强的C语言写的,不是Java的那种跨平台通用的Jar包,需要编译才能用,使用yum安装gcc依赖以便使用gcc编译:
yum -y install gcc-c++ tcl
安装好gcc就可以编译:
cd /export/server/redis-3.2.8/
make
安装:
make PREFIX=/export/server/redis-3.2.8-bin install
修改配置:
cp /export/server/redis-3.2.8/redis.conf /export/server/redis-3.2.8-bin/
mkdir -p /export/server/redis-3.2.8-bin/logs
mkdir -p /export/server/redis-3.2.8-bin/datas
cd /export/server/redis-3.2.8-bin/
vim redis.conf
然后小心地修改4处,使Redis可以使用网卡(61行)、后台运行(128行)、存储服务器日志(163行)、持久化数据存储(247行):
bind node1
daemonize yes
logfile "/export/server/redis-3.2.8-bin/logs/redis.log"
dir /export/server/redis-3.2.8-bin/datas/
记得保存。
创建软连接(类似Win的快捷方式)以便调用及修改:
cd /export/server
ln -s redis-3.2.8-bin redis
配置环境变量:
vim /etc/profile
找个空行插入:
# REDIS HOME
export REDIS_HOME=/export/server/redis
export PATH=:$PATH:$REDIS_HOME/bin
先保存,再重新加载环境变量:
source /etc/profile
OK,配置完成,试试能不能用。
启动
服务端
国际惯例,先启动服务端:
/export/server/redis/bin/redis-server /export/server/redis/redis.conf
当然也可以自己写个shell脚本,就不必这么麻烦:
vim /export/server/redis/bin/redis-start.sh
写上内容:
#!/bin/bash
REDIS_HOME=/export/server/redis
$REDIS_HOME/bin/redis-server $REDIS_HOME/redis.conf
增加可执行权限:
chmod u+x /export/server/redis/bin/redis-start.sh
由于配置了环境变量,任意目录都可以调用脚本:
[root@node1 server]# cd
[root@node1 ~]# redis-
redis-benchmark redis-check-aof redis-check-rdb redis-cli redis-sentinel redis-server redis-start.sh
[root@node1 ~]# redis-start.sh
启动后:
[root@node1 ~]# ps -ef |grep redis
root 5110 1 0 17:48 ? 00:00:00 /export/server/redis/bin/redis-server node1:6379
root 5118 1772 0 17:48 pts/0 00:00:00 grep --color=auto redis
可以看到相关的进程(6379端口的进程就是Redis的服务端)。
客户端
/export/server/redis/bin/redis-cli -h node1 -p 6379
启动后:
[root@node1 ~]# /export/server/redis/bin/redis-cli -h node1 -p 6379
node1:6379>
同意很“智能”:

简单试试:
node1:6379> keys *
(empty list or set)
node1:6379> set s1 hadoop
OK
node1:6379> keys *
1) "s1"
node1:6379> get s1
"hadoop"
和Win10上测试的效果一致,安装成功。
关闭
客户端
对话框输入exit就可以退出。
服务端
客户端可以使用命令shutdown让服务端关闭(注意!!!是Redis客户端中输入命令,不是shell中shutdown关机)。如果一定要要shell中关闭,可以:
/export/server/redis/bin/redis-cli -h node1 -p 6379 shutdown
这种方式其实也是通过客户端实现的关闭。
如果先关闭了客户端,也有办法关闭服务端。。。惯用的当然是先找到Redis对应的服务端的pid再kill -9(手动2步)。或者高端的做法(Linux中一切皆文件,运行中的进程也在文件中有记录,直接从文件中抓获进程号即可):
kill -9 `cat /var/run/redis_6379.pid`
如果不是root用户,可能有权限级别不够的问题,sudo开头即可(玩树莓派和Ubuntu那会儿好像每一句都是sudo开头。。。):
sudo cat /var/run/redis_6379.pid
可以看到进程号。
当然大部分情况下不可能手动写命令,用类似JDBC的方式使用编程语言自动调用命令显然更高效。下一篇讲述Jedis。
 超强干货来袭
超强干货来袭
 云风专访:近40年码龄,通宵达旦的技术人生
云风专访:近40年码龄,通宵达旦的技术人生
以上是关于Redis基础认识内存式NoSQL数据库及简单使用Redis的主要内容,如果未能解决你的问题,请参考以下文章