联网数据库 IoTDB —— 存储引擎原理篇
Posted 麒思妙想
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了联网数据库 IoTDB —— 存储引擎原理篇相关的知识,希望对你有一定的参考价值。

前言
没过正月都是年,在此给大家拜个晚年,衷心的祝福诸位读者朋友们晚年幸福 : )
新年伊始,谈谈今年的写作计划吧。
《联网数据库 IoTDB》开个新坑,起因是参加了《Apache IoTDB社区导师计划》,所以,为督促自己为社区尽一点绵薄之力。而且刚好选到了存储引擎和分布式两个有意思的方向,就以存储部分开头了。
《分布式系统课程笔记》这个系列也还是会继续填坑的—— “兰尼斯特家人,有债必偿!”。
以及答应几位读者要完成的相关内容
So let's begin ...
IotDB简介
Apache IoTDB(物联网数据库)是一体化收集、存储、管理与分析物联网时序数据的软件系统。Apache IoTDB 采用轻量式架构,具有高性能和丰富的功能,并与Apache Hadoop、Spark和Flink等进行了深度集成,可以满足工业物联网领域的海量数据存储、高速数据读取和复杂数据分析需求。
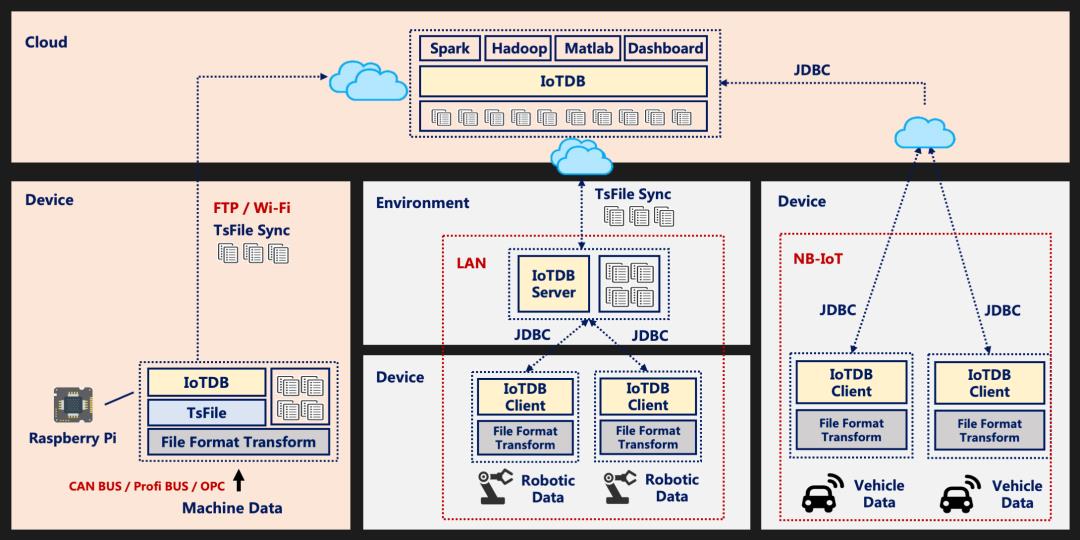
应用场景
高端设备
在高端制造业中,有很多设备配备有传感器来收集工作状态数据,例如气象站,风力涡轮机是常见的高端设备。这些设备如果支持Java或Go(正在开发中),则可以运行TsFile在本地存储数据。通过这种方式,TsFile可以提供具有高吞吐、高压缩率和毫秒级查询延迟的数据管理功能。结合TsFile-Sync工具,可以将TsFiles同步到数据中心。
本地控制器
在工厂现场,LAN网络下有数十台设备。IoTDB可以安装在工厂的本地控制器服务器上,以从这些设备接收数据。安装有IoTDB的本地服务器(普通PC或工作站)可以使用类SQL存储和查询数据。此外,使用TsFile-Sync工具,可以将本地控制器上的TsFile文件传输到云上安装有IoTDB实例的数据中心。
云数据管理
在高速网络(车联网等)的场景中,安装有传感器的汽车可以以一定频率收集自身的监视信息(行驶状态等)。通常,这些汽车设备的硬件配置有限,并且难以进行复杂的应用。轻量级的IoTDB(IoTDB客户端)应运而生。借助JDBC API(或MQTT),它可以使用窄带IoT或4G/5G发送数据,从而将设备和云连接在一起。
存储架构
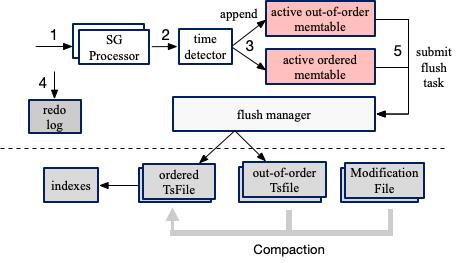
IoTDB 存储引擎基于 LSM Tree 结构设计,写入的数据先记录 WAL,再写到内存 memtable,在后台逐步刷到磁盘 TsFile;磁盘上的 TsFile 通过一定的规则进行 Compaction,保证查询效率。
那么我们就先从LSM Tree 说起吧。

LSM Tree
LSM Tree(Log Structured Merge Tree) 并不像B+树、红黑树一样是一颗严格的树状数据结构,其实它是一种存储结构,目前HBase,LevelDB,RocksDB这些NoSQL存储都是采用的LSM树。
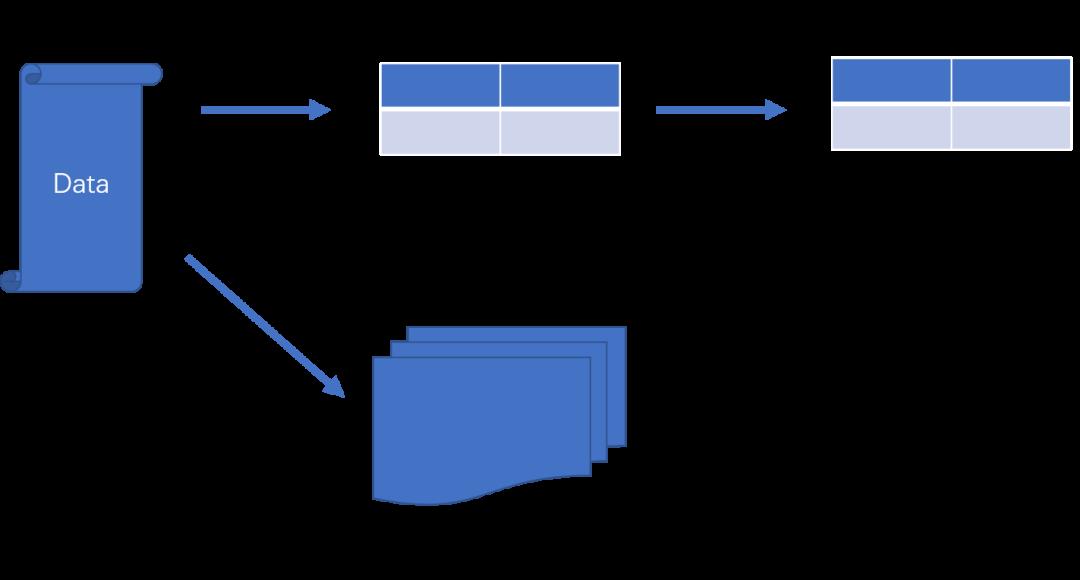
Mentable
MemTable是在内存中的数据结构,用于保存最近更新的数据,会按照Key有序地组织这些数据,LSM树对于具体如何组织有序地组织数据并没有明确的数据结构定义,例如Hbase使跳跃表来保证内存中key的有序。
因为数据暂时保存在内存中,内存并不是可靠存储,如果断电会丢失数据,因此通常会通过WAL(Write-ahead logging,预写式日志)的方式来保证数据的可靠性。
SSTable(Sorted String Table)
有序键值对集合,是LSM树组在磁盘中的数据结构。为了加快SSTable的读取,可以通过建立key的索引以及布隆过滤器来加快key的查找。
我们在写入数据时,首先将对数据的修改增量保存Memtable中,同时会提交wal,当Memtable达到指定大小限制之后批量把数据刷到磁盘(SSTable)中,磁盘中树定期可以做merge操作,合并成一棵大树,以优化读性能。不过读取的时候稍微麻烦一些,读取时看这些数据在内存中,如果未能命中内存,则需要访问较多的磁盘文件。极端的说,基于LSM树实现的hbase写性能比mysql高了一个数量级,读性能却低了一个数量级。
综上所述,LSM树会将数据的所有增、删、改等操作,记录到内存中,再顺序刷新到磁盘里,这就造成了其与B+树最大的不同,B+树会直接在数据的位置更新,而LSM树则可能追到到不同的SSTable中,当然,最新的那条记录才是准确的。这样设计的虽然大大提高了写性能,但同时也会带来一些问题:
1)冗余存储,对于某个key,实际上除了最新的那条记录外,其他的记录都是冗余无用的,但是仍然占用了存储空间。因此需要进行Compact操作(合并多个SSTable)来清除冗余的记录。2)读取时需要从最新的倒着查询,直到找到某个key的记录。最坏情况需要查询完所有的SSTable,这里可以通过前面提到的索引/布隆过滤器来优化查找速度。
压缩(Compact)策略
在正式介绍压缩策略以前,我们有必要先了解一下这3个基础概念,这也是以下压缩策略需要权衡的关键:读放大(Read Amplifier)、写放大(Write Amplifier)、空间放大(Space Amplifier)
读放大(Read Amplifier):是指我们要找到一个我们所需的数据,需要进行多少次磁盘的读操作。例如我们出门前需要找钥匙,你可能要每个房间,每件衣服口袋翻一遍。这并不应该是一个正常操作。
写放大(Write Amplifier):写入数据时实际写入的数据量大于真正的数据量。例如在LSM树中写入时可能触发Compact操作,导致实际写入的数据量远大于该key的数据量。
空间放大(Space Amplifier):数据实际占用的磁盘空间比数据的真正大小更多。上面提到的冗余存储,对于一个key来说,只有最新的那条记录是有效的,而之前的记录都是可以被清理回收的。
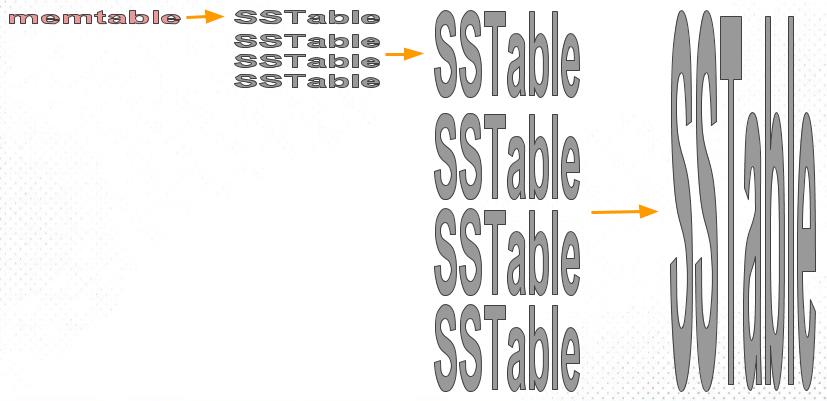
size-tiered 策略
size-tiered策略相对简单粗暴,其主旨保证每层SSTable的大小相近,同时限制每层SSTable的数量。如下图所示,每层限制SSTable为N,当每层SSTable达到N后,则触发Compact操作合并这些SSTable,并将合并后的结果写入到下一层成为一个更大的sstable。
由此可以看出,当层数达到一定数量时,最底层的单个SSTable的大小会变得非常大。并且size-tiered策略会导致空间放大比较严重。即使对于同一层的SSTable,每个key的记录是可能存在多份的,只有当该层的SSTable执行compact操作才会消除这些key的冗余记录。
leveled策略
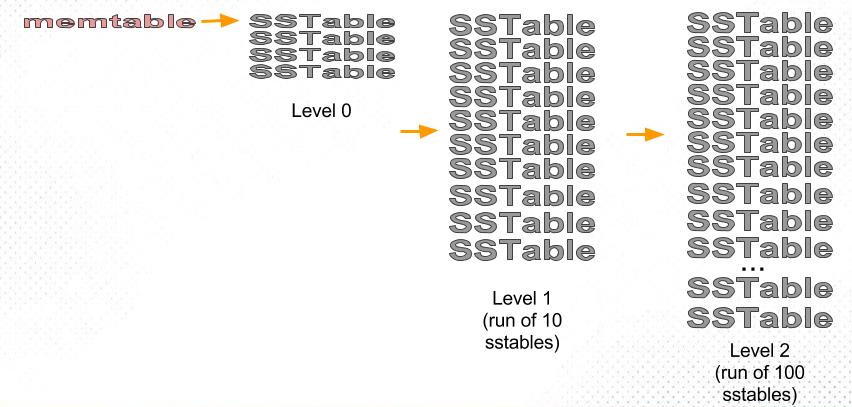
leveled策略也是采用分层的思想,每一层限制总文件的大小。但与size-tiered策略不同的是,leveled会将每一层切分成多个大小相近的SSTable。这些SSTable是这一层是全局有序的,这意味着一个key在每一层至多只有1条记录,不存在冗余记录。并且每层维持“唯一一个” Run。我们来了解一下Run这个LSM里面重要的概念,以下摘自Wiki:
Each run contains data *sorted* by the index key. A run can be represented on disk as a single file, or alternatively as a collection of files with *non-overlapping* key ranges.
run需要满足什么条件呢?第一sorted,第二non-overlapping key ranges
如下图所示:
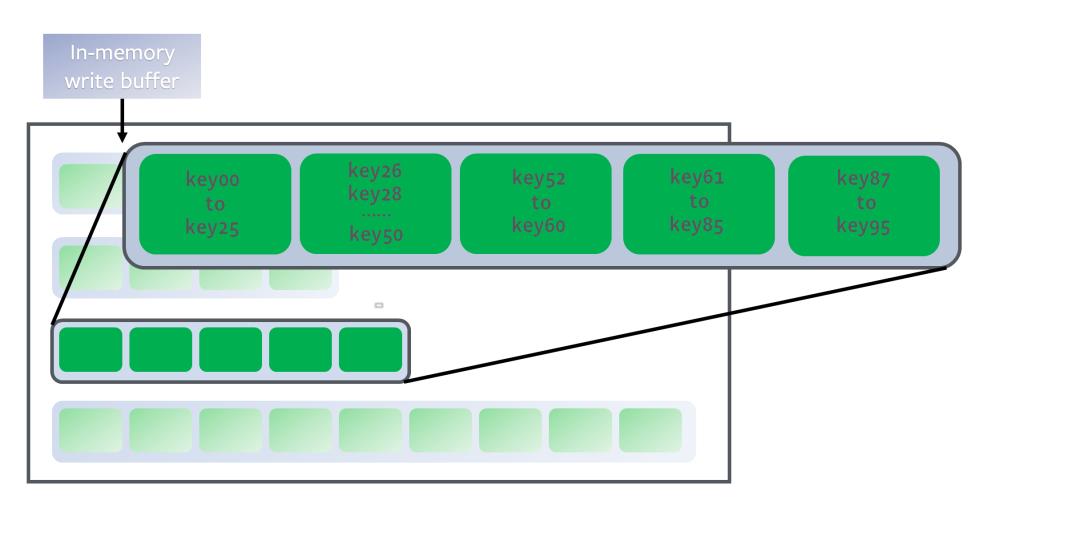
每层的大小是上一级的T(下图是10) 倍,层数越高,data越多但是也越旧.每层都有target size
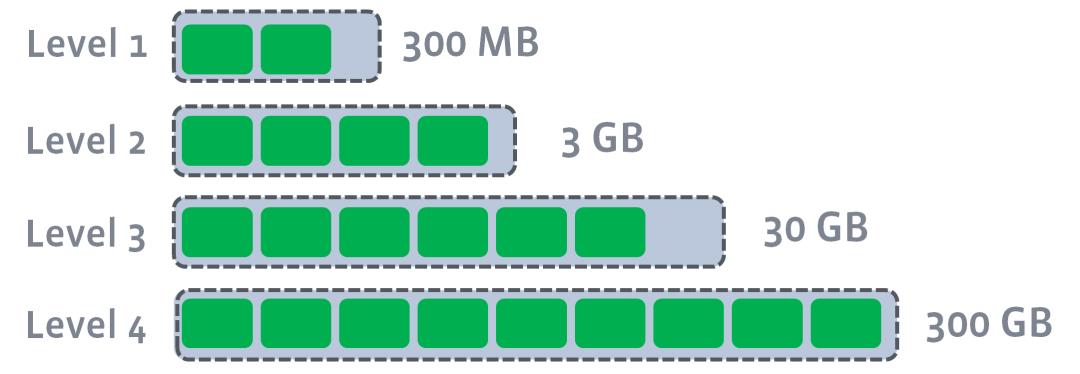
整个的过程可以简化成:in memory的table写满了,那么就flush到第一级的Disk SStable并且做compaction,要是第一级又满了,就又开始flush到第二级做compaction,以此类推直到max level, 下面几张图描述了整个过程。
假设如下图是起始状态
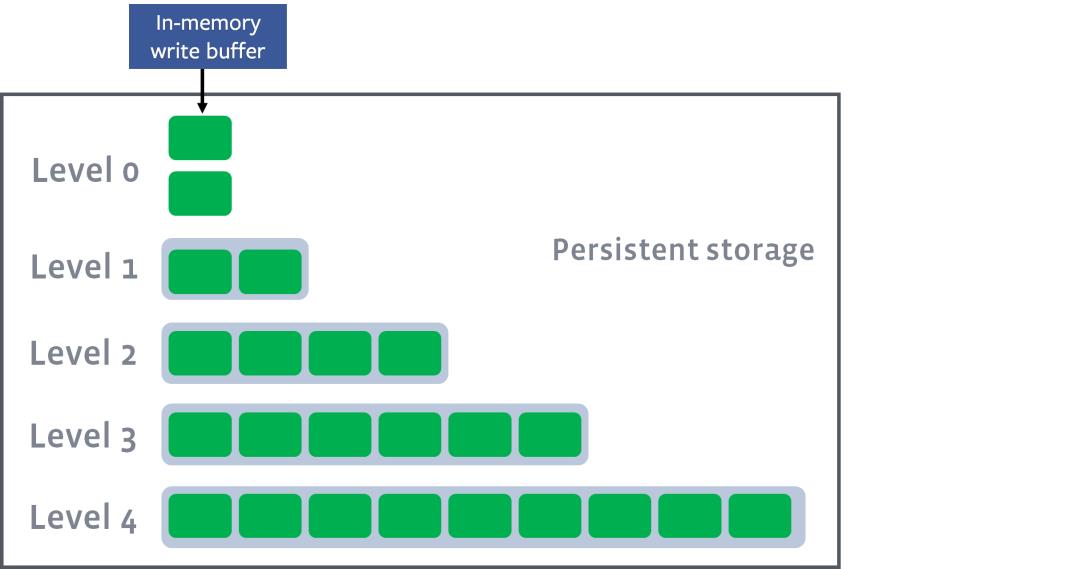
level0 有数据写入,这个时候触发level0到level1的compact
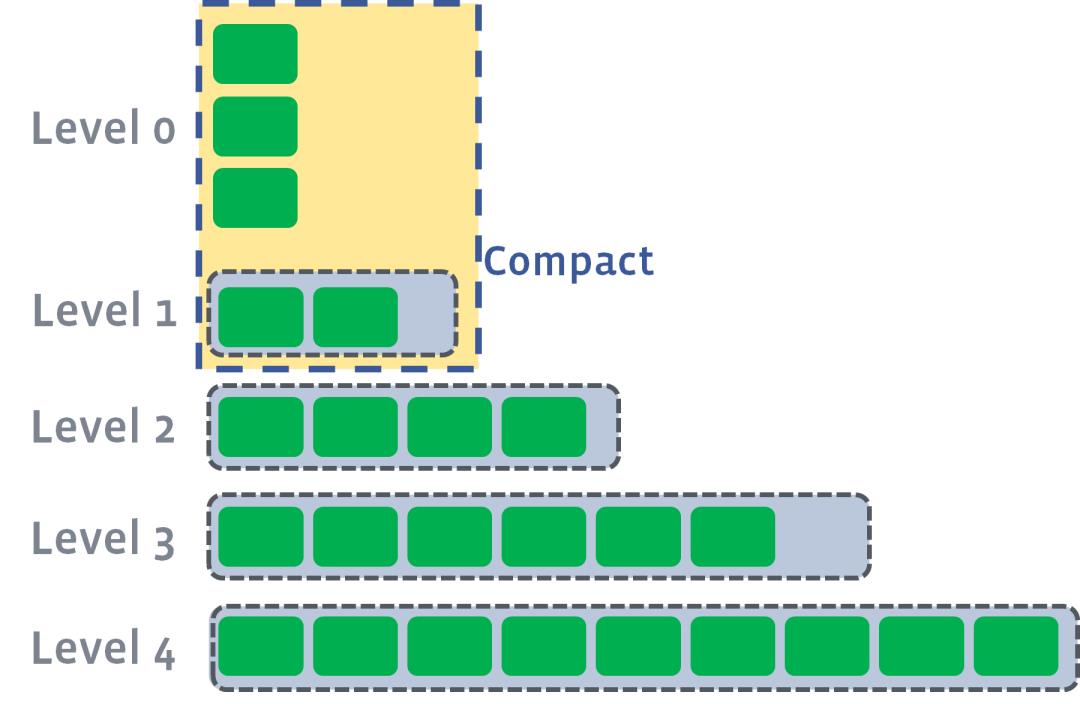
level1 超出限制,触发level1到level2compact
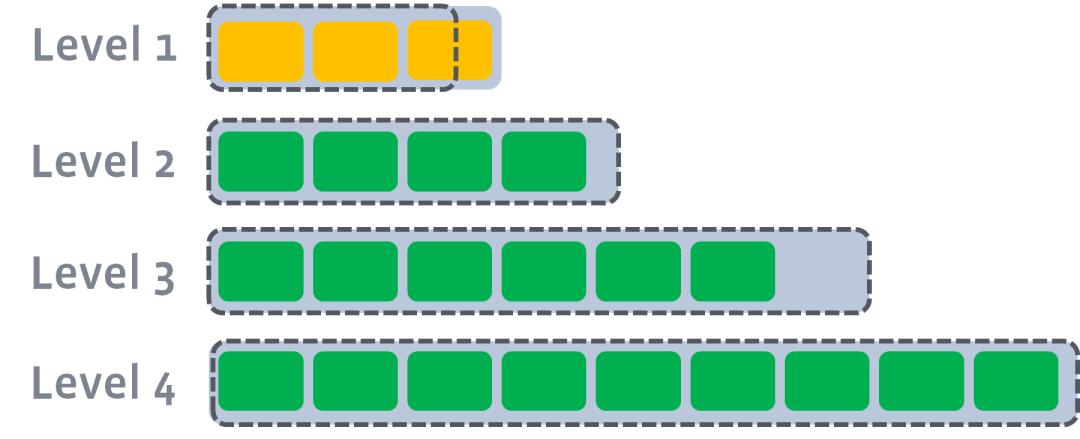
此时会从level1中选择至少一个文件,然后把它跟level2有交集的部分(非常关键)进行合并。生成的文件会放在level2
由于level1第二SSTable的key的范围覆盖了level2中前三个SSTable,那么就需要将level1中第二个SSTable与level2中前三个SSTable执行Compact操作。
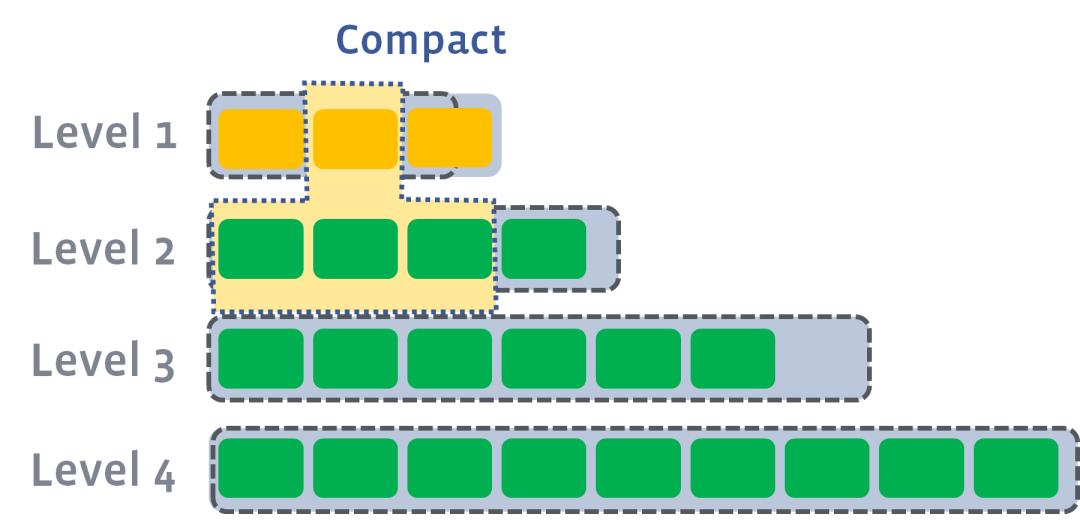
level2合并完成后,如果其超出了level2阈值的限制,那么会触发level2到level3的compact
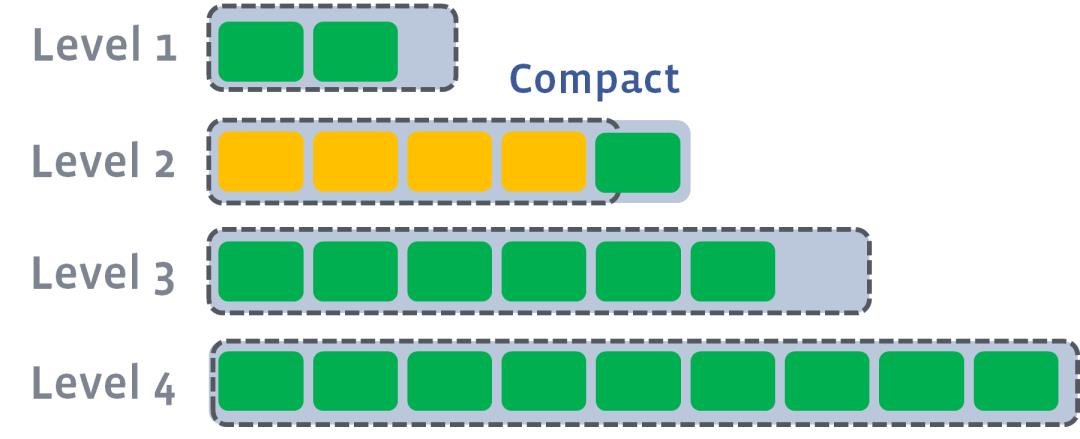
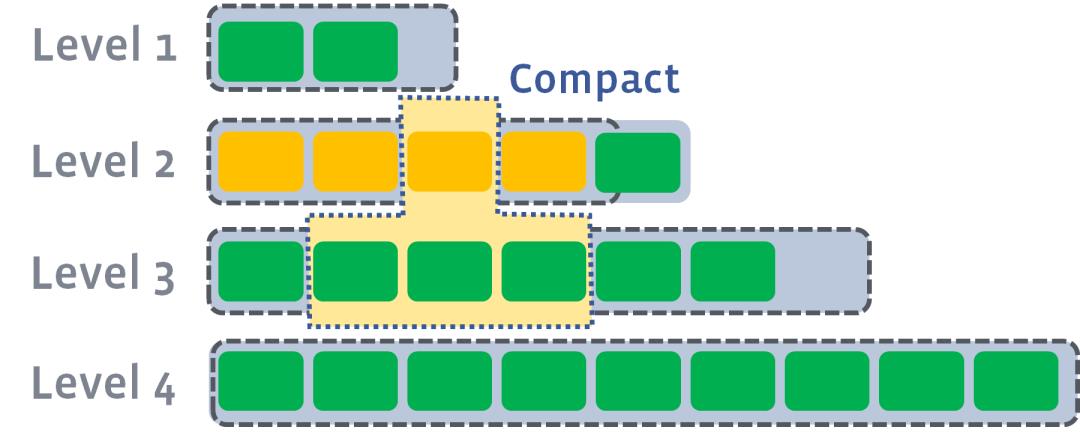
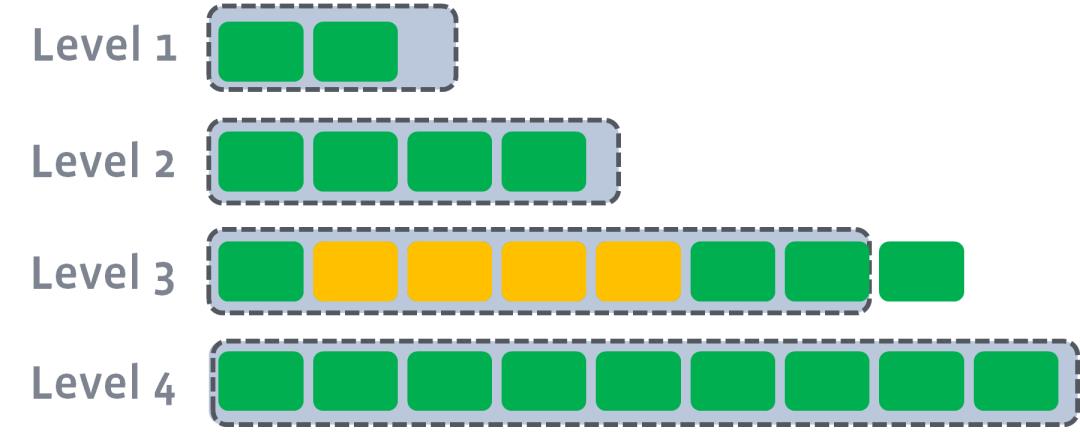
以此类推,上一层达到阈值以后,就出触发到下一层的compact操作。
值得一提的是,无论是同级还是不同级,不重叠的key,可以并行进行。
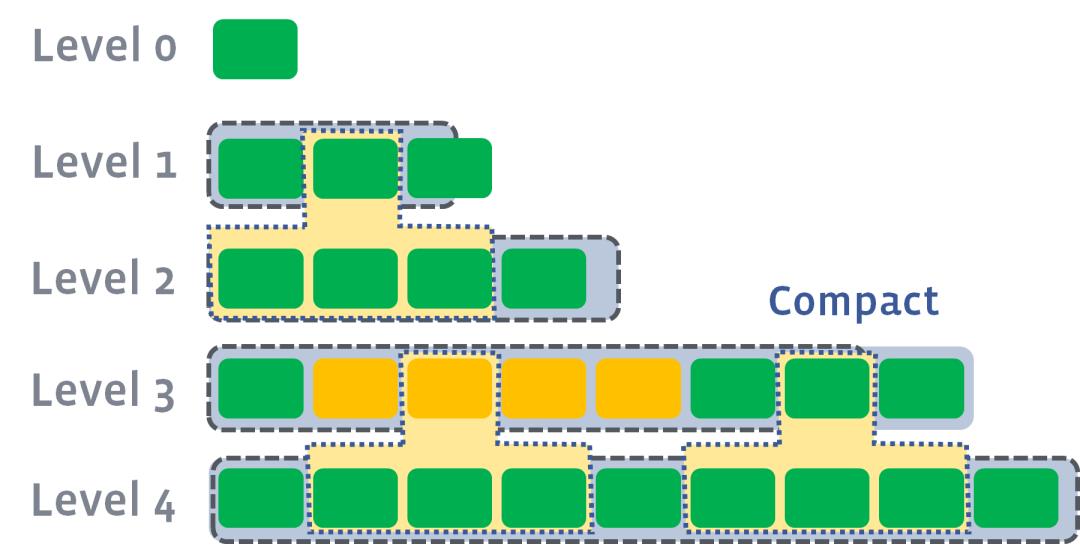
简单总结,Level compaction目标就是维持每个level都保持住one data sorted run,所以每个level都可以和下一个level做compaction,同时很有可能会被上一个level做compaction。这样做好处就是level之间的compaction可以multithread来做(除了memory到level0),提高效率。
LSM Tree vs. B+ Tree vs. Hash
对比三种引擎的实现:
hash存储引擎:哈希表持久化的实现,可以快速支持增删改查等随机操作,且时间复杂度为o(1),但是不支持顺序读取扫描,对应的存储系统为k-v存储系统的实现。
b树存储引擎是b树的持久化实现,不仅支持单条记录的增删改查操作,还支持顺序扫描,对应的存储系统就是mysql。
lsm树存储引擎和b树存储引擎,一样支持,增删改查,也支持顺序扫描操作。LSM牺牲了读性能,提高写性能。
Iotdb写入流程
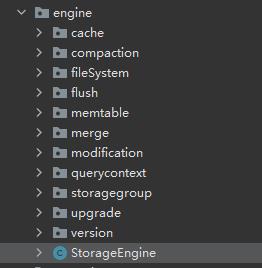
相关代码
org.apache.iotdb.db.engine.StorageEngine
负责一个 IoTDB 实例的写入和访问,管理所有的 StorageGroupProsessor。
org.apache.iotdb.db.engine.storagegroup.StorageGroupProcessor
负责一个存储组一个时间分区内的数据写入和访问。管理所有分区的TsFileProcessor。
org.apache.iotdb.db.engine.storagegroup.TsFileProcessor
负责一个 TsFile 文件的数据写入和访问。
这篇文章,我们先介绍到这里,下一篇文章再见。
参考链接
http://iotdb.apache.org/zh/SystemDesign/StorageEngine/StorageEngine.html
http://iotdb.apache.org/zh/SystemDesign/TsFile/Format.html
http://iotdb.apache.org/zh/SystemDesign/StorageEngine/DataPartition.html
https://www.scylladb.com/2018/01/31/compaction-series-leveled-compaction/
https://github.com/facebook/rocksdb/wiki/Leveled-Compaction
https://www.cnblogs.com/yankang/p/11041173.html
https://zhuanlan.zhihu.com/p/181498475
https://zhuanlan.zhihu.com/p/151234708
https://zhuanlan.zhihu.com/p/112574579
关注 【 麒思妙想】解锁更多硬核。
历史文章导读:
如果文章对您有那么一点点帮助,我将倍感荣幸
欢迎 关注、在看、点赞、转发

以上是关于联网数据库 IoTDB —— 存储引擎原理篇的主要内容,如果未能解决你的问题,请参考以下文章