MySQL--5--subquery和连接
Posted zx0801
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL--5--subquery和连接相关的知识,希望对你有一定的参考价值。
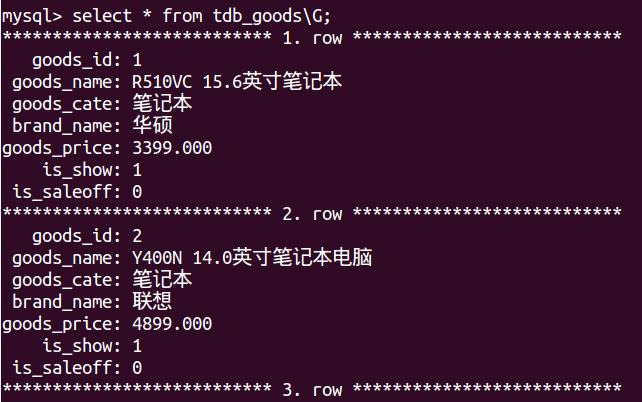
1.子查询
是指出现在其他SQL语句内的select子句
形式: SELECT * FROM T1 WHERE COL1=(SELECT COL2 FROM T2);
其中,select * from t1 称为外部查询(注意,不仅限于select 语句,包括SELECT、INSERT、UPDATE、DELETE)
(SELECT COL2 FROM T2)称为子查询:
| 子查询指嵌套在查询内部,且必须始终出现在小括号内; |
| 子查询可以包含多个关键字或条件,包括SELECT GROUP BY/ORDER BY/LIMIT |
|
外部查询可以是INSERT、SELECT、UPDATE、DELETE、SET、DO…… |
| 子查询的返回值可以是标量、一行、一列、一个表(子子查询) |
1.1 使用子查询进行比较
比较运算符: < 、> = <= >= !=
一般形式:select 字段1[as b],字段2,…… from where 字段3/字段3表达式’ >=运算符(子查询表达式--select 字段3/字段3表达式 from ……where ……);
selectCode,Name,Region,Continent,LifeExpectancyfrom country whereLifeExpectancy>=(select round(avg(LifeExpectancy),1)from country) order byLifeExpectancy desc;
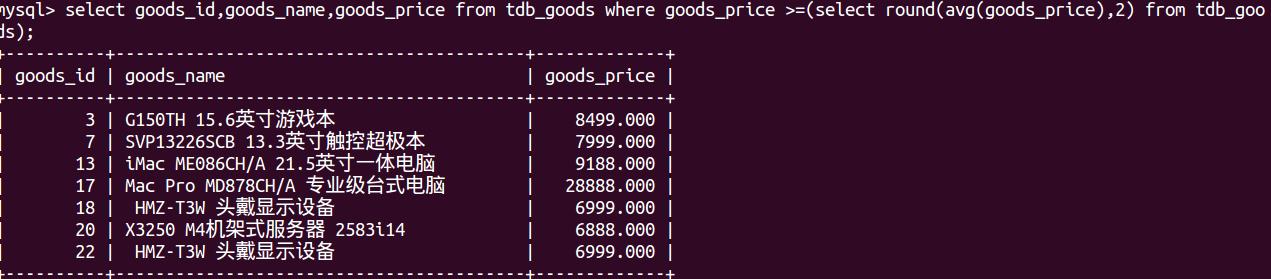
select goods_id,goods_name,goods_price from tdb_goods where goods_price >=(select round(avg(goods_price),2) from tdb_goods); ##avg 是一个聚合函数,只有一个值
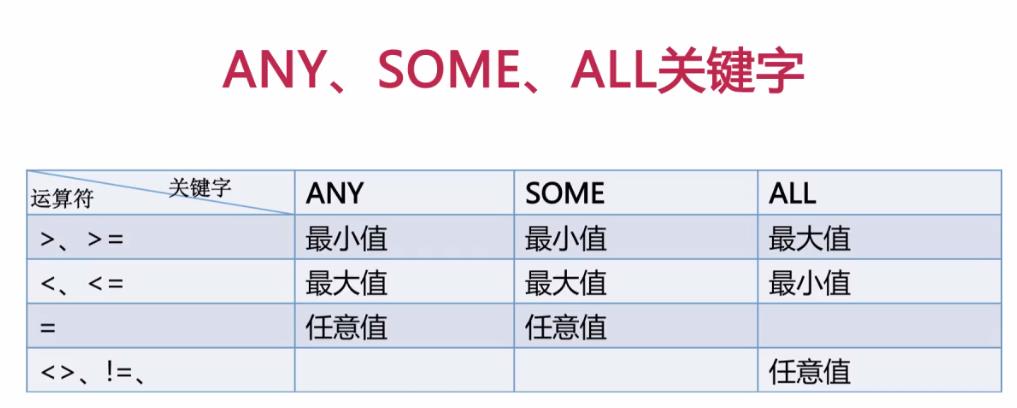
当子查询返回的包含多个结果时,需要用ANY、SOME、ALL 做修饰:其中SOME和ANY是一样的,
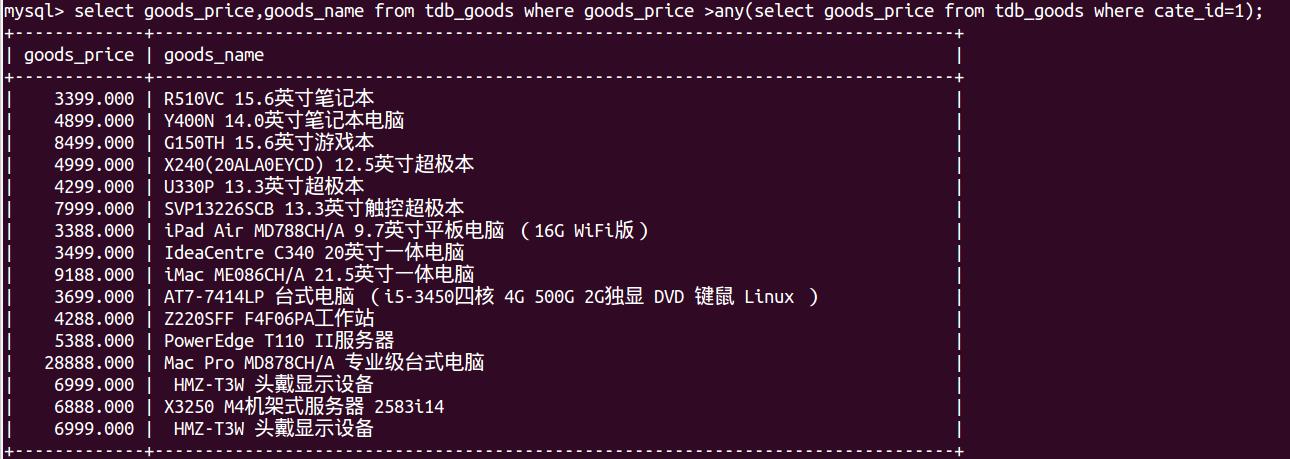
select goods_price,goods_name,goods_id from tdb_goods where goods_price > any (select goods_price from tdb_goods where goods_cate=\'超级本\'); # any 此处是指只要大于任意符合条件的价格就可以,(就是大于最小的)。若为all。则是大于最大的
-
select goods_price,goods_name from tdb_goods where goods_price !=all(select goods_price from tdb_goods where cate_id=1); -
select goods_price,goods_name from tdb_goods where goods_price =all(select goods_price from tdb_goods where cate_id=1);

1.2 使用【NOT】IN的子查询
…… 【NOT】IN (subquery)
=ANY与IN等价;
!=ALL与NOTIN等价
1.3 insert ……select
使用的子查询:
表中可能有很多重复的信息,比如多条记录中的品牌、类型是一样的,因为记录可能无穷多,并且汉字占的空间多。因此数据表庞大查询速度很慢。因此需要做一张数据表存储品牌或者分类,进行关联和原数据表的瘦身。
第一步:
创建品牌表:
create table brands(brand_id smallint unsigned key auto_increment,bname varchar(40)notnull);
create table goods_cates(cate_id smallint unsigned key auto_increment,cate_name varchar(40) not null);
第二步:
将tdb_goods中的goods_brand 和goods_cate 分别插入到对应的数据表:
insert goods_cate(cate_name) select goods_cate from tdb_goods group by goods_cate;insert brands(bname) select goods_cate from tdb_goods group by goods_cate;
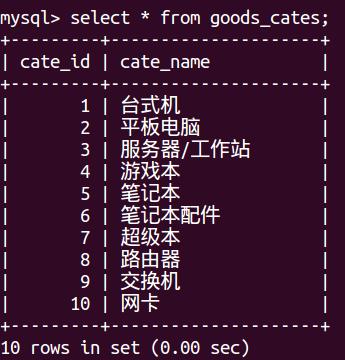
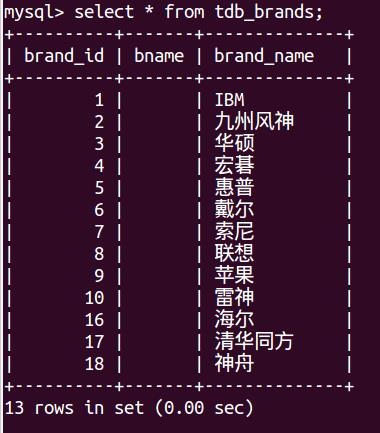
第三步:多表更新--与原tdb_goods 创建连接更新--参照分类表、品牌表更新原表,用cate_id 和brand_id 代替相应的中文
形式:UPDATE table_reference SET col1={expr|default},……,[WHERE ……]
update tdb_goods inner join brands on goods_brand=brand_name set goods_brand=brand_id;updatetdb_goods inner join tbd_cates on goods_cate=cate_name set goods_cate=cate_id;update tdb_goods inner join brands on goods_brand=brand_name set goods_brand=brand_id inner join tbd_cates on goods_cate=cate_name set goods_cate=cate_id;## 试下对不对,明天
table_reference 表的参照关系,由于是多表,就是多表之间的连接。
table_reference可以是table1 [[AS] 别名1]或者是table1_subquery [[AS] 子查询的别名]
连接的结构:
table_reference1 连接类型 table_reference2 ON 连接条件
连接类型:
| 内连接---INNER JOIN | -连接两张表中都有的,交集 |
| 外链接--左/右外连接 LEFT/RIGHT [OUTER] JOIN | 左边表的全部+右边表符合条件的/右边表的全部+左边表符合条件的 |
简洁的写法:
创建和写入一步更新(第一步和第二步):CREATE TABLE table_name(字段 属性) SELSECT col FROM table_name expr;
-
create tabletdb_cates (cate_id smallint unsigned key auto_increment,cate_name varchar(40) not null) select cate_name from tdb_goods group by cate_name;##因为id 是自动编号的,因此可以不用管,只选择cate_name字段的值加插入到tdb_cates的cate_name字段(选择出的字段名和要要插入的表的字段名最好一样,不然就另起一列添加了,如下图1,或者创建的时候只定义id字段/如下图2:)
-
create table tdb2_brands(brand_id smallint unsigned key auto_increment) select brand_name from tdb_brands group by brand_name;
create table tdb_brands(brand_id smallint unsigned key auto_increment,bname varchar(40) not null) select brand_name from tdb_goods group by brand_name;(列名不一样)
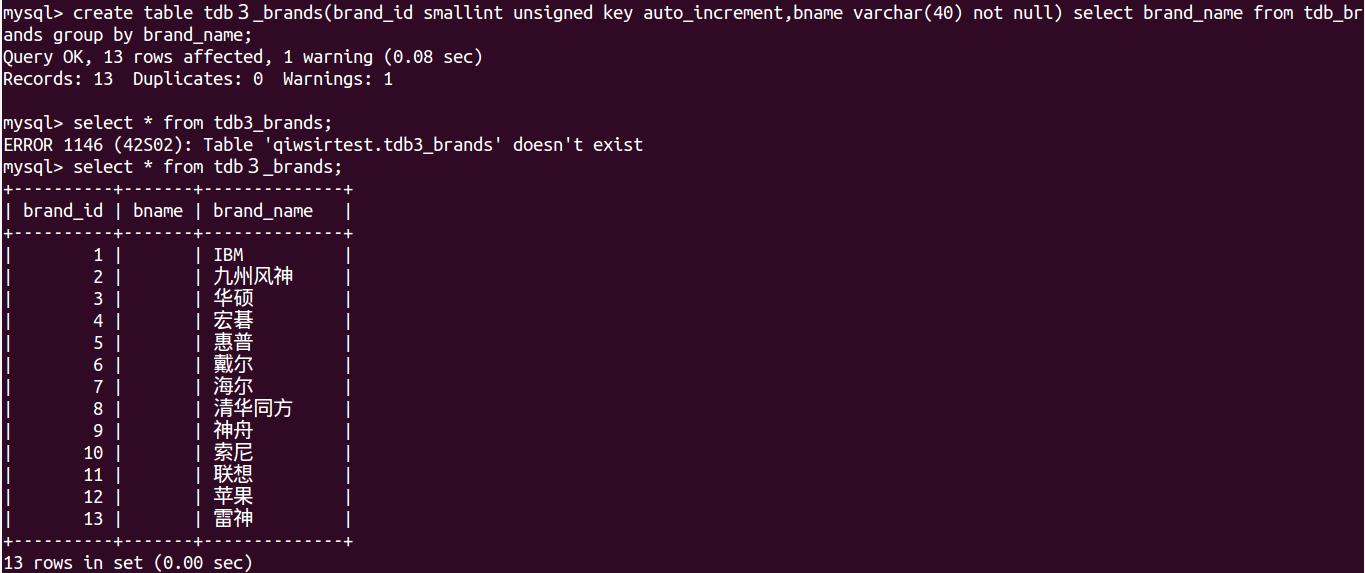
创建时省略列名,直接用插入的列名
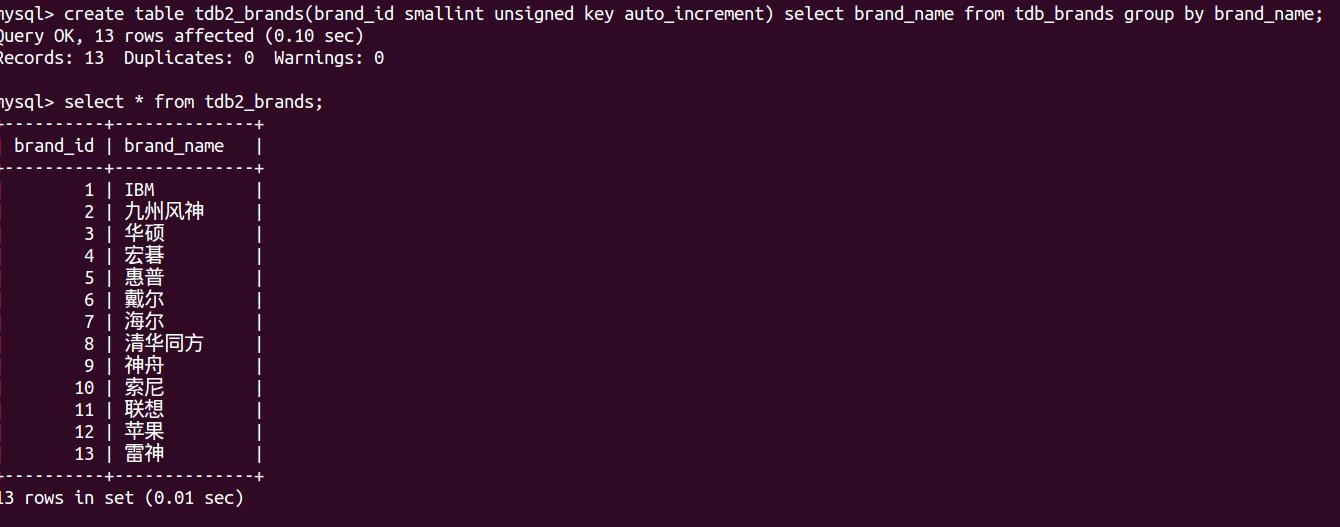
第三步连接:当然因为要连接的两张表的品牌名称字段是一样的,因此要加表名做前缀或者给表其别名,如果字段是唯一的不会引起混淆则不需要:
update tdb_goods as tg inner join tdb_cates as tc on tg.cate_name=tc.cate_name set cate_name=cate_id;
品牌表的一步更新:
create table tdb_brands(brand_id smallint unsigned key auto_increment,bname varchar(40) not null) select brand_name from tdb_goods group by brand_name; ##创建品牌表并且插入查询到的品牌名称update tdb_goods as tg inner join tdb_brands as tb on tg.brand_name=tb.brand_name set tg.brand_name=tb.brand_id;##连接原表和品牌表,并更新原表
接下来。虽然品牌和类型字段的中文表示都由其对应的参考表的编号代替了,但是tdb_goods的brand_name和cate_name的字段属性在最初定义的时候依旧还是字符类型,因此要修改为相应的int类型,:
alter tabletdb_goods change goods_cate cate_id smallint unsigned not nill,change goods_brand brand_id smallint unsigned not null;##原字段名1 新字段名1及其属性,……
select goods_id,goods_name,goods_price,brand_name,cate_name from tdb_goods inner join goods_cates as gc on gc.cate_id=tdb_goods.cate_id inner join tdb_brands as tb on tb.brand_id=tdb_goods.brand_id\\G;
alter table tdb_goods change goods_cate cate_id smallint unsigned not null, change goods_brand brand_id smallint unsigned nut null;
自身连接:
1.无限极分类---:同一个数据表对其自身进行连接,必须起别名。
很多数据库底下有很多很小的分类,例如生活电器下面有厨房电器和家具电器之类的,而厨房电器下面又分为电饭煲、微波炉之类的。底下可能又会具体分为很多类

如要查找表中各个名字的父类是谁。想象 左右一张相同的表 右边为子表 左边为父表
父表的第三列就没有用,
a.若我想查看子表中的条目对应的父表条目是谁,则子表中的条目应该都出现:
select s.type_id,s.type_name,p.type_name from tdb_goods_types as p right join tdb_goods_types as s on p.type_id=s.parent_id;##子表s中的条目要全部出现,因此连接要选择join右边s的方位,即右连接;

b.若想查看父类条目下都有哪些子类,则父类的条目要全部出现,:
select p.type_id,p.type_name,s.type_name from tdb_goods_types as p left join tdb_goods_types as s on s.parent_id=p.type_id;

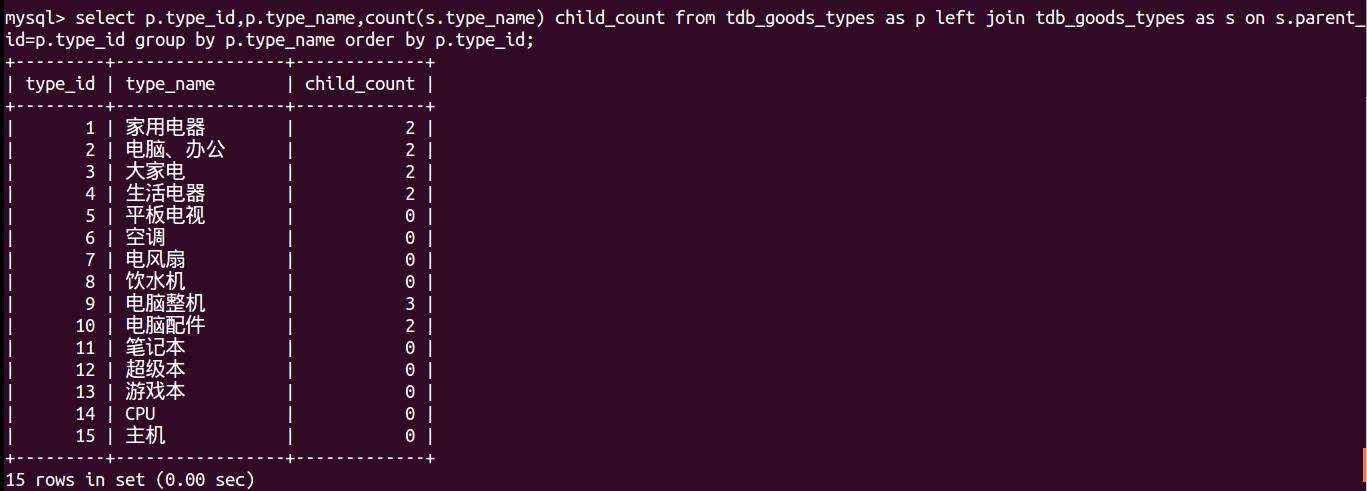
b.1 若想查看父类下的子类的数目而不是子类的具体,则:
select p.type_id,p.tyoe_name,count(s.type_name) child_count from tdb_goods_types as p left join tdb_goods_types as s on s.parent_id=p.type_name group by p.type_id order by p.type_id;##先做了一个左连接,然后对查询结果按照父类的type_name做了分组,分组的顺序按照p.type_id的顺序,并且计算了父类下面子类的数目,(注意其表达方式)
2.多表删除:删除表中重复的记录,保留ID较小的记录。
首先,查找重复记录:
select goods_id,goods_name from tdb_goods group by goods_id;##将所有的记录查看
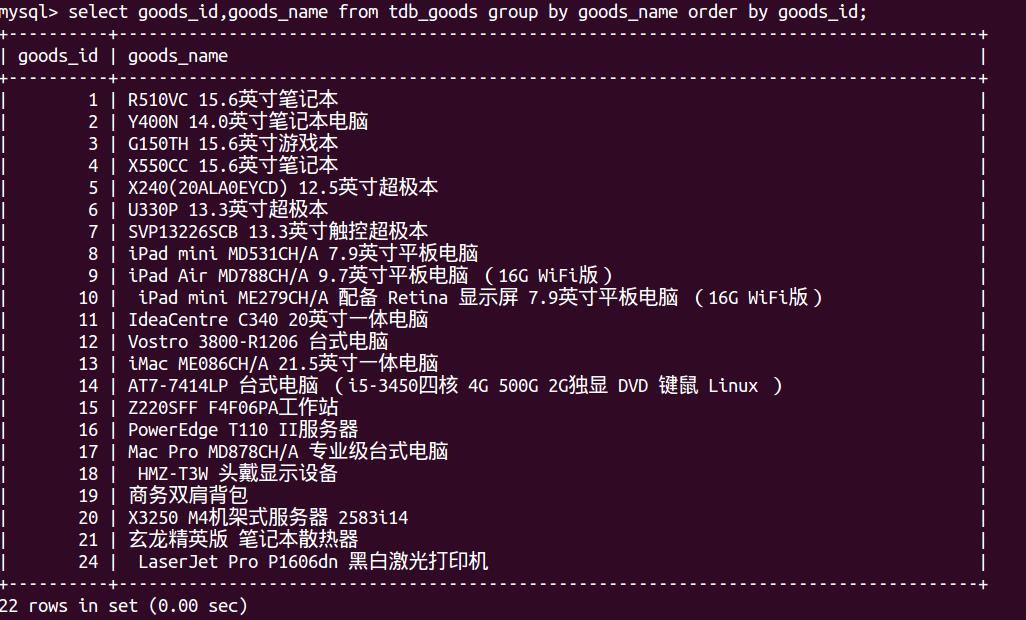
可以看到,原表表中一共24条记录,但是查询出来的只有22个,因为有重复的商品名称(22、23).
查询父类下对应子类的总数:
select goods_name,count(goods_id) name_count from tdb_goods group by goods_name order by goods_id;

单独挑出有两条或者两条以上的记录:
select goods_name,count(goods_id) name_count,goods_id from tdb_goods group by goods_name having name_count >=2 order by goods_id;


多表删除:DELETE tbl_name1,[tbl2_name,~~~] FROM tbl_references [WHERE where_condition]
下面也是用单表模拟多表删除重复的操作,运用了自身连接--
上表即为我们接下来要删除/保留的表了。
首先,从哪张表中删除(引用别名t1),然后就连接上图中的表--用子查询获取,(引用别名t2),连接的条件是名称相同,但是相同的不是都删除,而是删除id号比较大的记录(上表中的id 号都是相同名称下的小id)。
deletet1 fromtdb_goods as t1left join(select goods_id,goods_name from tdb_goods group by goods_name having count(goods_id) >=2) as t2ont1.goods_name=t2.goods_name where t1.goods_id >t2.goods_id;-
##小括号中的子查询语句即为我们上一步得出的有两条重复以上的记录。黑色加粗字体是多表删除的框架,删除的是id号较大的重复记录;红色字体的部分--左连接整体是作为参照表,连接的条件是两张表的name相同;绿色底色的部分--子查询整体是连接的右表,子查询返回的结果有两条重复以上的记录,

可以看到,删除后只有22条记录,即22和23号的重复记录都被删除了!
CREATE TABLE tdb_goods_types( type_id SMALLINT UNSIGNED PRIMARY KEY AUTO_INCREMENT, type_name VARCHAR(20) NOT NULL, parent_id SMALLINT UNSIGNED NOT NULL DEFAULT 0 );
以上是关于MySQL--5--subquery和连接的主要内容,如果未能解决你的问题,请参考以下文章
DEPENDENT SUBQUERY” 和 “SUBQUERY”
连接MySQL出现错误:ERROR 1045 (28000): Access denied for user ‘root‘@‘localhost‘ (using password: YES)(代码片段