BIT云计算实验Spark Local/Standalone模式搭建实验记录
Posted Nardack
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了BIT云计算实验Spark Local/Standalone模式搭建实验记录相关的知识,希望对你有一定的参考价值。
风险评估
前置知识:云计算公理,Linux基本指令,ssh
实验时间:1d
实验难度(采用Codeforces的rating标准):
- 使用相同初始用户名:div2C / ≈1600
- 使用不同用户名:div2D / ≈2100
- 使用不同初始用户名,然后再新建同名用户:div2C / ≈1800
如果仅仅是为了完成实验,强烈推荐大家初始创建相同用户名完成任务。
参考资料
以下是这个实验涉及到的常见问题的参考资料以及解决方案链接清单:
虚拟机 sudo apt install net-tools 无法下载问题解决方法
Spark学习之standalone模式部署实战(配置ssh)
实验中要用到的spark集成环境和jdk可以通过这个网盘地址下载:
https://pan.baidu.com/s/1QF00LD–i5CEx6NQCo8D-w
提取码:tjgj
关于云计算公理
由于老师提供的spark实验教程比较简略,并且省略了很多前置步骤,并没有提到这个步骤的目的是什么。因此在做实验之前,有必要介绍一些关于云计算的最最核心的概念和步骤,为致敬《三体2:黑暗森林》中的黑暗森林理论,称之为云计算公理:
- 公理1:云计算需要两台或多台电脑/虚拟机/云服务器共同运行;
- 公理2:云计算需要记录两台或多台电脑的ip地址;
- 公理3:记录ip地址的关键字是HOST,如果要用字符串代替ip地址,就要修改host文件;
- 公理4:云计算需要两台或多台电脑使用ssh无密码互相连接;
- 公理5:如果两台或多台电脑使用ssh无密码互相连接,则两台电脑必须生成ssh密钥,并相互分发到对方的电脑上;
如果在实验过程中出现了"No Connection"或者"Permission Denied"的情况,绝大多数可以归结为以下几种情况:
- 只使用了一台电脑/虚拟机,违反了公理1;
- 没有记录ip地址或者ip地址记录错误,违反了公理2;
- 使用字符串代替ip地址时没有修改host文件,违反了公理3;
- 没有生成并使用ssh密钥,违反了公理4;
- ssh密钥没有分发到对方电脑上,违反了公理5;
一:创建虚拟机
了解上述关于云计算的五条公理之后,接下来就是安装master和slave两台虚拟机的过程:
为了方便记忆名字,同时尽量避免旁边有人使用的用户重名的问题,我们把master称作Nardack,slave称作Krenz(P.S.两位都是非常厉害的传说级画师)
这里推荐使用VMWare创建两台虚拟机,使用的虚拟机iso映像:ubuntu-20.04.4-desktop-amd64.iso
(百度这个文件名可以直接找到下载地址)
然后VMWare会自动帮你完成剩下的安装步骤,之后点进去虚拟机的桌面:
这里其实点Remind Me Later或者Install Now都可以,这里推荐选Remind Me Later。
特别提醒:
- 记得两台虚拟机设一个比较好记的密码。
- 为了方便后续命令的复制,建议将VMWare的剪贴板模式设定成"双向"。
- 文件编辑器推荐使用vim,vi编辑器有一些兼容性的问题。
- 如果仅仅是为了完成实验,强烈推荐大家初始创建相同用户名完成任务,这样可以跳过步骤六。
二:本地ip地址查询
以下是查询本地ip地址的方法和常见的坑:
方法1——ifconfig
采用网上的ifconfig方法,在这个步骤会出现以下的问题:
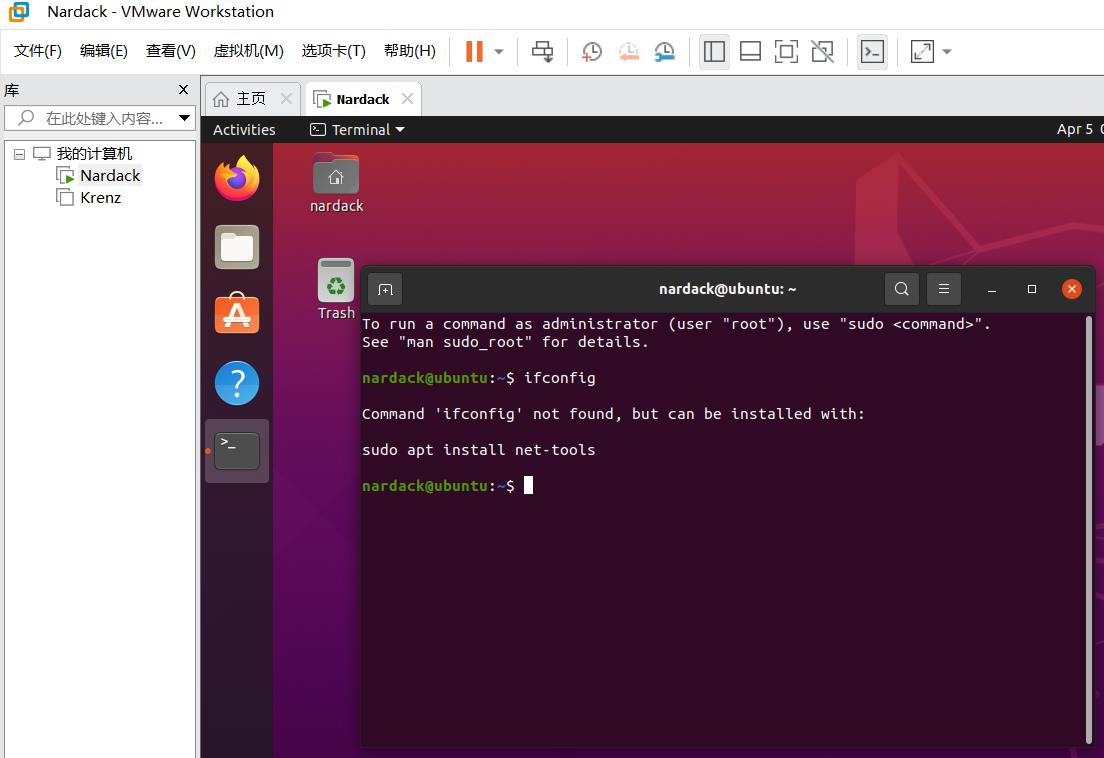
这是由于ifconfig是net-tools里面的包。
然后又按照系统提示的方法做,又会出现这个问题:
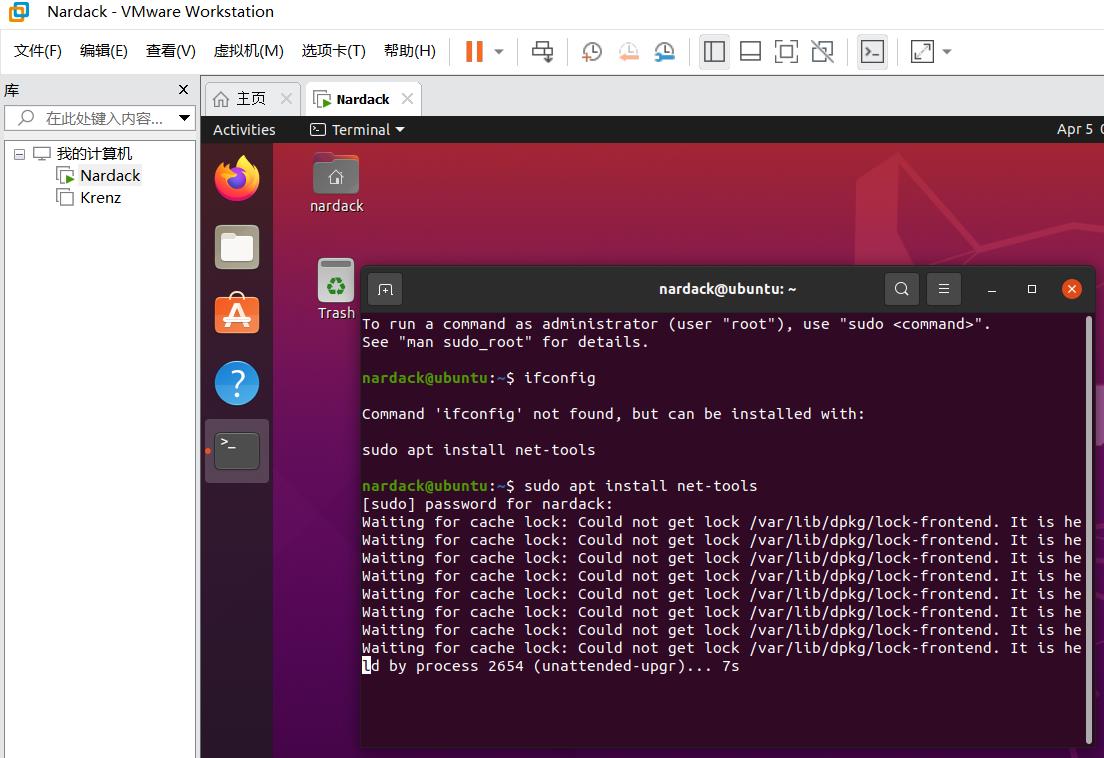
那么这个问题怎么解决呢?
参照这个教程的方法,可以通过运行以下的命令解决:
sudo rm /var/lib/dpkg/lock-frontend
sudo rm /var/lib/dpkg/lock
sudo rm /var/cache/apt/archives/lock
根本原因是apt这个时候仍然在运行,导致资源被锁不可用,而导致资源被锁的原因是上次执行安装或更新时没有正常完成。
这个时候就可以正常的运行sudo apt install net-tools这个命令了。
运行上述命令后,再运行ifconfig命令后的结果是这样的:
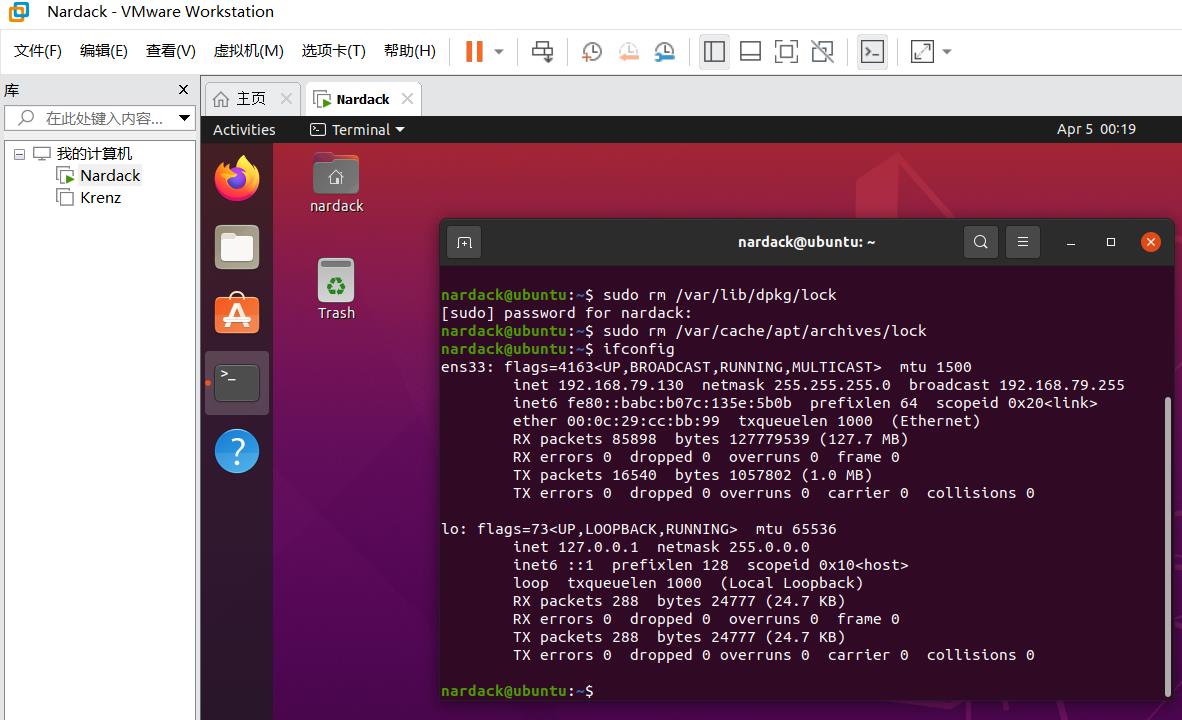
然后,我们注意到第二行的inet,这个192.168.79.130就是master虚拟机,也就是用户名Nardack的虚拟机对应的IP地址。这个结果对不同的地区和机器可能不相同。
对于slave虚拟机(用户名Krenz)也是同理,运行后的结果如下图所示:
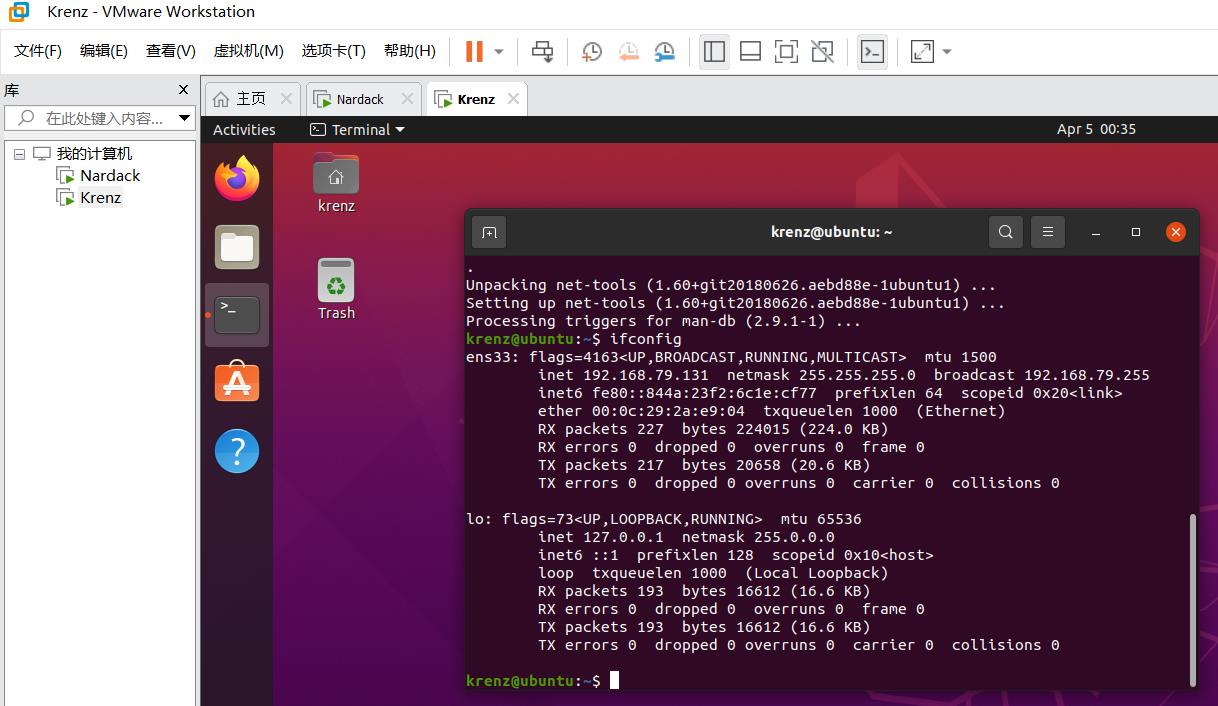
据此我们得出master(Nardack)的ip地址是192.168.79.130,slave(Krenz)的ip地址是192.168.79.131。
容易发现对于同一台机器相继创造的两台虚拟机,对应的ip地址最后一位也是连续的。
方法2——ip addr
在Ubuntu 20.04中,我们还可以使用ip addr这个命令来查询本地的ip:
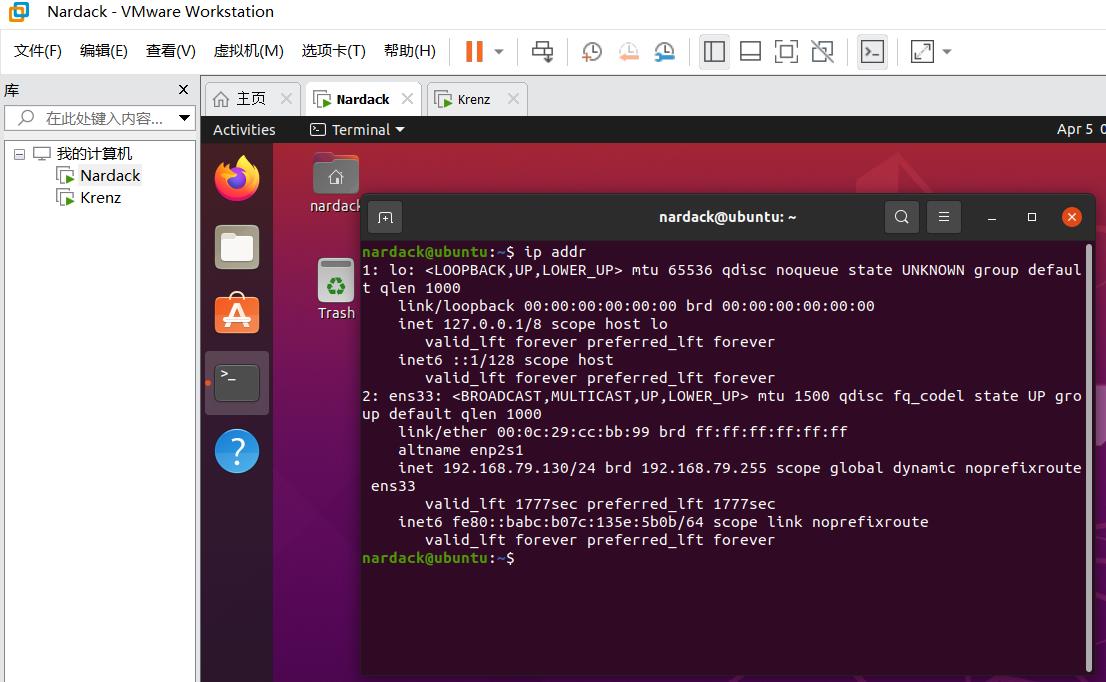
其中inet后面的192.168.79.130就是这台虚拟机的ip地址了。
为了之后的操作方便,记录master和slave两台虚拟机的用户名和IP地址是非常有必要的:
master:
- 用户名:Nardack
- IP:192.168.79.130
slave:
- 用户名:Krenz
- IP:192.168.79.131
温馨提示:在整个实验过程中,你可以通过观察上方的选项卡哪个被选中来判断当前使用的机器是master还是slave虚拟机。例如上图中"Nardack"的选项卡被选中,说明用的是master虚拟机。
三:配置ssh
接下来进入两台虚拟机无密码互通并且配置ssh环节:
测试两台机器是否能ping互通
我们先测试两台虚拟机能否用ping互通:
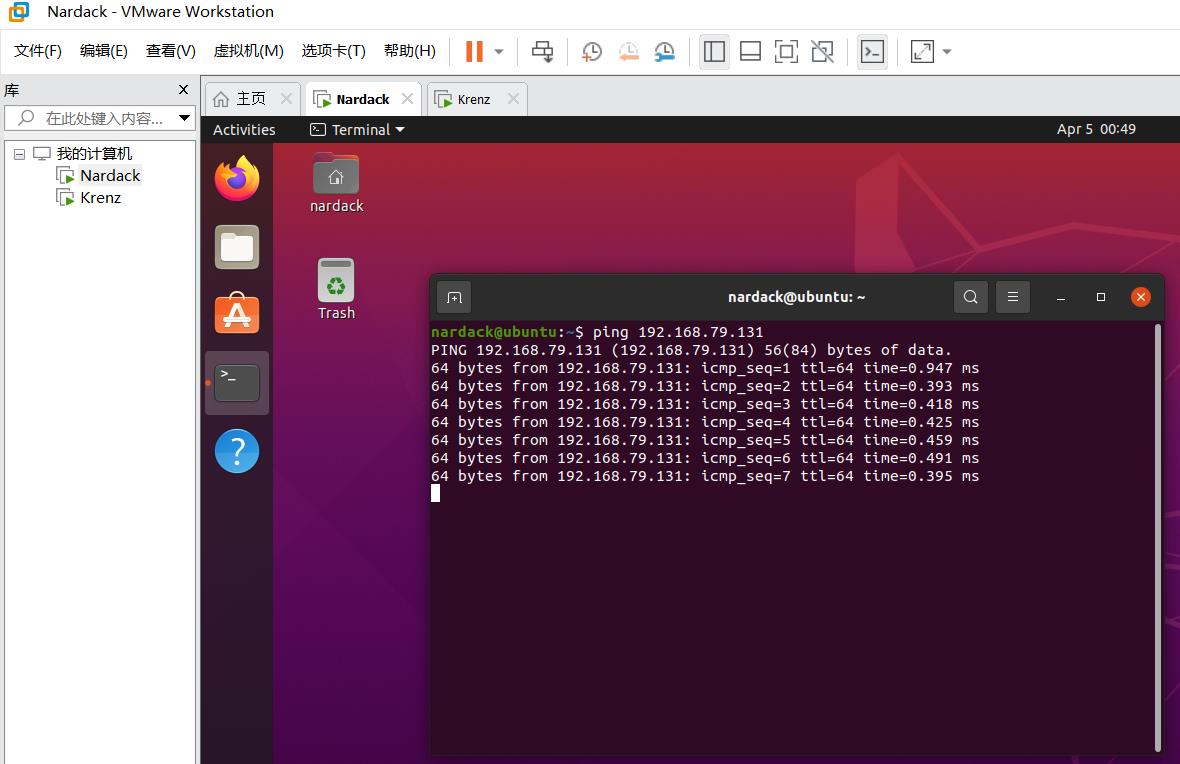

像这样master去ping一下slave,slave再去ping一下master,如果像上图一样相互ping到就成功了。
另外也要检查一下外网的连通性,比如能否正常上网,ping一下www.baidu.com是否有响应等等。
下载open-ssh并生成密钥
然后,两台虚拟机上都需要下载open-ssh:
sudo apt install openssh-server
安装之后生成密钥:
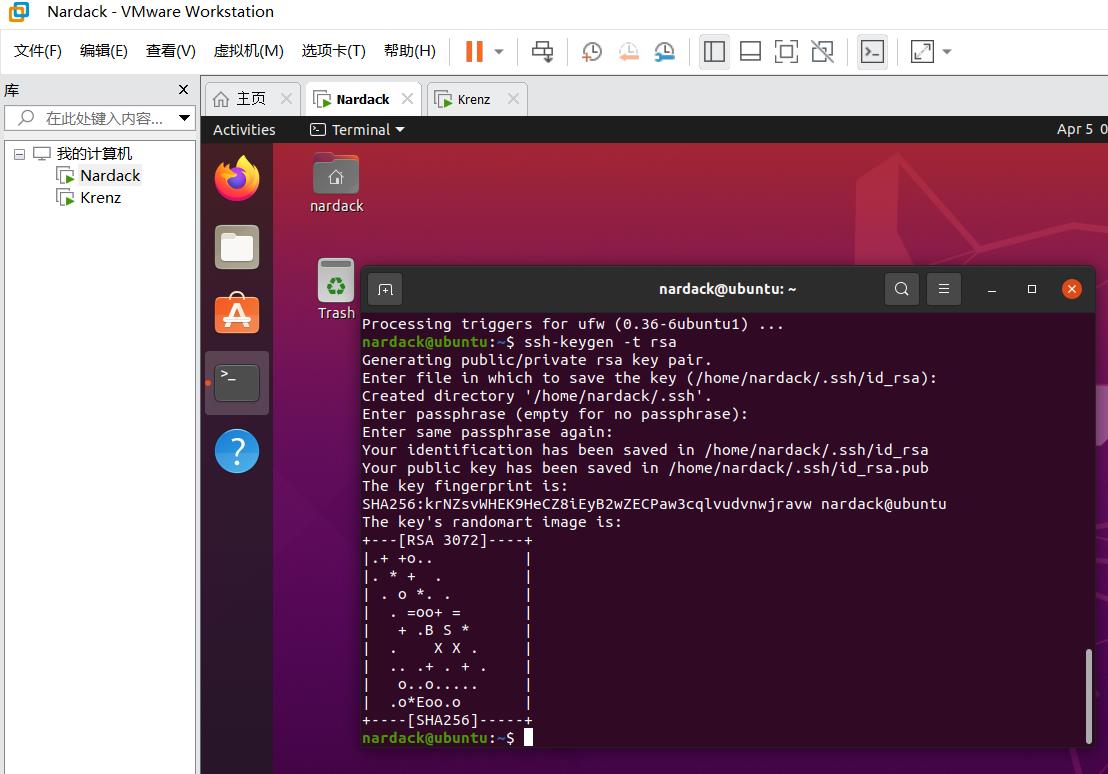
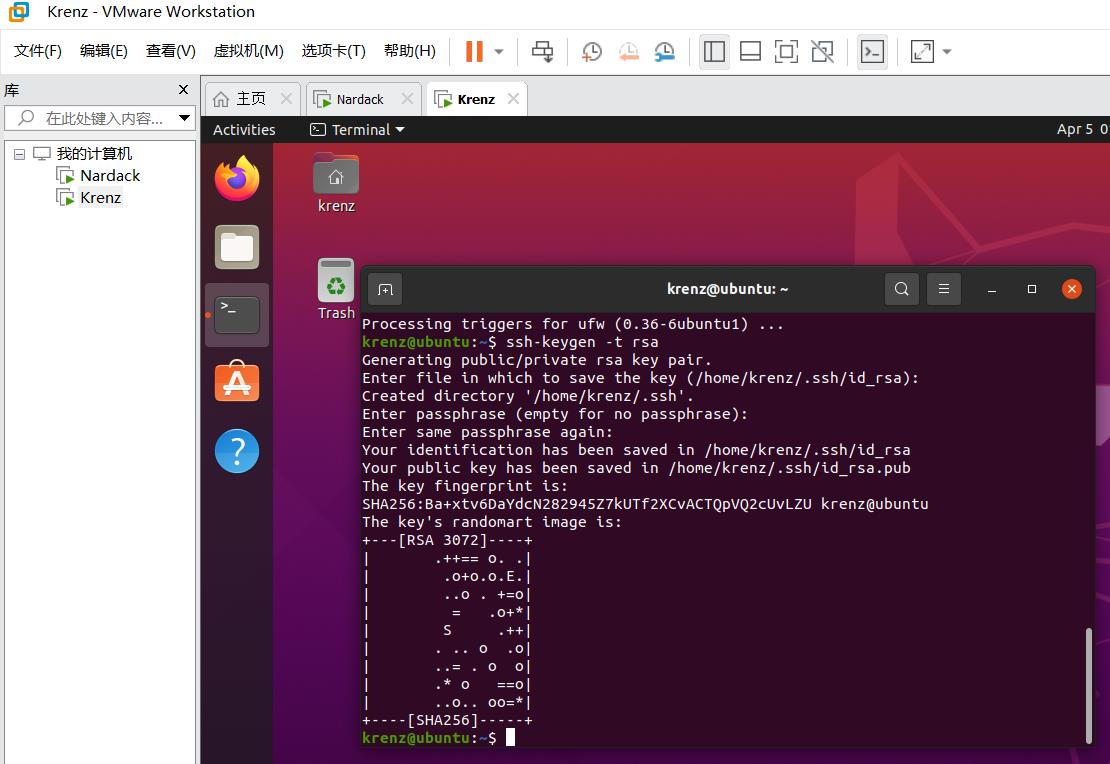
ssh-keygen -t rsa
然后系统会依次询问存储位置,passphrase(也就是密码),再输入一遍passphrase,这个过程直接按回车就可以(采用默认存储位置,无密码):
如果最后显示"The key’s randomart image is:",说明密钥生成成功:
将密钥相互拷贝到对方
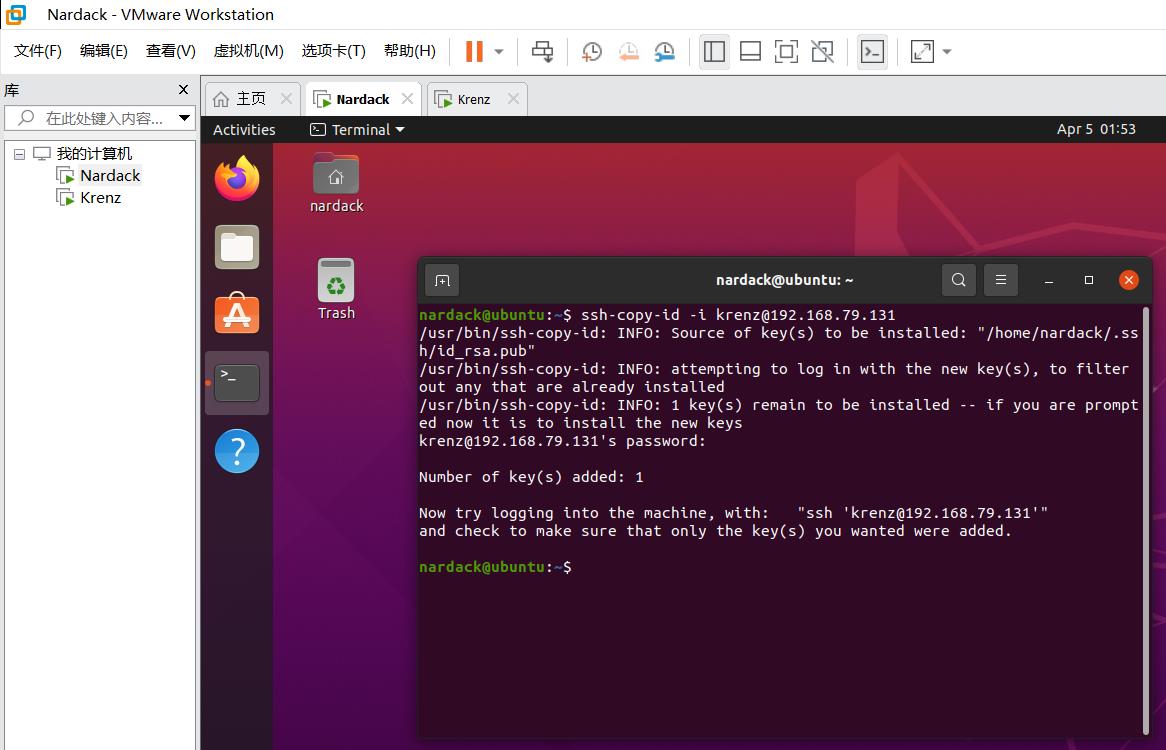
生成好密钥以后,要将密钥相互拷贝到对方。例如,在master虚拟机上,需要运行以下命令:
ssh-copy-id -i krenz@192.168.79.131
其中,krenz代表着对方的用户名,@后面的192.168.79.131代表着对方虚拟机的ip地址。
有时候系统会提示你输入yes/no,输入yes即可。
然后会要求输入密码,这里要输入slave虚拟机的密码:

出现以下信息,说明ssh已经复制到了slave虚拟机上:
按照系统的提示,我们验证一下master能不能无密码连接上slave:
ssh krenz@192.168.79.131
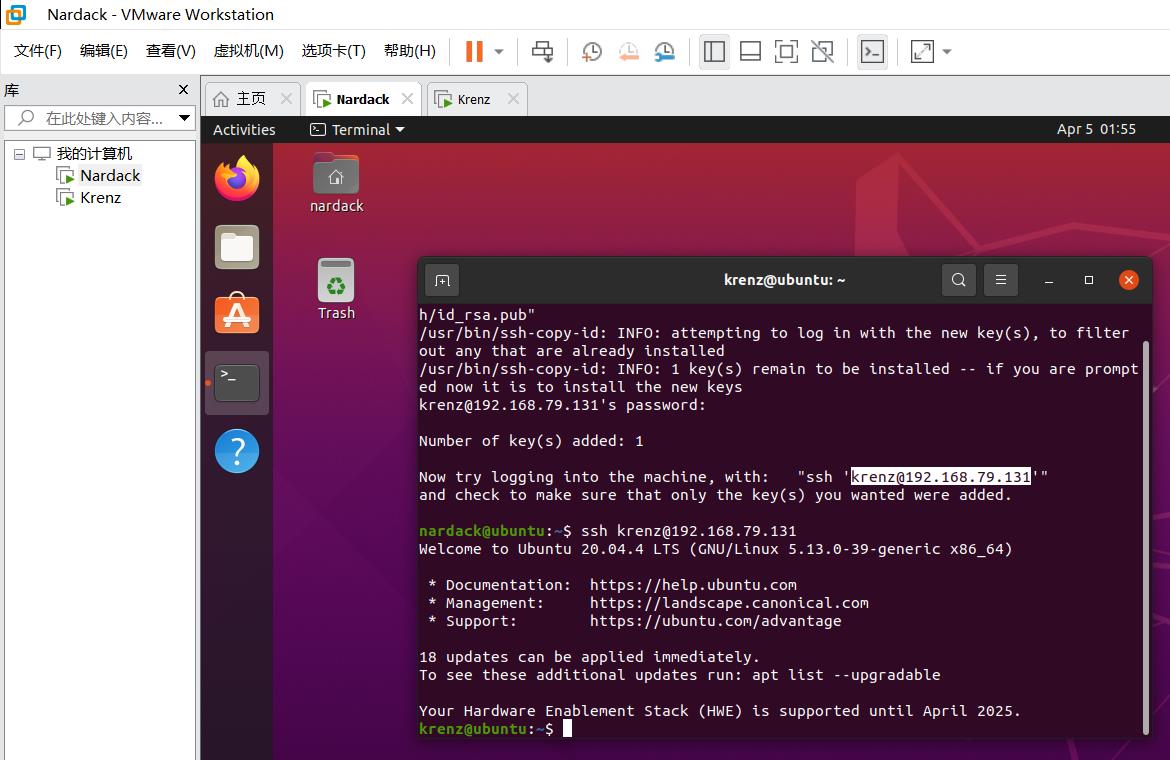
如果如上图所示,出现以下现象说明ssh无密码连接成功:
- 出现
Welcome to Ubuntu这个欢迎信息 - 用户名和上方的标题栏变成了
krenz@ubuntu
注意,如果之后在这台虚拟机上运行命令,影响将会作用到另一台虚拟机上。这时候需要手动重启一下terminal进行后续操作。
同理,我们在slave(Krenz)这台虚拟机上,需要运行以下的命令:
ssh-copy-id -i nardack@192.168.79.130
按照同样的步骤,最后的效果如下图所示:
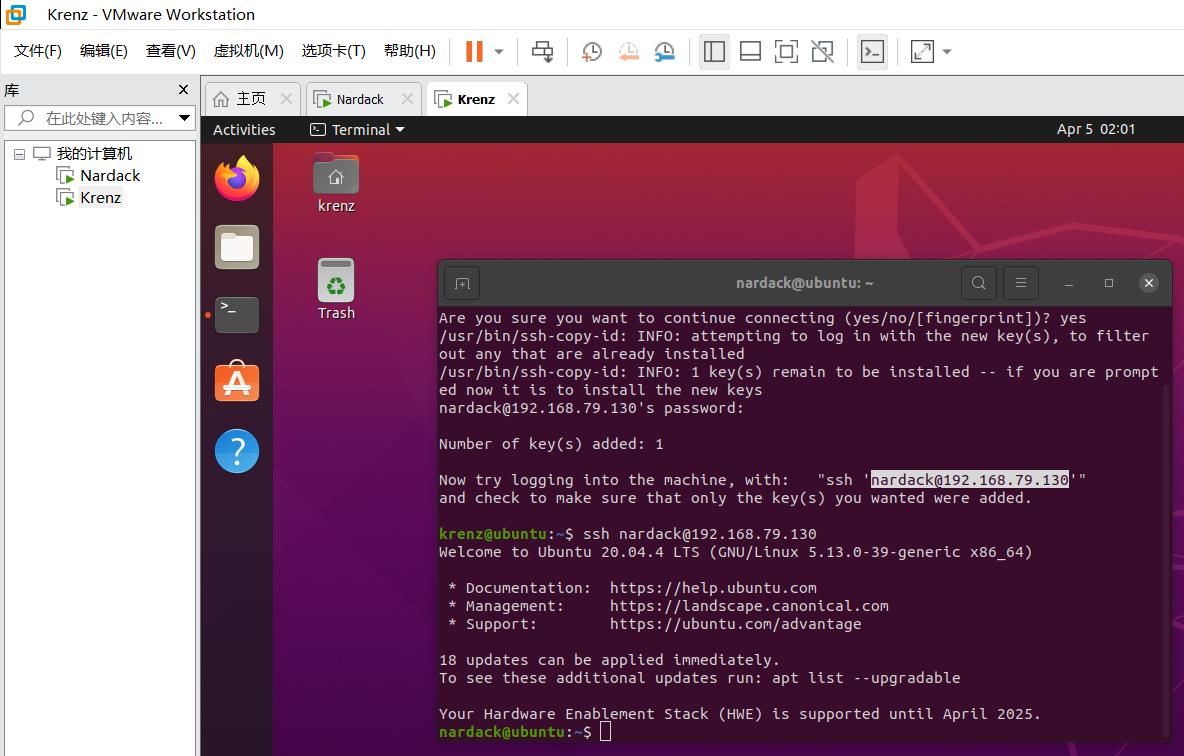
这个时候就说明两台电脑处于ssh能够无密码相互连接对方的状态,简称"相互连接"状态。
要建立Standalone下的Spark集群,前提必须是两台或多台电脑/虚拟机/云服务器处于相互连接状态。如果是master-slave模式的话,确保master和每个slave分别处于相互连接状态即可。
四:Standalone模式下Spark模式部署
在进行这个步骤之前,确保两台或多台虚拟机处于相互连接状态。然后,我们正式开始进行Standalone模式下Spark集群的部署。
这里先配置好master(Nardack)虚拟机,以下1~2操作都是在master虚拟机中进行:
配置~/.bashrc文件
我们先将spark安装包和jdk复制到Ubuntu的home目录。这个实现方法有很多,包括scp传输,使用网盘等。这里使用的方法是直接在电脑和虚拟机之间复制:
可能在复制的过程中会出现以下提示,直接点Skip All即可。VMware会直接帮你执行复制步骤。

然后,我们把两个文件分别进行解压。在terminal执行以下命令:
tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz
tar -zxvf jdk-8u202-linux-x64.tar.gz
如果在home文件夹下出现了两个与压缩包同名的目录,说明执行成功:
这里为了使用方便,把spark-3.0.0-bin-hadoop3.2对应的目录改成spark:
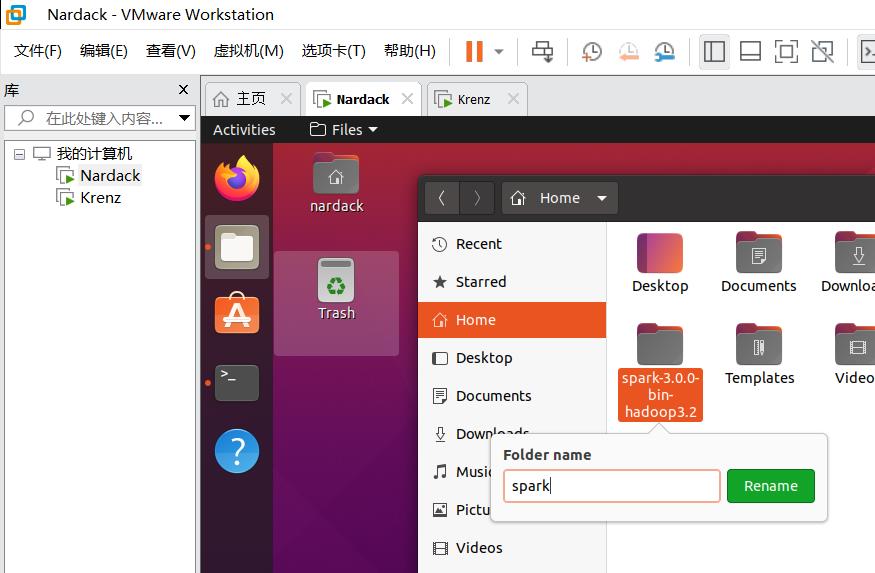
然后我们编辑.bashrc文件:
vim ~/.bashrc
移动到最后一行,添加如下命令:
export JAVA_HOME=~/jdk1.8.0_202
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=.:$JAVA_HOME/bin:$PATH
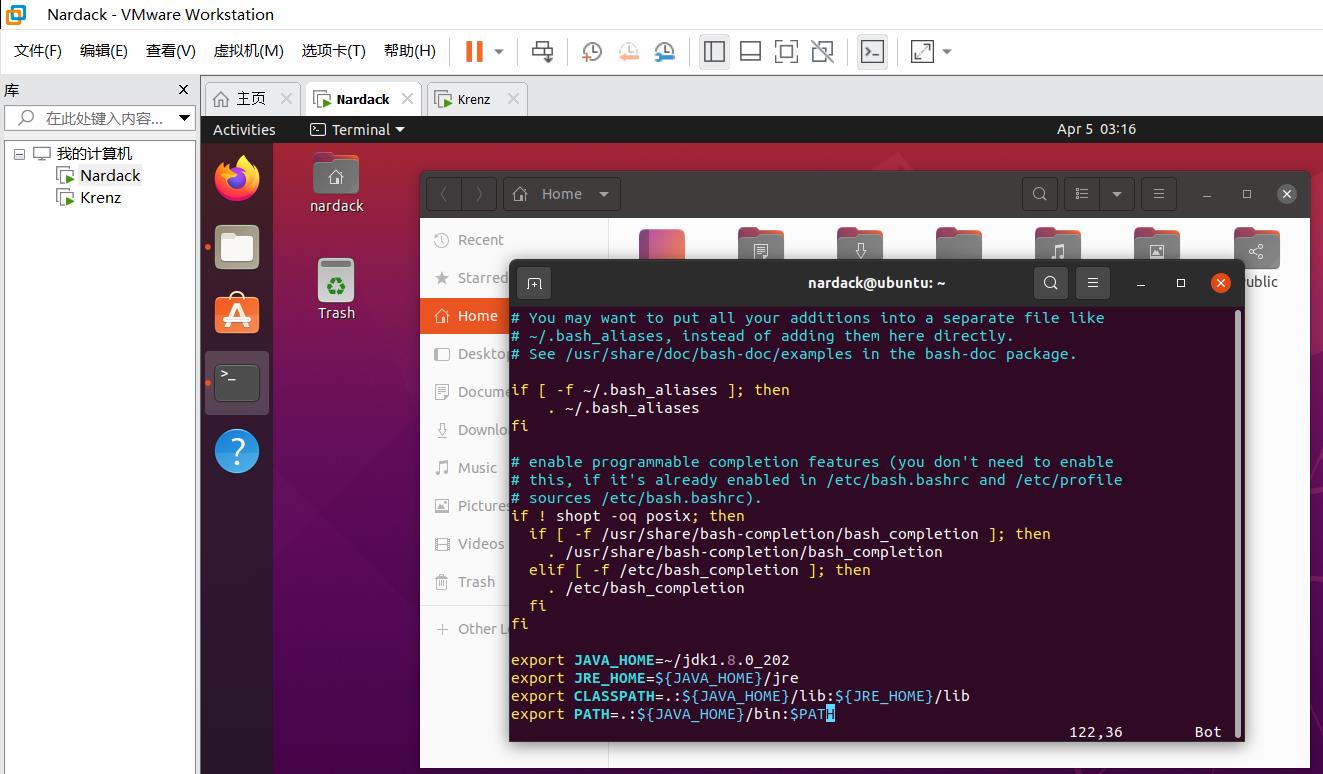
之后保存并退出。然后运行以下命令来配置bashrc文件:
source ~/.bashrc
这一步的目的是配置java路径。~/.bashrc里的代码相当于在运行终端之后会立刻运行的指令。如果不修改的话,就意味着每次运行终端时就要手动输一遍上面export的四行命令,操作麻烦很多。
然后,我们进入到修改spark配置文件的环节。
修改Spark配置文件
我们修改完spark包的文件名后,我们运行
cd spark/conf
进入到spark包的配置目录:
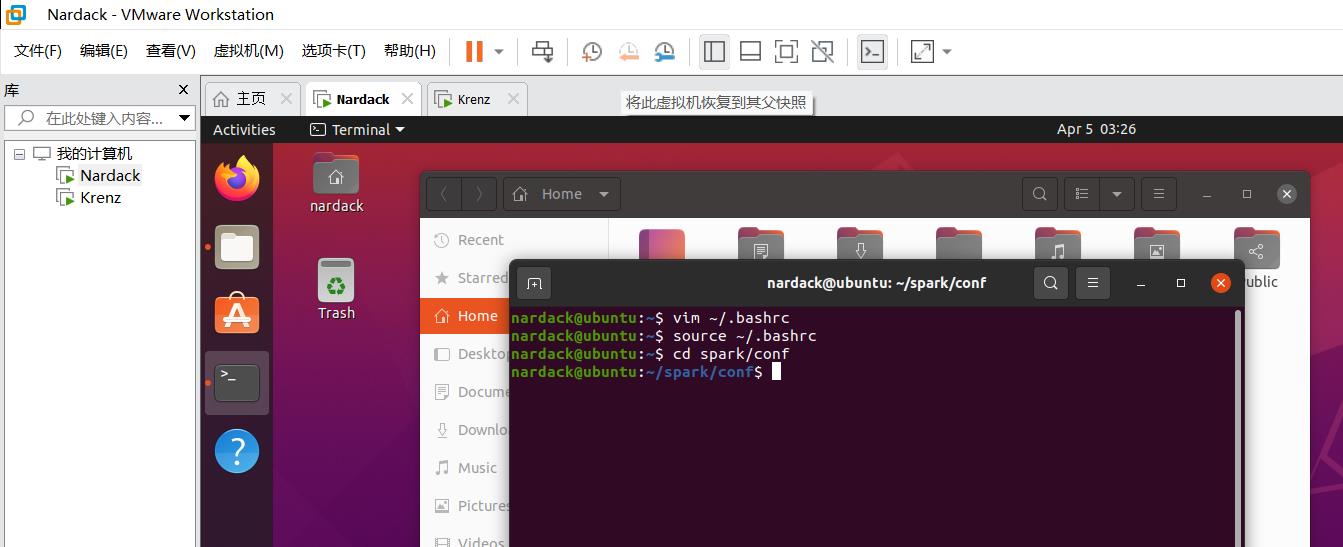
然后我们运行文件重命名命令:
mv slaves.template slaves
将这个目录下的slaves.template变成slaves(相当于改变了一下扩展名)
然后我们运行
vim slaves
修改这个配置文件
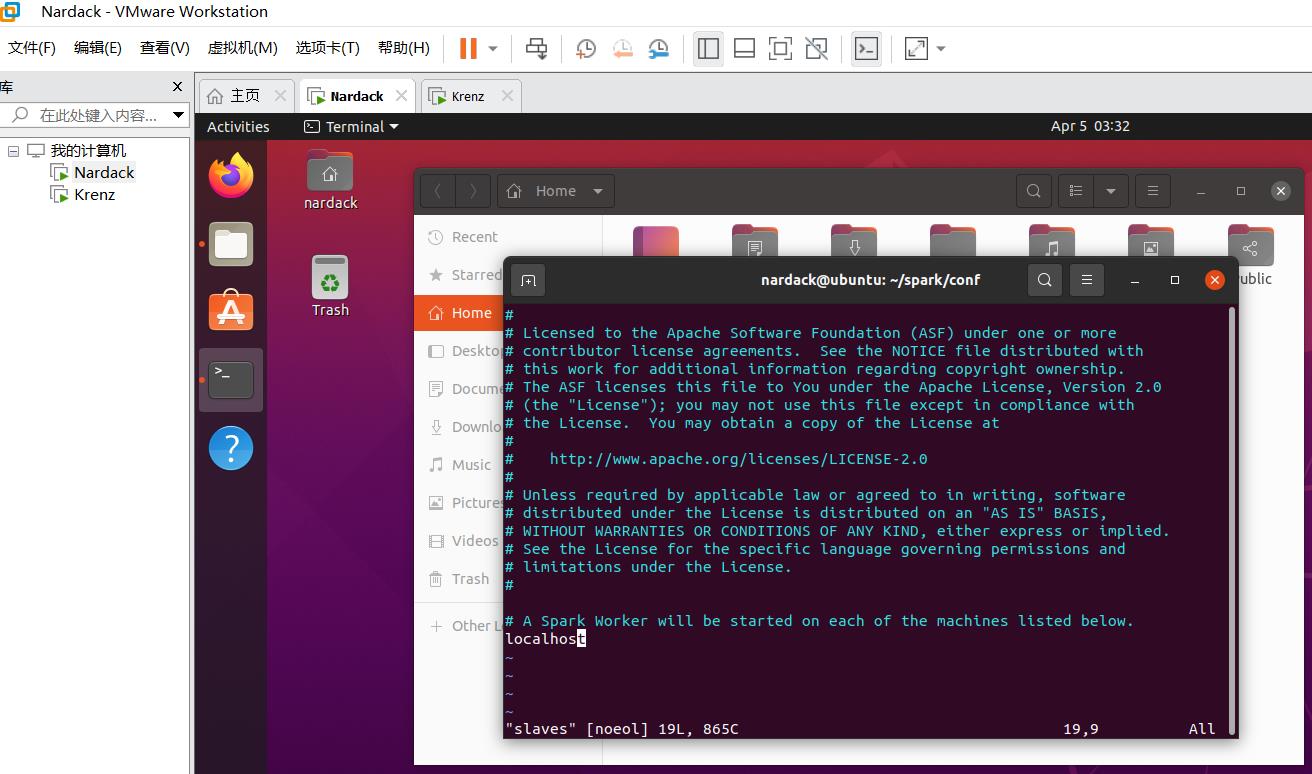
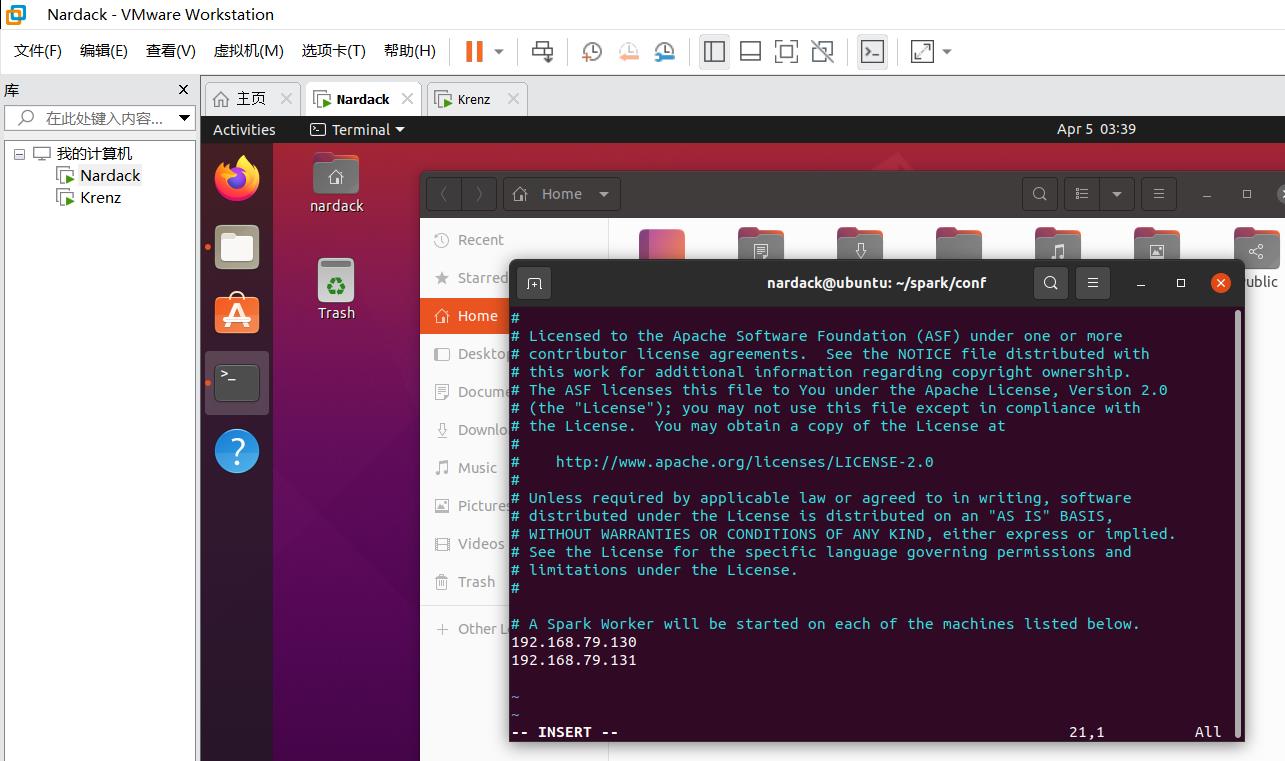
注意到里面有一个localhost,这里直接替换掉,并输入master和slave的ip地址就可以,也就是
192.168.79.130
192.168.79.131
之后保存并退出,并运行以下命令,将spark-env.sh.template替换为spark-env.sh,并编辑这个文件:
mv spark-env.sh.template spark-env.sh
vim spark-env.sh
我们还是光标移动到最后一行,添加以下内容:
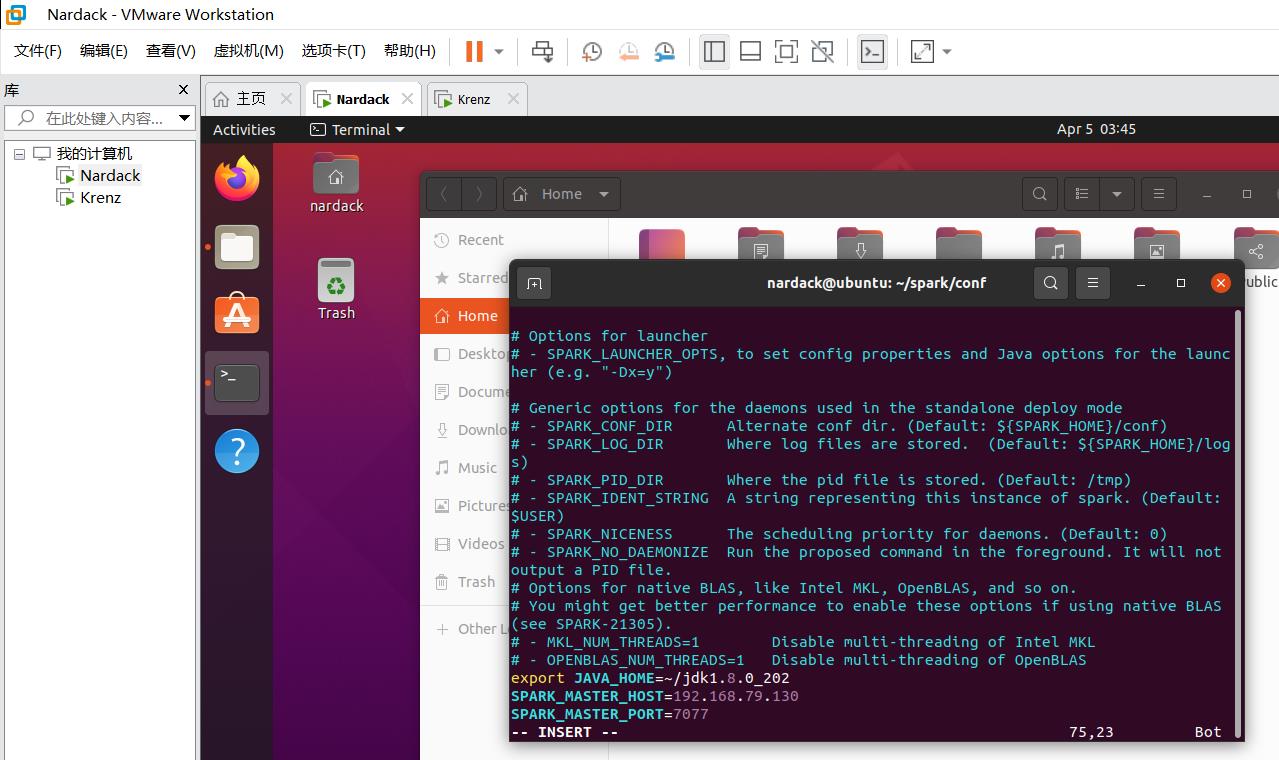
export JAVA_HOME=~/jdk1.8.0_202
SPARK_MASTER_HOST=192.168.79.130
SPARK_MASTER_PORT=7077
在这里特别阐述一下每个命令和参数的含义,因为这些参数对于后面的配置很重要:
export JAVA_HOME=~/jdk1.8.0_202代表配置环境变量,也就是jdk的位置;SPARK_MASTER_HOST代表master主机对应的ip地址,在这个例子中填写的是192.168.79.130。注:如果你已经配置好hosts文件,你可以把它替换成设定好的别名,也就是nardack。SPARK_MASTER_PORT代表master主机运行的端口,这个在之后的步骤七会用到,随便写一个0~65535范围内的数即可。
之后我们保存退出,执行下面的步骤:
同步配置到slave虚拟机
别忘了,对于slave虚拟机也要进行同样的配置,包括配置相同的环境变量,即在另一台虚拟机重复上述1~2过程。幸运的是,在两台电脑相互连接的状态下,这个过程可以使用scp命令很方便地实现:
以下代码我们还是在master虚拟机上运行。
我们使用scp命令将spark目录和jdk目录依次复制到slave虚拟机上:
scp -r ~/spark krenz@192.168.79.131:~/spark
scp -r ~/jdk1.8.0_202 krenz@192.168.79.131:~/jdk1.8.0_202
介绍一下scp命令的各个参数:-r代表复制整个目录,~/spark代表本机home下的spark目录,而krenz@192.168.79.131分别代表对方的用户名和对应ip,而后面的:/~/spark就是对方虚拟机home下的spark目录。
在两台电脑相互连接的状态下,可以无需密码执行这个命令。
出现以下现象,说明scp命令运行成功:
- 显示出一大堆文件名以及传输速度等信息:
- 在slave虚拟机的home目录出现了对应的文件目录:
之后,我们别忘了slave虚拟机上的.bashrc文件还没有被编辑过,我们还是重复在master虚拟机上的工作:
在slave虚拟机上先运行:
vim ~/.bashrc
最后一行添加:
export JAVA_HOME=~/jdk1.8.0_202
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=.:$JAVA_HOME/bin:$PATH
最后运行:
source ~/.bashrc
至此,Standalone模式下Spark模式部署已经全部完成,接下来就是运行Spark集群的环节。
五:Local 模式运行 Spark
这个步骤相对比较简单一些,其实这个步骤只需要一台虚拟机就可以执行,我们这里以slave虚拟机为例(这样也有助于确认slave虚拟机的环境是否也已经复制过去):
本地运行spark
当我们按照步骤四配好环境后,直接启动以下命令启动本地spark:
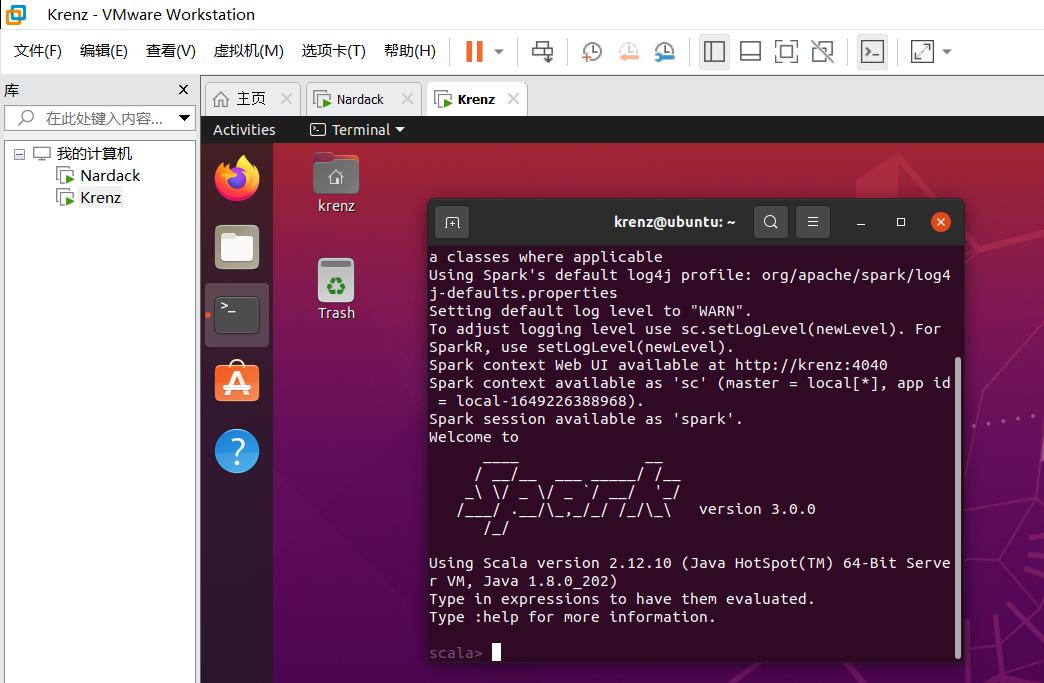
~/spark/bin/spark-shell
出现以下信息,并且最后显示logo,进入到scala>命令行,说明运行成功:
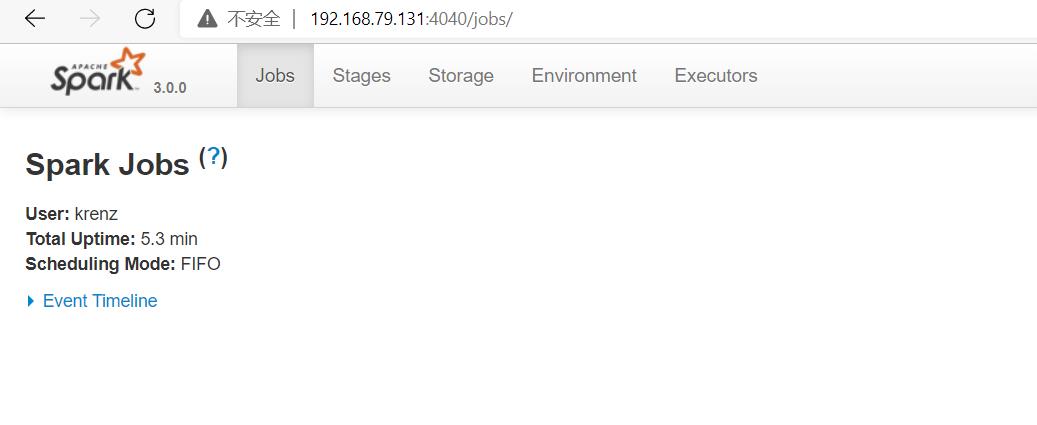
这时候,我们在浏览器中输入slave虚拟机的4040端口,也就是http://192.168.79.131:4040/,就会跳转到Local模式的Web UI界面:
scala运行实例程序
然后我们在scala命令行下运行以下实例程序,这个程序的作用是统计data/word.txt的单词信息。
在运行实例程序之前,我们需要在data目录专门新建一个word.txt文件并输入文字。新建一个terminal,运行:
mkdir data
cd data
touch word.txt
vim word.txt
这个实验中为了方便,我们在word.txt输入以下内容:
The quick brown fox jumps over the lazy dog.
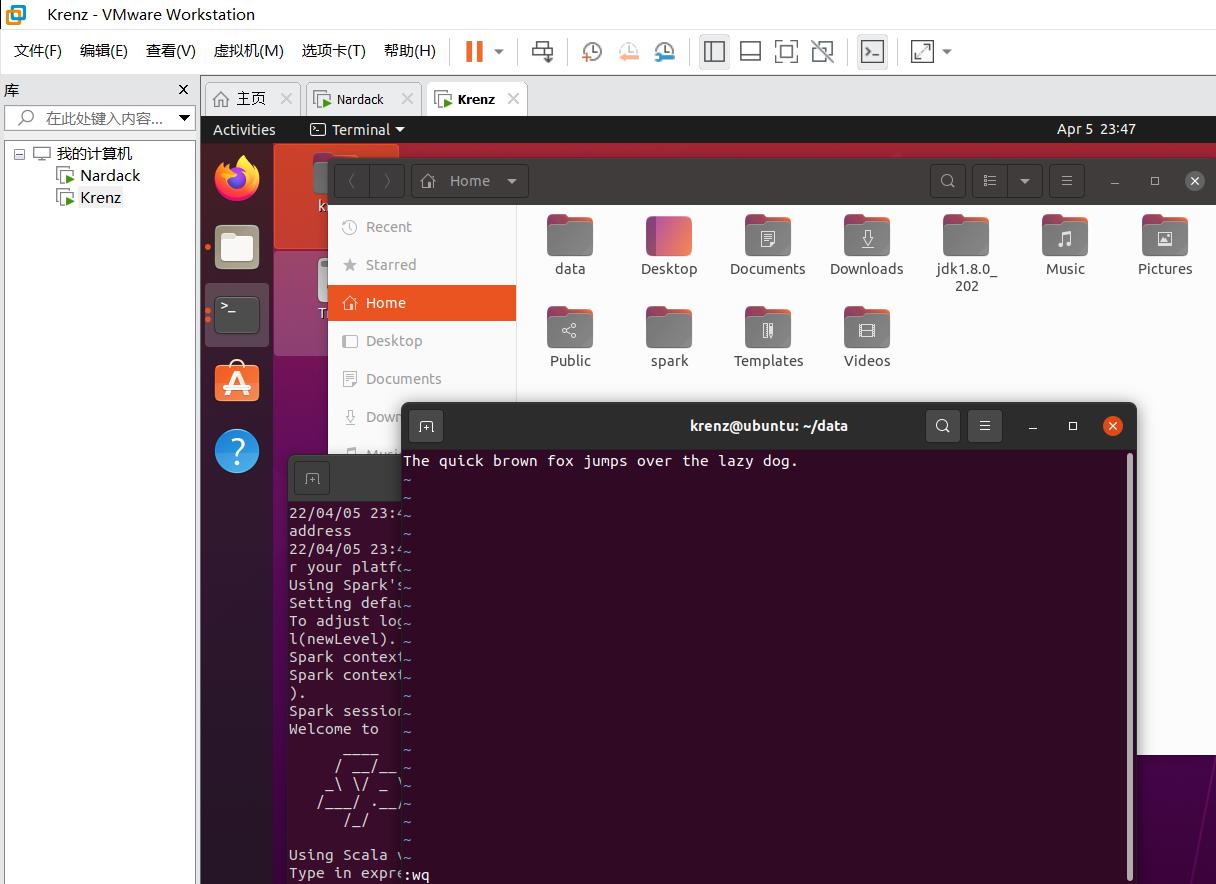
创建完毕之后,我们回到scala>命令行下,输入以下命令:
sc.textFile("data/word.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
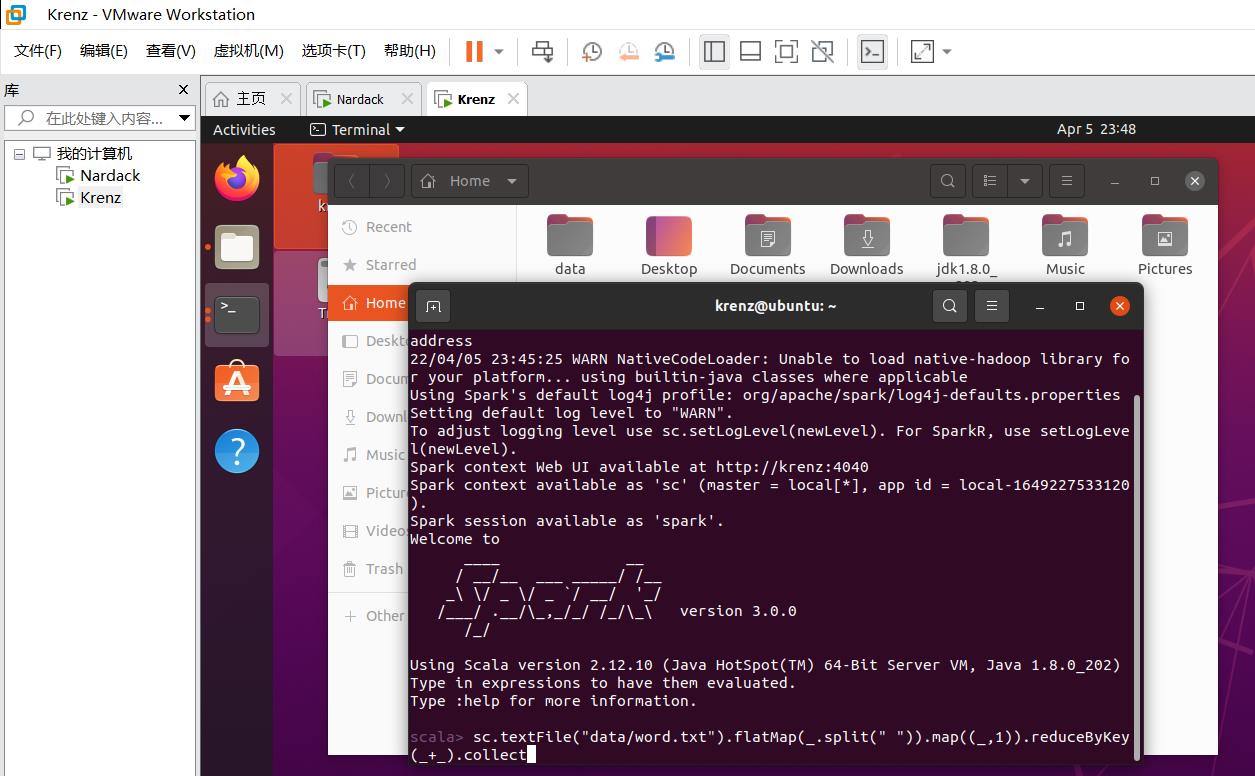
输出以下信息,说明运行成功!
res0: Array[(String, Int)] = Array((dog.,1), (lazy,1), (over,1), (brown,1), (fox,1), (The,1), (jumps,1), (quick,1), (the,1))
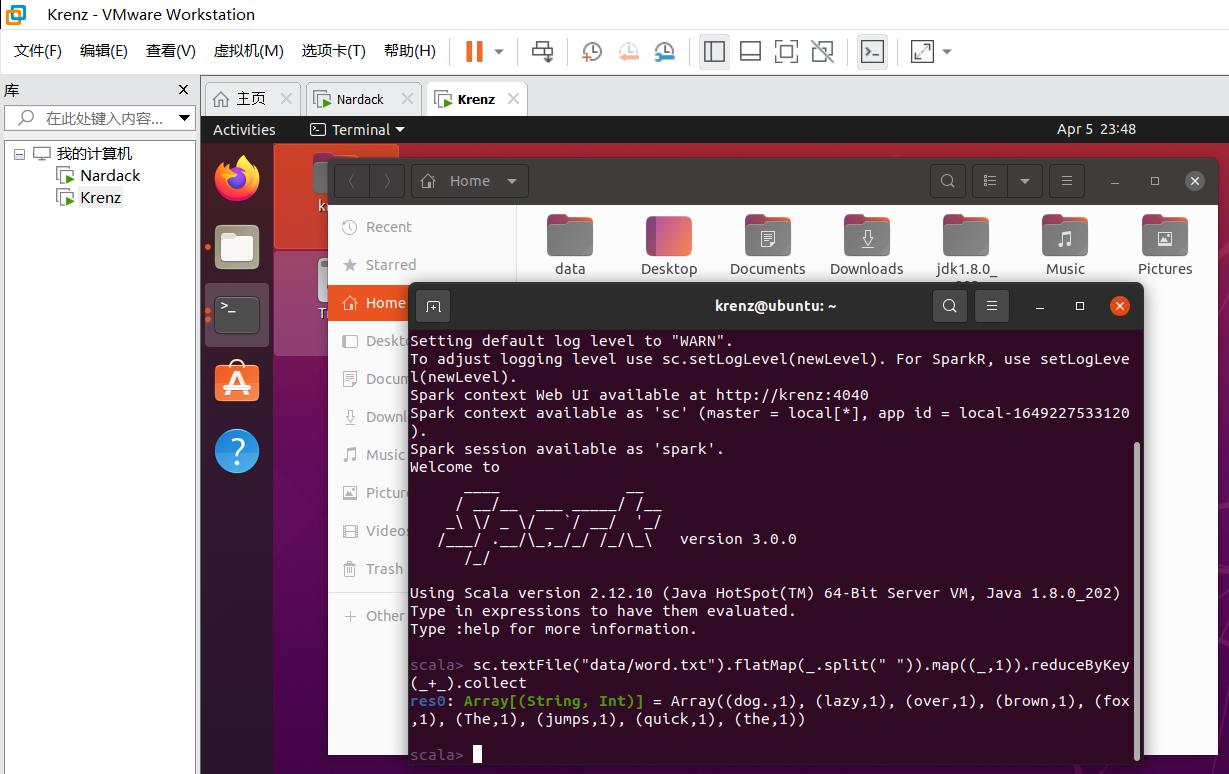
然后我们回到Web UI界面,会发现以下变化:
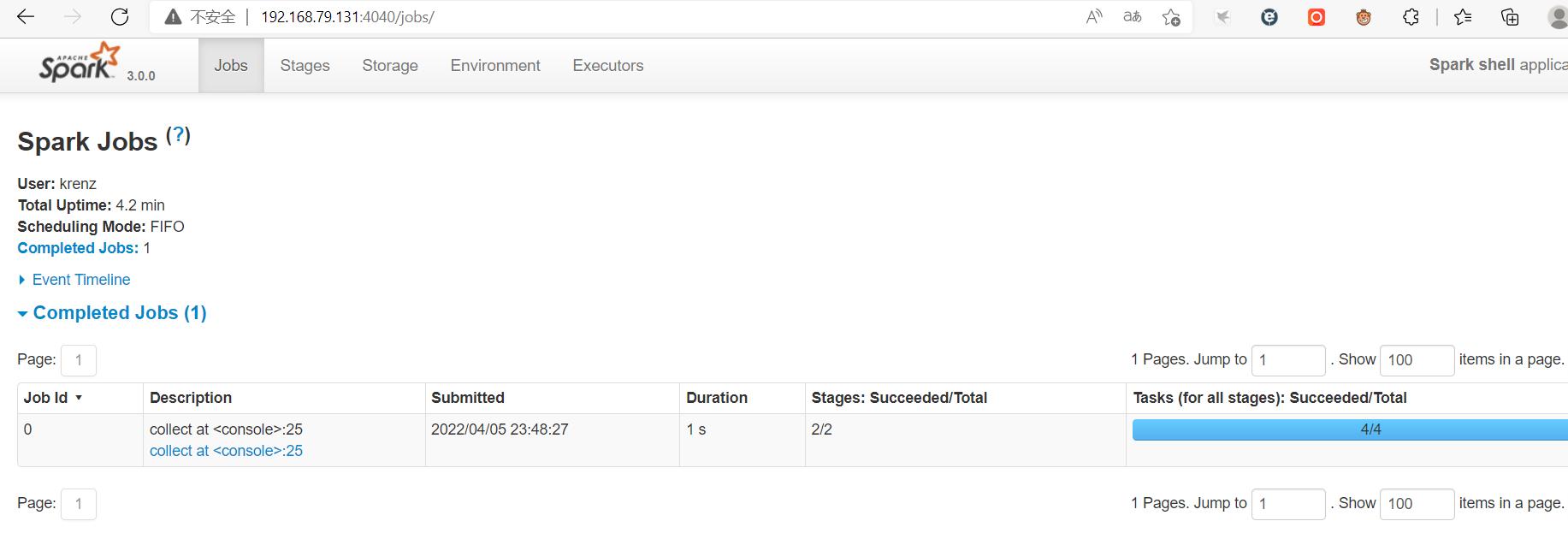
再运行命令一次,发生一下变化:
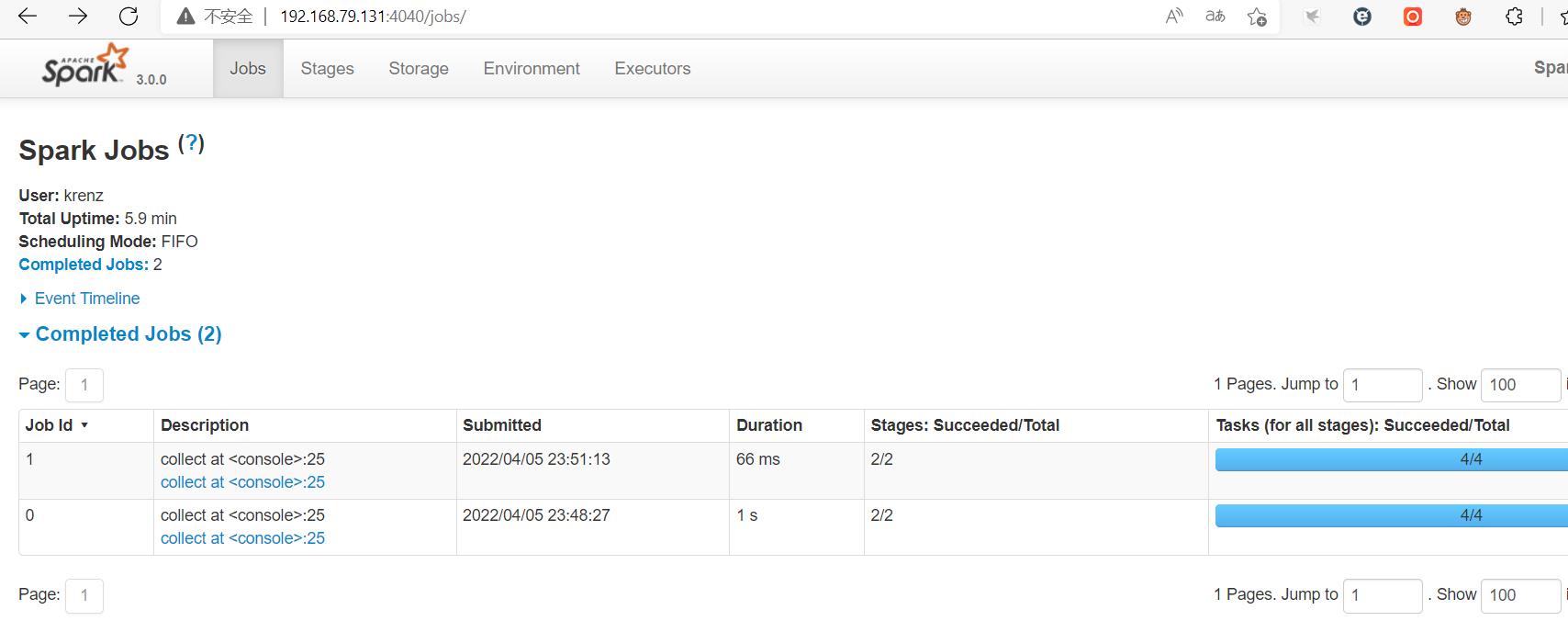
说明本地运行的命令已经上传到Web UI界面。点进去各个超链接,可以了解更详细的运行信息:
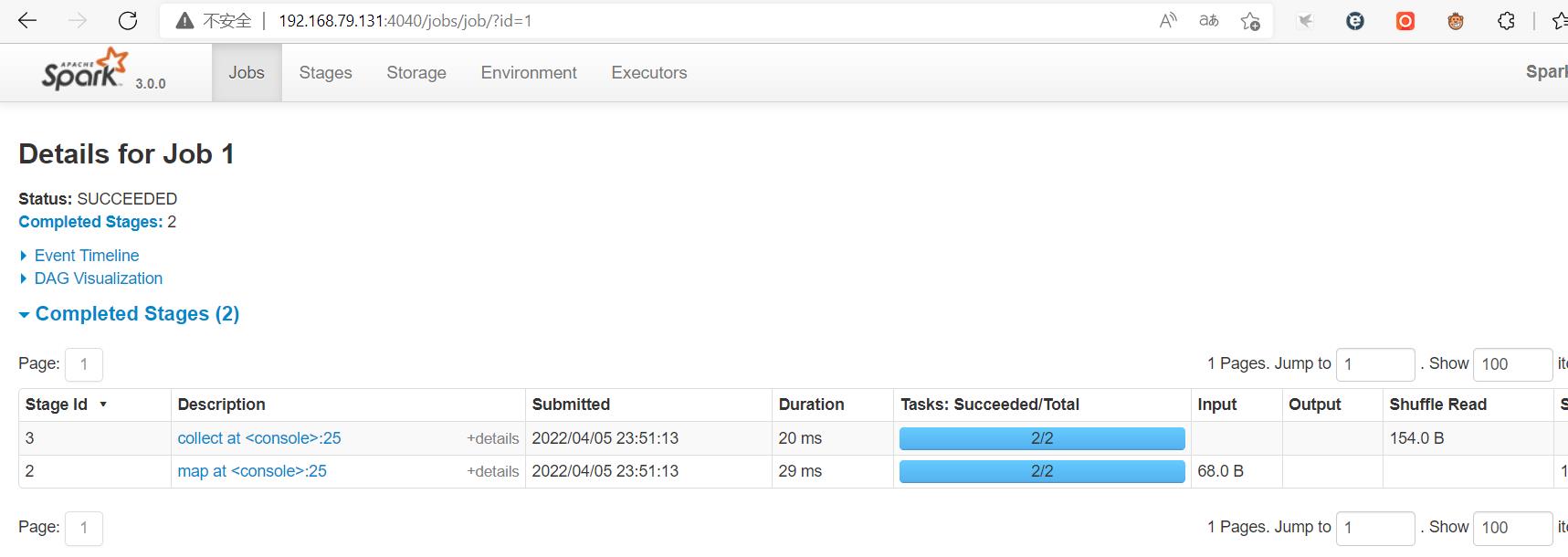
使用spark-submit提交任务
另开一个terminal,然后执行以下命令:
cd spark
bin/spark-submit --class org.apache.spark.examples.SparkPi --master local[2] ./examples/jars/spark-examples_2.12-3.0.0.jar 10
出现以下命令,说明运行成功:
我们关注到Pi is roughly ...这一行,说明示例程序的目的:计算Pi的近似值。可以通过是否出现这一行检测程序是否正常运行。
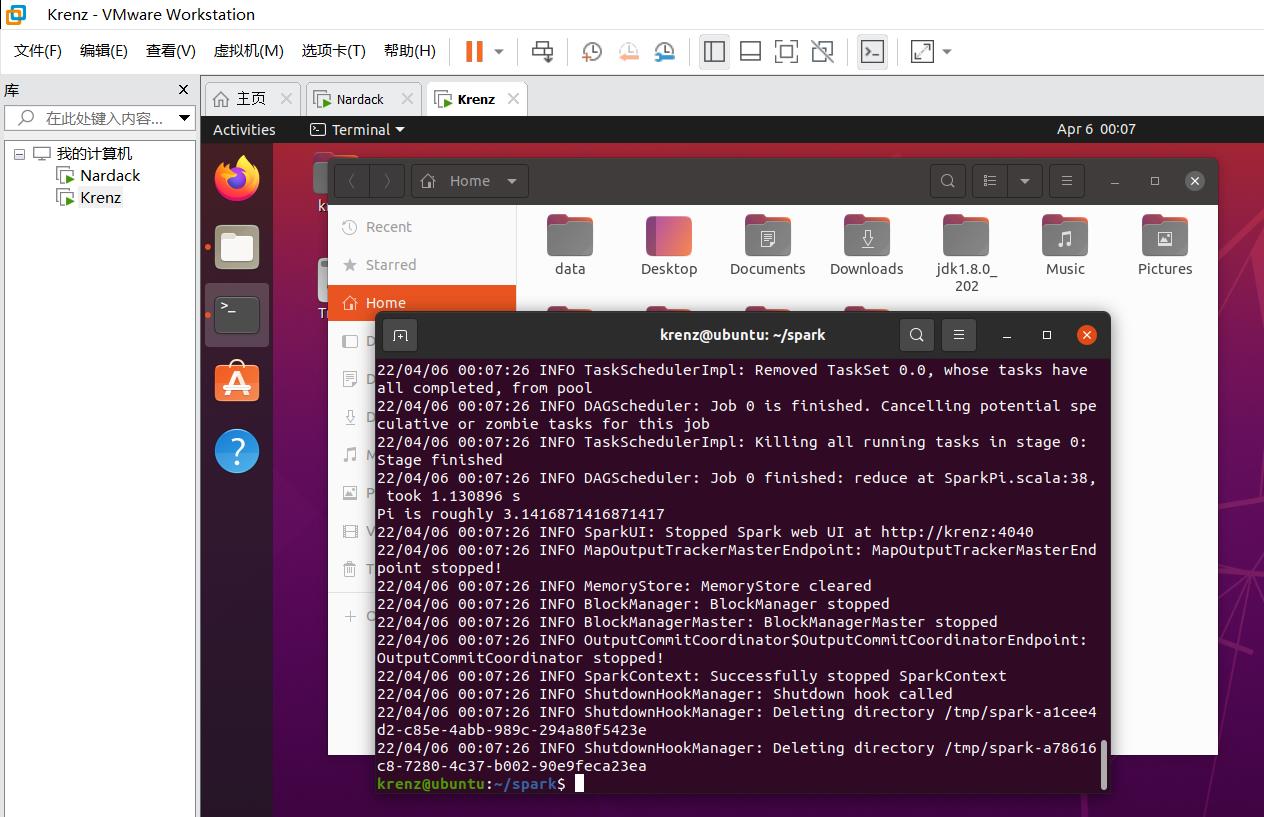
至此,Local模式运行Spark实验正式完成。接下来,我们重点讲一下这个实验遇到的最大的坑点:用户名不同的两个用户Standalone模式运行spark集群。
※六:用户名不同的两个用户Standalone模式运行spark集群(重难点)
如果你的两个虚拟机用户名相同(比如说,都叫nardack),那么可以跳过步骤六,直接进入到步骤七。
问题原因分析
按照网上的传统方法,运行以下命令之后:
~/spark/sbin/start-all.sh
就会出现以下问题:
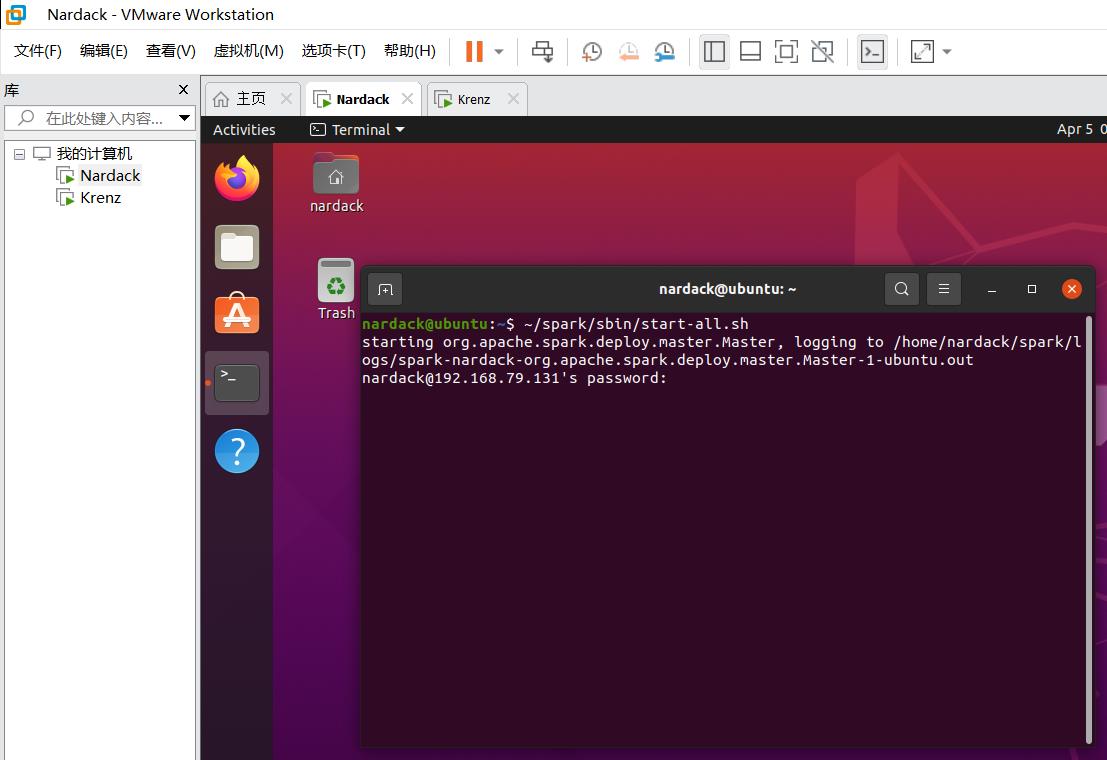
神奇的事情发生了:哎,这ssh都齐了怎么还得输密码啊?这我连接的是对方的服务器怎么还是叫nardack@192.168.79.131呢?
原因其实是这样的:
192.168.79.131是那个叫krenz的用户名ip地址,而spark在启用这个节点时,会直接把本地的username(即nardack)以及slave文件里面的ip地址直接拼接上。
也就是说,程序在处理这个ip地址的时候,会自动把"nardack"和192.168.79.131拼接变成nardack@192.168.79.131。
换句话说,只有nardack@192.168.79.130和krenz@192.168.79.131这两个主机用户名和ip地址是真正存在的,而nardack@192.168.79.131这个地址根本就不存在,更别提相互连接了。
要解决这个问题有三种方案:
- 使用两个初始用户名一样的虚拟机,但是这样显然不符合实际需求以及实验的完整性。
- 研究不同用户名下spark的相互连接方法,修改shell文件。
- 在两台虚拟机上均新建相同的用户名。
由于方案2过于复杂,这里我讲解一下方案3,也就是在两台机器上新建相同的用户名,并把对应文件复制过去。
在两台机器上新建相同的用户名
我们先确定好两台机器相同的用户名,在这个例子里面,我们选定sparktest作为我们的相同用户名。
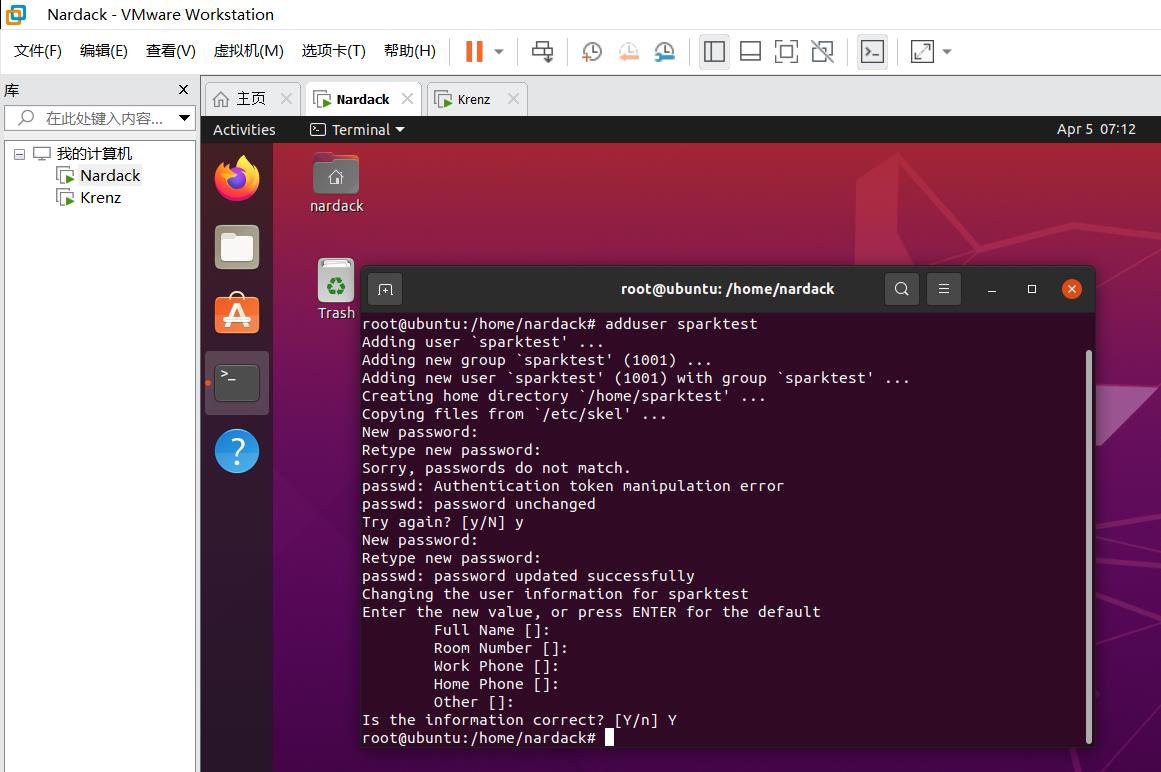
我们先在master虚拟机上创建这个用户,运行
sudo su
进入到root用户:

然后,运行以下命令创建新用户sparktest:
adduser sparktest
之后机器会让你输入密码,直接输入一个好记的密码即可。之后会让你填充一些用户的基本信息,这里一直回车,最后按Y即可:
点击右上角就可以看到切换用户的选项,然后切换到sparktest这个用户即可:

记得对于slave虚拟机也进行同样操作。
为新用户配置ssh文件
在这之后,针对两台机器的sparktest用户同样要进行配置ssh,免密码相互连接的操作,即重复步骤三。
幸运的是,由于我们已经用apt装好相应组件了,而这些组件是给所有用户共用的。因此,我们可以省去sudo apt install openssh-server相关的操作。
这里需要特别注意的是,在配置ssh文件的时候,由于本地的sparktest还没有生成对应的ssh密钥,因此本地也需要复制一份。
换句话说,两台虚拟机上都需要运行以下命令:
ssh-keygen -t rsa
ssh-copy-id -i sparktest@192.168.79.130
ssh-copy-id -i sparktest@192.168.79.131
这个过程中,提示输入yes/no的时候输入yes,然后paraphrase的环节直接回车。

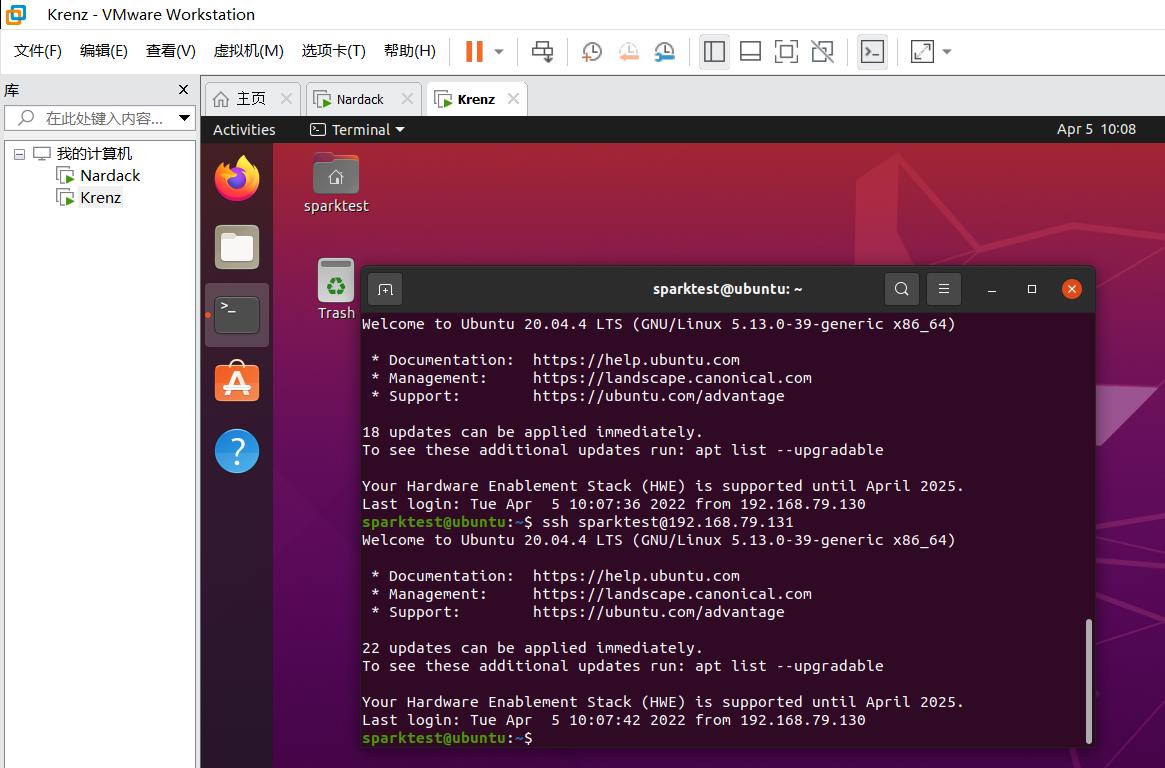
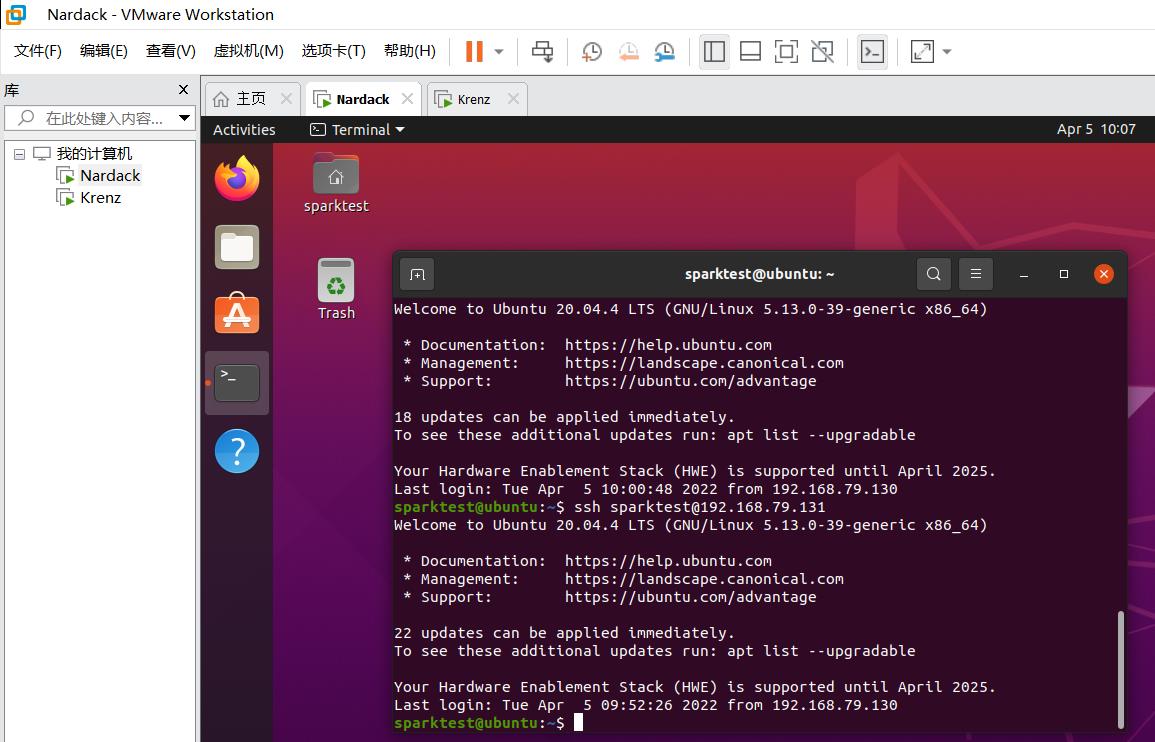
然后是例行的相互连接测试,这里需要顺便测试一下ssh无密码访问自己。两台虚拟机上都跑一遍以下命令:
ssh sparktest@192.168.79.130
ssh sparktest@192.168.79.131
为新用户设置sudo权限
我们注意到sparktest不在sudoer列表中,因此我们需要手工配置。
我们先切换到nardack这个用户(也就是系统的admin用户),并执行以下命令:
sudo visudo
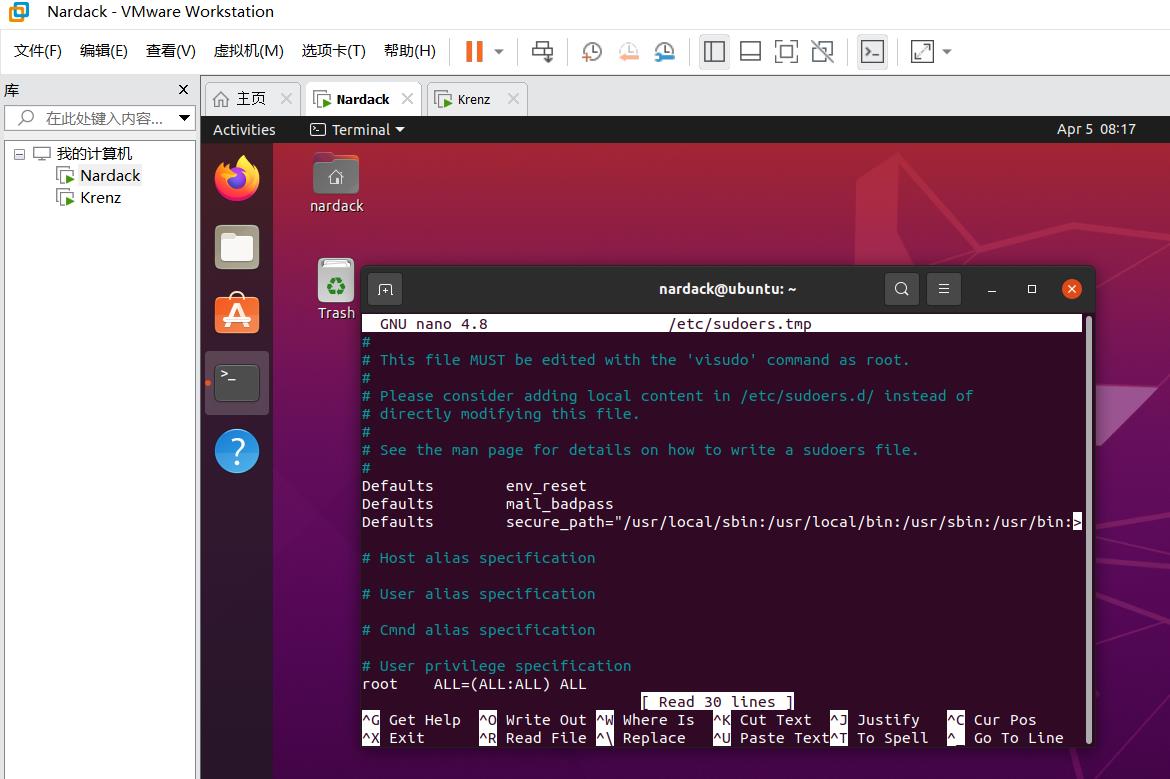
然后我们修改中间这一行,将sparktest添加到sudoer列表中:
root ALL=(ALL) ALL
sparktest ALL=(ALL) ALL
注意到我们使用的字符编辑器不同。修改完毕后,我们需要按CTRL+X进行退出。
然后会询问是否保存,这里直接填Y然后按回车。
之后会询问保存到哪个文件,直接按回车即可。
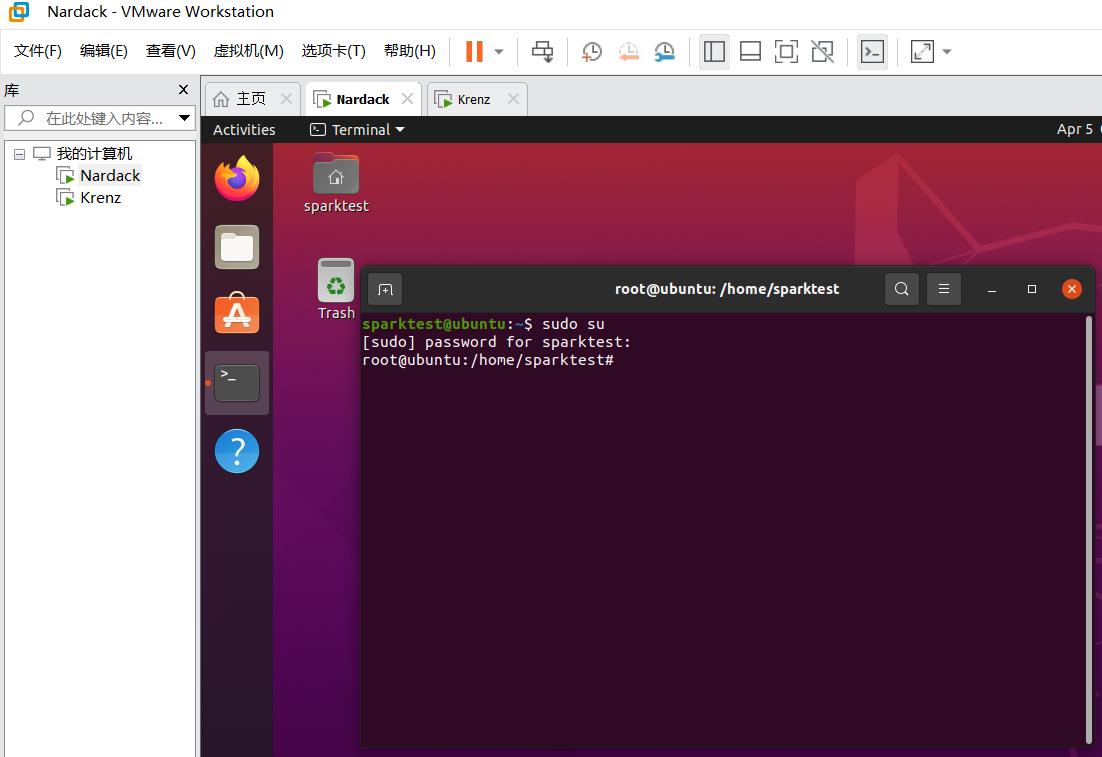
然后我们再次切换到sparktest用户下,如果我们运行sudo su能够直接切换到root用户,说明sparktest已经在sudoer列表中,可以使用sudo命令。
复制spark和jdk到新用户目录下
接下来,我们要做的就是把原来用户名为nardack,krenz下面的文件夹分别复制到两台虚拟机的sparktest用户名的目录下。
cp -r -p /home/nardack/spark /home/sparktest/spark
cp -r -p /home/nardack/jdk1.8.0_202 /home/sparktest/jdk1.8.0_202
介绍一下各个参数的含义:cp命令就是linux下的本地复制命令(远程复制是scp),-r代表复制目录,-p代表把文件对应的权限也拷贝过去(如果不这样做,会发现复制的文件是上了锁的,也就是ReadOnly),/home/nardack/spark代表原来的目录,/home/sparktest/spark代表新的目录。
然后我们打开sparktest的home目录,我们发现文件已经成功复制好,并且拥有了权限:
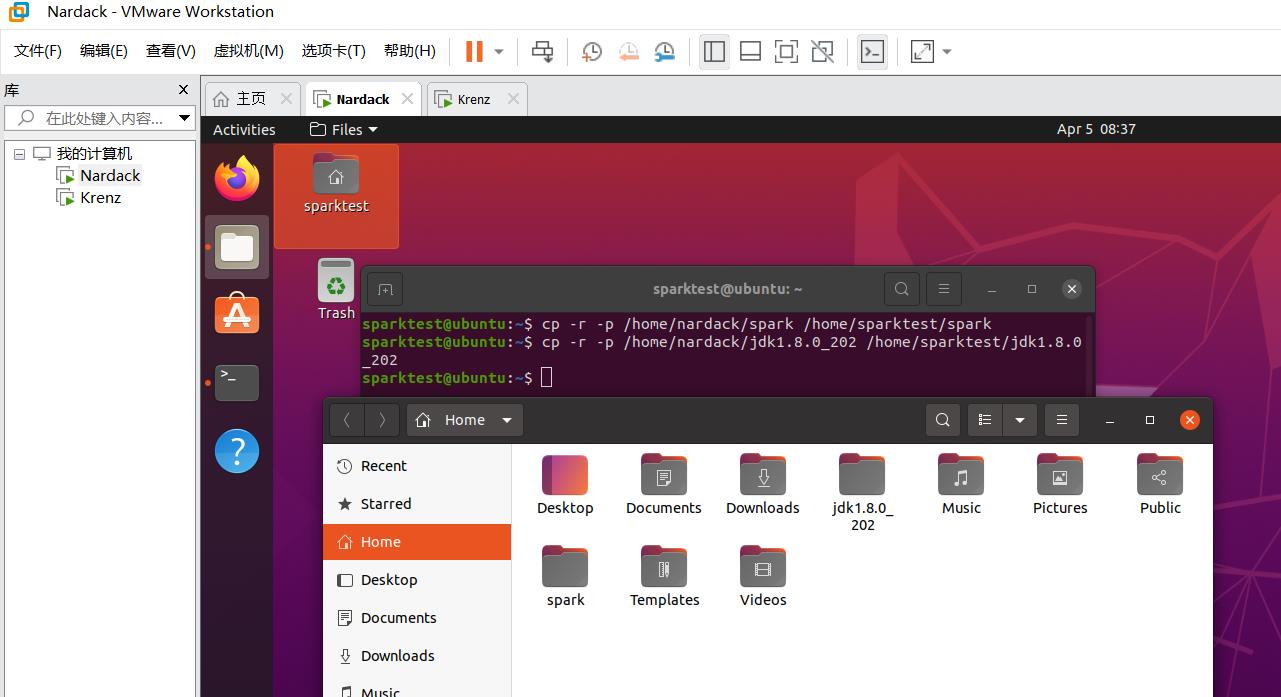
然后对于slave虚拟机也进行同样的操作:
其实只要想办法把master下的spark和jdk都复制过来就行,这里仍然使用和上面一样的流程:
cp -r -p /home/krenz/spark /home/sparktest/spark
cp -r -p /home/krenz/jdk1.8.0_202 /home/sparktest/jdk1.8.0_202
之后别忘了分别重新设置两个新用户的~/.bashrc文件,剩下的在前面的步骤已经配置好了:
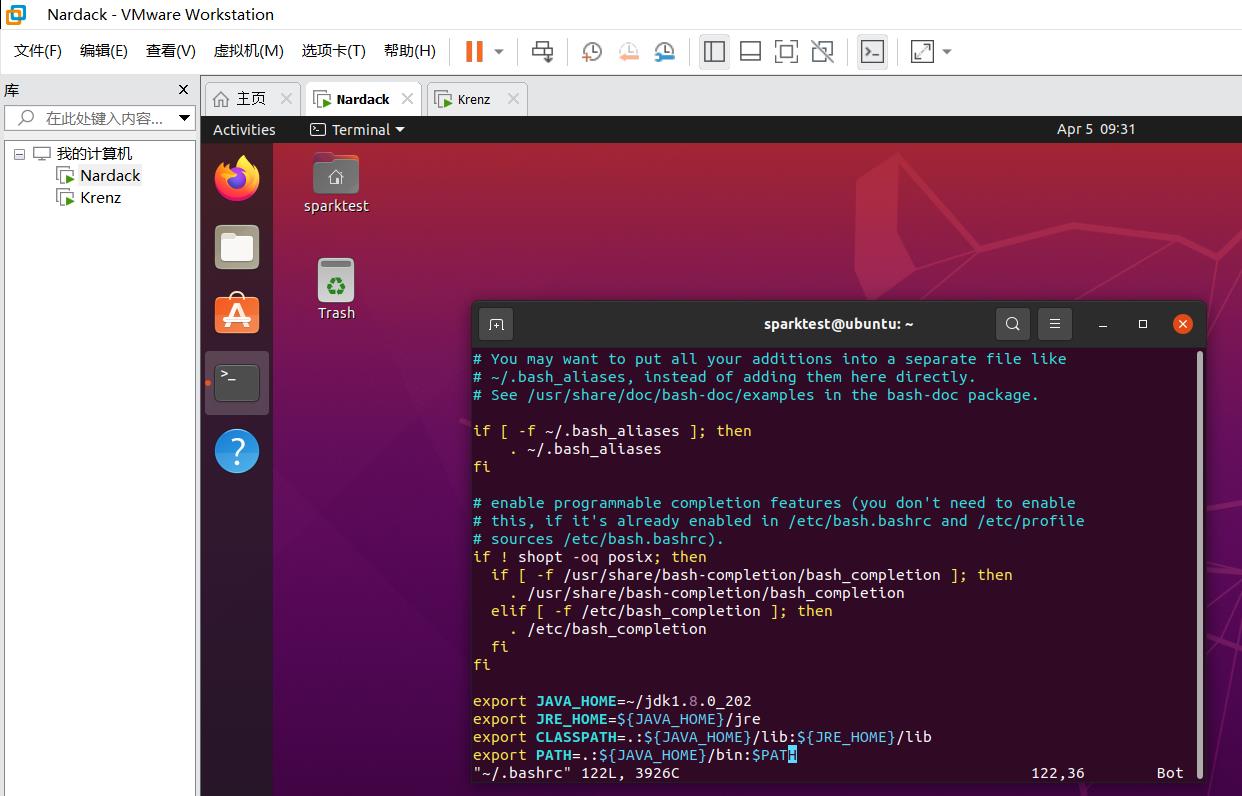
至此,两台虚拟机切换到同名用户以及要做的工作已经全部完成。
七:Standalone模式spark集群运行以及提交任务
开启spark的master和slave节点
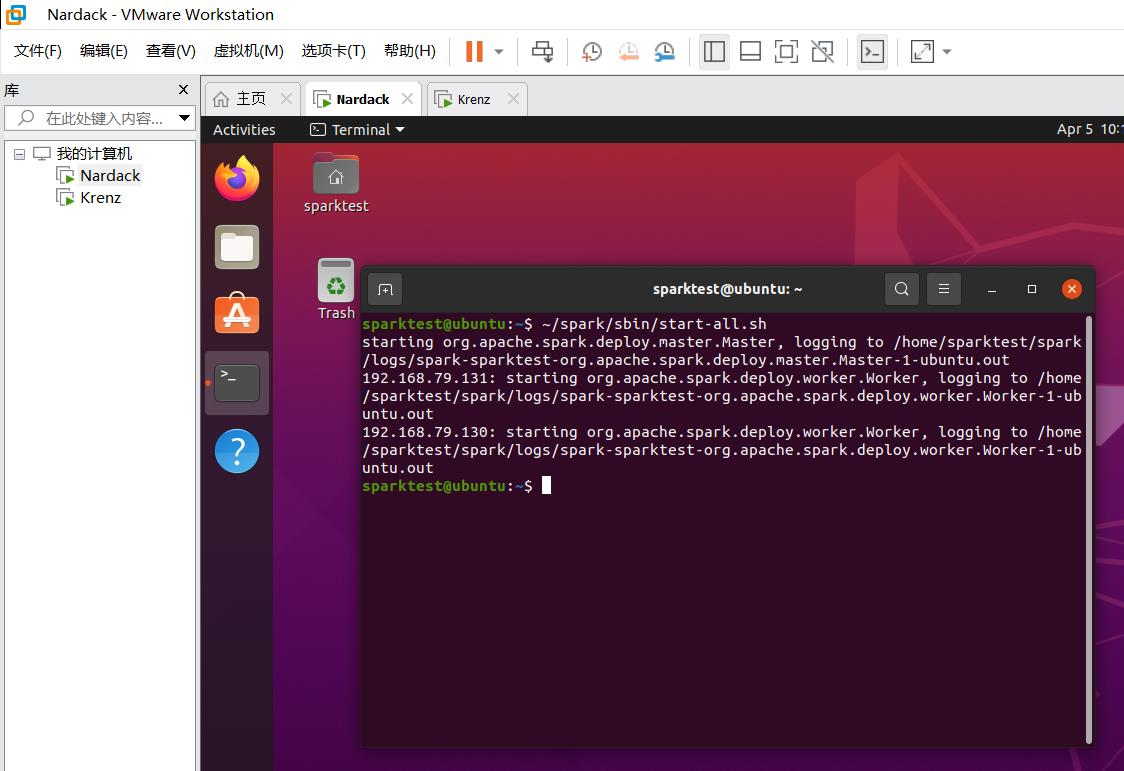
在master虚拟机的sparktest用户下运行:
~/spark/sbin/start-all.sh
顾名思义,start-all.sh就是运行spark的所有节点。
或者替代的,直接运行下列命令也可以(事实上,start-all.sh本质上就是依次执行下面两个命令):
~/spark/sbin/start-master.sh
~/spark/sbin/start-slaves.sh
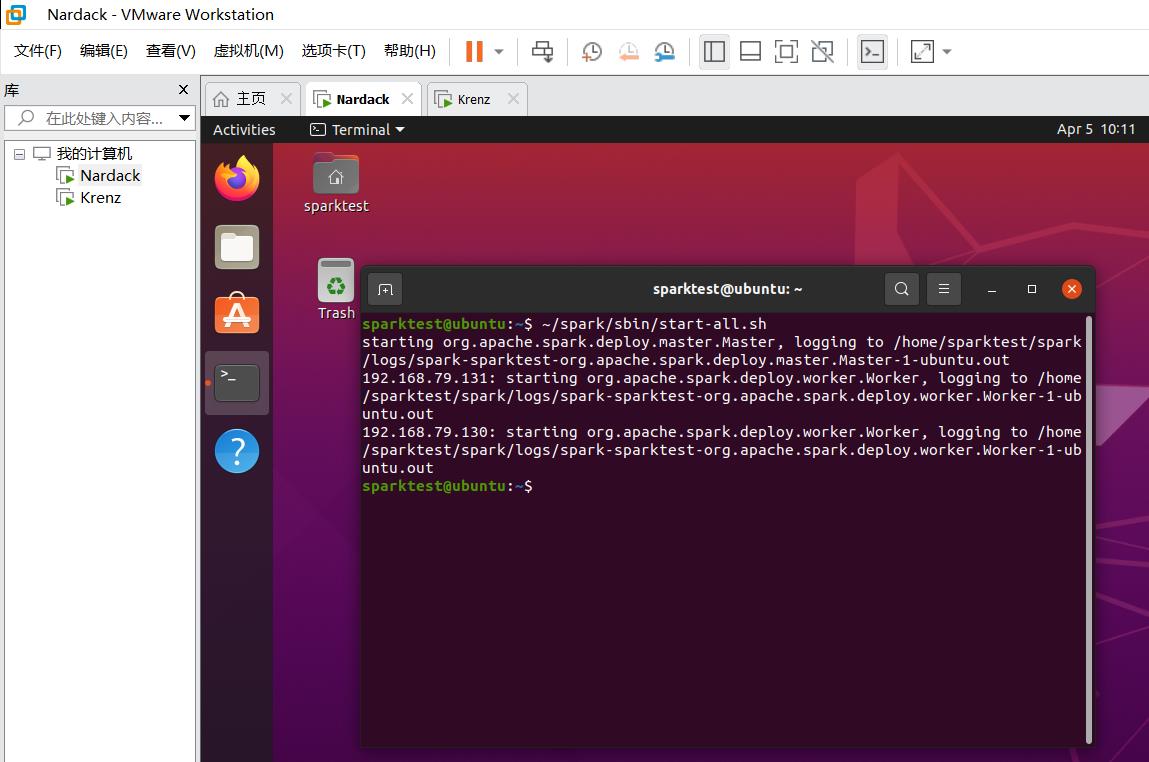
注:如果出现了如下的Stop it first的问题,说明之前运行的节点没有关闭,这时候运行以下命令即可。stop-master.sh就是停止运行spark的master节点,stop-slaves.sh就是停止运行spark的所有slaves节点。
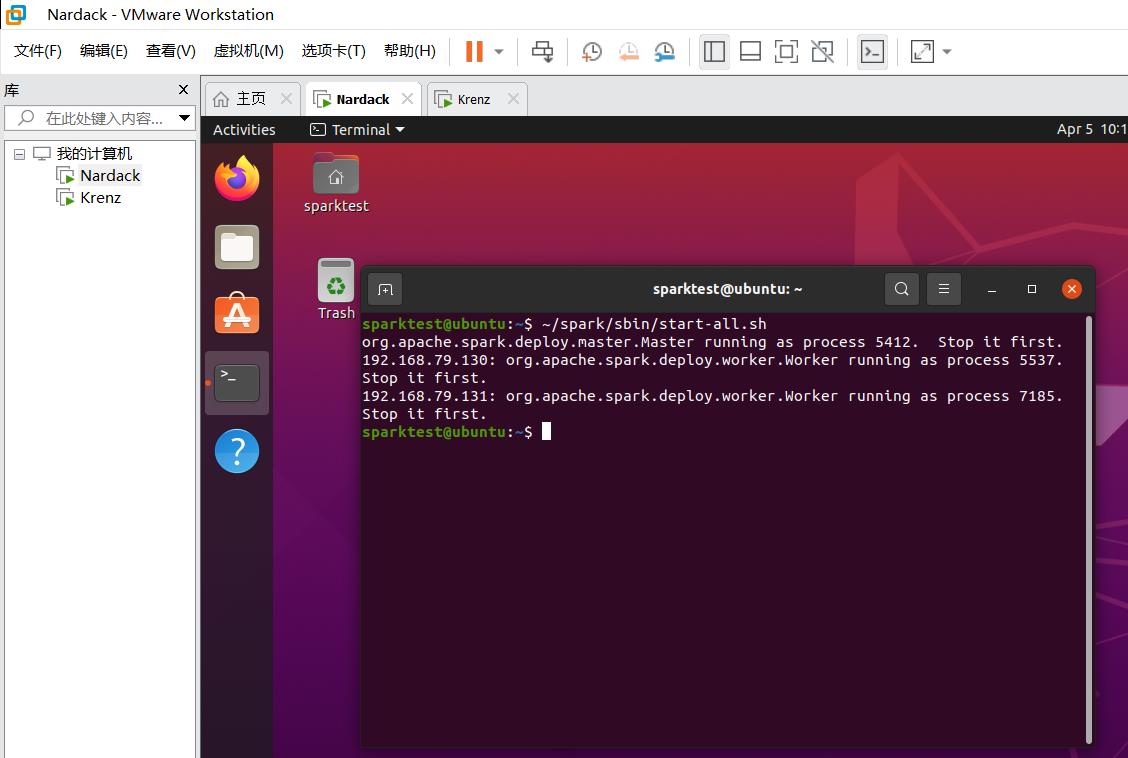
运行命令:
~/spark/sbin/stop-all.sh
或者
~/spark/sbin/stop-master.sh
~/spark/sbin/stop-slaves.sh
之后的结果:
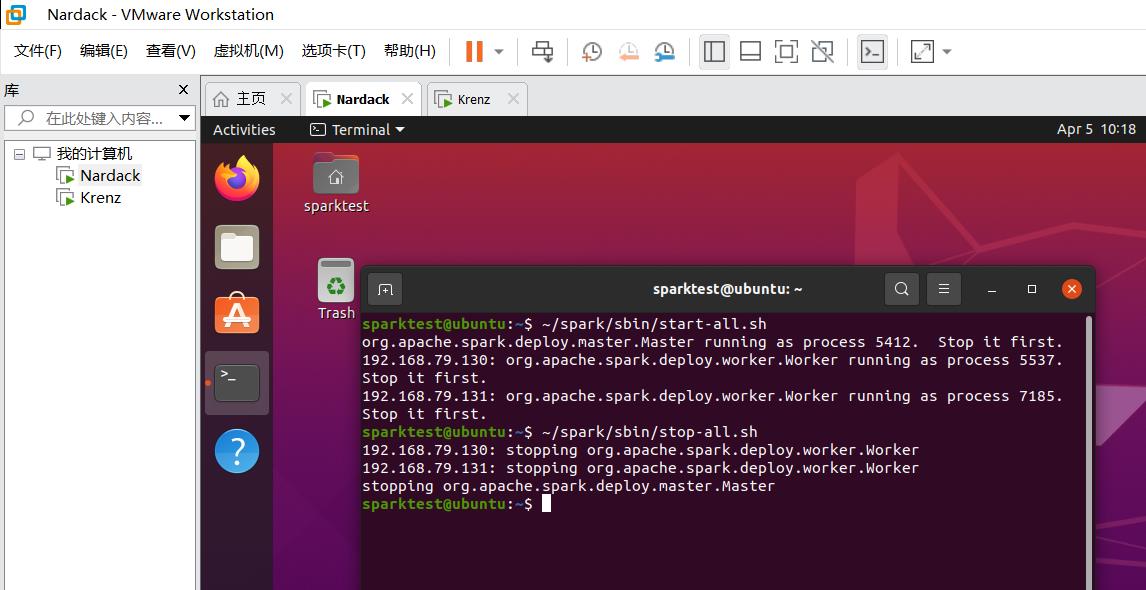
如果出现以下实验现象,说明spark集群搭建成功!
- 程序输出如下三条语句,并且正常退出(即又回到
sparktest@ubuntu:这个命令行):
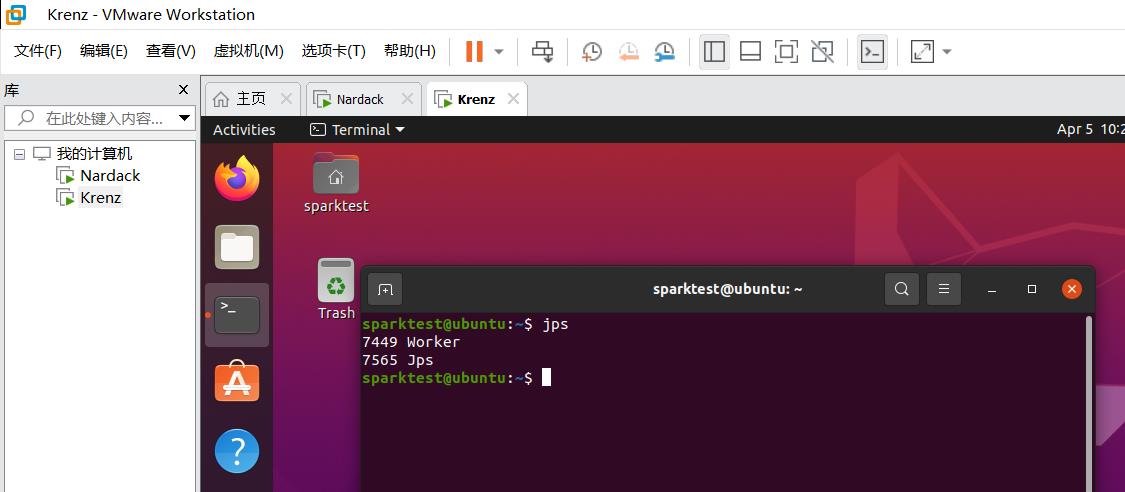
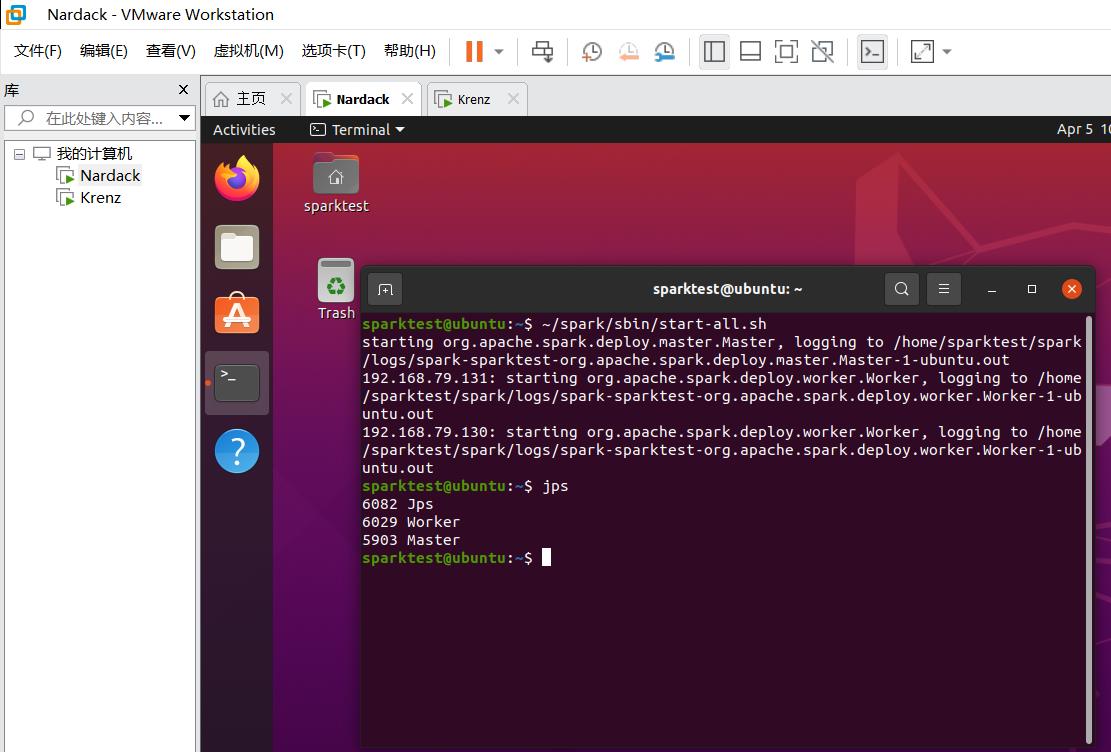
- 在master虚拟机上执行jps命令可以看到
Jps Master Worker三个进程,在slave虚拟机上可以看到Jps Worker两个进程:
- 用浏览器进入
http://192.168.79.130:8080/,可以看到以下的Web UI界面,其中:-
恰好有两个worker(一个是master虚拟机的,一个是slave虚拟机的)
-
上面显示
Spark Master at spark://192.168.79.130:7077(这里的7077就是之前在spark-env.sh里配置好的SPARK_MASTER_PORT,在下一步就会用到)

-
等这个界面成功显示之后,我们就可以通过spark进行submit等操作了。
使用spark-submit提交任务
在master虚拟机上,执行以下命令:
cd spark
bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://192.168.79.130:7077 ./examples/jars/spark-examples_2.12-3.0.0.jar 10
如果已经按附录配置好host文件,将spark://192.168.79.130:7077替换成spark://nardack:7077也是可以的:
cd spark
bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://nardack:7077 ./examples/jars/spark-examples_2.12-3.0.0.jar 10
其中spark://192.168.79.130:7077就是上面已经配置好的master运行的IP地址和端口,而7077就是之前配置好的SPARK_MASTER_PORT。
在这个实验中,我们只需要复制上面的命令即可。
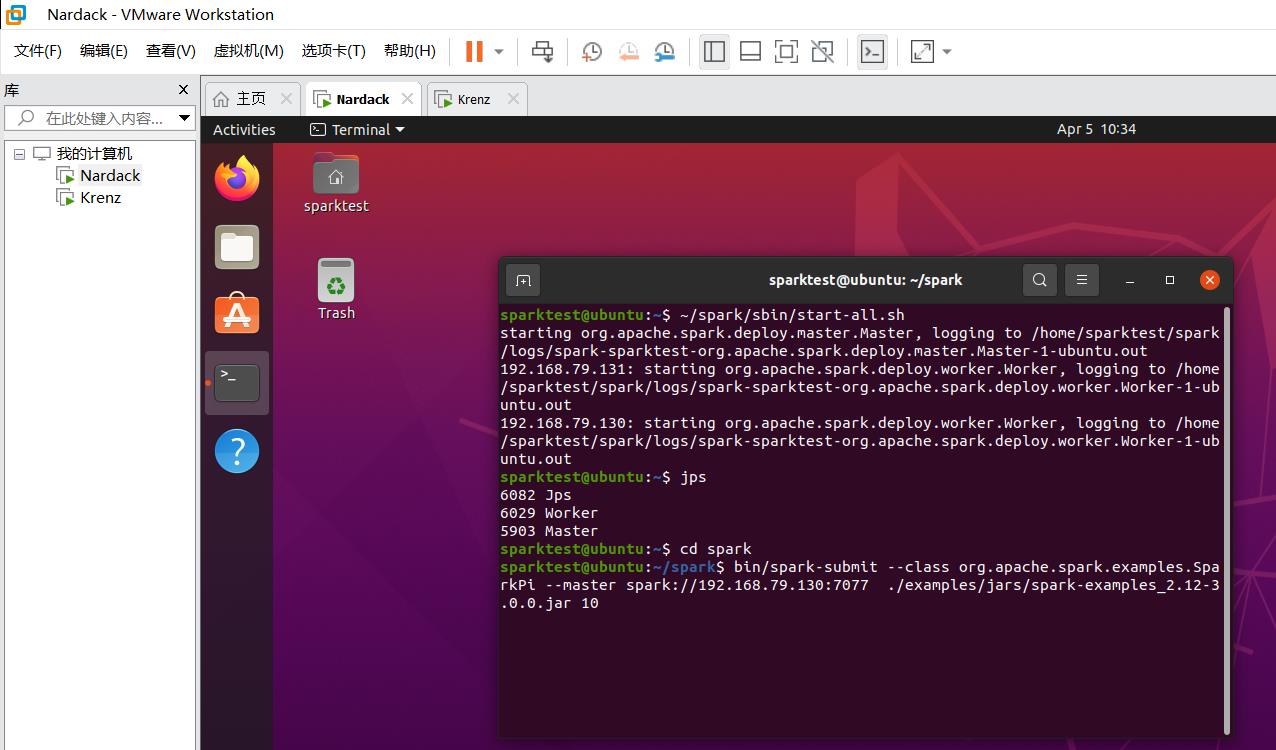
如果程序正常退出且不报错,说明运行成功!同Local模式搭建一样,我们可以通过是否出现Pi is roughly ...这一行检测程序是否正常运行。
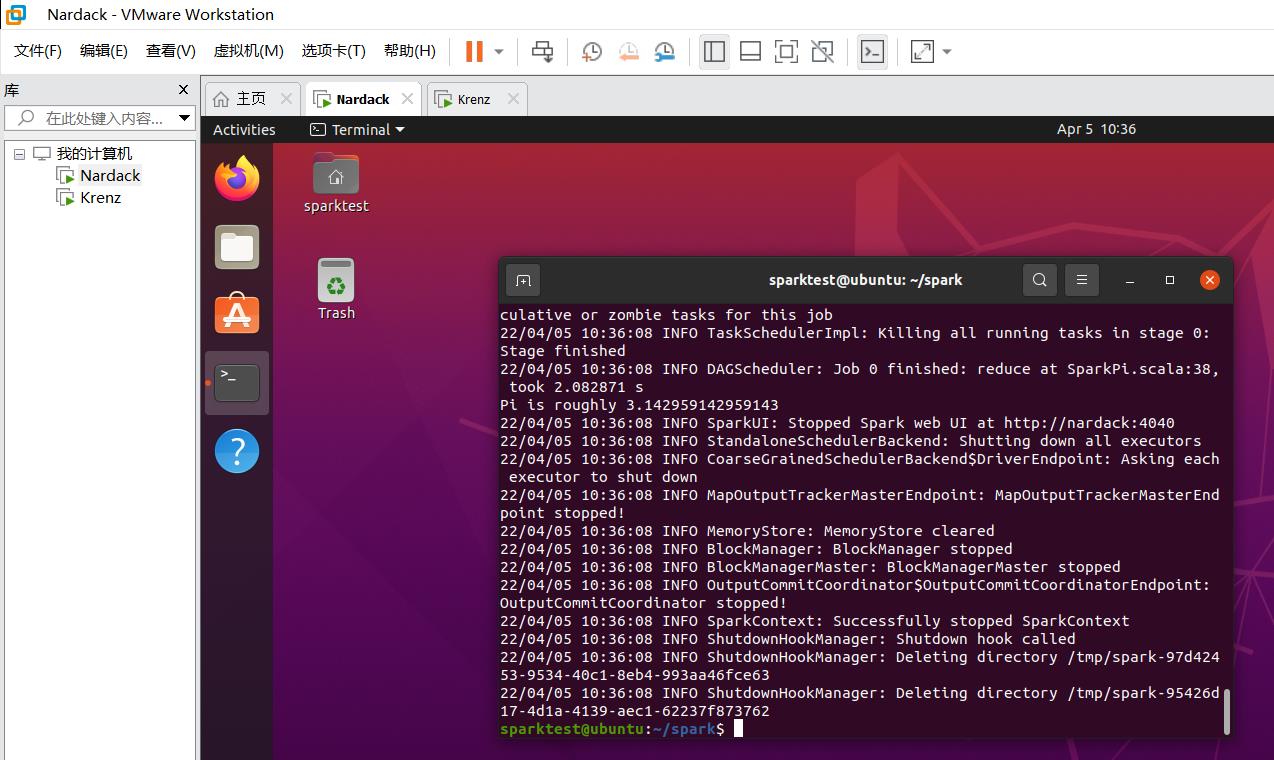
之后我们去观察Web UI界面,会看到如下变化:

我们可以尝试点进去各种超链接,观察更详细的信息:
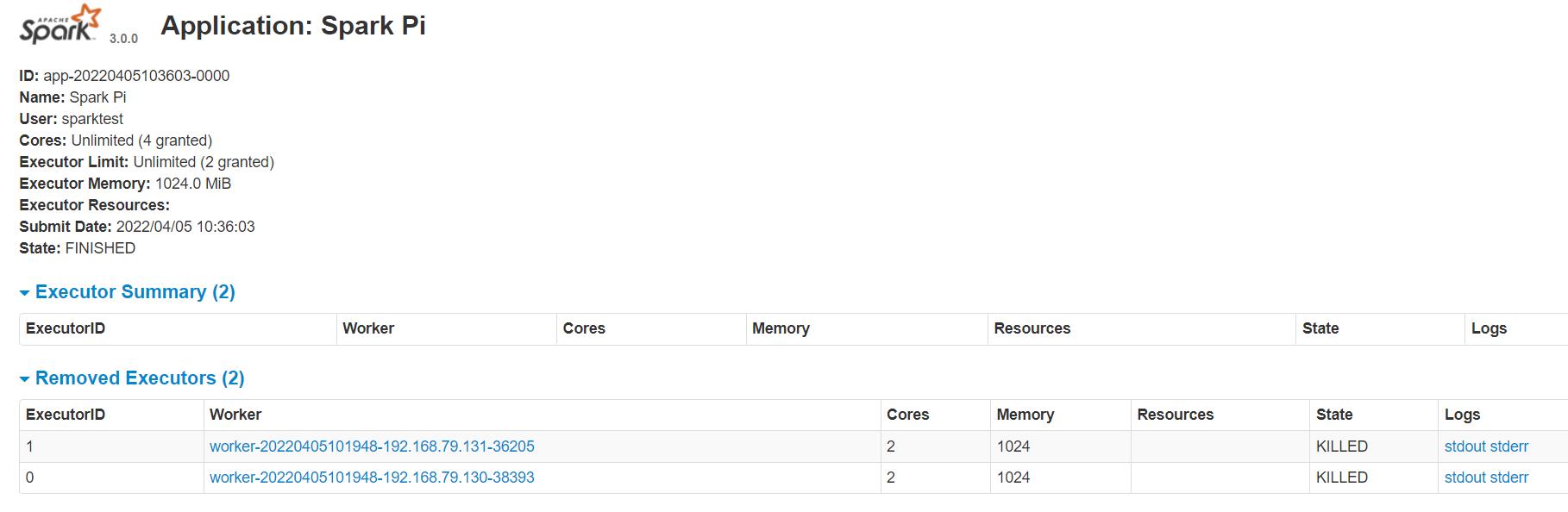
做完实验之后,别忘记执行stop-all.sh关闭所有的节点(当然,如果你关机的话,节点也就自动关掉了):
实验总结
至此,作为云计算基础中的基础,云计算101——Spark Standalone模式搭建实验正式完成!相信大家做完这个实验,对于云计算公理,访问ip地址,ssh互联,远程传输,配置权限等基础知识会有更深刻的理解~
附录:可选步骤
配置hosts文件(在步骤二完成后可选)
为了减少虚拟机输入ip地址的麻烦,我们可以采用通过配置hosts文件的方法,用别名代替ip地址:
在两台虚拟机上均运行:
sudo apt install vim
sudo vim /etc/hosts
这里vim前面加入sudo的目的是为了获取hosts文件的修改权限。
然后按i进入INSERT模式在host文件里添加以下内容:
192.168.79.130 nardack
192.168.79.131 krenz
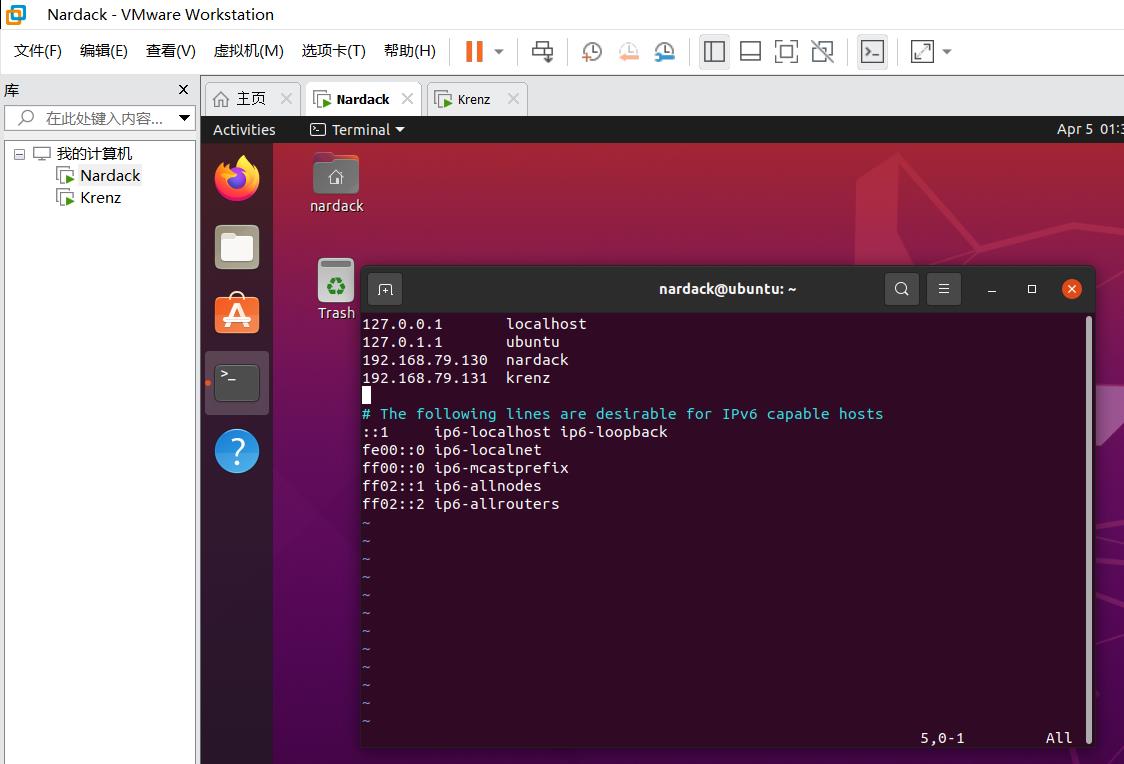
之后按ESC进入到命令模式,输入:wq保存并退出。对于两台虚拟机都进行一样的操作。
配置Hosts文件的主要目的就是为其他主机的ip设置一个别名。换句话说,对于之后要调用master(Nardack)或者slave(Krenz)虚拟机对应ip的操作,只需要输入nardack或者krenz这个字符串即可。
例如,为了查看配置host文件的过程是否成功,直接在master虚拟机上运行ping krenz即可。
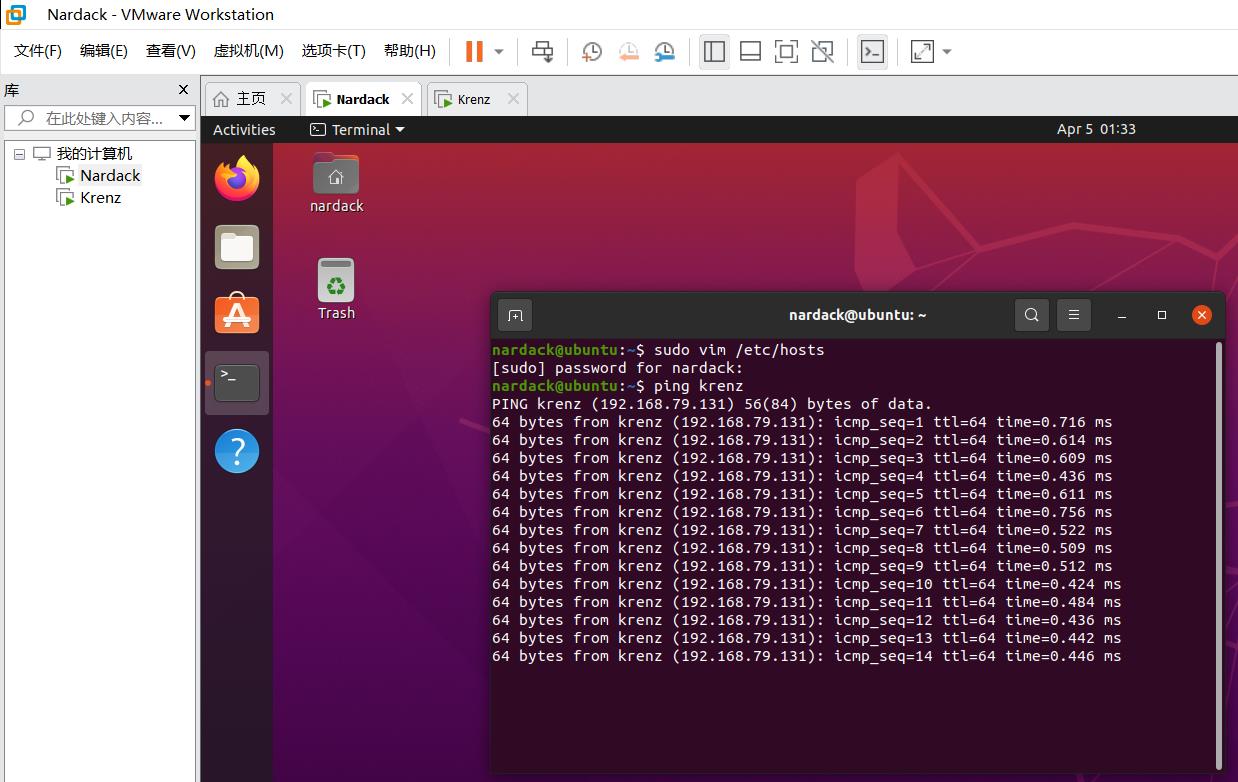
可以发现,在ping的界面显示了PING krenz (192.168.79.131)这个信息,说明host文件已经成功把krenz当成了ip地址192.168.79.131的引用。
配置ssh别名(在步骤三完成后可选)
在master虚拟机下,进入.ssh目录,并创建config文件:
cd ~/.ssh/
touch config
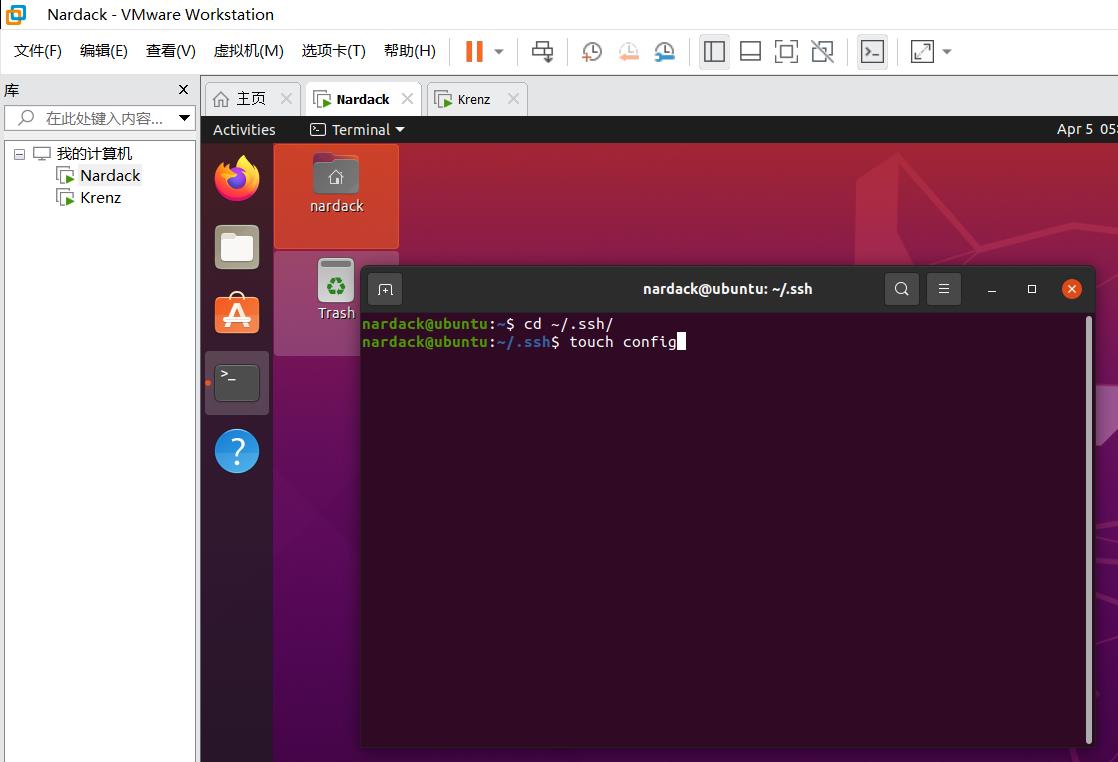
用vim编辑config文件:
vim config
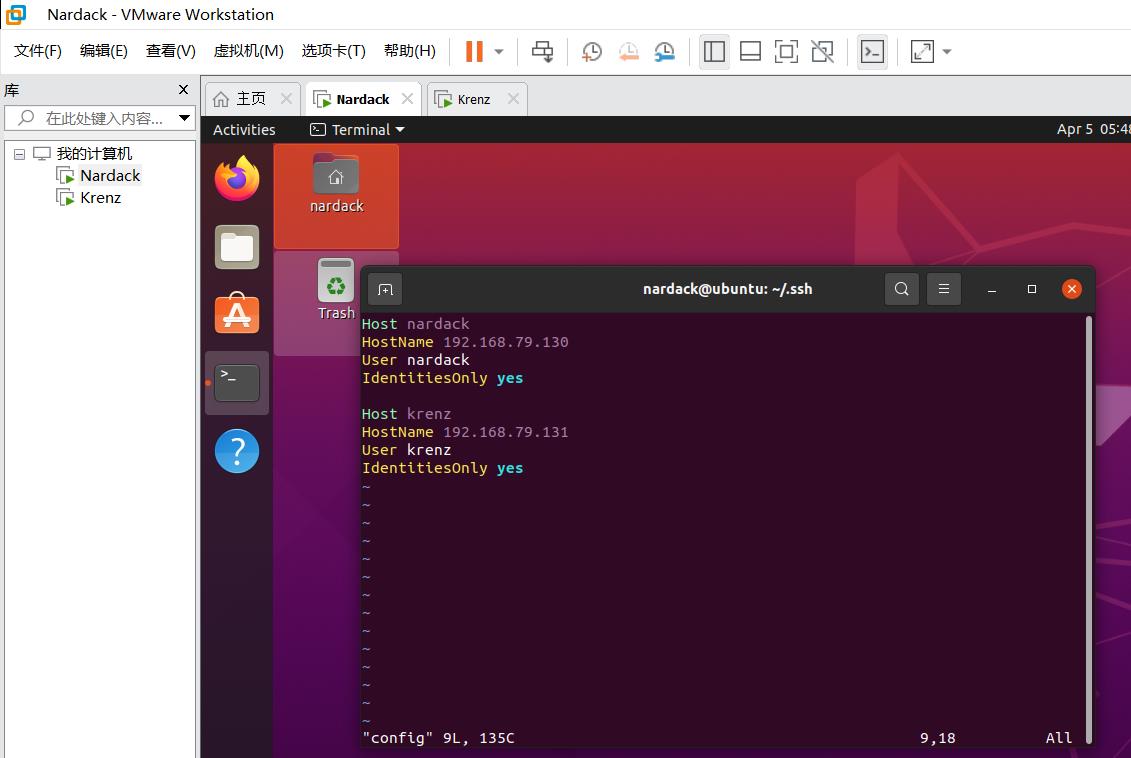
添加如下内容:
Host nardack
HostName 192.168.79.130
User nardack
IdentitiesOnly yes
Host krenz
HostName 192.168.79.131
User krenz
IdentitiesOnly yes
对于每一组,Host代表着ssh别名,HostName代表着对应ip地址,User表示要登录的用户名(在这个情况下,和Host别名相同),IdentitiesOnly直接默认是yes即可。
之后,我们尝试使用ssh一下ssh别名来验证是否成功:
ssh nardack
ssh krenz
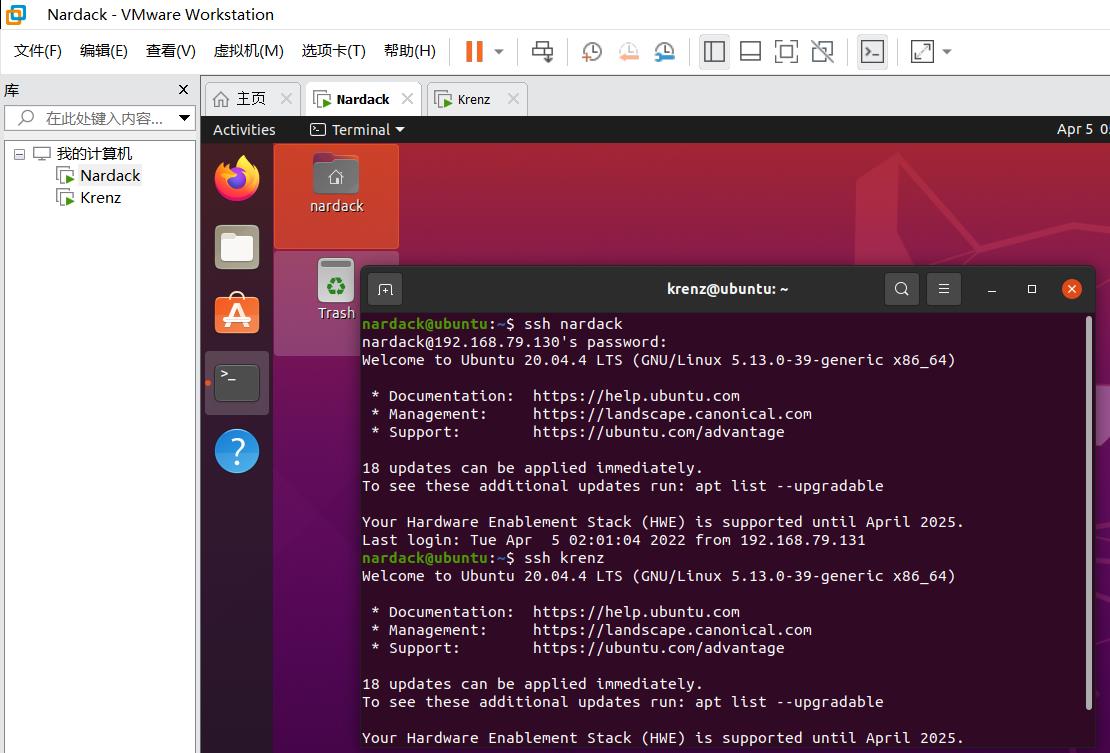
如果出现以上信息,即ssh nardack时输入一次密码(当然,如果需要本地无密码登录,需要运行ssh-copy-id命令将ssh拷贝到nardack@192.168.79.130),而ssh krenz则不需要密码直连,说明ssh别名已经配置完毕。
Spark-submit 命令参数说明(在步骤六完成后可选):
bin/spark-submit \\
--class <main-class>
--master <master-url> \\
... # other options
<application-jar> \\
[application-arguments]
| 参数 | 解释 | 可选值举例 |
|---|---|---|
| –class | Spark 程序中包含主函数的类 | ------- |
| –master | Spark 程序运行的模式(环境) | local[*]、 spark://master:7077 |
| –executor-memory 1G | 指定每个 executor 可用内存为 1G | ------- |
| –total-executor-cores 2 | 指定所有 executor 使用的 cpu 核数为 2 个 | ------- |
| –executor-cores | 指定每个 executor 使用的 cpu 核数 | ------- |
| application-jar | 打包好的应用 jar,包含依赖。这个 URL 在集群中全局可见。 比如 hdfs:// 共享存储系统,如果是 file:// path,那么所有的节点的 | |
| path 都包含同样的 jar | ------- | |
| application-arguments | 传给 main()方法的参数 | ------- |
以上是关于BIT云计算实验Spark Local/Standalone模式搭建实验记录的主要内容,如果未能解决你的问题,请参考以下文章