解读 Pathways :向前一步是 OneFlow
Posted OneFlow深度学习框架
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了解读 Pathways :向前一步是 OneFlow相关的知识,希望对你有一定的参考价值。

撰文|袁进辉
本文目录如下:
-
下一代 AI 架构是否成立?
-
问题设定
-
Pathways 如何工作?
-
数据流执行引擎 PLAQUE
-
关于 PLAQUE 的一些问题
-
从 Pathways 的视角理解 OneFlow SBP
-
从 Pathways 的视角理解 OneFlow Actor
-
OneFlow 可以向 Pathways 学习什么?
-
Ray 距离Pathways 有多远?
-
总结
1
下一代 AI 架构是否成立?
多数情况下,在学术界提“下一代”、“重新思考”、“重新设计” 这样的字眼是一件很讨人厌的事,其令人反感的程度堪比“我不是针对谁,我是说在座的都不如我厉害”,归根结底,不是谁都可以站出来定义真正的“下一代”。
最近几年,在分布式计算系统领域,印象中有 3 篇论文这么做过:
第一篇是 《Ray: a distributed framework for emgerging AI applications(https://www.usenix.org/system/files/osdi18-moritz.pdf)》,主张面向未来的 AI 应用必须重新思考分布式计算框架,结果就是 Ray。这篇论文据说也被拒过,不过最终被 OSDI 录用。其作者是伯克利 AMP Lab 的 Ion Stoica,其神奇履历见访谈《Ion Stoica: 做成 Spark 和 Ray 两个明星项目的秘笈》。虽然 Ray 以强化学习场景为目标,但我所知道的大规模的强化学习系统都不是用它实现的,原因是用 Ray 时遇到无法搞定的问题。我个人认为 Ray 已经很有影响力,但仍未解决自己的定位问题,它好似介于 K8S 和深度学习框架之间的位置,但在这两个领地都无法真正实现取而代之。
第二篇是OneFlow团队写的《OneFlow: Redesign the Distributed Deep Learning Framework from Scratch(https://arxiv.org/pdf/2110.15032.pdf)》,论文称,为了灵活、高效的支持近些年的大模型需求,不能在已有深度学习框架基础上修修补补,必须另起炉灶,相对于在已有框架上做增量式改进,从零开始设计的 OneFlow 更有优势。不幸的是,这篇论文被 OSDI, SOSP, MLSys 拒稿。为什么要重新设计?在原有系统上改造不香吗?你能证明在原有系统上增量修改不能实现一样的目标吗?
第三篇就是本文要进一步讨论的《Pathways: asynchronous distributed dataflow for ML》,虽然论文标题没有写下一代 AI 架构,但作者之一 Jeff Dean 投稿时在 Google 官网发了一篇震动世界的博客《Pathways:下一代 AI 架构》。如果从 SPMD 的需求来看框架,真是再简单不过了,但是,MPMD 是由多个 SPMD 组成。Pathways 要思考为 MPMD 服务的最优架构,就要跳出传统深度学习框架的藩篱,在更高层次进行设计。如果把之前的 PyTorch 和 JAX 等为 SPMD 场景设计的深度学习框架理解成狭义的框架,那么 Pathways 之所以敢自称下一代 AI 架构,是因为它可以被理解成框架的框架。
一般来说,这样的论文立意宏大,难写。在论文里论证研发下一代架构的必要性也很难,必须要有理有据的证明。强如 Google Brain 这样的团队也只能说,尽管 TF v1 可以做到这个以及那个,但它有这样及那样的问题,需求发生变化了,我们需要重新思考这个问题。
The implementation choices made by TF v1 were over-specialized to assume a single, smallish, exclusively-owned island of accelerators. This over-specialization makes it practically infeasible to use TF for contemporary or future ML workloads.
但这个论证并不能以理服人。毕竟,为了训练 GPT-3, TensorFlow 团队还是研发了Mesh-tensorflow、GPipe、GShard、GSPMD,虽然 PyTorch 还没有解决这些问题,但英伟达在其基础上做了Megatron-LM,微软做了 DeepSpeed 都还可以训练大模型和 MoE,用户也不少,你怎么能说人家这些增量式的改进行不通?
这样的论文也难懂。在上一篇《解读Pathways(一):Single-controller与Multi-controller》中,我说 Pathways 的论文不好理解,因为绝大部分人思维的舒适区还是在 SPMD,理解起来 MPMD 不那么顺理成章。
所以,写文章解读 Pathways 也有一定的价值吧。
2
问题设定
为便于理解 Pathways 的设计理念,我们先简要回顾一下它的设计目标是什么。Pathways 认为未来的 AI 模型不是 SPMD 所能描述的,得用MPMD(譬如流水并行这样的任务)。简单来说, MPMD 是由多个 SPMD 构成的,每个 SPMD 是同一个 computation 在一组设备上通过 GShard 或 GSPMD 的方式来均匀、对称的划分。我们用 Pathways 论文里的一个例子来说明。

上图展示了 Pathways 可以运行的 MPMD 类型的 program,这个 program 由 a, b, c, a 四个 computation 构成,每个 computation 都是一个 SPMD 类型的任务,每个 computation 需要被 sharding 到若干设备上去,例如 a,b,c 都被分配了 2 个设备。
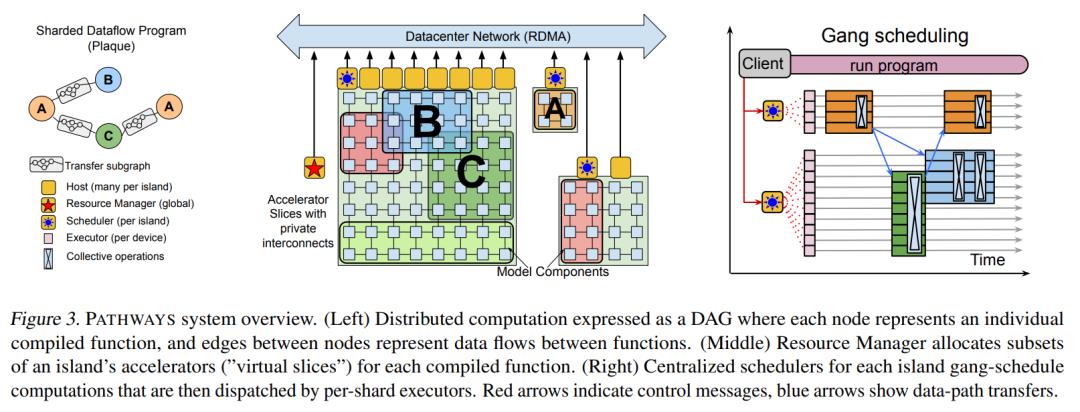
上图则展示了 Pathways 执行 Figure 2 代码时内部发生的事情。需要注意的是,尽管 A, B, C 每一个 computation 在多个设备上并行执行,数据和代码都对应着多份,但最左边的数据流图仍把每个 computation 抽象成数据流图的一个节点来表示。
集群中设备被分成很多组,每个组包含一批互联成 mesh 拓扑的同质设备,称为一个 island (一般表示一个 POD),一个 island 内部的设备可以通过称为 ICI 的高速连接通信,island 之间则需要通过带宽低一些的DCN(RDMA)来通信。每个 island 上有一个中心化的 scheduler 来实现该 island 上的群调度,一个island 内部每个设备都有一个运行在对应 host (CPU)上的 executor,同一个 island 上的 SPMD 内部会发生集群通信,相邻的 SPMD 之间也会通过 ICI 传输中间结果。
3
Pathways 如何工作?

首先对 Pathways 系统做一个鸟瞰式介绍,再去深入讨论每一个具体问题。
第①步,用户想运行一个由多个 computations(SPMD)构成的 traced program(MPMD)时,通过调用 Client library 来使用 Pathways 系统。
第②步,Client 为之前没有运行过的 computation 分配虚拟设备(virtual devices),并向 Resource Manager 注册这个 computation,也就是获得虚拟设备对应的物理设备(physical devices)。
第③步,client 触发后台服务器对 computations 进行编译:首先,基于 MLIR 的 dialect 构造一个设备无感(location-agnostic)的中间表示 (IR),这个 IR 通过一系列标准的编译(pass)被逐步降低(lowered)成一个感知设备物理位置的底层表示。值得一提的是,这个底层表示已经考虑了物理设备之间的网络连接,以及不同 computation 之间的数据路由操作。如果 program 的虚拟设备对应的物理设备不发生变化,就可以非常迅捷地重复使用这个已生成的底层表示;如果 Resource Manager 改变了一个 program 的虚拟设备,就需要重新编译。
个人把①②③这三个步骤称之为 Pathways 的前端(front-end),这基本是常规做法,比较容易理解,但还没有进入到 Pathways 的核心。
第④步,Client 把编译生成的底层表示转换成一个能被 PLAQUE 识别的数据流图(dataflow graph),并发送给运行时(runtime)系统去执行。Pathways 运行时系统缺失很多细节,特别是依赖于一个语焉不详的闭源系统 PLAQUE,这是一个谷歌内部使用的、闭源的数据流执行引擎。
分布式被表示成数据流图后,就托管给 PLAQUE 来执行,分布式的协调机制(coordination)是其核心。PLAQUE 由 scheduler 和 executor 两种 long-running 的值守进程(daemon)组成,它们可以通过互相通信(箭头⑤⑥⑦)来完成分布式协调(coordination),这些是控制平面的通信。下文会详细讨论控制平面的机制。
executor 则通过调用 TensorFlow,PyTorch 或 JAX 等传统深度学习框架(箭头⑧)来完成深度学习的计算或箭头⑨表示的数据平面通信(主要是集群通信)。大家应该对传统深度学习框架都很熟悉,本文就不过多介绍了。
值得注意的是,数据平面和控制平面的通信可能使用了不同的传输介质,前者是蓝色箭头表示 ICI,带宽更高,后者是绿色箭头表示的 DCN,带宽更低一些。
4
数据流执行引擎 PLAQUE
Pathways 论文对 PLAQUE 介绍的并不多,本文尽力把这个拼图补全。
数据流(dataflow)就是把任务之间的依赖关系用一个有向无环图(DAG)表示,并基于 DAG 的拓扑顺序去执行任务。相关文献有很多,感兴趣的朋友也可以看之前的博客《对抗软件系统复杂性①:如无必要,勿增实体》。
数据流引擎有很多种实现办法,基于消息传递的 actor 系统是一个很好的选择,另一篇博客《对抗软件系统复杂性②:全局一致,统一隐喻》对此做过讨论。
虽然 Pathways 论文没有明确说 PLAQUE 是一个 actor 系统,但这基本是一个事实,原因如下:
首先,论文明确了 PLAQUE 主要用跨 host(CPU)通信来协调分布式计算,通信则是通过消息传递来实现,无论是规则的 fanin/fanout 还是不规则的 sparse 模式。
其次,论文提到了 PLAQUE 需要使用标准的进度跟踪机制(progress tracking mechanism),这其实就是 actor 抽象里的有限状态机,一般就是用计数器来记录一个 actor 的依赖条件已经了满足几个,特别是此处引用了一篇数据流系统的经典论文 《Naiad: a timely dataflow system(https://dl.acm.org/doi/pdf/10.1145/2517349.2522738)》,这篇论文获得了 SOSP 2013 最佳论文奖,Naiad 全文没有一处提到 actor 这个词,又无处不是 actor ,论文中的 graph vertex 之间的 message passing 其实就是 actor 。值得注意的是,Naiad 论文的主创也是 TensorFlow 和 Pathways 的主创,譬如 Barham、Murray、Isard、Abardi 都是当年从微软的硅谷研究院跳槽到 Google Brain 的数据流系统的大佬,他们把之前的得意之作拿过来解决新的问题再正常不过。
最后,Google 之外没有 PLAQUE 的人想实现 Pathways 该怎么办?论文在 4.3 节说了,PLAQUE 可以被任何一个通用的数据流引擎所取代(当然是在满足苛刻性能要求的前提下)。同时,论文还是为其他同行推荐了一个可能的办法,就是基于 Ray 的 long-running actor 来自己实现一个数据流引擎,当然论文也指出了 Ray 要达到 PLAQUE 的效果仍有挺多工作要做,后文也会详细讨论。
5
关于 PLAQUE 的一些问题
让我们来细致地考察一下基于 PLAQUE 实现的数据流协调系统有没有潜在的问题。
问题1:scheduler 和 executor 之间的通信是单向还是双向的?肯定是双向的,scheduler 当然可以向 executor 发送命令,executor 也可以向 scheduler 发送关于任务完成的消息,另外论文有这样一句话进行佐证,(executor) communicating with the scheduler to determine a consistent order of function executions across all programs running on the island。
问题2:不同 island 的 executor 是否可以直接通信?论文没写,理论上可以,但应该是禁止的,因为这么做会给系统带来极大的麻烦,executor 上的执行顺序本来是它所属的 scheduler 安排好的,如果允许 island #1 上的 exectuor 跳过 island #2 上的 scheduler 直接和 island #2上的 executor 通信,那么为 gang scheduling 准备的中心化的 scheduler per island 就形同虚设,仍会有死锁风险。
问题3:island #1 上的 executor 是否可以跳过 island #1 的 scheduler 直接和 island #2 的 scheduler 通信?论文没写,理论上可以。不过,如果 island #1 和 island #2 上都有数据的消费者时,生产者 executor 还是需要同时与 island #1 和 island #2 的 scheduler 协调。
这里引入了一个新问题, 在 Pathways 举的例子里,任何一个 computation (compiled function) 都能完全放在某一个 island (POD) 之内。但假如用满一个 island (POD) 的设备都无法满足这个 computation 的需求,这个 computation 必须跨越多个 island 时怎么办?这时底下的集群通信就需要同时通过 DCN 和 ICI,多个 island 的 scheduler 肯定需要协调,但 Pathways 论文没有讨论这种情况。
问题4:island #1 的 scheduler 可以和 island #2 的 scheduler 通信吗?肯定可以,不然就需要在 island scheduler 之上设置一个更大范围的中心调度器来协调。
6
从 Pathways 的视角理解 OneFlow SBP
Pathways 这篇论文的重心是运行时系统,只用了比较少的篇幅讨论了编译器如何适应这个运行时系统。论文对编译相关的内容惜墨如金,但还是在多处反复强调了同一个问题:sharded dataflow graph,想必这是作者眼中很重要的事情。
不熟悉这个领域的人很容易忽略字眼背后的意思,我把论文中和 sharded dataflow 相关的句子都摘抄出来(可以跳过这些英文先看后面的讨论,回头再用英文印证)。
PATHWAYS uses a sharded dataflow graph of asynchronous operators that consume and produce futures, and efficiently gang-schedules heterogeneous parallel computations on thousands of accelerators while coordinating data transfers over their dedicated interconnects. (Abstract)
We have addressed the key limitations of older client-server ML systems using a sharded dataflow model and asynchronous gang-scheduling. (1. Introduction)
Finally, a system for modern ML workloads must be designed to run computations distributed over thousands of accelerators, with first class support for sharded representations and data structures. For instance, a naive dataflow graph representing an edge between an M-way sharded computation and an N-way sharded computation would require M + N nodes and M × N edges, rapidly becoming unwieldy. (2. Design motivation)
TF also materializes the full sharded computation graph, which introduces substantial overhead in both graph serialization and execution when the number of shards reaches into the thousands, leading to millions of graph edges between sub-computations. (2. Design motivation)
These XLA computations are usually characterized by known input and output types and shapes, bounded loops, and with few (if any) conditionals (see Appendix B for more details) making it feasible to estimate the resource requirements of computations in advance. We refer to these computations with known resource requirements as “compiled functions”. Each such function maps to a single (sharded) computation node in a PATHWAYS program. (3. Pathways programming model)
We convert each compiled function into a standalone PATHWAYS program containing just one (sharded) computation. (3. Pathways programming model)
The tracer generates a single PATHWAYS program where each compiled function is represented by a computation node in a dataflow graph. (3. Pathways programming model)
The client in older single controller systems can quickly become a performance bottleneck as it coordinates thousands of individual computations and data buffers corresponding to each shard of computations spread across thousands of accelerators. The PATHWAYS client uses a sharded buffer abstraction to represent a logical buffer that may be distributed over multiple devices. This abstraction helps the client scale by amortizing the cost of bookkeeping tasks (including reference counting) at the granularity of logical buffers instead of individual shards. (4.2 Client)
First, the representation used to describe the PATHWAYS IR must contain a single node for each sharded computation, to ensure a compact representation for computations that span many shards, i.e. a chained execution of 2 computations A and B with N computation shards each should have 4 nodes in the dataflow representation: Arg → Compute(A) → Compute(B) → Result, regardless of the choice of N. In the PLAQUE runtime implementation each node generates output data tuples tagged with a destination shard, so when performing data-parallel execution N data tuples would flow, one between each adjacent pair of IR nodes. (4.3 Coordination implementation)
其实,上面所有的文字都在说一件事:把每个 SPMD 当成一个节点,MPMD 可以表示成多个 SPMD 构成的抽象层次相对高的 DAG。每个 SPMD 做规则和对称的并行计算,可以被编译成一个 compiled function,内部是更低层次的 DAG。

如上图所示,左半部分表示由 A 和 B 两个 SPMD 构成的 DAG (逻辑层次)。假设 A 并行度是 3,B 并行度是 2,右半部分表示把 A 和 B 按照 sharding 展开后更细致的 DAG (物理层次)。Pathways 的想法是,如果在最细致的 DAG 层次来推理和处理,工作量太大,开销很大,所以在 Client 等处只需要处理逻辑层次的 DAG 就可以。
其实 OneFlow 早已用了这个想法,用 global tensor 表示逻辑张量,用 local tensor 表示物理张量,通过 SBP 实现了逻辑和物理表示之间的转换规则。
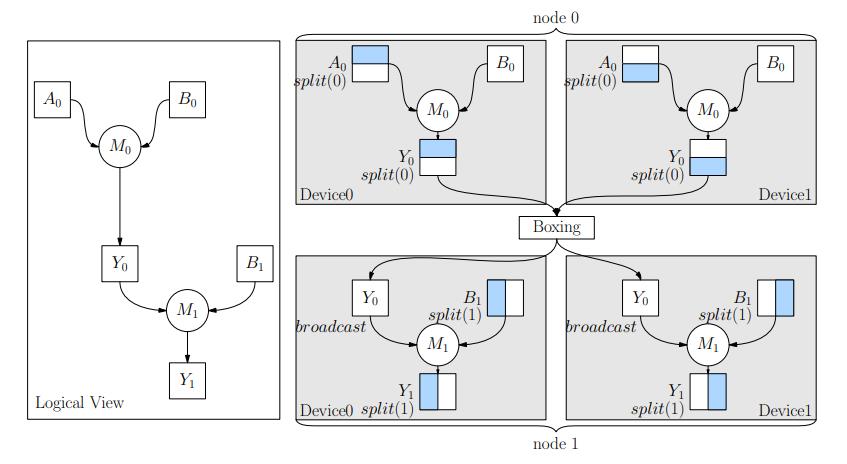
上图左半部分相当于逻辑层次的数据流图,右半部分相当于是物理层次的数据流图。对这个问题感兴趣的朋友可以阅读 GSPMD 论文《GSPMD: General and Scalable Parallelization for ML Computation Graphs(https://arxiv.org/pdf/2105.04663.pdf)》和 OneFlow论文《OneFlow: Redesign the Distributed Deep Learning Framework from Scratch(https://arxiv.org/pdf/2110.15032.pdf)》。二者还有一些微妙的区别,我在博客 《如何超越数据并行和模型并行:从 GShard 谈起》也做过对比讨论。值得一提的是,PyTorch 正在推进一个和 SBP 抽象一样的方案(https://github.com/pytorch/pytorch/issues/72138),不过那里的逻辑张量被称为 ShardedTensor。百度 PaddlePaddle 也在最近引入了 global tensor 这样的抽象。
7
从 Pathways 的视角理解 OneFlow Actor
前面我们介绍了 Pathways 使用 PLAQUE 实现的数据流引擎来协调分布式设备上运行的传统深度学习框架。PLAQUE 实质上是一个用 actor 机制实现的数据流执行引擎,很多朋友知道 OneFlow 的运行时系统就是用 actor 实现的,二者有什么异同?如果把 Pathways 的运行时系统用 OneFlow 的理念代替,整个系统会变成下图这样。
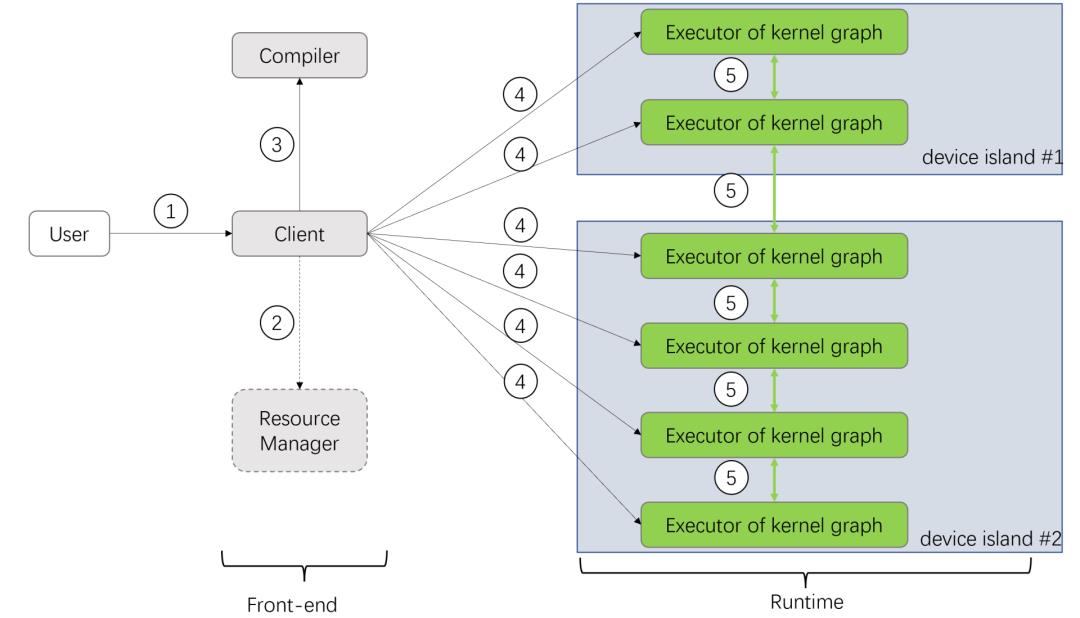
第一,OneFlow actor 实现了运行时真正的去中心化调度。为避免一些死锁问题,Pathways 通过为每个 island 准备一个中心化的 scheduler 来实现群调度(gang scheduling)。但正如我们刚才讨论的那样,这种 scheduler per island 的方案还是有缺陷的。
在博客《解读 Pathways(一)》文末,我提到,不见得非得用中心调度才能避免死锁,也可以通过完全静态调度实现,静态调度相当于一种 ahead of time 的中心调度,OneFlow 正是这么做的,不需要为每个 island 设置一个中心化的 scheduler,也不需要所谓 gang scheduling,这是一种更极致的去中心化调度。
第二,OneFlow 消除了 executor 和传统深度学习框架之间的隔阂。在 Pathways 里,PLAQUE 的 executor 会调用本地安装的深度学习框架 TensorFlow/PyTorch/JAX,二者之间有一个基于 future 的异步交互机制:(i) enqueueing the execution of local compiled functions at each accelerator, with buffer futures as inputs; (ii) enqueueing network sends to remote accelerators for the buffer futures output by function executions。
这也是 TensorFlow 正在重构的新版 runtime 所使用的机制(https://github.com/tensorflow/runtime/blob/master/documents/async_value.md),它可以被理解成一种用于在线、动态的构建数据流图的语法糖。Pathways 宏观的分布式用了 message passing 的方式实现异步 coordination,在局部单设备内部使用了 async value 的方式实现异步。而 OneFlow 重起炉灶从零设计和研发分布式框架,有机会在宏观和微观上使用统一的方式来实现异步,那就是全部基于 actor 之间的 message passing。这一点在博客《对抗软件系统复杂性②:全局一致,统一隐喻》里有详细讨论。
第三,OneFlow 已自然而优雅地支持了 Pathways 的并行异步分发(Parallel asynchronous dispatch)。

如上图(a)所示,Pathways 举了一个串行派发任务的例子:有三个计算任务 A, B, C 分别运行在三个不同的设备 A, B, C 上(不产生混淆的情况下,我们把设备、设备对应的host以及在它们上面运行的任务用同一个字母来表示)。生产和消费关系是 A->B->C。Host A 把任务 A 异步地插入设备 A 的任务队列,返回一个保存任务 A 输出结果的 future,并把这个 future 发送给 host B 使用。host B 为任务 B 的输入分配内存,并把内存地址传给 host A (同时在 host B 上启动recv),并为启动任务 B 做好必要准备。当任务 A 执行结束时,它的输出被直接通过高速连接 ICI 从设备 A 发送到为任务 B 分配好的输入缓冲区,随后 host B 可以在设备 B 上启动任务 B。从 B 到 C 的执行过程和从A到B类似,不再赘述。
上述过程有什么问题?当任务在设备上执行时间相对于 host 上做准备的时间(包括调度、分配资源和 host 之间的协调等)明显长的多的情况,上述方案问题不大。但当任务在设备上执行时间非常短的时候(上图(a)所示的情况),异步流水线就会出现停顿,因为 host 上的执行逻辑变成了系统瓶颈。
怎么解决这个问题?核心洞察是:大部分深度学习模型都是静态的,下游输入对应的张量形状都可以在编译阶段提前获得,不需要等到上游任务异步入队列那一刻。因此,如上图(b)所示,Pathways 用了所谓的并行异步分发,基于 compiled function 提前可知的、静态的资源需求量的事实,提前启动 host 上的工作,譬如上图中的 recv 就被提前启动了。
这个想法还是很高明的。其实,OneFlow 也早就利用了这一点,我们称之为静态调度(利用静态已知的信息)和流式执行(提前启动可以提前的工作以实现流水线),关于这一点,此前的博客《对抗软件系统复杂性①:如无必要,勿增实体》也有详细讨论。

第四,OneFlow 设计了基于消息传递的内存所有权(ownership)转移和引用计数规则来高效率地使用内存资源。内存管理是分布式深度学习框架极其关键的问题,Pathways 建议使用像 Ray 一样的 Object store 和所有权归属机制(ownership)来管理内存,不过对此仅用一句话一带而过(The objects are tagged with ownership labels so that they can be garbage collected if a program or client fails.)。如果你想补全这个拼图,可以看 Ray 团队在 NSDI 2021 上发表的论文《Ownership: A Distributed Futures System for Fine-Grained Tasks(https://stephanie-wang.github.io/pdfs/nsdi21-ownership.pdf)》。
PyTorch 的 remote reference 机制也使用了类似的思路(https://pytorch.org/docs/stable/rpc/rref.html)。这还是一种动态内存管理的思路,在深度学习场景不是最优的办法。不利用深度学习模型的领域知识,就只能做基于作用域的垃圾回收,作用域可能比某些 object 的真实生命周期宽(一个 object 还没出作用域就可能已经可以释放了)。在用户用 Ray 写的代码里,一个 object 甚至可能没有作用域,生命周期是无限的,系统永远都不敢删除,为此 Ray 还实现了一个定期把数据从内存向磁盘 flush 的机制,这在深度学习里都是不可接受的。下文我们还会专门讨论 Ray。
正如可以利用静态已知信息来设计并行异步分发一样,深度学习框架的内存管理也可以充分利用静态图的完整信息进行优化。OneFlow 定义了内存所有权的机制,张量的生产者对张量有读写权限,可以通过消息传递来转移对内存的读写权限,这样既可以解决读写冲突,也可以基于消息传递的引用计数方法来解决内存的及时回收(比 Ray 的 distributed reference counting protocol 出现的更早,在深度学习里也更优),感兴趣的朋友可以阅读 OneFlow 论文。总之,当利用深度学习的领域知识时,内存管理可以变得更有效。
第五,OneFlow 已基于 credit-based flow control 方法实现了背压机制(back-pressure)。这对全链路异步的流水线非常重要,但 Pathways 只用一句话提到了这个问题,并没有详细讨论(We can use simple back-pressure to stall a computation if it cannot allocate memory because other computations’buffers are temporarily occupying HBM)。
OneFlow 核心的想法是:在静态分析阶段,通过软件流水线(software pipelining)技术分析得到每个流水线阶段的最优资源配额(内存或显存),如上图的 a1 有 3 个配额,a2 和 a3 只有 2 个配额,每个算子都只能在自己的配额范围内使用资源,一旦用完即使输入数据都就绪也不能启动(即 Pathways 描述的stall)。感兴趣的朋友可以阅读OneFlow论文或此前的博客《Credit-based flow control 的前世今生》。
上述每个问题都挺复杂,展开讨论都可以单独写一篇文章,但无论如何,OneFlow 用一个统一、简洁的机制就把上述问题都解决了,所以我们在刚开始写 OneFlow 的论文时,一度想用《OneFlow: a minimal design of distributed deep learning framework》这样一个也属于“找死”类型的标题。我们设计和研发 OneFlow 时的确秉持了”最简即最正确“的理念 ,从各种角度看,用 actor 这个抽象来实现分布式深度学习系统都是最简单的选项。
我们注意到,最近华为 Mindspore 和百度 PaddlePaddle 都已经跟进了 actor 这个理念,现在 Google Pathways 也来为这个想法站台了。还有一件值得注意的事情是,actor 抽象也会为软硬件协同设计带来极大便利,最近大火的 Tenstorrent 简洁的软件栈也有所体现《Tenstorrent 虫洞芯片分析》。
8
OneFlow 可以向 Pathways 学习什么?
OneFlow 使用了极致的静态调度理念,每个 actor 在运行时是绑定到固定的CPU和设备上,显然,这会给容错、弹性计算、多租户共享资源带来一些挑战,博客《动态调度的“诅咒”》讨论过这一问题。
Pathways 论文对此用较多篇幅进行了讨论,基本思路是引入虚拟设备,先解决 compiled function 和虚拟设备的映射,然后再用 Resource Manager 来解决虚拟设备和物理设备的映射。这是计算机系统里很经典的解决问题的思路,即额外引入一层抽象或虚拟化,这比较容易理解,在此不再展开讨论,感兴趣的朋友可以阅读博客《再谈“去虚拟化”对深度学习系统的必要性》。
OneFlow 可以直接使用 Pathways 引入的中心调度器和 Resource Manager 来解决任务和设备的映射问题。在基于 actor 的数据流系统中,每个 actor 可以被理解成一个路由器,数据在 actor 系统里的流动就像在网络里传输的数据包,引入的 Resource Manager 有点像 DNS 服务器,当消息发出方发现目的地的地址发生变化时,可以在从 Resource Manager 这里查询到目的地的新地址之后再发消息和传输数据。
Pathways 花了不少篇幅讨论这个问题,但论证以及实验支撑存在不足,即使是随后不久发表的PaLM 大模型也并没有体现出来多少动态性。既然无法充分论证这个问题,完全可以把这部分内容全部删除,用另外一篇论文专门研究这个问题。不知道审稿人有没有提出意见,我怀疑,如果换成其他人在一篇论文里“兜售”过多观点,但又无法提供有力支撑,一定会被 challenge。这种做法也很不公平,一些大佬在工作不成熟的情况下先把坑占住,后来者即使做的再好都会被审稿人挑战 novelty,恐怕最后就没法发表。
最近学术界的确有几个相关工作在研究 elastic training,需要解决 exclusive ownership of resource 的问题,我的谨慎判断是,这个现状在中短期内不会发生改变,有可能长期也不会改变,主要原因是让任务飘来飘去得不偿失,computation 对应的设备每发生一次变化,都要重新编译一次 (It is efficient to repeatedly run the low-level program in the common case that the virtual device locations do not change, and the program can be re-lowered if the resource manager changes the mapping between virtual and physical devices),迅速解决这个问题非常具有挑战性(The scheduler must implement policies for allocating accelerators at a time-scale of milliseconds)。
9
Ray 距离 Pathways 有多远?
Pathways 论文已经讨论了使用 Ray 来实现的可能性,指出了一些很重要但 Ray 还没做的事,包括:(1) object store 支持 HBM 等设备内存管理;(2)支持设备间高速数据传输,譬如NVLink 和 RDMA;(3) 基于 Ray 开发一个数据流引擎进行依赖管理。
第一个问题是显而易见的,前文我们也讨论过,设备内存(显存)非常珍贵,一定要有效利用,但 Ray 作为一个通用计算框架不能利用面向特定领域的需求引入对通用系统显得过度的假设,只能使用作用域来管理生命周期,作用域来管理深度学习张量的生命周期并非最优,还有的场合没有显式的作用域,Ray 的作者非常清楚这一点,论文里也提到了:
Given the workload generality, specialized optimizations are hard. For example, we must make scheduling decisions without full knowledge of the computation graph. Scheduling optimizations in Ray might require more complex runtime profiling. In addition, storing lineage for each task requires the implementation of garbage collection policies to bound storage costs in the GCS, a feature we are actively developing.

第二个问题,如上图所示,Ray 主要使用 gRPC 通信,缺乏对 NVLink 和 RDMA 的支持,也缺乏集群通信的支持。不过,Ray 在积极向深度学习系统领域发展,他们也意识到了这个问题,已开展各种增强 Ray 通信功能的工作,包括让 Ray 支持高速集群通信(https://arxiv.org/pdf/2002.05814.pdf)。对这个问题感兴趣的朋友可以阅读《对抗软件系统复杂性③:恰当分层,不多不少》。
第三个问题,有人可能以为用 Ray 的 actor 实现一个数据流引擎即可,没错,Ray 如果连这个都实现不了那还称得上通用分布式计算框架吗?事实上 Ray 已经有了一套用于解决 Workflow 的接口,问题是是否满足深度学习的性能要求。另外,把 Ray 用到深度学习系统里还是有一个不易察觉的大“陷阱”,那就是 Ray 通过 object store 和 RPC 机制实现了一套“自动”的数据搬运机制 (object 在 object store 之间的隐式迁移),本意当然是帮上层用户着想,让他们不用再操心复杂的数据搬运,但这个“自作主张”,“越俎代庖”之举在深度学习里会帮倒忙,不是做少了,而是做过了。
在深度学习系统里,数据搬运是一等公民,深度学习框架需要像对待数据计算一样重视且全权管理,不能把数据搬运委托给更底层的机制以至于数据搬运隐式地在背后发生,丧失宝贵的确定性和可预测性,必须把数据搬运像计算一样作为算子显式的调度管理。虽然 TensorFlow 没有基于 Ray 开发,但也存在这个问题,感兴趣的朋友可以阅读《数据搬运的“诅咒”》。多说一句,做 AI 芯片的朋友对这一点体会最深,通用 CPU 都使用 cache 机制,硬件自动完成预取的工作,让软件开发更简单,但仍存在 cache miss rate 的问题,AI 芯片不能承受这个代价,再加上深度学习任务有显著的规律,所以更希望让软件显式的管理缓存何时预取数据,这里普遍使用一种叫 scratchpad 的技术,以实现100%的”命中“。
总之,Ray 作为通用分布式计算框架(RPC, actor, object store三件套),当应用到深度学习系统时,还是要向专门化和静态化的方向做不少工作。
OneFlow 在向 MLSys 投稿时,有个审稿人说,Ray 已经用了 actor, 这篇论文没有 novelty,他显然没有思考过这些问题,也没有仔细阅读我们的论文。
10
总结
Pathways 在 single-controller 和 multi-controller 上花了不少篇幅,但正如在上一篇博客中讨论的那样,这一点并不本质。
Pathways 提出用 centralized scheduler 和 Resource Manager 解决设备共享、弹性计算的问题,这一点是有趣,但文章几乎仅仅是抛出观点,实验证据非常薄弱。
Pathways 提出的 sharded dataflow graph,以及基于 PLAQUE 的协调系统是最有价值的部分,但几乎全方位弱于 OneFlow 的设计方案,每个方面都再向前走一步才是 OneFlow。
如果 Google 认为 Pathways 是下一代 AI 架构,那么,比 Pathways 更超前的 OneFlow 是哪一代?
Pathways 被 MLSys 录用了,而投稿的 OneFlow 却被拒了。那么,MLSys 的录用标准是什么?
其他人都在看
欢迎下载体验OneFlow v0.7.0最新版本:GitHub - Oneflow-Inc/oneflow: OneFlow is a performance-centered and open-source deep learning framework. https://github.com/Oneflow-Inc/oneflow/
https://github.com/Oneflow-Inc/oneflow/
以上是关于解读 Pathways :向前一步是 OneFlow的主要内容,如果未能解决你的问题,请参考以下文章