MySQL索引
Posted 364.99°
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL索引相关的知识,希望对你有一定的参考价值。
1.概述
索引: 帮助mysql提高查询效率的数据结构。
索引的优点:
- 提高查询速度
- 确保数据的唯一性
- 可以加速表和表之间的连接 , 实现表与表之间的参照完整性
- 使用分组和排序子句进行数据检索时 , 可以显著减少分组和排序的时间
- 全文检索字段进行搜索优化
索引的缺点:
- 创建和维护的时间成本高,且这个成本随着数据量的增加而加大
- 创建和维护的空间成本高,每一条索引都要占据数据库的物理存储空间,数据量越大,占用空间也越大(数据表占据的是数据库的数据空间)
- 会降低表的增删改的效率,因为每次增删改索引需要进行动态维护,导致时间变长
索引分类:
- a.主键索引
primary key默认加索引,主键索引不能为空
-- 主键索引在创建表的时候自动创建
CREATE TABLE `t_user` (
`id` INT(19) PRIMARY KEY,
`name` VARCHAR(20)
);
-- 查看表的索引
SHOW INDEX FROM `t_user`;
- b.单值索引/普通索引
一个索引只有单列,但是可以拥有多个
-- 建表之后新建普通索引
CREATE INDEX `name_index` on `t_user`(`name`);
-- 删除表
DROP TABLE `t_user`;
CREATE TABLE `t_user` (
`id` INT(19) PRIMARY KEY,
`name` VARCHAR(20),
KEY(`name`) #创建表时创建普通索引
);
- c.唯一索引
值必须唯一,允许为空(但只能有一个为空)
-- 删除表
DROP TABLE `t_user`;
CREATE TABLE `t_user` (
`id` INT(19) PRIMARY KEY,
`name` VARCHAR(20),
UNIQUE(`name`) #创建表时创建唯一索引
);
-- 删除索引
DROP INDEX `name` ON `t_user`;
-- 建表之后新建唯一索引
CREATE UNIQUE INDEX `unique_index` ON `t_user`(`name`);
- d.复合索引/多值索引
一个索引多个列
复合索引注意事项:
- 最左前缀原则
如下代码,使用联合索引(name,age,length)只能:这样基于name查、基于name age查、基于name,age,length查,其他组合都不能使用 - mysql 引擎在查询时,为了更好地利用索引,在查询过程中会动态调整查询字段顺序以便利用索引
所以,使用联合索引时,只要有最左边的索引name就能查,但只有name,length的话就只能用到name
-- 删除表
DROP TABLE `t_user`;
CREATE TABLE `t_user` (
`id` INT(19) PRIMARY KEY,
`name` VARCHAR(20),
`age` INT(3),
`length` DOUBLE,
KEY(`name`,`age`,`length`) #创建表时创建复合索引
);
-- 删除联合索引,删一个就能全部删掉
DROP INDEX `name` ON `t_user`;
-- 建表之后创建联合索引
CREATE INDEX `key_index` ON `t_user`(`name`,`age`,`length`);
- e.全文索引(5.7之前,只有MYISAM支持)
InnoDB支持的:a,b,c,d
2.索引的底层原理
创建一个主键索引的表,再乱序插入数据,查看表
CREATE TABLE `t_user` (
`id` INT(19) PRIMARY KEY,
`name` VARCHAR(20),
`length` DOUBLE
);
-- 乱序插入数据
INSERT INTO `t_user` VALUES(5,'qing',1.7);
INSERT INTO `t_user` VALUES(9,'song',1.8);
INSERT INTO `t_user` VALUES(1,'qiu',1.5);
INSERT INTO `t_user` VALUES(3,'chen',1.9);
INSERT INTO `t_user` VALUES(6,'hu',1.4);
INSERT INTO `t_user` VALUES(8,'zhao',1.7);
INSERT INTO `t_user` VALUES(4,'wang',1.8);
SELECT * FROM `t_user`;
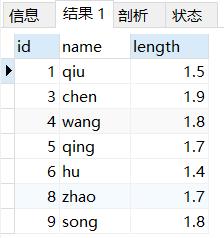
可见:乱序插入的数据,已经排好序了,为什么呢?
是为了快速查询
- 排序之后,查询更快
- 插入的数据是无序的,但主键索引在每一次插入的时候会对数据进行一次排序,并会使用每条插入数据最后一个指针去连接下一条数据

- MySQL会进一步优化,分页存储
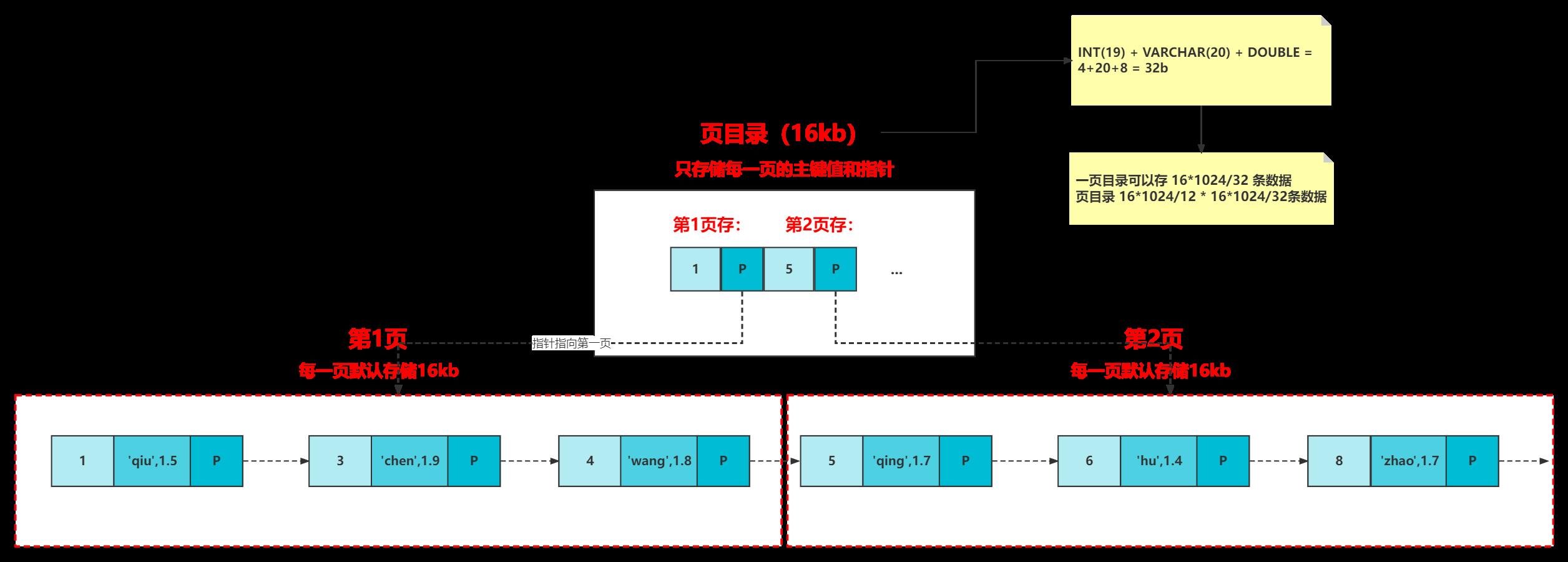
- 然后继续存储更多数据,就会构成一个B+树(一般情况下,不会超过三层)
一般深度为3的B+树可以存 10^3*10^3*10^3 = 10^9条数据
顶层页为常驻内存,所以三层B+树查找某一条记录的时候最多只需要2次操作
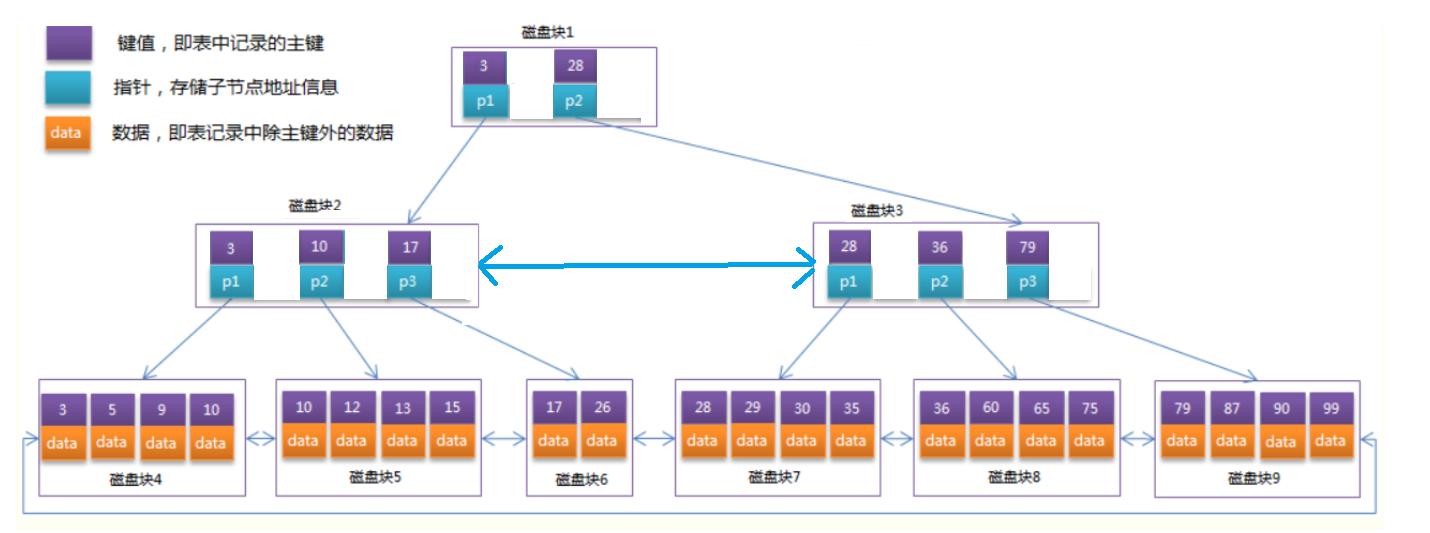
B+树与B树最大的区别: B树非叶子结点必须存储数据,B+树只有叶子结点存储数据。
3.聚簇索引和非聚簇索引
聚簇索引: 将数据存储和索引放到一起,索引结构的叶子结点保存了行数据(如:主键索引)。
- 聚簇索引具有唯一性,由于聚簇索引是将数据跟索引结构放到一块,因此一个表仅有一个聚簇索引
- 表中行的物理顺序和索引中行的物理顺序是相同的,在创建任何非聚簇索引之前创建聚簇索引,这是因为聚簇索引改变了表中行的物理顺序,数据行 按照一定的顺序排列,并且自动维护这个顺序
- 聚簇索引默认是主键,如果表中没有定义主键,InnoDB 会选择一个唯一且非空的索引代替。如果没有这样的索引,InnoDB 会隐式定义一个主键(类似oracle中的RowId)来作为聚簇索引。如果已经设置了主键为聚簇索引又希望再单独设置聚簇索引,必须先删除主键,然后添加我们想要的聚簇索引,最后恢复设置主键即可
非聚簇索引: 将数据与索引分开储存,索引结构的叶子结点指向了数据对应的位置。
注意: 在innodb中,在聚簇索引之上创建的索引称之为辅助索引,非聚簇索引都是辅助索引,像复合索引、前缀索引、唯一索引。辅助索引叶子节点存储的不再是行的物理位置,而是主键值,辅助索引访问数据总是需要二次查找。
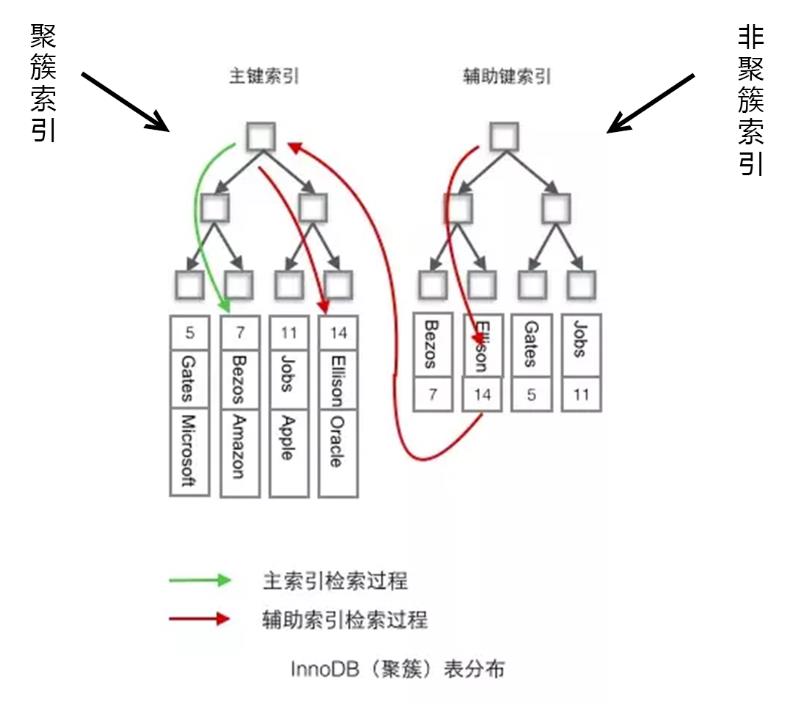
问:辅助索引为啥不直接存地址,而是存id?
答:当发生增删改之后,物理地址会变化,且主键占用空间小于地址占用空间。
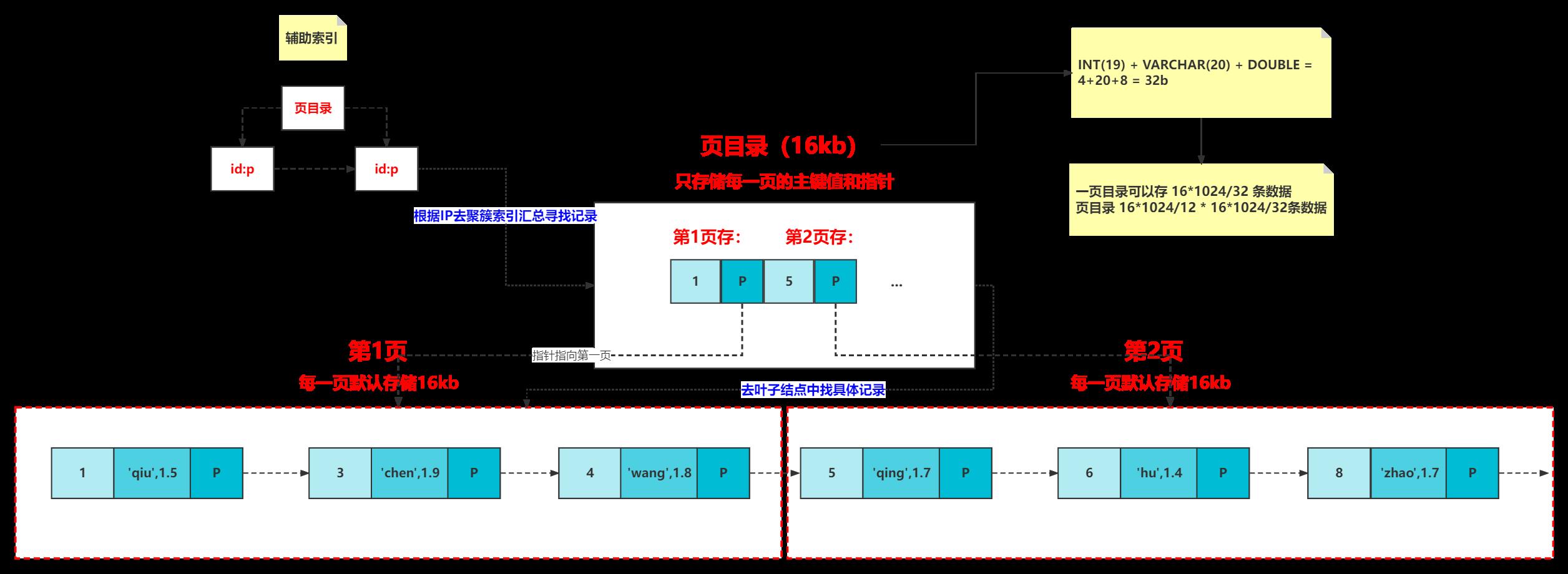
一次io读写,可以获取到 16K 大小的资源,我们称之为读取到的数据区域为 Page 。而我们的B树,B+树的索引结构,叶子节点上存放好多个关键字(索引值)和对应的数据,都会在一次IO操作中被 读取到缓存 中,所以在访问同一个页中的不同记录时,会在内存里操作,而不用再次进行IO操作了。除非发生了页的分裂,即要查询的行数据不在上次IO操作的缓存里,才会触发新的IO操作。
InnoDB与MyISAM对比:
- InnoDB
聚簇索引
将主键组织到一棵B+树中,而行数据就储存在叶子节点上
若直接使用主键查找,则按照B+树的检索算法即可查找到对应的叶节点,之后获得行数据
若用非主键作为条件查找则:先在辅助索引B+树中检索Name,到达其叶子节点获取对应的主键;再使用主键在主索引B+树种再执行一次B+树检索操作,最终到达叶子节点即可获取整行数据 - MyISAM(不支持事务)
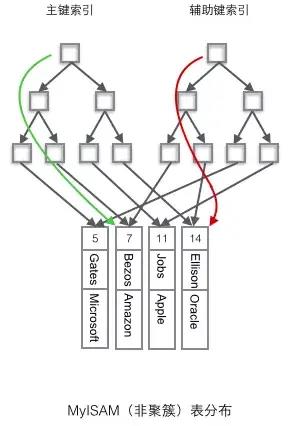
非聚簇索引
两棵B+树节点的结构完全一致只是存储的内容不同
主键索引B+树的节点存储了主键,辅助键索引B+树存储了辅助键,表数据存储在独立的地方
这两颗B+树的叶子节点都使用一个地址指向真正的表数据,对于表数据来说,这两个键没有任何差别。由于索引树是独立的,通过辅助键检索无需访问主键的索引树。
使用聚簇索引的优势:
- 由于:行数据和聚簇索引的叶子节点存储在一起,同一页中会有多条行数据
所以:访问同一数据页不同行记录时,已经把页加载到缓存器中(主键和行数据是一起被载入内存),再次访问时,会在内存中完成访问,不必访问磁盘。 - 由于:辅助索引的叶子节点,存储主键值
所以:当行数据放生变化时,索引树的节点也需要分裂变化;避免对辅助索引的维护工作,只需要维护聚簇索引树;减少了辅助索引占用的存储空间大小 - 由于:MyISAM的主索引并非聚簇索引
所以:其数据的物理地址必然是凌乱的,拿到这些物理地址,按照合适的算法进行I/O读取,遍历树。聚簇索引则只需一次I/O。
涉及到大数据量的排序、全表扫描、count之类的操作的话,还是MyISAM占优势些,因为索引所占空间小,这些操作是需要在内存中完成的。
简而言之: 聚簇索引第一次读就会把所有数据写进缓存(二层树只需要一次IO操作),非聚簇索引因为物理地址是乱的,每次都需要IO读取
聚簇索引需要注意的地方:
当使用主键为聚簇索引时,主键最好不要使用uuid,因为uuid的值太过离散,不适合排序且可能出线新增加记录的uuid,会插入在索引树中间的位置,导致索引树调整复杂度变大,消耗更多的时间和资源。
建议使用int类型的自增,方便排序并且默认会在索引树的末尾增加主键值,对索引树的结构影响最小。而且,主键值占用的存储空间越大,辅助索引中保存的主键值也会跟着变大,占用存储空间,也会影响到IO操作读取到的数据量。
为什么主键通常建议使用自增id
聚簇索引的数据的物理存放顺序与索引顺序是一致的,即:只要索引是相邻的,那么对应的数据一定也是相邻地存放在磁盘上的。如果主键不是自增id,那么它会不断地调整数据的物理地址、分页,当然也有其他一些措施来减少这些操作,但却无法彻底避免。但,如果是自增的,那就简单了,它只需要一 页一页地写,索引结构相对紧凑,磁盘碎片少,效率也高。
什么时候下不能利用索引?
使用
like进行查询的时候,如果匹配字符串的第一个字符为%,就不能用索引查询语句使用复合索引的时候,没有使用最左边的索引字段
查询语句中只有
or,且or前后两个条件列都是索引的时候,可以使用索引;当or前后有一个条件不是索引的时候,就不能使用索引
以上是关于MySQL索引的主要内容,如果未能解决你的问题,请参考以下文章
mysql数据库如何创建自增长标识? id int identity(1,1)在mysql中行不同啊!!!