Hadoop基本概念指南
Posted henry-hacker
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop基本概念指南相关的知识,希望对你有一定的参考价值。
前言
这是关于Hadoop的系列文章。
背景
最近突然对于Hadoop有了一定的兴趣,于是乎就有了这篇文章,因为工欲善其事,必先利其器啊!这一点永远都是真理。于是自己去看了Hadoop实战这本书,真心觉得收获很大!
应用场景
空谈理论不谈场景是极其不负责任的一种行为,那么下面我就来谈谈我对这件事情的理解吧!我仔细询问了我一个做大数据的同僚,他们平时使用Hadoop主要做的事情就是对日志的分析,当然我在这里说的十分轻巧,他们需要做的事情还是比较多的。
如下便是我根据他的描述做的一个简单的流程图:
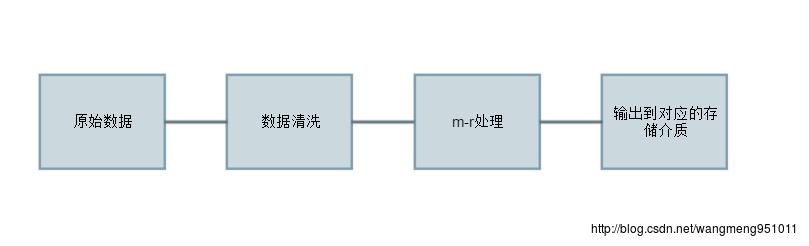
通过上面的流程图我们可以看得出来,这里面Hadoop应该是在第三步的时候发挥自己的作用的,然后,数据清洗的话实际上主要是一些脏数据,比如说明显有问题的数据。mr的话实际上对应的就是Hadoop的实际数据处理过程。这里我们暂且不谈。最后写入到存储介质中去,这里的存储介质实际上就是存储数据的方式,而这里的方式是千差万别的,比如说传统的DB,像Redis的key-value型的内存数据库,elaticsearch的等支持搜索的数据库等等,不一而足。
那么我们来举一个非常常见的例子,比如说nginx的access.log通常会记录访问这台机器的机器的ip以及URL,这里的话我们就可以去统计每一个URL下面出现的ip的次数的统计以及每个URL的总的访问数,这样我们将最后的统计结果绘制成图表,就可以很清晰的看出来每个接口的访问热度,当然如果你比较有心的话,还可以去按照时间段进行统计。这样你将会得到一个非常清晰的接口的实时调用图像。
说完了这些,我们怎么去做呢?那当然是要开始写程序了。首先我们要收集日志文件,然后用java的io流读取相应的文件,最后一行行的做处理。按照正则匹配读取其中的ip以及请求的url,然后相同的url做一次归类,这就统计出了相同的url的个数,然后在统计的结果集可以统计ip的出现频率。当然,也可以直接只统计ip的出现频率。恩,这样看来我们的数据处理很快就可以跑完了。
当然,我们的想法是美好的,可是现实条件是怎样的呢?我们的访问日志绝可能只有几十K大小。怎莫说也得有个几百M吧,当然,谁家还没有个集群啥的,那么假设就有十个G的日志需要处理吧!你的程序需要跑多久呢?我们还可以看到,这里的10个G已经将内存撑爆了。也就是说你需要分段去做。然而抛开这些,还有非常多的问题等待着你去解决,比如说现在一百亿条记录,你已经处理了99亿数据,还剩下1亿。此时你每处理一条数据就需要去将取得新的数据ip以及url存入你的存储介质中去。此时,如何归类,当然,如果像阿福这样的话,就只能遍历寻找了。额,我当然不会这麽做。但是我们可以看到数据量的增大给我们的处理带来了诸多的麻烦。
现在是时候让我们的Hadoop上场了。
Hadoop解决了什么问题
事实上我们通过刚才讨论的例子可以看得出来,大数据量为我们的处理带来了很大的挑战,我们不得不去引入更先进的框架和工具以应对这样的挑战。而Hadoop或许是我们的一个选择。
我们刚才谈到的问题主要有:
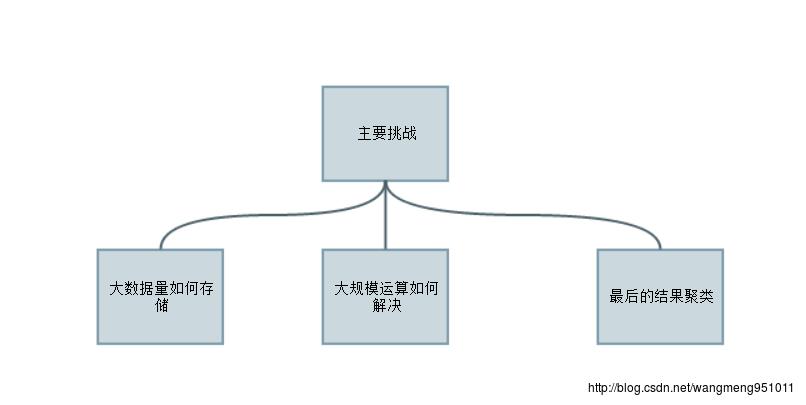
借着上面的问题,我们来简单的看看Hadoop都为我们提供了哪些组件解决我们的问题。
首先出场的是我们的HDFS先生,它是Hadoop为我们提供的分布式的文件存储系统,有了它,再也不怕文件没地方存。其次就是Hadoop是基于可扩展的集群的,其集群扩展也很方便,因此,大量机器的计算能力的聚合将会让我们的问题极快的得到求解。当然,最后要说的是其m-r编程模型。这样的模型对于我们来说很容易上手。至于是怎样的模型,日后在做分析。
HDFS
下面首先放出阿福画的一张HDFS的基本架构图。
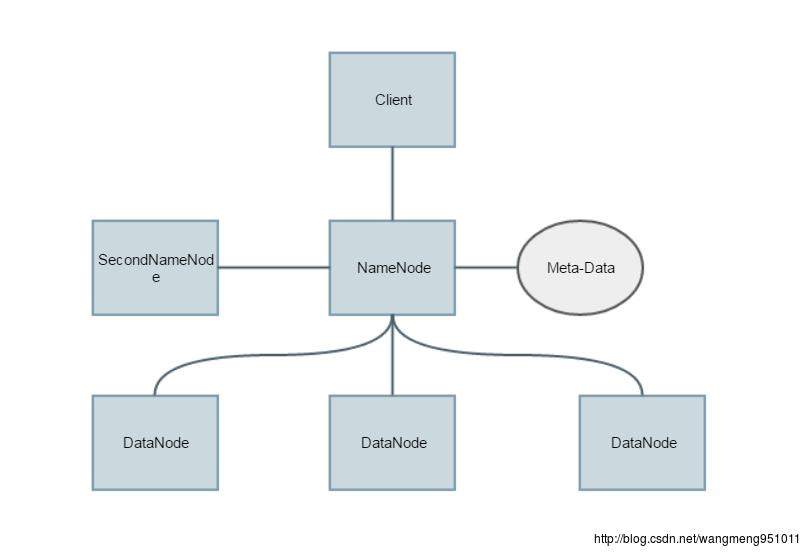
我们可以看到这里的话主要有三种角色,分别是NameNode、SecondNameNode和DataNode。啊哈,我们下面就来说说这三种角色的区别。
NameNode和SecondNameNode很容易看出这两者的关系,很明显,SecondNameNode是NameNode的backup,也就是说NameNode不行了换它上。
其次。NameNode主要是用来管理DataNode的,为何这麽说呢?因为NameNode实际上是不存储实际的数据,他保存的知识数据的位置,当client需要数据的时候,他知道从哪里读取就可以了。简单的来说他就像是数据库的索引,索然它不存储数据,可是要是没了它,整个系统的数据就会丢掉,虽然DataNode的数据并没有丢失,但是我们已经不知道去哪里找寻对应的数据了。当然,这里列出的Meta-Data我们称之为元数据,其实也就是那些存储在DataNode上的数据的索引。
DataNode只是存储数据的,这里不在赘述。
m-r
这个部分说句实话,我现在还不是太理解,所以就不坑害大家了。以后懂了在更新!
总结
实际上这篇文章更多是想说针对一个特定的问题如何去分析,然后敲定具体的技术方案,实际上我们可以看到。Hadoop在这种大数据量的离线计算上还是非常强的。
立个flag,近期会分享自己学习Hadoop的过程,希望能帮助到更多的人!
以上是关于Hadoop基本概念指南的主要内容,如果未能解决你的问题,请参考以下文章