redis缓存数据库
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了redis缓存数据库相关的知识,希望对你有一定的参考价值。
缓存数据库介绍
NoSQL(NoSQL = Not Only SQL ),意即“不仅仅是SQL”,泛指非关系型的数据库,随着互联网web2.0网站的兴起,传统的关系数据库在应付web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。NoSQL数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题。
NoSQL数据库的四大分类
NoSQL数据库的四大分类表格分析
redis
介绍
redis是业界主流的key-value nosql 数据库之一。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
Redis优点
-
异常快速 : Redis是非常快的,每秒可以执行大约110000设置操作,81000个/每秒的读取操作。
-
支持丰富的数据类型 : Redis支持最大多数开发人员已经知道如列表,集合,可排序集合,哈希等数据类型。
这使得在应用中很容易解决的各种问题,因为我们知道哪些问题处理使用哪种数据类型更好解决。 -
操作都是原子的 : 所有 Redis 的操作都是原子,从而确保当两个客户同时访问 Redis 服务器得到的是更新后的值(最新值)。
-
MultiUtility工具:Redis是一个多功能实用工具,可以在很多如:缓存,消息传递队列中使用(Redis原生支持发布/订阅),在应用程序中,如:Web应用程序会话,网站页面点击数等任何短暂的数据;
安装Redis环境
$sudo apt-get update $sudo apt-get install redis-server
启动 Redis
$redis-server
查看 redis 是否还在运行
$redis-cli
redis 127.0.0.1:6379>
redis 127.0.0.1:6379> ping PONG
Redis API使用
redis-py 的API的使用可以分类为:
- 连接方式
- 连接池
- 操作
- String 操作
- Hash 操作
- List 操作
- Set 操作
- Sort Set 操作
- 管道
- 发布订阅
连接方式
1、操作模式
redis-py提供两个类Redis和StrictRedis用于实现Redis的命令,StrictRedis用于实现大部分官方的命令,并使用官方的语法和命令,Redis是StrictRedis的子类,用于向后兼容旧版本的redis-py。
|
1
2
3
4
5
|
import redis r = redis.Redis(host=‘10.211.55.4‘, port=6379)r.set(‘foo‘, ‘Bar‘)print r.get(‘foo‘) |
2、连接池
redis-py使用connection pool来管理对一个redis server的所有连接,避免每次建立、释放连接的开销。默认,每个Redis实例都会维护一个自己的连接池。可以直接建立一个连接池,然后作为参数Redis,这样就可以实现多个Redis实例共享一个连接池。
操作
1. String操作
redis中的String在在内存中按照一个name对应一个value来存储。如图:
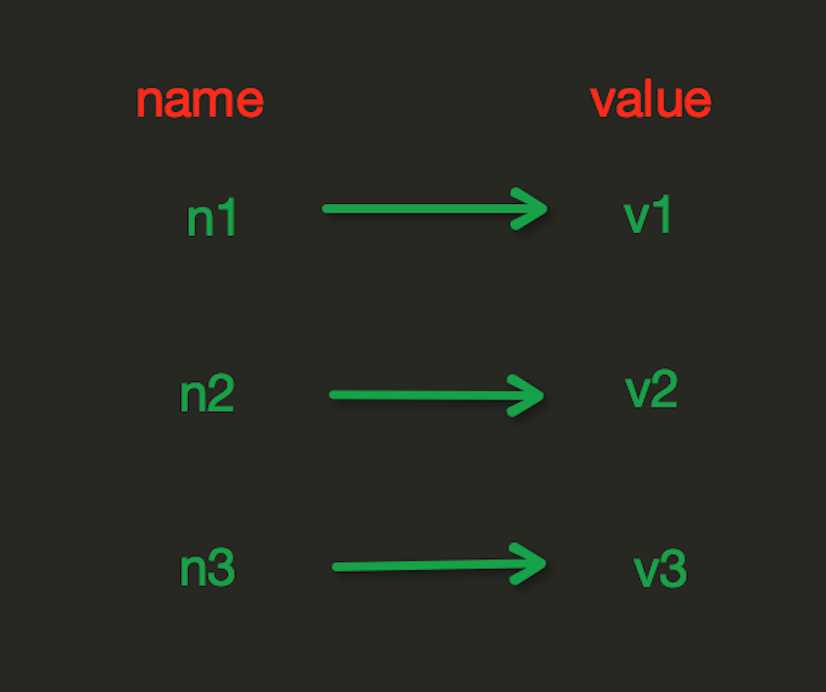
set(name, value, ex=None, px=None, nx=False, xx=False)
|
1
2
3
4
5
6
|
在Redis中设置值,默认,不存在则创建,存在则修改参数: ex,过期时间(秒) px,过期时间(毫秒) nx,如果设置为True,则只有name不存在时,当前set操作才执行 xx,如果设置为True,则只有name存在时,岗前set操作才执行 |
setnx(name, value)
|
1
|
设置值,只有name不存在时,执行设置操作(添加) |
setex(name, value, time)
|
1
2
3
|
# 设置值# 参数: # time,过期时间(数字秒 或 timedelta对象)
|
psetex(name, time_ms, value)
|
1
2
3
|
# 设置值# 参数: # time_ms,过期时间(数字毫秒 或 timedelta对象) |
mset(*args, **kwargs)
|
1
2
3
4
5
|
批量设置值如: mset(k1=‘v1‘, k2=‘v2‘) 或 mget({‘k1‘: ‘v1‘, ‘k2‘: ‘v2‘}) |
get(name)
|
1
|
获取值 |
mget(keys, *args)
|
1
2
3
4
5
|
批量获取如: mget(‘ylr‘, ‘wupeiqi‘) 或 r.mget([‘ylr‘, ‘wupeiqi‘]) |
getset(name, value)
|
1
|
设置新值并获取原来的值 |
getrange(key, start, end)
|
1
2
3
4
5
6
|
# 获取子序列(根据字节获取,非字符)# 参数: # name,Redis 的 name # start,起始位置(字节) # end,结束位置(字节)# 如: "武沛齐" ,0-3表示 "武" |
setrange(name, offset, value)
|
1
2
3
4
|
# 修改字符串内容,从指定字符串索引开始向后替换(新值太长时,则向后添加)# 参数: # offset,字符串的索引,字节(一个汉字三个字节) # value,要设置的值 |
setbit(name, offset, value)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
# 对name对应值的二进制表示的位进行操作# 参数: # name,redis的name # offset,位的索引(将值变换成二进制后再进行索引) # value,值只能是 1 或 0# 注:如果在Redis中有一个对应: n1 = "foo", 那么字符串foo的二进制表示为:01100110 01101111 01101111 所以,如果执行 setbit(‘n1‘, 7, 1),则就会将第7位设置为1, 那么最终二进制则变成 01100111 01101111 01101111,即:"goo"# 扩展,转换二进制表示: # source = "武沛齐" source = "foo" for i in source: num = ord(i) print bin(num).replace(‘b‘,‘‘) 特别的,如果source是汉字 "武沛齐"怎么办? 答:对于utf-8,每一个汉字占 3 个字节,那么 "武沛齐" 则有 9个字节 对于汉字,for循环时候会按照 字节 迭代,那么在迭代时,将每一个字节转换 十进制数,然后再将十进制数转换成二进制 11100110 10101101 10100110 11100110 10110010 10011011 11101001 10111101 10010000 -------------------------- ----------------------------- ----------------------------- 武 沛 齐 |
*用途举例,用最省空间的方式,存储在线用户数及分别是哪些用户在线
getbit(name, offset)
|
1
|
# 获取name对应的值的二进制表示中的某位的值 (0或1) |
bitcount(key, start=None, end=None)
|
1
2
3
4
5
|
# 获取name对应的值的二进制表示中 1 的个数# 参数: # key,Redis的name # start,位起始位置 # end,位结束位置 |
strlen(name)
|
1
|
# 返回name对应值的字节长度(一个汉字3个字节) |
incr(self, name, amount=1)
|
1
2
3
4
5
6
7
|
# 自增 name对应的值,当name不存在时,则创建name=amount,否则,则自增。# 参数: # name,Redis的name # amount,自增数(必须是整数)# 注:同incrby |
incrbyfloat(self, name, amount=1.0)
|
1
2
3
4
5
|
# 自增 name对应的值,当name不存在时,则创建name=amount,否则,则自增。# 参数: # name,Redis的name # amount,自增数(浮点型) |
decr(self, name, amount=1)
|
1
2
3
4
5
|
# 自减 name对应的值,当name不存在时,则创建name=amount,否则,则自减。# 参数: # name,Redis的name # amount,自减数(整数) |
append(key, value)
|
1
2
3
4
5
|
# 在redis name对应的值后面追加内容# 参数: key, redis的name value, 要追加的字符串 |
2. Hash操作
hash表现形式上有些像pyhton中的dict,可以存储一组关联性较强的数据 , redis中Hash在内存中的存储格式如下图:
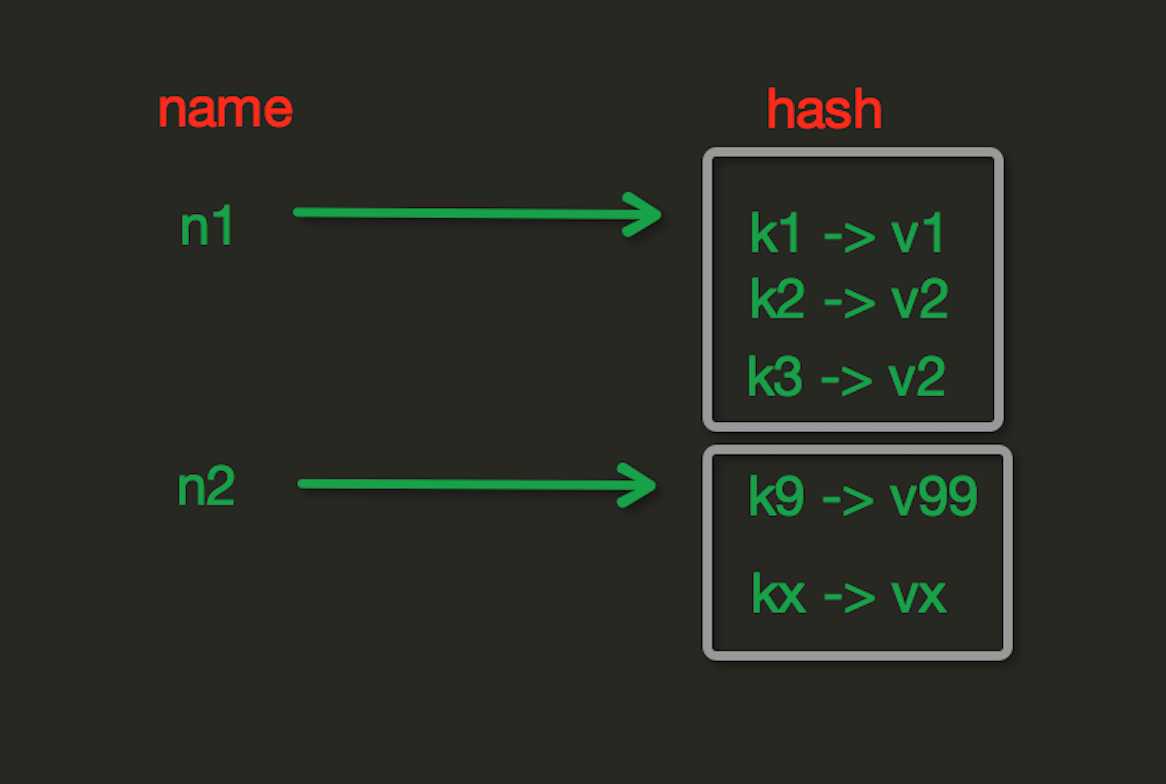
hset(name, key, value)
|
1
2
3
4
5
6
7
8
9
|
# name对应的hash中设置一个键值对(不存在,则创建;否则,修改)# 参数: # name,redis的name # key,name对应的hash中的key # value,name对应的hash中的value# 注: # hsetnx(name, key, value),当name对应的hash中不存在当前key时则创建(相当于添加) |
hmset(name, mapping)
|
1
2
3
4
5
6
7
8
|
# 在name对应的hash中批量设置键值对# 参数: # name,redis的name # mapping,字典,如:{‘k1‘:‘v1‘, ‘k2‘: ‘v2‘}# 如: # r.hmset(‘xx‘, {‘k1‘:‘v1‘, ‘k2‘: ‘v2‘}) |
hget(name,key)
|
1
|
# 在name对应的hash中获取根据key获取value |
hmget(name, keys, *args)
|
1
2
3
4
5
6
7
8
9
10
11
|
# 在name对应的hash中获取多个key的值# 参数: # name,reids对应的name # keys,要获取key集合,如:[‘k1‘, ‘k2‘, ‘k3‘] # *args,要获取的key,如:k1,k2,k3# 如: # r.mget(‘xx‘, [‘k1‘, ‘k2‘]) # 或 # print r.hmget(‘xx‘, ‘k1‘, ‘k2‘) |
hgetall(name)
|
1
|
获取name对应hash的所有键值 |
hlen(name)
|
1
|
# 获取name对应的hash中键值对的个数 |
hkeys(name)
|
1
|
# 获取name对应的hash中所有的key的值 |
hvals(name)
|
1
|
# 获取name对应的hash中所有的value的值 |
hexists(name, key)
|
1
|
# 检查name对应的hash是否存在当前传入的key |
hdel(name,*keys)
|
1
|
# 将name对应的hash中指定key的键值对删除 |
hincrby(name, key, amount=1)
|
1
2
3
4
5
|
# 自增name对应的hash中的指定key的值,不存在则创建key=amount# 参数: # name,redis中的name # key, hash对应的key # amount,自增数(整数) |
hincrbyfloat(name, key, amount=1.0)
|
1
2
3
4
5
6
7
8
|
# 自增name对应的hash中的指定key的值,不存在则创建key=amount# 参数: # name,redis中的name # key, hash对应的key # amount,自增数(浮点数)# 自增name对应的hash中的指定key的值,不存在则创建key=amount |
hscan(name, cursor=0, match=None, count=None)
Start a full hash scan with:
HSCAN myhash 0
Start a hash scan with fields matching a pattern with:
HSCAN myhash 0 MATCH order_*
Start a hash scan with fields matching a pattern and forcing the scan command to do more scanning with:
HSCAN myhash 0 MATCH order_* COUNT 1000
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
# 增量式迭代获取,对于数据大的数据非常有用,hscan可以实现分片的获取数据,并非一次性将数据全部获取完,从而放置内存被撑爆# 参数: # name,redis的name # cursor,游标(基于游标分批取获取数据) # match,匹配指定key,默认None 表示所有的key # count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数# 如: # 第一次:cursor1, data1 = r.hscan(‘xx‘, cursor=0, match=None, count=None) # 第二次:cursor2, data1 = r.hscan(‘xx‘, cursor=cursor1, match=None, count=None) # ... # 直到返回值cursor的值为0时,表示数据已经通过分片获取完毕 |
hscan_iter(name, match=None, count=None)
|
1
2
3
4
5
6
7
8
9
|
# 利用yield封装hscan创建生成器,实现分批去redis中获取数据 # 参数: # match,匹配指定key,默认None 表示所有的key # count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数 # 如: # for item in r.hscan_iter(‘xx‘): # print item |
3. list
List操作,redis中的List在在内存中按照一个name对应一个List来存储。如图:
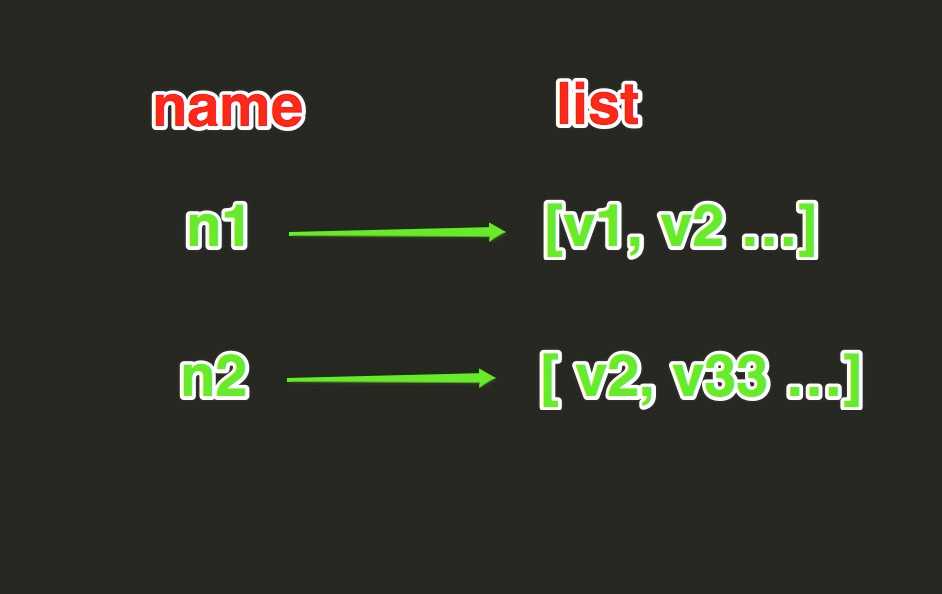
lpush(name,values)
|
1
2
3
4
5
6
7
8
|
# 在name对应的list中添加元素,每个新的元素都添加到列表的最左边# 如: # r.lpush(‘oo‘, 11,22,33) # 保存顺序为: 33,22,11# 扩展: # rpush(name, values) 表示从右向左操作 |
lpushx(name,value)
|
1
2
3
4
|
# 在name对应的list中添加元素,只有name已经存在时,值添加到列表的最左边# 更多: # rpushx(name, value) 表示从右向左操作 |
llen(name)
|
1
|
# name对应的list元素的个数 |
linsert(name, where, refvalue, value))
|
1
2
3
4
5
6
7
|
# 在name对应的列表的某一个值前或后插入一个新值# 参数: # name,redis的name # where,BEFORE或AFTER # refvalue,标杆值,即:在它前后插入数据 # value,要插入的数据 |
r.lset(name, index, value)
|
1
2
3
4
5
6
|
# 对name对应的list中的某一个索引位置重新赋值# 参数: # name,redis的name # index,list的索引位置 # value,要设置的值 |
r.lrem(name, value, num)
|
1
2
3
4
5
6
7
8
|
# 在name对应的list中删除指定的值# 参数: # name,redis的name # value,要删除的值 # num, num=0,删除列表中所有的指定值; # num=2,从前到后,删除2个; # num=-2,从后向前,删除2个 |
lpop(name)
|
1
2
3
4
|
# 在name对应的列表的左侧获取第一个元素并在列表中移除,返回值则是第一个元素# 更多: # rpop(name) 表示从右向左操作 |
lindex(name, index)
|
1
|
在name对应的列表中根据索引获取列表元素 |
lrange(name, start, end)
|
1
2
3
4
5
|
# 在name对应的列表分片获取数据# 参数: # name,redis的name # start,索引的起始位置 # end,索引结束位置 |
ltrim(name, start, end)
|
1
2
3
4
5
|
# 在name对应的列表中移除没有在start-end索引之间的值# 参数: # name,redis的name # start,索引的起始位置 # end,索引结束位置 |
rpoplpush(src, dst)
|
1
2
3
4
|
# 从一个列表取出最右边的元素,同时将其添加至另一个列表的最左边# 参数: # src,要取数据的列表的name # dst,要添加数据的列表的name |
blpop(keys, timeout)
|
1
2
3
4
5
6
7
8
|
# 将多个列表排列,按照从左到右去pop对应列表的元素# 参数: # keys,redis的name的集合 # timeout,超时时间,当元素所有列表的元素获取完之后,阻塞等待列表内有数据的时间(秒), 0 表示永远阻塞# 更多: # r.brpop(keys, timeout),从右向左获取数据 |
brpoplpush(src, dst, timeout=0)
|
1
2
3
4
5
6
|
# 从一个列表的右侧移除一个元素并将其添加到另一个列表的左侧# 参数: # src,取出并要移除元素的列表对应的name # dst,要插入元素的列表对应的name # timeout,当src对应的列表中没有数据时,阻塞等待其有数据的超时时间(秒),0 表示永远阻塞 |
4.set集合操作
Set操作,Set集合就是不允许重复的列表
sadd(name,values)
# name对应的集合中添加元素scard(name)
获取name对应的集合中元素个数sdiff(keys, *args)
在第一个name对应的集合中且不在其他name对应的集合的元素集合sdiffstore(dest, keys, *args)
# 获取第一个name对应的集合中且不在其他name对应的集合,再将其新加入到dest对应的集合中sinter(keys, *args)
# 获取多一个name对应集合的并集sinterstore(dest, keys, *args)
# 获取多一个name对应集合的并集,再讲其加入到dest对应的集合中sismember(name, value)
# 检查value是否是name对应的集合的成员smembers(name)
# 获取name对应的集合的所有成员smove(src, dst, value)
# 将某个成员从一个集合中移动到另外一个集合spop(name)
# 从集合的右侧(尾部)移除一个成员,并将其返回srandmember(name, numbers)
# 从name对应的集合中随机获取 numbers 个元素srem(name, values)
# 在name对应的集合中删除某些值sunion(keys, *args)
# 获取多一个name对应的集合的并集sunionstore(dest,keys, *args)
# 获取多一个name对应的集合的并集,并将结果保存到dest对应的集合中sscan(name, cursor=0, match=None, count=None)
sscan_iter(name, match=None, count=None)
# 同字符串的操作,用于增量迭代分批获取元素,避免内存消耗太大
有序集合,在集合的基础上,为每元素排序;元素的排序需要根据另外一个值来进行比较,所以,对于有序集合,每一个元素有两个值,即:值和分数,分数专门用来做排序。
zadd(name, *args, **kwargs)
# 在name对应的有序集合中添加元素# 如:# zadd(‘zz‘, ‘n1‘, 1, ‘n2‘, 2)# 或# zadd(‘zz‘, n1=11, n2=22)zcard(name)
# 获取name对应的有序集合元素的数量zcount(name, min, max)
# 获取name对应的有序集合中分数 在 [min,max] 之间的个数zincrby(name, value, amount)
# 自增name对应的有序集合的 name 对应的分数r.zrange( name, start, end, desc=False, withscores=False, score_cast_func=float)
# 按照索引范围获取name对应的有序集合的元素# 参数:# name,redis的name# start,有序集合索引起始位置(非分数)# end,有序集合索引结束位置(非分数)# desc,排序规则,默认按照分数从小到大排序# withscores,是否获取元素的分数,默认只获取元素的值# score_cast_func,对分数进行数据转换的函数# 更多:# 从大到小排序# zrevrange(name, start, end, withscores=False, score_cast_func=float)# 按照分数范围获取name对应的有序集合的元素# zrangebyscore(name, min, max, start=None, num=None, withscores=False, score_cast_func=float)# 从大到小排序# zrevrangebyscore(name, max, min, start=None, num=None, withscores=False, score_cast_func=float)zrank(name, value)
# 获取某个值在 name对应的有序集合中的排行(从 0 开始)# 更多:# zrevrank(name, value),从大到小排序
zrem(name, values)
|
1
2
3
|
# 删除name对应的有序集合中值是values的成员# 如:zrem(‘zz‘, [‘s1‘, ‘s2‘]) |
zremrangebyrank(name, min, max)
|
1
|
# 根据排行范围删除 |
zremrangebyscore(name, min, max)
|
1
|
# 根据分数范围删除
|
zscore(name, value)
|
1
|
# 获取name对应有序集合中 value 对应的分数 |
zinterstore(dest, keys, aggregate=None)
|
1
2
|
# 获取两个有序集合的交集,如果遇到相同值不同分数,则按照aggregate进行操作# aggregate的值为: SUM MIN MAX |
zunionstore(dest, keys, aggregate=None)
|
1
2
|
# 获取两个有序集合的并集,如果遇到相同值不同分数,则按照aggregate进行操作# aggregate的值为: SUM MIN MAX |
zscan(name, cursor=0, match=None, count=None, score_cast_func=float)
zscan_iter(name, match=None, count=None,score_cast_func=float)
|
1
|
# 同字符串相似,相较于字符串新增score_cast_func,用来对分数进行操作 |
其他常用操作
delete(*names)
# 根据删除redis中的任意数据类型exists(name)
# 检测redis的name是否存在keys(pattern=‘*‘)
# 根据模型获取redis的name# 更多:# KEYS * 匹配数据库中所有 key 。# KEYS h?llo 匹配 hello , hallo 和 hxllo 等。# KEYS h*llo 匹配 hllo 和 heeeeello 等。# KEYS h[ae]llo 匹配 hello 和 hallo ,但不匹配 hilloexpire(name ,time)
# 为某个redis的某个name设置超时时间rename(src, dst)
# 对redis的name重命名为move(name, db))
# 将redis的某个值移动到指定的db下randomkey()
# 随机获取一个redis的name(不删除)type(name)
# 获取name对应值的类型scan(cursor=0, match=None, count=None)
scan_iter(match=None, count=None)
# 同字符串操作,用于增量迭代获取key
管道
redis-py默认在执行每次请求都会创建(连接池申请连接)和断开(归还连接池)一次连接操作,如果想要在一次请求中指定多个命令,则可以使用pipline实现一次请求指定多个命令,并且默认情况下一次pipline 是原子性操作。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
#!/usr/bin/env python# -*- coding:utf-8 -*-import redispool = redis.ConnectionPool(host=‘10.211.55.4‘, port=6379)r = redis.Redis(connection_pool=pool)# pipe = r.pipeline(transaction=False)pipe = r.pipeline(transaction=True)pipe.set(‘name‘, ‘alex‘)pipe.set(‘role‘, ‘sb‘)pipe.execute()
|
Python操作Redis
|
1
2
3
4
5
6
7
|
sudo pip install redisorsudo easy_install redisor源码安装 详见:https://github.com/WoLpH/redis-py |
发布订阅

import redis pool = redis.ConnectionPool(host=‘192.168.14.35‘, port=6379,password="Alex3714" ,db=1) r = redis.Redis(connection_pool=pool) pub = r.pubsub() #打开收音机 pub.subscribe("fm87.7") #调台 pub.parse_response() #准备接收 print("准备监听...") data = pub.parse_response() #正式接收 print(data)
发布:
import redis pool = redis.ConnectionPool(host=‘192.168.14.35‘, port=6379,password="Alex3714" ,db=1) r = redis.Redis(connection_pool=pool) r.publish("fm87.7", "big SB!")
什么时候用关系型数据库,什么时候 用NoSQL?
Go for legacy relational databases (RDBMS) when:
- The data is well structured, and lends itself to a tabular arrangement (rows and columns) in a relational database. Typical examples: bank account info, customer order info, customer info, employee info, department info etc etc.
- Another aspect of the above point is : schema oriented data model. When you design a data model (tables, relationships etc) for a potential use of RDBMS, you need to come up with a well defined schema: there will be these many tables, each table having a known set of columns that store data in known typed format (CHAR, NUMBER, BLOB etc).
- Very Important: Consider whether the data is transactional in nature. In other words, whether the data will be stored, accessed and updated in the context of transactions providing the ACID semantics or is it okay to compromise some/all of these properties.
- Correctness is also important and any compromise is _unacceptable_. This stems from the fact that in most NoSQL databases, consistency is traded off in favor of performance and scalability (points on NoSQL databases are elaborated below).
- There is no strong/compelling need for a scale out architecture ; a database that linearly scales out (horizontal scaling) to multiple nodes in a cluster.
- The use case is not for “high speed data ingestion”.
- If the client applications are expecting to quickly stream large amounts of data in/out of the database then relational database may not be a good choice since they are not really designed for scaling write heavy workloads.
- In order to achieve ACID properties, lots of additional background work is done especially in writer (INSERT, UPDATE, DELETE) code paths. This definitely affects performance.
- The use case is not for “storing enormous amounts of data in the range of petabytes”.
Go for NoSQL databases when:
- There is no fixed (and predetermined) schema that data fits in:
- Scalability, Performance (high throughput and low operation latency), Continuous Availability are very important requirements to be met by the underlying architecture of database.
- Good choice for “High Speed Data Ingestion”. Such applications (for example IoT style) which generate millions of data points in a second and need a database capable of providing extreme write scalability.
- The inherent ability to horizontally scale allows to store large amounts of data across commodity servers in the cluster. They usually use low cost resources, and are able to linearly add compute and storage power as the demand grows.
source page https://www.quora.com/When-should-you-use-NoSQL-vs-regular-RDBMS
以上是关于redis缓存数据库的主要内容,如果未能解决你的问题,请参考以下文章
Swift新async/await并发中利用Task防止指定代码片段执行的数据竞争(Data Race)问题