面试必备:一文讲透树模型
Posted Python学习与数据挖掘
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了面试必备:一文讲透树模型相关的知识,希望对你有一定的参考价值。
决策树模型因为其特征预处理简单、易于集成学习、良好的拟合能力及解释性,是应用最广泛的机器学习模型之一。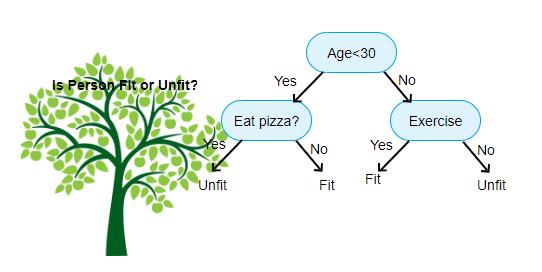
不同于线性模型【数学描述:f(W*X +b)】是通过数据样本学习各个特征的合适权重,加权后做出决策。决策树会选择合适特征并先做特征划分后,再做出决策(也就是决策边界是非线性的,这提高了模型的非线性能力)。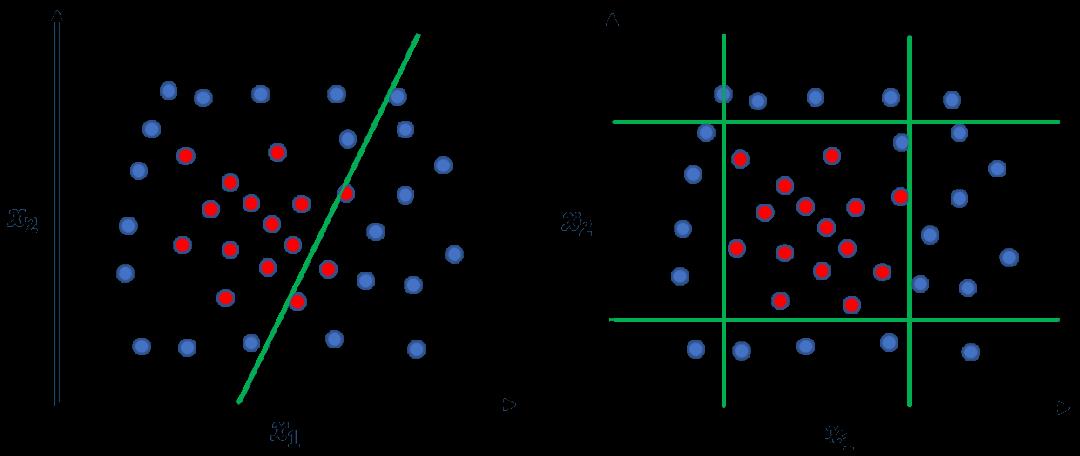
一、树模型的概括
决策树呈树形结构,更通俗来讲,树模型的数学描述就是**“分段函数”**。如下一个简单判别西瓜质量的决策树模型示例(注:以下西瓜示例,数据随机杜撰的,请忽略这么小的西瓜瓜~):

学习这样树模型的过程,简单来说就是从有监督的数据经验中学习一个较优的树模型的结构:包含了依次地选择特征、确定特征阈值做划分的内部节点及最终输出叶子节点的数值或类别结果。

-
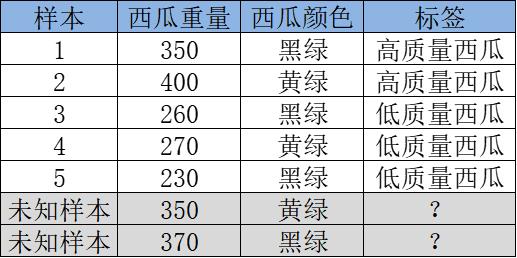
1、我们首先要拿到一些有关西瓜的有监督数据(这些西瓜样本已有标注高/低质量西瓜),并尝试选用决策树模型来学习这个划分西瓜的任务。如下数据样本示例:
-
2、后面也就是,凭着已知西瓜样本的特性/特征【如:西瓜重量、西瓜颜色】,学习如何正确地划分这些西瓜(归纳出本质规律)。开始学习之前,我们得确定一个树模型在生长的目标(学习的目标)。简单来说,也就是在当前节点以什么为目标来指导怎么选择特征及分裂,而划分得好也就是要划分出的各组的准确率(纯度)都比较高。
-
3、然后,根据学习目标,简单的我们可以通过遍历计算所有特征不同阈值的划分效果。选择各个的特征及尝试特征的所有实际取值,看以哪个特征阈值划分西瓜质量的效果较好。这个过程也就是确定选择特征及特征阈值划分的优化算法。
-
4、最终的,按照上面的步骤,我们逐个特征及取值试着去划分后发现,根据西瓜重量的特征 以300g作为划分出了两组,我们以叶子节点的大多数类作为该节点的决策类别。可能发现<300的组 里面低质量西瓜占比100%,>300 那组 高质量西瓜占比99%,整体分类效果是不错的,最终就确定下了这样的一个决策树模型。
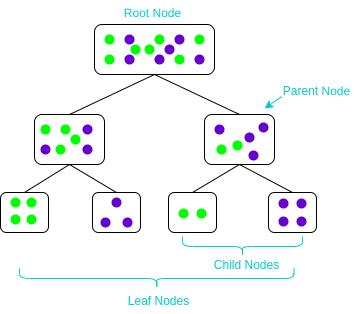
二、树模型的要素
从上述例子,我们可以将树模型的学习可以归到经典机器学习的4个要素:
-
2.0 已知(标签)的数据
-
2.1 树模型的结构(分段函数结构:特征划分+决策结果)
-
2.2 学习目标
-
2.3 优化算法
树模型通过结合这几个要素,更快更好地划分特征空间,得出比较准确的决策。如下对这几个要素具体解析。
2.1 树模型的结构
树模型的结构也就是个分段函数,包含了 选定特征做阈值划分(内部节点),以及划分后赋值的分数或类别决策(叶子节点)。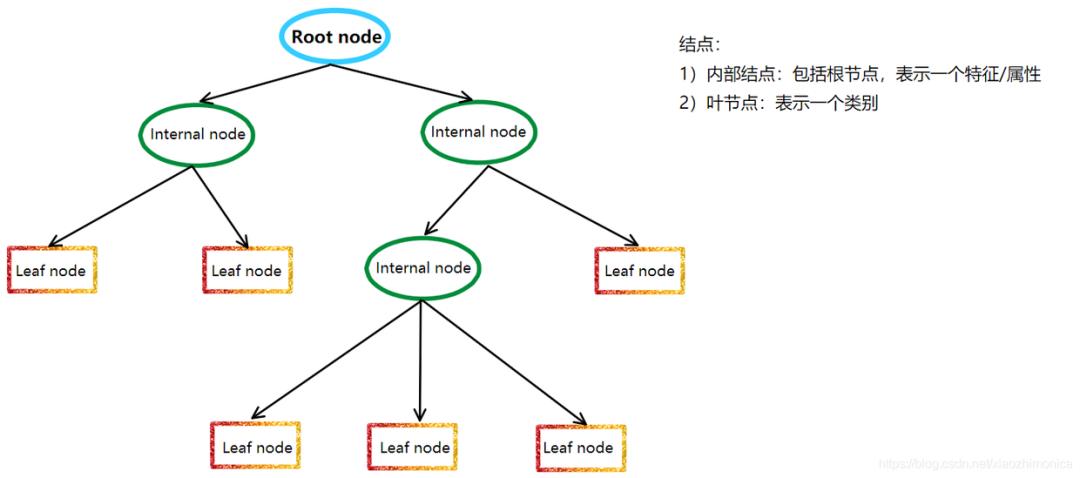
2.1.1学习树结构的过程
学习树模型的关键在于依据某些学习目标/指标(如划分准确度、信息熵、Gini不纯度、均方误差的增益量)去选择当前最优的特征并对样本的特征空间做非线性准确的划分,如上面西瓜的例子选择了一个特征做了一次划分(一刀切),通常情况下仅仅一刀切的划分准确度是不够的,可能还要在前面划分的样本基础上,继续多划分几次(也就多个切分条件的分段函数,如 if a>300 且特征b>10 且特征c<100, then 决策结果1;),以达到更高的准确度(纯度)。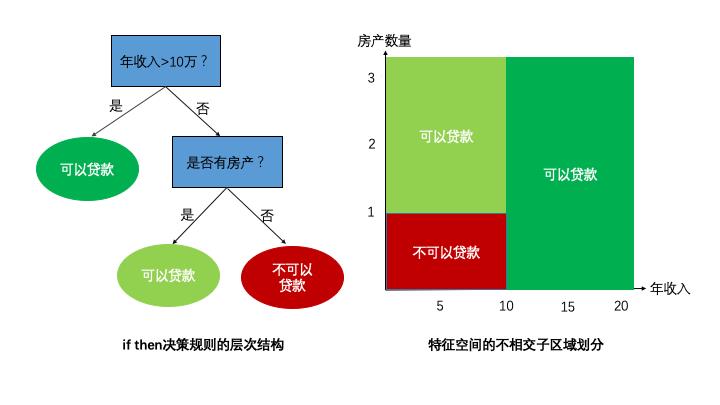 但是,随着切分次数的变多,树的复杂度提高也就容易过拟合,相应每个切分出的小子特征空间的统计信息可能只是噪音。减少树生长过程的过拟合的风险,一个重要的方法就是树的剪枝,剪枝是一种正则化:由于决策树容易对数据产生过拟合,即生长出结构过于复杂的树模型,这时局部的特征空间会越分越“小”得到了不靠谱的“统计噪声”。通过剪枝算法可以降低复杂度,减少过拟合的风险。
但是,随着切分次数的变多,树的复杂度提高也就容易过拟合,相应每个切分出的小子特征空间的统计信息可能只是噪音。减少树生长过程的过拟合的风险,一个重要的方法就是树的剪枝,剪枝是一种正则化:由于决策树容易对数据产生过拟合,即生长出结构过于复杂的树模型,这时局部的特征空间会越分越“小”得到了不靠谱的“统计噪声”。通过剪枝算法可以降低复杂度,减少过拟合的风险。
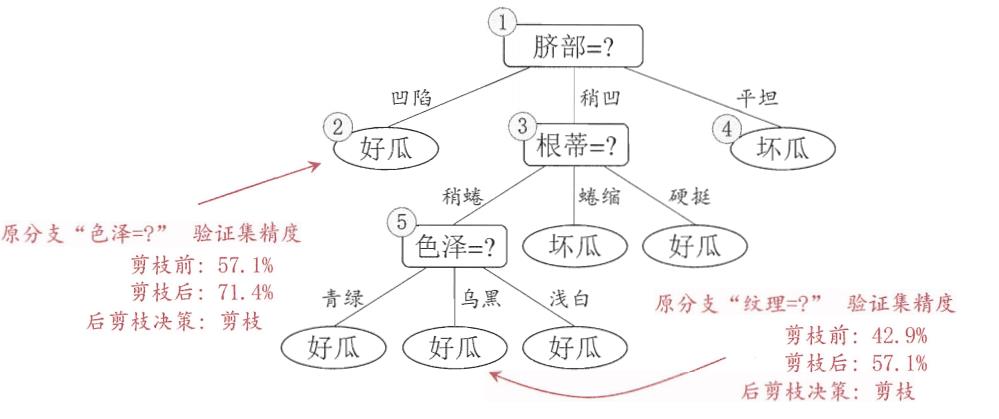
决策树剪枝的目的是极小化经验损失+结构损失,基本策略有”预剪枝“和”后剪枝“两种策略:①预剪枝:是在决策树生成过程中,限制划分的最大深度、叶子节点数和最小样本数目等,以减少不必要的模型复杂度;②后剪枝:是先从训练集生成一棵完整的决策树,然后用用验证集自底向上地对非叶结点进行考察,若将该节点对应的子树替换为叶子结点(剪枝)能带来决策树的泛化性能提升(即目标函数损失更小,常用目标函数如:loss = 模型经验损失bias+ 模型结构损失α|T|, T为节点数目, α为系数),则将该子树替换为叶子结点。
2.1.2 复杂树结构的进阶
- 树模型的集成学习
实践中可以发现,浅层的树很容易欠拟合,而通过加深树的深度,虽然可以提高训练集的准确度,却很容易过拟合。
这个角度来看,单个树模型是比较弱的,且很容易根据特征选择、深度等超参数调节各树模型的多样性。正因为这些特点,决策树很适合通过结合多个的树模型做集成学习进一步提升模型效果。
集成学习是结合一些的基学习器共同学习,来改进其泛化能力和鲁棒性的方法,主流的有两种集成思想:
-
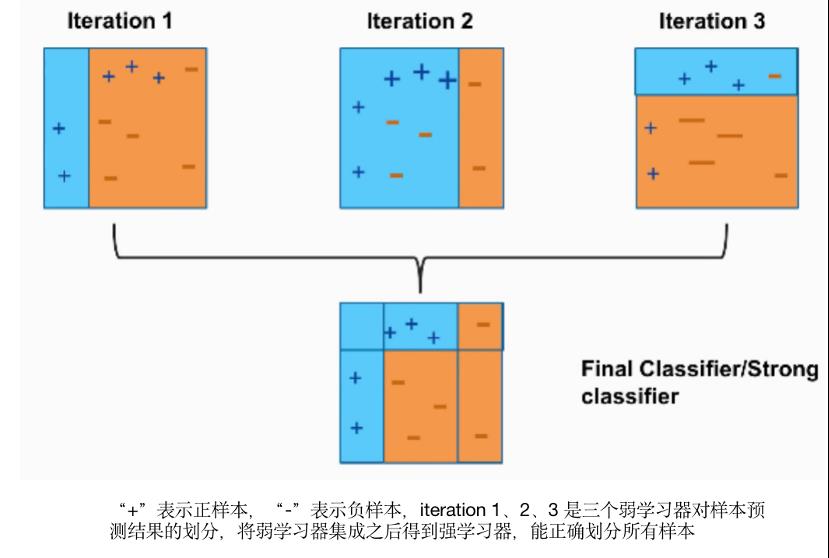
并行方式(bagging):独立的训练一些基学习器,然后(加权)平均它们的预测结果。代表模型如:Random Forests;
-
串行方式(boosting):一个接一个的(串行)训练基学习器,每一个基学习器主要用来修正前面学习器的偏差。代表模型如:AdaBoost、GBDT及XGBOOST;(扩展:像基于cart回归树的GBDT集成方法,通过引入了损失函数的梯度去代替残差,这个过程也类似局部的梯度下降算法)
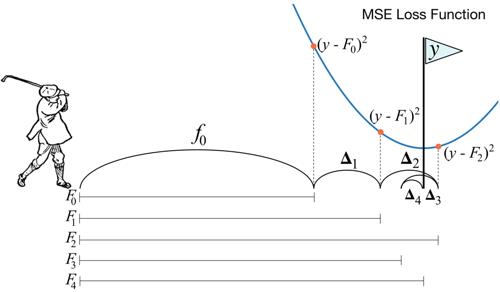
- 线性决策树
树模型天然具有非线性的特点,但与此有个缺陷,树模型却学习不好简单的线性回归!可以简单构想下传统决策树表达 y=|2x|这样规律,需要怎么做?如 if x=1,then 2; x =3, then 6 .....;这样穷举显然不可能的。这里介绍下线性决策树,其实原理也很简单:把线性回归加到决策树的叶子节点里面(特征划分完后,再用线性模型拟合做决策)。一个简单线性树模型用分段函数来表示如:if x >0, then 2x;代表模型有 linear decision tree, GBDT-PL等模型。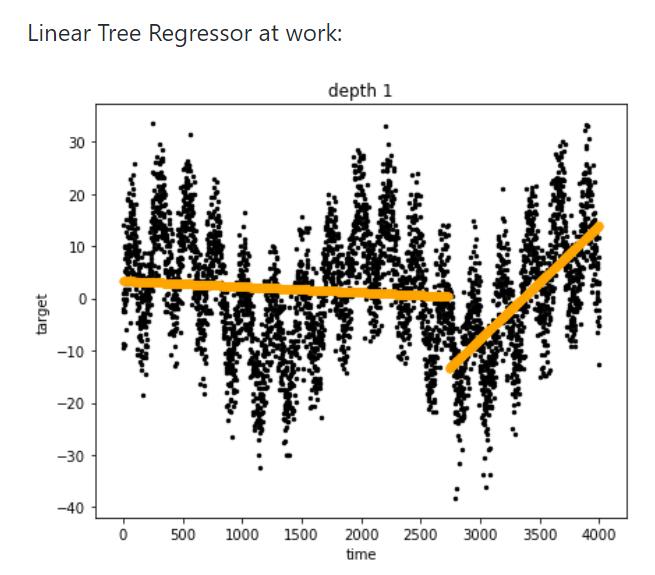
2.2 学习目标(目标函数)
上文有提到,树模型的学习目标就是让各组的划分的准确率(纯度)都比较高,减小划分误差损失(此处忽略了结构损失T)。能达成划分前后损失差异效果类似的指标有很多:信息熵、基尼系数、MSE损失函数等等 都可以评估划分前后的纯度的增益 ,其实都是对分类误差的一种衡量,不同指标也对应这不同类型的决策树方法。
- ID3决策树的指标:信息增益(information gain) 信息增益定义为集合 D 的经验熵 H(D) 与特征 A 给定条件下 D 的经验条件熵 H(D|A) 之差,也就是信息熵减去条件信息熵,表示得知特征X的信息而使得Y的信息的不确定性减少的程度(信息增益越大,表示已知X的情况下, Y基本就确定了)。
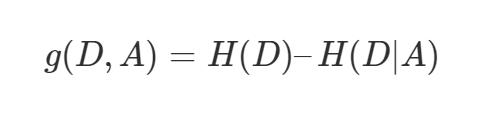
使用信息增益做特征划分的缺点是:信息增益偏向取值较多的特征。当特征的取值较多时,根据此特征划分更容易得到纯度更高的子集,因此划分之后的熵更低,由于划分前的熵是一定的,因此信息增益更大,因此信息增益比较偏向取值较多的特征。
- C4.5决策树的指标:信息增益比
信息增益比也就是信息增益除以信息熵,这样可以减少偏向取值较多信息熵较大的特征。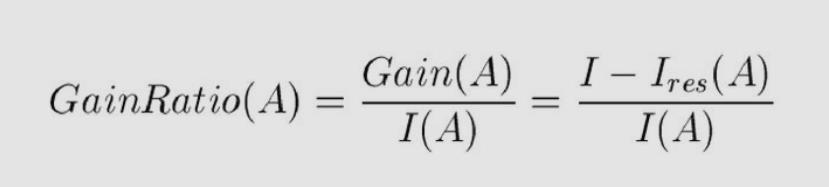
相应的,使用信息增益比缺点是:信息增益比偏向取值较少的特征。综上两种指标,可以在候选特征中找出信息增益高于平均水平的特征,然后在这些特征中再选择信息增益率最高的特征。
- Cart决策树的指标:基尼系数(分类树) 或 平方误差损失(回归)
与信息熵一样(信息熵 如下式)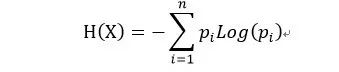
基尼系数表征的也是事件的不确定性(不纯度),也都可以看做是对分类误差率的衡量。

我们将熵定义式中的“-log(pi)”替换为 1-pi 也就是基尼系数,因为-log(pi)的泰勒近似展开第一项就是1-pi。基尼系数简单来看就是熵的“平替版”,在衡量分类误差的同时,也简化了大量计算。
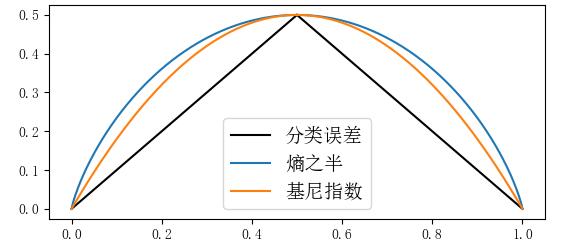
(注:由于分类误差为分段函数=1-max(p, 1-p) ,不便于微分计算,实际中也比较少直接用)
当Cart应用于回归任务,平方误差损失也就是Cart回归树的生长指标。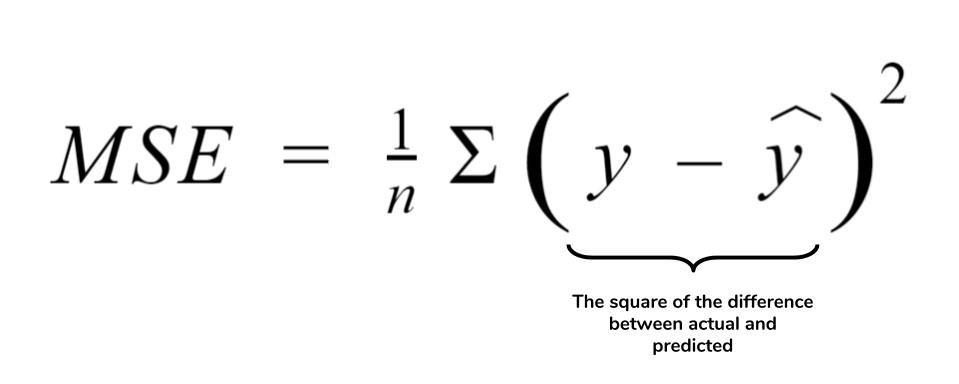
2.3 优化算法
确认学习目标,而依据这个指标去学习具体树结构的方法(优化算法),基本上有几种思路:
-
暴力枚举:尝试所有可能的特征划分及组合,以找到目标函数最优的树结构。但在现实任务中这基本是不可能的。
-
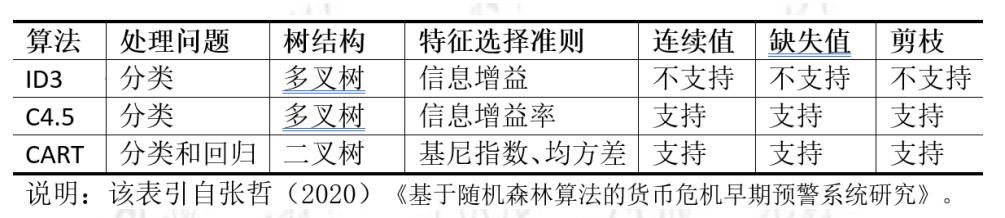
自上而下的贪心算法:每一步(节点)都选择现在最优(信息增益、gini、平方误差损失)的特征划分,最终生成一颗决策树,这也是决策树普遍的启发式方法,代表有:cart树、ID3、C4.5树等等
-
随机优化:随机选择特征及划分方式,通常这种方法单树的生长较快且复杂度较高。模型的随机性、偏差比较大(模型的方差相对较小,不容易过拟合,但是bias较大),所以常用集成bagging的思路进一步优化收敛。代表有:Extremely randomized trees(极端随机树)、孤立森林等等.
总结
树模型也就是基于已知数据上, 通过以学习目标(降低各划分节点的误差率)为指导,启发式地选择特征去划分特征空间,以各划分的叶子节点做出较"优"的决策结果。所以,树模型有非常强的非线性能力,但是,由于是基于划分的局部样本做决策,过深(划分很多次)的树,局部样本的统计信息可能失准,容易过拟合。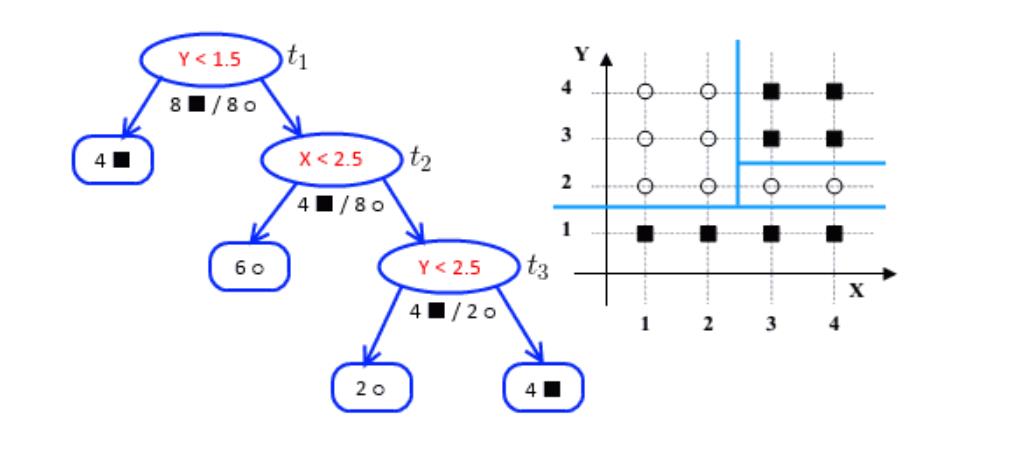
推荐文章
技术交流
欢迎转载、收藏、有所收获点赞支持一下!

目前开通了技术交流群,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友
- 方式①、发送如下图片至微信,长按识别,后台回复:加群;
- 方式②、添加微信号:dkl88191,备注:来自CSDN
- 方式③、微信搜索公众号:Python学习与数据挖掘,后台回复:加群

以上是关于面试必备:一文讲透树模型的主要内容,如果未能解决你的问题,请参考以下文章