Golang 入门总结:Go Module, for range, 切片, map, struct 等使用和实现
Posted 拭心
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Golang 入门总结:Go Module, for range, 切片, map, struct 等使用和实现相关的知识,希望对你有一定的参考价值。
文章目录
- Go 程序结构
- 项目结构
- Go Module 构建模式
- Go Module 的常规操作
- 入口函数与包初始化:搞清Go程序的执行次序
- 使用内置包实现一个简单的 Web 服务 【待学完回来敲】
- 变量声明
- 代码块与作用域
- 基本数据类型:数值类型
- 基本数据类型:字符串类型
- 常量
- 数组和切片
- map 使用及实现
- struct
- if 自用变量
- 循环的新花样和坑
- switch 和其他语言有点小区别
- 实践收获记录
- 学习资料
项目里使用 Go 开发后端,花了些时间系统的学习,这里做个总结。
本文内容整理自极客时间 《Go 语言第一课》的学习笔记及日常总结。
Go 程序结构
https://time.geekbang.org/column/article/428267
Go 的命名规则:
- Go 源文件总是用全小写字母形式的短小单词命名,并且以.go 扩展名结尾
- 如果要在源文件的名字中使用多个单词,我们通常直接是将多个单词连接起来作为源文件名,而不是使用其他分隔符,比如下划线。也就是说,我们通常使用 helloworld.go 作为文件名而不是 hello_world.go。
import “fmt”:
- "fmt”代表的是包的导入路径(Import),它表示的是标准库下的 fmt 目录,整个 import 声明语句的含义是导入标准库 fmt 目录下的包
- 通常导入路径的最后一个分段名与 使用的包名是相同的
package main:
- 包是 Go 语言的基本组成单元,一个 Go 程序本质上就是一组包的集合
- main 包在 Go 中是一个特殊的包,整个 Go 程序中仅允许存在一个名为 main 的包
func main:
- 运行一个可执行的 go 程序时,入口就是 main 函数
- 只有首字母为大写的函数才是导出的,才能被人调用;如果首字母是小写,则说明只在声明的包内可见
函数内部:
- 标准 Go 代码风格使用 Tab 而不是空格来实现缩进的
go build main.go
- Go 是一种编译型语言,这意味着只有你编译完 Go 程序之后,才可以将生成的可执行文件交付于其他人
- go生成的应用程序不依赖环境就可以运行(对方不需要安装 go 就可以运行)
- 开发阶段可以使用 go run main.go 直接运行
如果你交付给其他人的是一份.rb、.py 或.js 的动态语言的源文件,那么他们的目标环境中就必须要拥有对应的 Ruby、Python 或 javascript 实现才能解释执行这些源文件
Go module 构建模式:
- Go 1.11 版本正式引入的,为的是彻底解决 Go 项目复杂版本依赖的问题
- Go 默认的包依赖管理机制和 Go 源码构建机制
- 一个 module 就是一个包的集合,这些包和 module 一起打版本、发布和分发。go.mod 所在的目录被我们称为它声明的 module 的根目录
- go.mod 文件,存储这个 module 对第三方的依赖信息(一个 go.mod 文件代表一个包,一个项目可以有多个 go.mod)
- go mod init github.com/shixinzhang/hellomodule1: 生成一个 go.mod 文件
go mod tidy可以根据 .go 文件里的依赖,自动下载和添加依赖- go.sum 文件:记录直接/间接依赖库的 hash 值,在构建时会检查本地库版本和这个文件里的哈希值是否一致
- Go Module 本身就支持可再现构建,而无需使用 vendor。 当然 Go Module 机制也保留了 vendor 目录(通过 go mod vendor 可以生成 vendor 下的依赖包,通过 go build -mod=vendor 可以实现基于 vendor 的构建)
admin@C02ZL010LVCK hellomodule % go mod tidy
go: finding module for package go.uber.org/zap
go: finding module for package github.com/valyala/fasthttp
go: downloading github.com/valyala/fasthttp v1.34.0
go: found github.com/valyala/fasthttp in github.com/valyala/fasthttp v1.34.0
go: found go.uber.org/zap in go.uber.org/zap v1.21.0
go: downloading github.com/andybalholm/brotli v1.0.4
go: downloading github.com/klauspost/compress v1.15.0
admin@C02ZL010LVCK hellomodule % ls
go.mod go.sum main.go
admin@C02ZL010LVCK hellomodule % cat go.mod
module github.com/shixinzhang/hellomodule1
go 1.16
require (
github.com/valyala/fasthttp v1.34.0
go.uber.org/zap v1.21.0
)
admin@C02ZL010LVCK hellomodule %
项目结构
https://time.geekbang.org/column/article/429143
两种项目:
- 可执行程序
- 库项目
可执行程序
- go.mod go.sum 放在项目根目录
- cmd 目录:存放要构建的可执行文件对应的 main 包源码
- 其他代码按照不同包,放在对应的目录下
- internal 目录:存放内部使用,外部无法访问的 Go 包
通常来说,main 包应该很简洁。我们在 main 包中会做:命令行参数解析、资源初始化、日志设施初始化、数据库连接初始化等工作
之后就会将程序的执行权限交给更高级的执行控制对象
Reproducible Build:
可重现构建,就是针对同一份go module的源码进行构建,不同人,在不同机器(同一架构,比如都是x86-64),相同os上,在不同时间点都能得到相同的二进制文件。
库项目
可执行程序的简化版,去掉 cmd 和 vendor 目录就是了。
Go 库项目的初衷是为了对外部(开源或组织内部公开)暴露 API,对于仅限项目内部使用而不想暴露到外部的包,可以放在项目顶层的 internal 目录下面。
Go 项目结构没有绝对的标准:https://github.com/golang-standards/project-layout/issues/117#issuecomment-828503689
Go Module 构建模式
https://time.geekbang.org/column/article/429941
Go 程序构建过程:
- 确定包版本
- 编译包
- 将编译后的目标文件链接到一起
Go 语言的构建模式历经了三个迭代和演化过程:
- GOPATH:去本地环境变量目录下查找依赖的库
- Vendor:把依赖库的代码下载到 vendor 下,一起提交。查找依赖时,先从 vendor 目录查找
- Go Module: go.mod 及背后的机制
GOPATH:
可以通过 go get 命令将本地缺失的第三方依赖包(还有它的依赖)下载到本地 GOPATH 环境变量配置的路径。
先找 $GOROOT 然后找 $GOPATH
在没有 go module 机制前,go get 下载的是当时最新的。如果别人在不同时间去执行,可能和你下载的库版本不一致。
go env GOPATH查看本地环境变量
vendor:
要想开启 vendor 机制,你的 Go 项目必须位于 GOPATH 环境变量配置的某个路径的 src 目录下面。如果不满足这一路径要求,那么 Go 编译器是不会理会 Go 项目目录下的 vendor 目录的。
Go Module:
go.mod 文件将当前项目变为了一个 Go Module,项目根目录变成了 module 根目录
- go mod init: 创建 go.mod 文件,将一个 Go 项目转变为一个 Go Module
- go mod tidy:扫描 Go 源码,并自动找出项目依赖的外部 Go Module 以及版本,下载这些依赖并更新依赖信息到 go.mod 文件中,生成校验和文件
- go build 执行构建:读取 go.mod 中的依赖及版本信息,并在本地 module 缓存路径下找到对应版本的依赖 module,执行编译和链接
相关环境变量:
- GOPROXY:下载的代理服务
- GOMODCACHE:下载到哪里
admin@C02ZL010LVCK ~ % go env GOPROXY
https://proxy.golang.org,direct
admin@C02ZL010LVCK ~ % go env GOMODCACHE
/Users/simon/go/pkg/mod
语义导入版本
- v1.2.1,主版本号(major)、次版本号(minor)、补丁版本号(patch)
- 默认主版本号不同时,不兼容;次版本号和补丁版本号提升后,向前兼容
- 如果主版本号升级,需要在导入路径里增加版本号:
import "github.com/sirupsen/logrus/v2",这样 Go Module 机制就会去 v2 路径下查找库
Go 的“语义导入版本”机制:通过在包导入路径中引入主版本号的方式,来区别同一个包的不兼容版本,这样一来我们甚至可以同时依赖一个包的两个不兼容版本。
最小版本选择原则
A 和 B 有一个共同的依赖包 C,但 A 依赖 C 的 v1.1.0 版本,而 B 依赖的是 C 的 v1.3.0 版本,并且此时 C 包的最新发布版为 C v1.7.0
Go 命令会选择 v1.3.0,兼容 2 个库的最小版本,而不会擅自选择最新版本
最小版本选择更容易实现可重现构建。
试想一下,如果选择的是最大最新版本,那么针对同一份代码,其依赖包的最新最大版本在不同时刻可能是不同的,那么在不同时刻的构建,产生的最终文件就是不同的。
可以通过 GO111MODULE 环境变量进行构建模式的切换。
但要注意,从 Go 1.11 到 Go 1.16,不同版本在 GO111MODULE 配置不同时,使用的构建模式不一样。
Go Module 的常规操作
https://time.geekbang.org/column/article/431463
空导入:
import _ "foo"- 空导入只是引入这个包,常见于引入mysql驱动,但是却不使用这个包中暴露的方法,有些包是依赖驱动实现的
- 空导入意味着期望依赖包的init函数得到执行,这个init函数中有我们需要的逻辑。
go 私有仓库:
私有代理做的比较好的有goproxy.io、goproxy.cn、athen等
1.添加依赖
- 代码里加上 import 语句
- 执行 go get,会下载并更新 go.mod
- go mod tidy 也能达到类似的效果,但比 go get 更好,尤其在复杂项目里
对于复杂的项目变更而言,逐一手工添加依赖项显然很没有效率,go mod tidy 是更佳的选择
imported and not used: “github.com/google/uuid”
go mod tidy 有点类似 pip install -r requirements.txt
2.升级/降级依赖
go list -m -versions github.com/gin-gonic/gin 查看某个库的所有版本号
升级、降级,也是使用 go get 和 go mod tidy,区别在于参数
go get 库名@版本号:go get github.com/gin-gonic/gin@v1.7.7 会下载指定的版本,同时更新 go.mod 里的配置版本号
go mod:
- 先用 go mod edit 修改版本号: go mod edit -require=库名@版本号:
go mod edit -require=github.com/gin-gonic/gin@v1.7.0 - 然后执行
go mod tidy
3.添加一个主版本号大于 1 的依赖
之所以主版本号大于 1 特殊,是因为一般来说主版本号不同,是大升级,不向前兼容。
如果新版本号和之前的不兼容,就不能使用默认的库名方式导入,而需要在库名后,加上版本号:
import github.com/user/repo/v2/xxx
然后再执行 go get 什么的,就和之前的一样了。
4.删除依赖
删除这个库的导入语句后,执行 go mod tidy 就可以了,真不愧它的名称,处理的干干净净。
go mod tidy 会自动分析源码依赖,而且将不再使用的依赖从 go.mod 和 go.sum 中移除
5.vendor 相关
执行 go mod vendor 会创建一个 vendor 目录,然后把依赖的库的代码都复制一份到这里。其中的 modules.txt 文件也会记录下库的版本号。
如果要基于 vendor 构建,而不是基于本地缓存的 Go Module 构建,需要在 go build 后面加上 -mod=vendor 参数。
高版本(1.14 以后),如果有 vendor 目录,go build 会优先从 vendor 查找依赖。
入口函数与包初始化:搞清Go程序的执行次序
https://time.geekbang.org/column/article/432021
Go 应用的入口函数:main 包中的 main 函数
如果要在 main.main 函数之前执行一些工作,可以定义一个 init 函数,在其中进行。
每个 Go 包可以拥有不止一个 init 函数,每个组成 Go 包的 Go 源文件中,也可以定义多个 init 函数
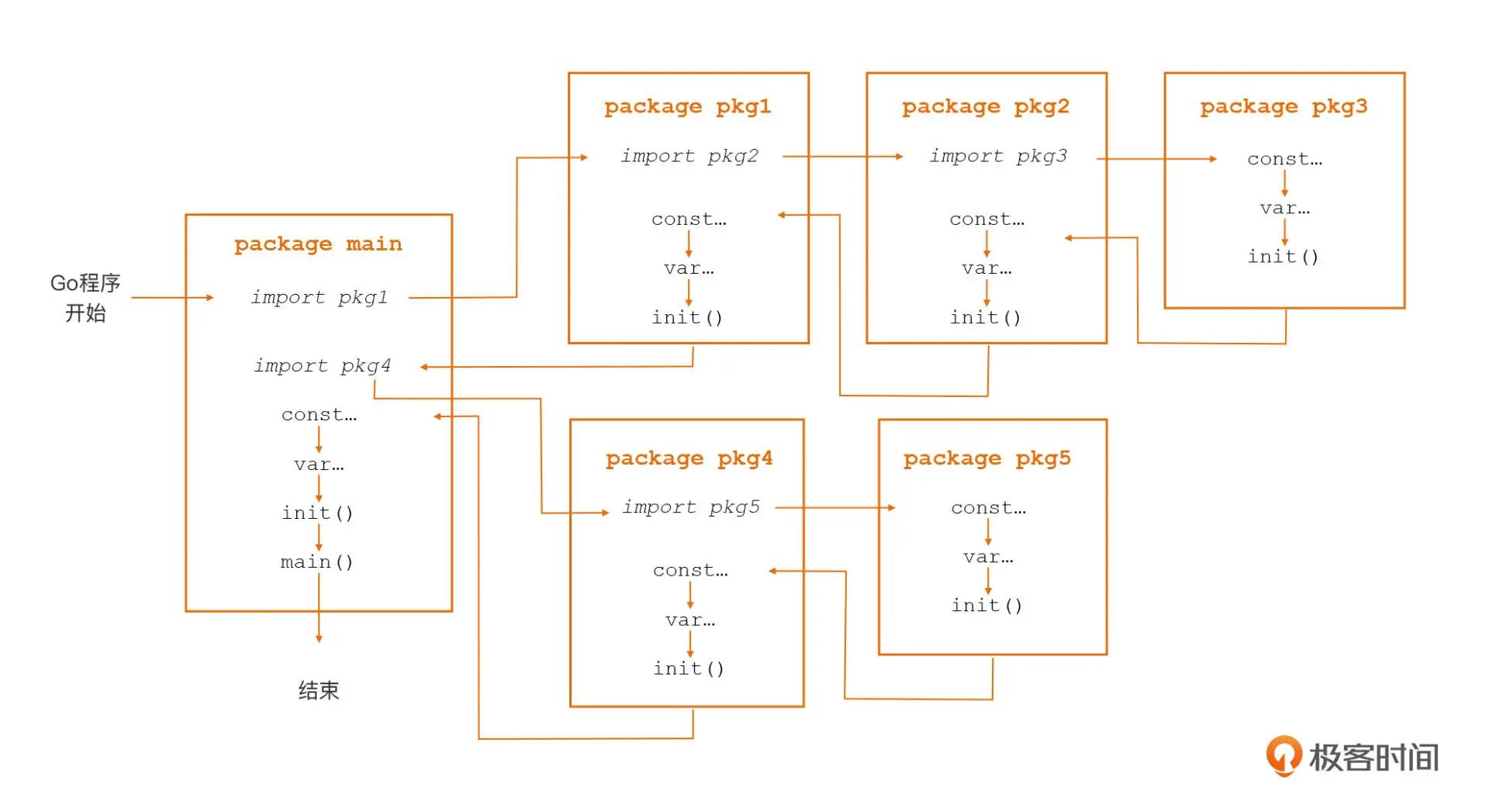
Go 包是程序逻辑封装的基本单元,每个包都可以理解为是一个“自治”的、封装良好的、对外部暴露有限接口的基本单元
程序的初始化就是这些包的初始化。
初始化顺序:
- 按照导入顺序,递归初始化依赖的所有包(以及他们依赖的包)的内容
- 某个包的初始化顺序:常量 -> 变量 -> init 函数
- 如果是 main 包的话,然后执行 main 函数
多个包依赖的包仅会初始化一次
init 函数的用途
对包级变量的初始化状态进行检查和修改,比如有些必须设置的参数,调用方没设置或者设置的有问题,可以在这里兜底。
每个 init 函数在整个 Go 程序生命周期内仅会被执行一次。
还可以根据配置(比如环境变量),修改变量的值,比如 url 等,挺实用的。
还有一个非常常见的应用场景:结合空导入,实现一些解耦性很强的设计。
比如访问数据库,一般会空导入一个具体的驱动实现(mysql 或者 postgres),在这个调用的文件初始化时,会执行到驱动实现的文件初始化,从而执行它的 init 方法,向 sql 库中注入一个具体的驱动实现。
import (
"database/sql"
_ "github.com/go-sql-driver/mysql" //空导入
)
db, err = sql.Open("mysql", "root:password@tcp(127.0.0.1:3306)/todo")
//mysql 的 driver.go
func init()
sql.Register("mysql", &MySQLDriver)
从标准库 database/sql 包的角度来看,这种“注册模式”实质是一种工厂设计模式的实现,sql.Open 函数就是这个模式中的工厂方法,它根据外部传入的驱动名称“生产”出不同类别的数据库实例句柄
使用内置包实现一个简单的 Web 服务 【待学完回来敲】
https://time.geekbang.org/column/article/434017
变量声明
https://time.geekbang.org/column/article/435858


静态语言声明的意义在于告诉编译器该变量可以操作的内存的边界信息(几个字节)。
不同类型的零值:
- 整数类型:0
- 浮点类型:0.0
- 字符串类型:“”
- 指针、接口、切片、channel、map、函数:nil
package test
import "fmt"
//包级变量
var Age int
var (
name string = "shixinzhang"
address = "Shanghai" //省略类型
a, b, c = 1, 2.1, 'c' //一行声明多个,省略类型
)
func TestVariable()
var height int = 128
var h = int32(128) //显式类型转换 等同于下面这个
var h32 int32 = 128
var a, b, c int = 1,2,3 //一行声明多个变量,类型其实可以推导出来,逗号不能少!
weight := 140 //短变量声明,省略 var 和类型
d, e, f := 4,5, "hi" //短变量也可以声明多个,不同类型也可以
fmt.Println("height ", height, h, h32, weight, a,b,c, d,e,f)
声明方式:
- 通用变量声明
- 短变量声明
通用变量声明:
var a int = 10
变量名在类型的前面,和 typescript 一样。
之所以这样,原因简单来:和C相比,在当参数是指针的复杂情况下,这种声明格式会相对好理解一点。
声明的时候也可以不赋值,会有默认值,称为零值
**变量声明块:**用一个 var 关键字,包括多个变量声明:
var (
name string = "shixinzhang"
address = "Shanghai" //省略类型
a, b, c = 1, 2.1, 'c' //一行声明多个,省略类型
)
短变量声明
短变量声明(:=):省去 var 关键字和类型信息
a := 12
a, b, c := 12, 'B', "CC"
变量类型会由编译器自动推导出来。
Go 中的变量类型:
- 包级变量、导出(首字母大写的包级变量)变量
- 局部变量
包级变量的声明形式
1.声明的同时直接初始化
var ErrShortWrite = errors.New("short write")
2.先声明,稍后初始化
声明聚类:把延迟初始化和直接显式初始化的变量放到不同的声明块中。
可以提升代码可读性。
就近原则: 变量尽可能地声明在使用处附近
局部变量的声明形式
1.声明时直接初始化
使用短变量声明。
短变量声明是局部变量使用最多的声明方式。
age := 28
name := "shixinzhang"
复杂类型不支持获取默认类型,需要在等号右侧增加显式转型:
s := []byte("hello shixinzhang")
2.先声明,稍后初始化
因为没有初始化值,所以需要声明类型。使用通用变量声明:
先 var a number,然后赋值。
如果有多个局部变量需要声明,也可以考虑使用 var 声明块完成。
func test()
var
age int
name string
代码块与作用域
https://time.geekbang.org/column/article/436915
作用域:
- 变量仅在某一范围内有效。
- 在这个范围内,如果声明和更大层级同名的变量,会重新创建一个,而不是使用全局的变量。如果进行赋值,修改的也是当前范围的 (变量遮蔽)
- 退出这个代码块后,变量不再可访问。
显式代码块:使用 包围起来的代码。
隐式代码块:
- 全局/宇宙级代码块
- 包级代码块
- 文件级代码块
- 函数级代码块
- 控制逻辑级代码块
作用域最大的 Go 语言预定义标识符:

同一个 package 中的不同文件,不能有同名的包级变量! 假如在同一个包中的文件 A 定义了全局变量 a,那在这个包里的其他文件,都不能再定义全局变量 a。
导入其他包时,仅可使用其他包的导出标识符,导出标识符具有包代码块级作用域。
导出标识符:
- 声明在包代码块中(包中的全局变量或方法)
- 首字母大写
导入的包名的作用域是文件代码块
控制逻辑级代码的作用域:
- if 条件里创建的,在 else 里也可以访问
- switch 条件里创建的,在 case 结束后无法访问
func bar()
if a := 1; false
else if b := 2; false
else if c := 3; false //在 if 条件里创建的临时变量,在 else 里也可以访问
else
println(a, b, c)
//在 if 条件里创建的临时变量,在 else 里也可以访问
//因为这个创建等价于这样:
c := 3 // 变量c作用域始于此
if false
else
println(a, b, c)
// 变量c的作用域终止于此
注意⚠️:短变量声明与控制语句的结合十分容易导致变量遮蔽问题,并且很不容易识别!
变量遮蔽如何解决:
- 可以借助 go vet 进行变量遮蔽检查
- 约定命名规则,避免重复
go vet 下载及使用:
- 下载 go vet:
go install golang.org/x/tools/go/analysis/passes/shadow/cmd/shadow@latest需要梯子 - 执行:
go vet -vettool=$(which shadow) -strict test/variable.go
-strict 指定要检测的文件,执行结果:
# command-line-arguments
test/variable.go:18:6: declaration of "a" shadows declaration at line 10
约定好包级别的变量用长的名字,越是局部的变量用越短小的名字,应该能够解决一大部分变量遮蔽的问题。
基本数据类型:数值类型
https://time.geekbang.org/column/article/439782
Go 中的类型:
- 基本数据类型
- 复合数据类型
- 接口类型
基本数据类型:整型、浮点型、复数类型
整型
整型分平台无关和平台相关两种(和 C/C++ 类似)。
区别在于:在不同的 CPU 架构和操作系统下,长度是否一致
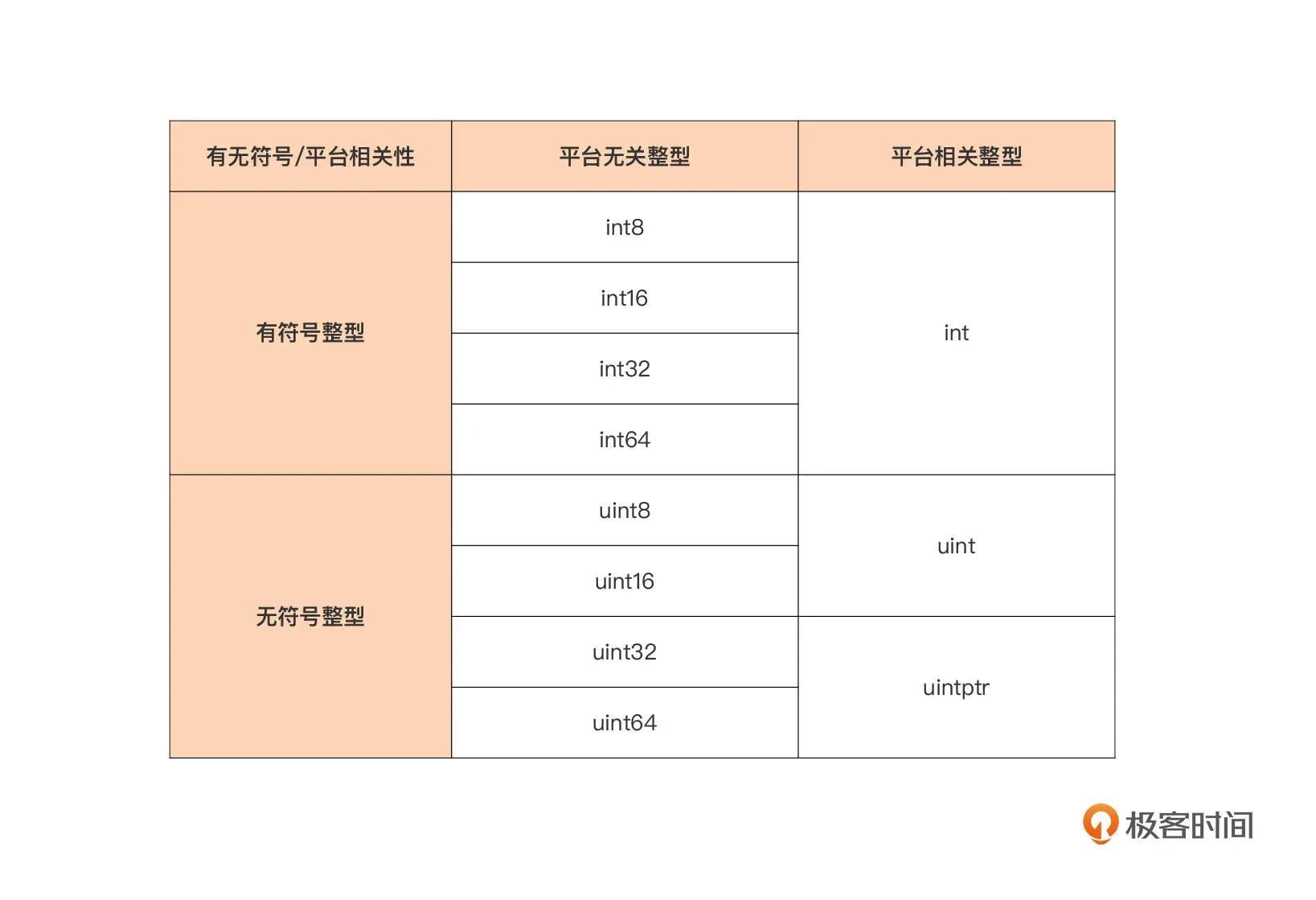
平台无关整形分为两种,区别在于二进制首位是表示数还是符号位:
- 有符号
- 无符号
符号位就是表示正负符号
Go 的整型比特位编码:2 的补码方式(按位取反再 + 1)
所以有符号的二进制数 10000001 的整数值就是负的 01111110 + 1 = -127
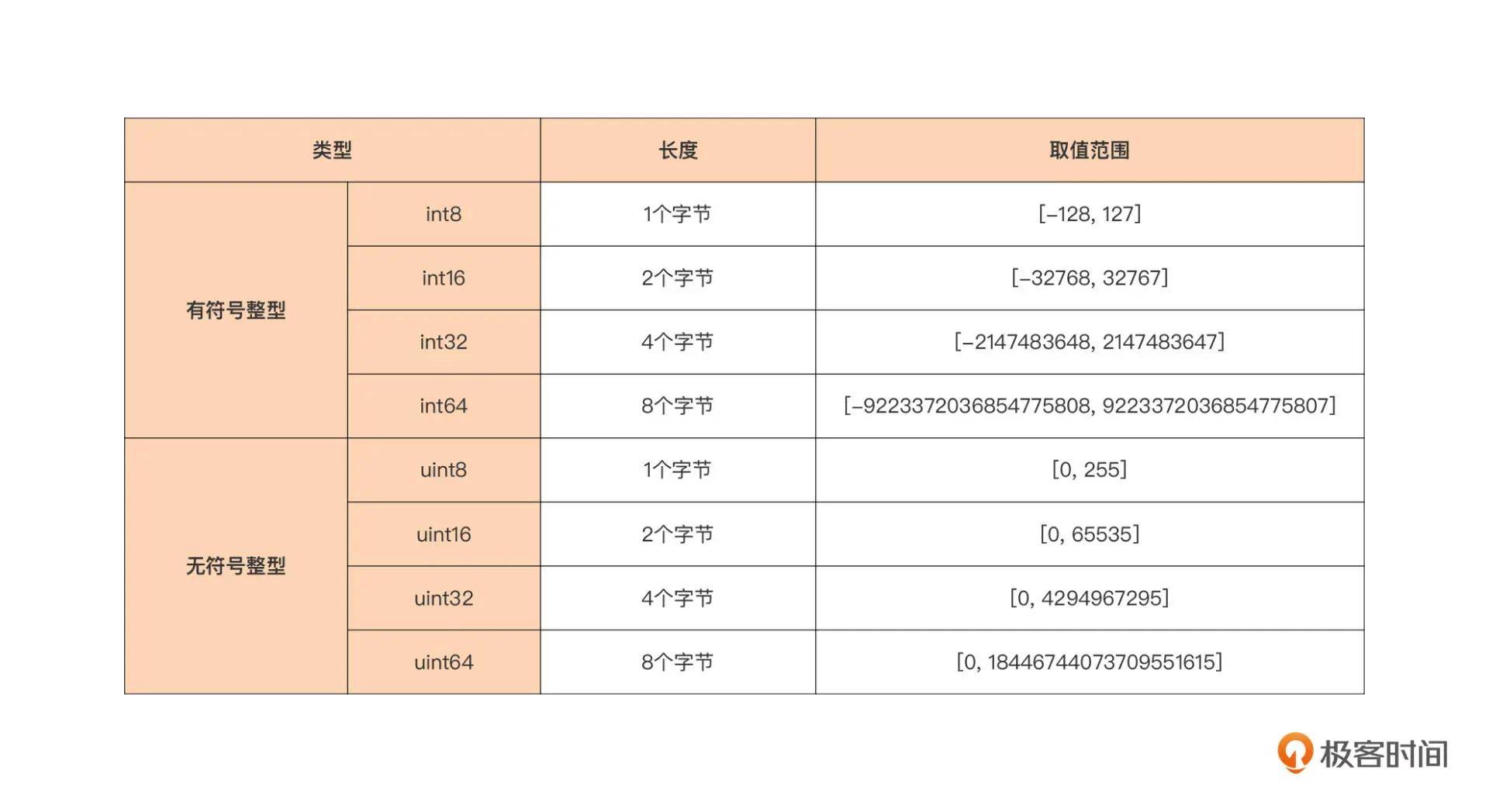
平台相关整形貌似就 3 个:
- int: 32 位 4 字节,64 位 8 字节
- uint:32 位 4,64 位 8
- uintptr

在编写可移植性程序时,不要使用平台相关!
unsafe.Sizeof(a) 可以查看变量的长度。
整型溢出
在使用名称带数字的整型时,要注意它的长度范围,避免溢出。
func TestVariable()
ss := int32(12)
int8_a := int8(127)
int8_a += 1 //溢出!
uint8_b := uint8(1)
uint8_b -= 2 //溢出!
fmt.Println("sizeof int:", unsafe.Sizeof(a))
fmt.Println("sizeof int8:", unsafe.Sizeof(int8_a), int8_a)
fmt.Println("sizeof uint8:", unsafe.Sizeof(uint8_b), uint8_b)
fmt.Println("sizeof int32:", unsafe.Sizeof(ss))
比如上面使用了 int8 和 uint8,从名字我们知道它只有 8 个字节,1 byte,所以表示范围为 [-128, 127],在使用时如果不小心超出这个范围,就会得到预期外的结果:
sizeof int: 8
sizeof int8: 1 -128
sizeof uint8: 1 255
sizeof int32: 4
以不同进制格式化打印:
Printf:
func TestDiffFormatPrint()
value := 127
value8 := 010
value16 := 0x10
fmt.Printf("value8 十进制:%d \\n", value8)
fmt.Printf("value16 十进制:%d \\n", value16)
fmt.Printf("十进制:%d \\n", value)
fmt.Printf("二进制:%b \\n ", value)
fmt.Printf("八进制:%o \\n", value)
fmt.Printf("八进制带前缀:%O \\n", value)
fmt.Printf("十六进制:%x \\n ", value)
fmt.Printf("十六进制带前缀:%X \\n", value)
输出:
value8 十进制:8
value16 十进制:16
十进制:127
二进制:1111111
八进制:177
八进制带前缀:0o177
十六进制:7f
十六进制带前缀:7F
浮点数
和整型相比,浮点类型在二进制表示和使用方面都更复杂!
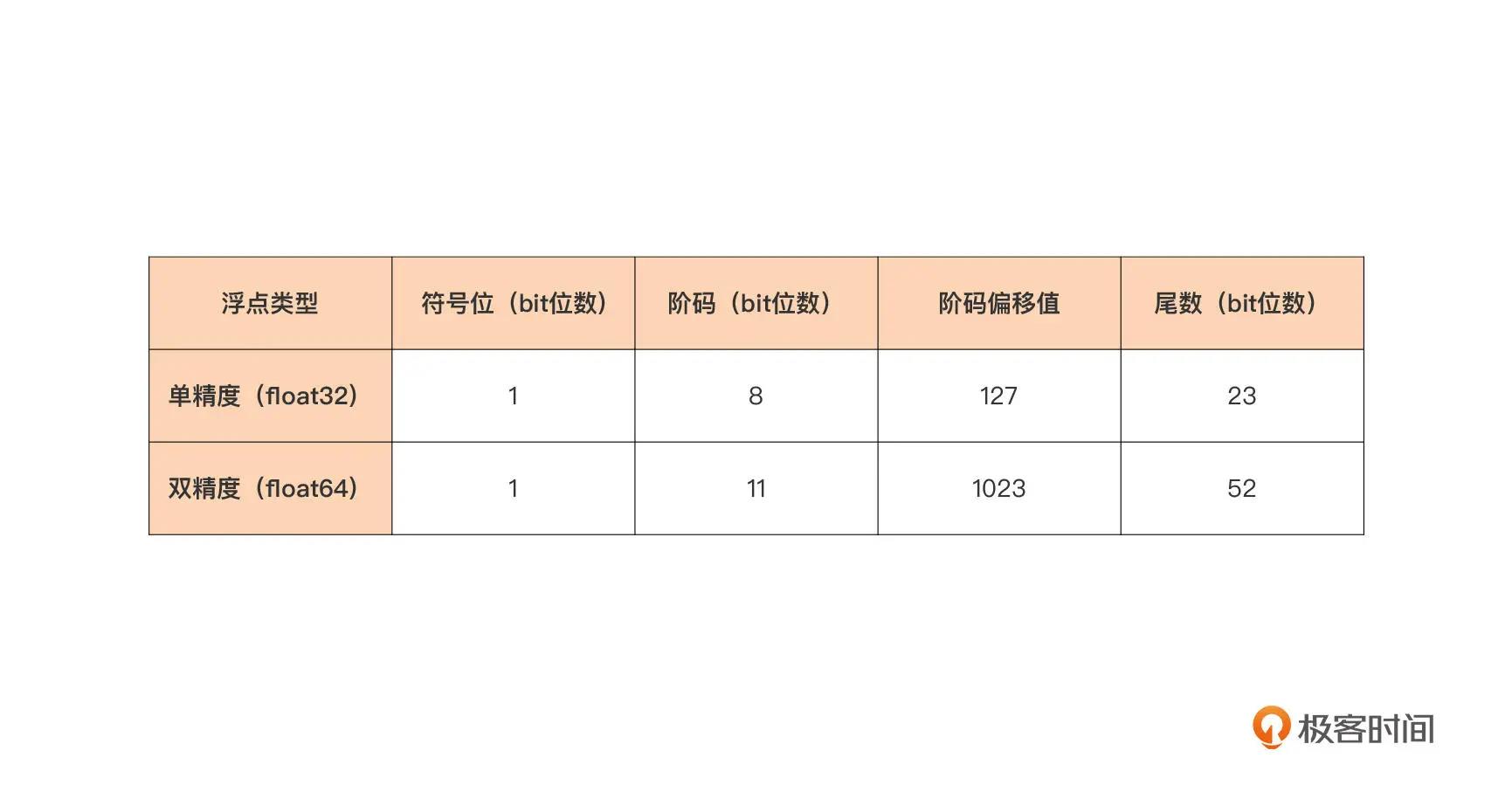
Go 语言提供了 float32 与 float64 两种浮点类型,它们分别对应的就是 IEEE 754 中的单精度与双精度浮点数值类型。
Go 浮点类型与平台无关。

浮点数的二进制表示:
- 符号位
- 阶码
- 尾数
阶码和尾数的长度决定了浮点类型可以表示的浮点数范围与精度。
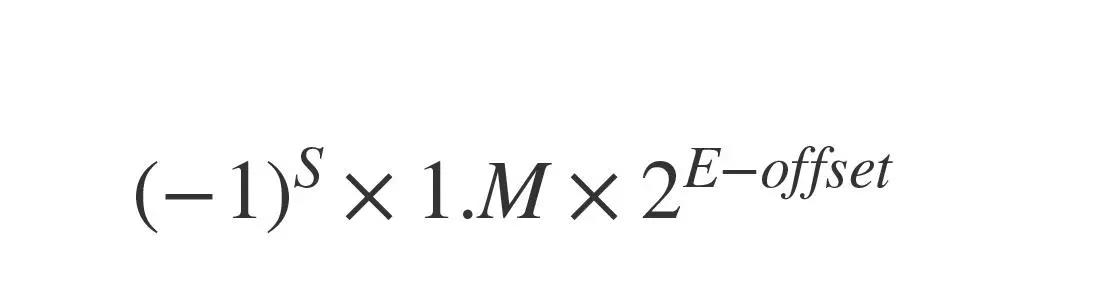
【浮点数十进制转二进制的规则待仔细整理】
日常使用中尽量使用 float64,这样不容易出现浮点溢出的问题
func TestFloatNumber()
value := float64(1.2)
fmt.Println("value: %d", value)
var fl1 float32 = 16777216.0
var fl2 float32 = 16777217.0
fmt.Println("16777216.0 == 16777217.0? ", fl1 == fl2);
bits := math.Float32bits(fl1)
bits_fl2 := math.Float32bits(fl2)
fmt.Printf("fl1 bits:%b \\n", bits)
fmt.Printf("fl2 bits:%b \\n", bits_fl2)
value3 := 6456.43e-2 //e-2 = 10^-2
value4 := .12345e4 //10^4
fmt.Printf("6456.43e-2 %f, .12345e4:%0.2f \\n", value3, value4)
//输出为科学计数法的形式
fmt.Printf("%e \\n", 6543.21) //十进制的科学计数法
fmt.Printf("%x \\n", 6543.21) //十六进制的科学计数法 //p/P 代表的幂运算的底数为 2
输出:
value: %d 1.2
16777216.0 == 16777217.0? true
fl1 bits:1001011100000000000000000000000
fl2 bits:1001011100000000000000000000000
6456.43e-2 64.564300, .12345e4:1234.50
6.543210e+03
0x1.98f35c28f5c29p+12
float32 类型的 16777216.0 与 16777217.0 相等,是因为他们的二进制数一样。因为 float32 的尾数只有 23bit。
复数类型
复数:z=a+bi,a 为实部,b 为虚部。
复数主要用于矢量计算等场景。
Go 中实部和虚部都是浮点类型。
Go 复数有两种类型:complex128 和 complex64,complex128 是默认类型。
func TestComplex()
//声明一个复数
c := 5 + 6i
fmt.Println(reflect.TypeOf(c))
//real 获取复数实部
//imag 获取复数虚部
fmt.Printf("实部: %f, 虚部: %f \\n", real(c), imag(c))
var _complex = complex(7.7, 8.8)
fmt.Printf("实部: %f, 虚部: %f \\n", real(_complex), imag(_complex))
运行结果:
complex128
实部: 5.000000, 虚部: 6.000000
实部: 7.700000, 虚部: 8.800000
类型别名
Go 也支持类似 C/C++ 那样的 typedef,有两种方式:
type MyInt int32 //类型定义
type MyInt = int32 //类型别名
- 第一种不加等号的,是等于新创建一个类型,这种类型和 int32 不能直接赋值,需要做强转。
- 第二种加等号的,就是一个别名,类型和 int32 一致,可以赋值。
type MyInt int32
type MyIntAlias = int32
func TestTypeDef()
age := int32(29)
height := MyInt(199)
weight := MyIntAlias(150)
//cannot use height (type MyInt) as type int32 in assignment
age = height //编译器报错:Cannot use 'height' (type MyInt) as type int32
age = weight //不报错
基本数据类型:字符串类型
https://time.geekbang.org/column/article/440804
- 对比
- 原理
- 实操
- 背后的设计以及常用方法
C 语言没有提供字符串类型的原生支持,是以’\\0’结尾的字符数组方式实现的。存在的问题:
- 字符串操作时要时刻考虑结尾的’\\0’,防止缓冲区溢出;
- 以字符数组形式定义的“字符串”,它的值是可变的,在并发场景中需要考虑同步问题
- 获取一个字符串的长度代价较大,
strlen通常是 O(n) 时间复杂度 - C 语言没有内置对非 ASCII 字符(如中文字符)的支持
Go 中 string 的特性:
- 字符不可变:
- 只可以整体修改,不能单独修改其中某个字符。保证了多线程访问的安全性。
- 一个 value,在内存中只有一份
- 结尾不需要 ‘\\0’,获取长度效率也很高
- 支持 raw string,由一对 `` 包围即可
- 默认使用 Unicode 字符集,支持中文
举个例子:
- 按字节输出一个字符串值
- 使用 Go 在标准库中提供的 UTF-8 包,对 Unicode 字符(rune)进行编解码
func TestString()
location := "中国人"
//1.按字节输出
fmt.Printf("the length of location is:%d\\n", len(location)) //len: 字节大小
for i:= 0; i < len(location); i++
fmt.Printf("0x%x,", location[i])
fmt.Print("\\n")
//2.按字符输出
fmt.Println("the length of rune/character:", utf8.RuneCountInString(location))
for _, c := range location
fmt.Printf("%c | 0x%x , ", c, c)
fmt.Print("\\n")
运行结果:
the length of location is:9
0xe4,0xb8,0xad,0xe5,0x9b,0xbd,0xe4,0xba,0xba,
the length of rune/character: 3
中 | 0x4e2d , 国 | 0x56fd , 人 | 0x4eba ,
len 函数的作用:
// The len built-in function returns the length of v, according to its type:
// Array: the number of elements in v.
// Pointer to array: the number of elements in *v (even if v is nil).
// Slice, or map: the number of elements in v; if v is nil, len(v) is zero.
// String: the number of bytes in v.
// Channel: the number of elements queued (unread) in the channel buffer;
// if v is nil, len(v) is zero.
// For some arguments, such as a string literal or a simple array expression, the
// result can be a constant. See the Go language specification's "Length and
// capacity" section for details.
func len(v Type) int
rune
Go 使用 rune 类型来表示一个 Unicode 字符的码点。为了传输和存储 Unicode 字符,Go 还使用了 UTF-8 编码方案,UTF-8 编码方案使用变长字节的编码方式,码点小的字符用较少的字节编码,码点大的字符用较多字节编码,这种编码方式兼容 ASCII 字符集,并且拥有很高的空间利用率。
Go rune 的概念和 Java 的 char 类似,字符字面值,Unicode 字符的编码,本质是一个整数
// $GOROOT/src/builtin.go
type rune = int32
- Unicode字符集中的中文字符:‘a’, ‘中’
- Unicode :字符\\u 或\\U 作为前缀: ‘\\u4e2d’(字符:中), ‘\\U00004e2d’(字符:中)
UTF-8 编码方案已经成为 Unicode 字符编码方案的事实标准,各个平台、浏览器等默认均使用 UTF-8 编码方案对 Unicode 字符进行编、解码。
UTF-8(Go 语言之父 RobPike 和其他人联合创造)的特点:
- 使用变长字节表示,1~4 个字节不等,空间利用率高
- 兼容 ASCII 字符
为什么 UTF-8 没有字节序问题?
字节序问题:超出一个字节的数据如何存储的问题。是使用大端还是小端,从哪头开始读取合适。
因为UTF-8的头已经标出来了,所以不存在顺序出问题的情况。
UTF-8 是变长编码,其编码单元是单个字节,不存在谁在高位、谁在低位的问题。而 UTF-16 的编码单元是双字节,utf-32编码单元为4字节,均需要考虑字节序问题。
UTF-8 通过字节的形式就能确定传输的是多少字节的字符编码(如果是超过一个字节表示,会在首字节的前几位用特殊值表示)
测试一下 rune 转字节数组和字节数组转 rune:
func TestRune()
//定义一个字符
var r rune = 0x4E2D
fmt.Printf("The unicode character is: %c", r)
fmt.Print("\\n")
//encode
p := make([]byte, 3) //创建一个数组
_ = utf8.EncodeRune(p, r) //编码为二进制
fmt.Printf("encode result: 0x%X", p)
fmt.Print("\\n")
//decode 0xE4B8AD
buf := []byte 0xE4, 0xB8, 0xAD
r2, size := utf8.DecodeRune(buf)
fmt.Printf("decode result: %c, size:%d", r2, size)
fmt.Print("\\n")
运行结果:
The unicode character is: 中
encode result: 0xE4B8AD
decode result: 中, size:3
Go 字符串类型的内部表示
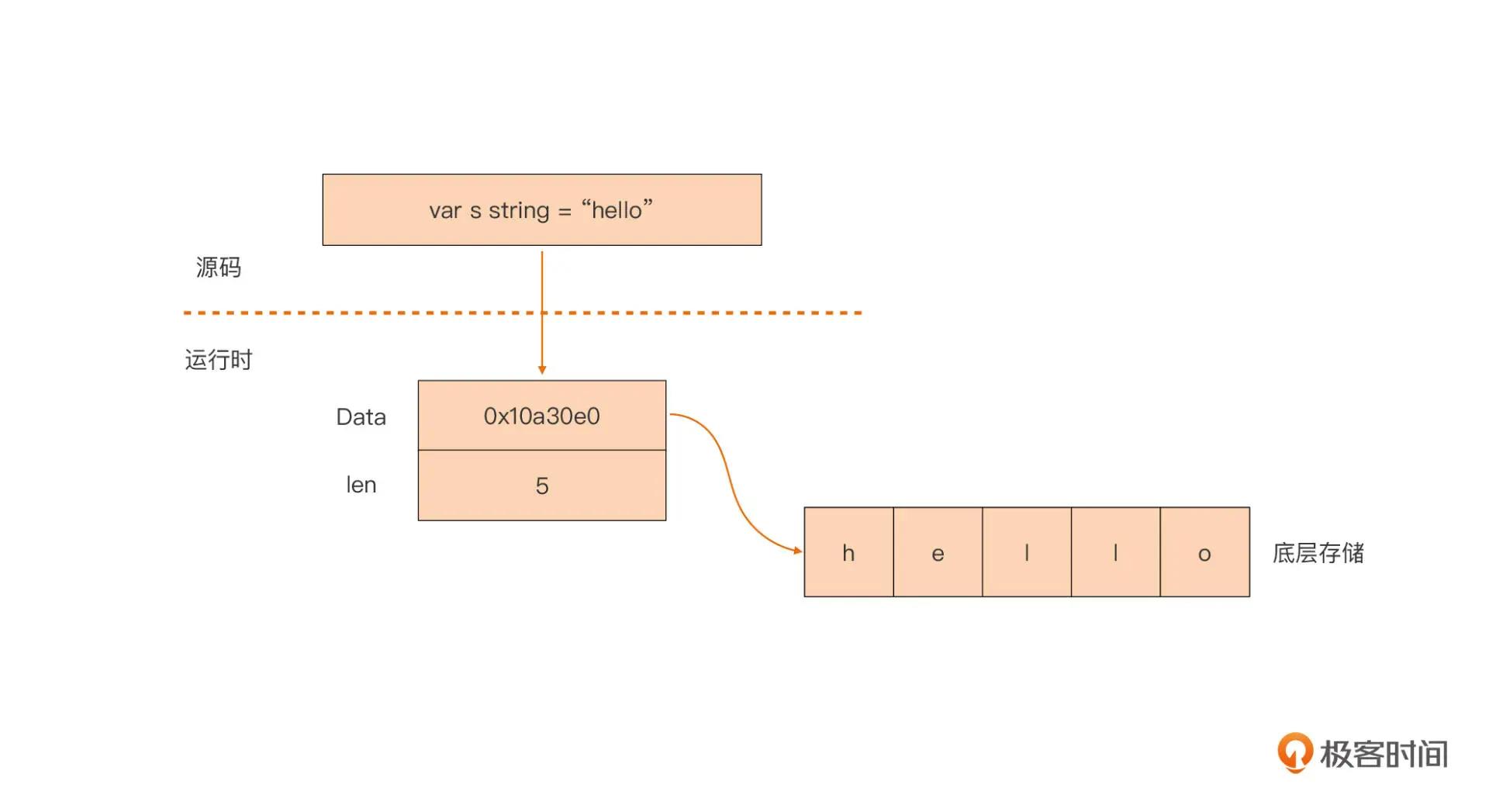
Go string 运行时,仅仅是一个指针和长度,并不保存真实的数据:
// StringHeader is the runtime representation of a string.
// It cannot be used safely or portably and its representation may
// change in a later release.
// Moreover, the Data field is not sufficient to guarantee the data
// it references will not be garbage collected, so programs must keep
// a separate, correctly typed pointer to the underlying data.
type StringHeader struct
Data uintptr
Len int
指向数据的指针和一个长度值。
举个例子:
func TestDumpBytes()
s := "hello"
//1.获取这个字符串的地址,转换为一个 StringHeader
header := (*reflect.StringHeader)(unsafe.Pointer(&s))
fmt.Printf("0x%X\\n", header.Data); //输出底层数组的地址
//2.通过 StringHeader 的数据指针获取到真实的字符串数据
originString := (*[5]byte)(unsafe.Pointer(header.Data)) //StringHeader.Data 就是一个指针
fmt.Printf("originString :%s\\n", *originString) //通过 * 获取指针指向的内容
//3.遍历每个字符,打印
for _, c := range *originString
fmt.Printf("%c_", c)
fmt.Print("\\n")
上面的代码中,我们通过 unsafe.Pointer 读取了字符串的底层实现,然后通过 String.Header 的结构体里的数据,实现了字符串的打印。
输出信息:
0x10C9622
originString :hello
h_e_l_l_o_
字符串操作
- 通过下标读取,结果是字节(而不是字符)
- 字符迭代(for 迭代和 for range 迭代,得到的结果分别是:字节、字符)
- 字符串拼接(+/+=, strings.Builder, strings.Join, fmt.Sprintf)
- 字符串比较(==, !=, >=, <=)
- 字符串转换(string/byte[]/rune[])
字符串拼接性能对比
- +/+=是将两个字符串连接后分配一个新的空间,当连接字符串的数量少时,两者没有什么区别,但是当连接字符串多时,Builder的效率要比+/+=的效率高很多。
- 因为 string.Builder 是先将第一个字符串的地址取出来,然后将builder的字符串拼接到后面,
常量
https://time.geekbang.org/column/article/442791
Go 常量的创新:
- 无类型常量:声明时不赋予类型的常量
- 隐式自动转型:根据上下文把无类型常量转为对应类型
- 可用于实现枚举
使用 const 关键字,也支持类似 var 那样的代码块,声明多个常量。
无类型常量与常量隐式转型的组合,使得在 Go 在混合数据类型运算的时候具有比较大的灵活性,代码编写也得到简化。
Go 没有提供枚举类型,可以使用 const 代码块 + iota 实现枚举:
- iota:行偏移量指示器,表示当前代码块的行号,从 0 开始
- const 代码块里,如果没有显式初始化,就会复制上一行,但因为行号不一样,所以就实现了增加
每个 const 代码块都拥有属于自己的 iota。同一行即使出现多次,多个 iota 的值都一样
const (
_ = iota
APPLE
WATERMELON
_
BINANA = iota + 1000
_
ORANGE
)
func TestConstValue()
fmt.Printf("test enum %d \\n", APPLE)
fmt.Printf("test enum %d \\n", WATERMELON)
fmt.Printf("test enum %d \\n", BINANA)
fmt.Printf("test enum %d \\n", ORANGE)
输出:
test enum 1
test enum 2
test enum 1004
test enum 1006
注意⚠️:要定义大量常量时,建议不要使用 iota,否则不清楚值到底是多少!
数组和切片
https://time.geekbang.org/column/article/444348
数组
//参数的类型,如果是数组,个数也必须一致
func printArray(a [5]int)
fmt.Printf("length of arr: %d \\n", len(a)) //元素个数
fmt.Printf("size of arr: %d \\n", unsafe.Sizeof(a)) //所有元素占用的字节数
for i := 0; i < len(a); i++
fmt.Printf("index: %d , value: %d, addr: 0x%x \\n", i, a[i], &a[i]) //也可以取地址
func (Array) test()
var arr [5]int
printArray(arr)
arr[0] = 1
//var arr2 []int //不声明默认长度为 0
//printArray(arr2) //编译报错:Cannot use 'arr' (type [5]int) as type []int
//var arr3 = [5]int 1,2,3,4,5 //直接初始化,类型在等号右边,花括号包围初始值
//var arr3 = [...]int 1,2,3,4,5 //也可以省略长度,编译时推导
var arr3 = [5]int 2: 3 //也可以指定下标赋值,只设置某个值
printArray(arr3)
输出:
length of arr: 5
size of arr: 40
index: 0 , value: 0, addr: 0xc00001e2d0
index: 1 , value: 0, addr: 0xc00001e2d8
index: 2 , value: 0, addr: 0xc00001e2e0
index: 3 , value: 0, addr: 0xc00001e2e8
index: 4 , value: 0, addr: 0xc00001e2f0
从上面的例子可以看出:
- Go 中,数组等价要求类型和长度一致,如果不一致,无法传递、赋值。
- 直接初始化:类型写在等号右边,花括号包围初始值;可以省略长度,编译时推导;也可以指定下标赋值,只设置某个值
- 数组声明时不赋值,会初始化元素为零值
- item 的地址是连续的
在 Java 中类型校验这么严格,数组参数只要类型一致即可。
数组的特点:元素个数固定;作为参数传递时会完全拷贝一次,内存占用大。
切片
声明时不指定大小,append 添加元素,动态扩容
Go 编译器会为每个新创建的切片创建一个数组,然后让切片指向它。
切片的实现:
//go/src/runtime/slice.go
type slice struct
array unsafe.Pointer //指向底层数组的指针
len int
cap int
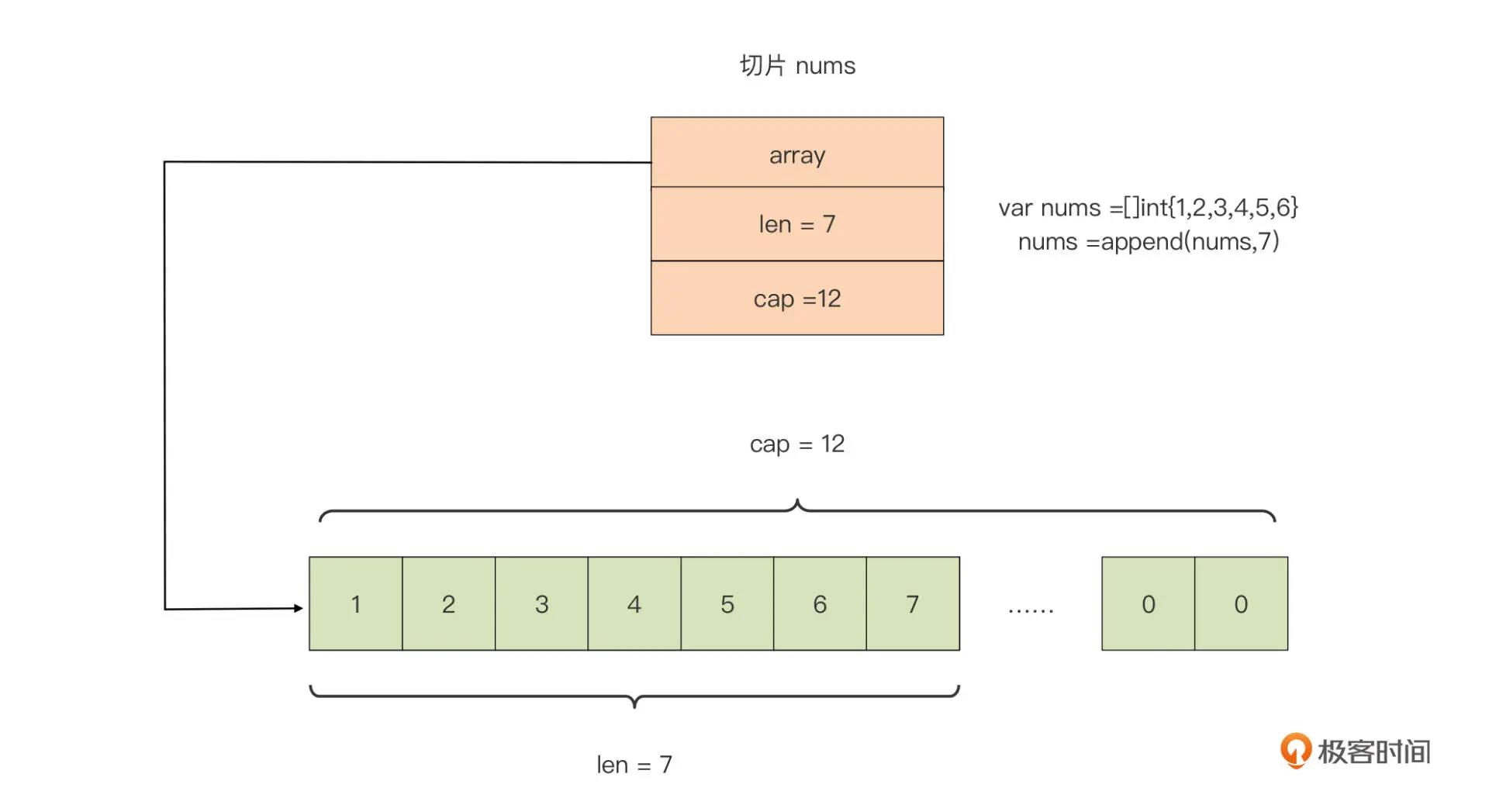
切片好比打开了一个访问与修改数组的“窗口”,通过这个窗口,我们可以直接操作底层数组中的部分元素。

type MySlice struct
func printSlice(sl []int)
fmt.Printf("length: %d, capcity: %d \\n", len(sl), cap(sl))
for i, i2 := range sl
fmt.Printf("(%d, %d ) ", i, i2)
fmt.Printf("\\n")
func (MySlice) test()
//1.创建切片
sl := make([]int , 5, 7) //创建了一个切片,长度为 5,有 5 个元素为 0 的值
printSlice(sl)
sl = append(sl, 1,2,3,4,5,6) //添加 6 个,超出容量,翻倍,元素个数为 5 + 6
printSlice(sl)
//数组与切片类型不兼容:Cannot use '[5]int 1,2,3,4,5' (type [5]int) as type []int
//printSlice([5]int 1,2,3,4,5)
//2.数组的切片化
var arr = [...]int 1,2,3,4,5
//从索引 1 (第二个)开始,长度到 2,容量到 5
sl2 := arr[1:3:5] //长度是第二个值减去第一个,容量是第三个值减去第一个
printSlice(sl2)
sl2[0] = 444 //修改切片,会影响原始数组
fmt.Printf("origin array first value: %d\\n", arr[1])
sl2 = append(sl2, 2, 3, 4, 5)
printSlice(sl2)
sl2[0] = 555 //扩容后会创建新数组,再修改不会影响原始数组
fmt.Printf("origin array first value: %d\\n", arr[1])
切片在做为参数传递时,只传递指针,成本更低。
切片扩容后会创建新数组,再修改不会影响原始数组
**如何把完整的数组转换为切片:a[:] **,意思是将数组 a 转换为一个切片,长度和容量和数组一致。
在大多数场合,我们都会使用切片以替代数组。
map 使用及实现
https://time.geekbang.org/column/article/446032
Go map 是一个无序的 key-value 数据结构。
注意点:
- 不要依赖 map 的元素遍历顺序;
- map 不是线程安全的,不支持并发读写;
- 不要尝试获取 map 中元素(value)的地址。
for range 过程中的 k,v 公用,不能直接做引用传递。
Go map 的 key 类型有要求,必须支持 == 操作符,这就导致这些类型不能做 key:
- 函数
- map
- 切片
切片零值可用,但 map 不支持,必须初始化后才能用。
两种赋值方式:
- 短变量的方式,加上 ,就是初始化了
- 通过 make 创建
type MyMap struct
type Position struct
x float64
y float64
func updateMap(m map[string]int)
m["hihi"] = 1024
func (MyMap) test()
//var m map[int]string //不赋值,默认为 nil。这时操作的话会报错:panic: assignment to entry in nil map
//m := map[int]string //1.短变量的方式,加上 ,就是初始化了
m := make(map[int]string, 6) //2.通过 make 创建
m[1] = "haha"
m[1024] = "bytes"
fmt.Println(m[1], len(m)) //len(map): 获取 map 中已存储的键值对
for k, v := range m
fmt.Printf("(%d, %s) ", k, v)
fmt.Printf("\\n")
//第一种初始化方式:字面值初始化
//m1 := map[Position]string //较为复杂的初始化,写全类型
// Position1,2: "home",
// Position3,4 : "company",
//
m1 := map[Position]string
1,2: "home", //初始化赋值时,可以省略掉类型,直接以内容作为 key
3,4 : "company",
fmt.Println(m1)
p := Position1,2
m1[p] = "shop"
fmt.Println(m1)
delete(m1, p) //通过内置函数 delete 删除 map 的值,参数为 map 和 key
fmt.Println("after delete: ", m1)
//通过下标访问不存在的值,会返回这个类型的零值
emptyMap := make(map[string]int)
fmt.Printf("try key that is not inside map: %s , %d\\n", m[1024], emptyMap["hihi"])
//map 作为参数是引用传递,内部修改,外部也有影响!
updateMap(emptyMap)
value, ok := emptyMap["hihi"] //通过 _value, ok(逗号 + ok) 的方式判断是否存在于 map
if !ok
fmt.Println("hihi not in map")
else
fmt.Println("hihi in the map! ", value)
输出:
haha 2
(1, haha) (1024, bytes)
map[1 2:home 3 4:company]
map[1 2:shop 3 4:company]
after delete: map[3 4:company]
try key that is not inside map: bytes , 0
hihi in the map! 1024
可以看到:
- 对 map 遍历多次时,元素的次序不确定,可能会有变化。
- 和 切片 一样,map 也是引用类型。
- map 作为参数是引用传递,内部修改,外部也有影响!⚠️
- 在 map 中查找和读取时,建议通过逗号 + ok 的方式,以确认 key 是否存在!
map 内部实现
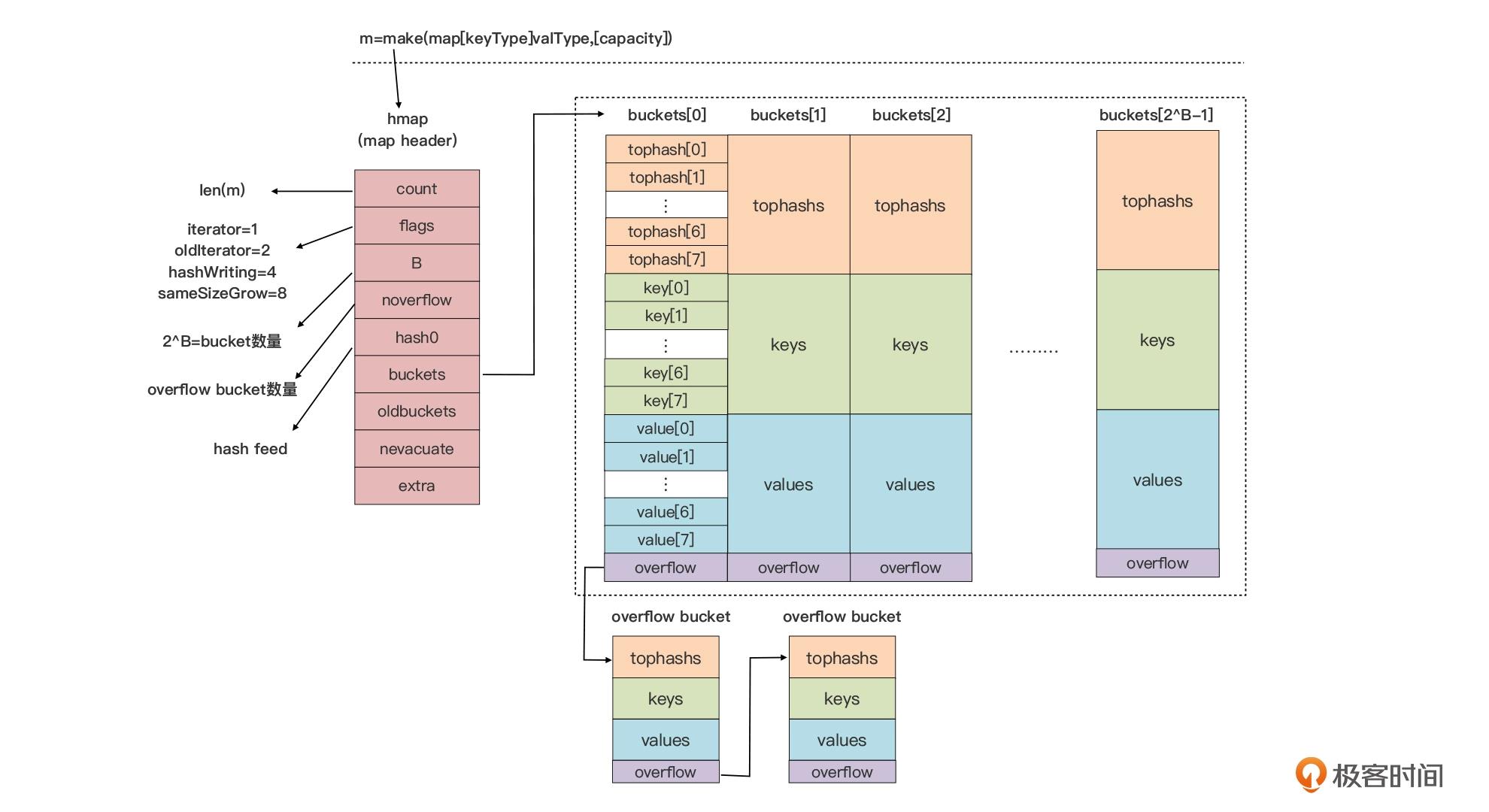
map 类型在 Go 运行时层实现的示意图:
图片来自:https://time.geekbang.org/column/article/446032
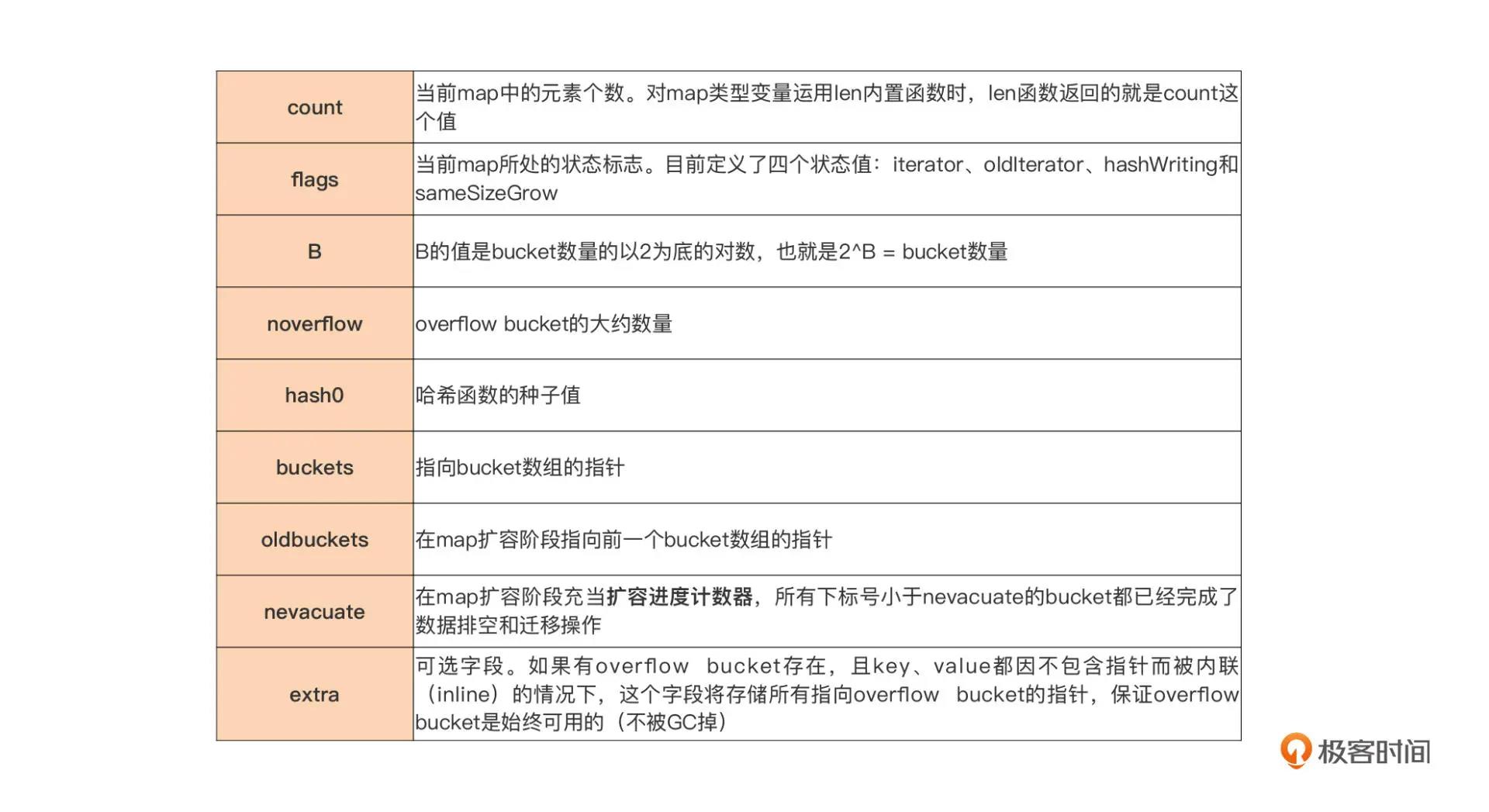
- hmap:
runtime.hmap,map 类型的头部结构(header) - bucket:真正存储键值对数据的数据结构,哈希值低位相同的元素会放到一个桶里,一个桶默认 8 个元素
- overflow bucket:某个 bucket元素 > 8 && map 不需要扩容时,会创建这个溢出桶,数据保存在这里
每个 bucket 由三部分组成:
- tophash
- key
- value
哈希值分两部分:
- 低位值是桶索引,决定当前访问数据在第几个桶
- 高位值是桶内索引(tophash 数组的索引),决定在桶里第几个
使用哈希值,可以提升这两步查找时的速度。
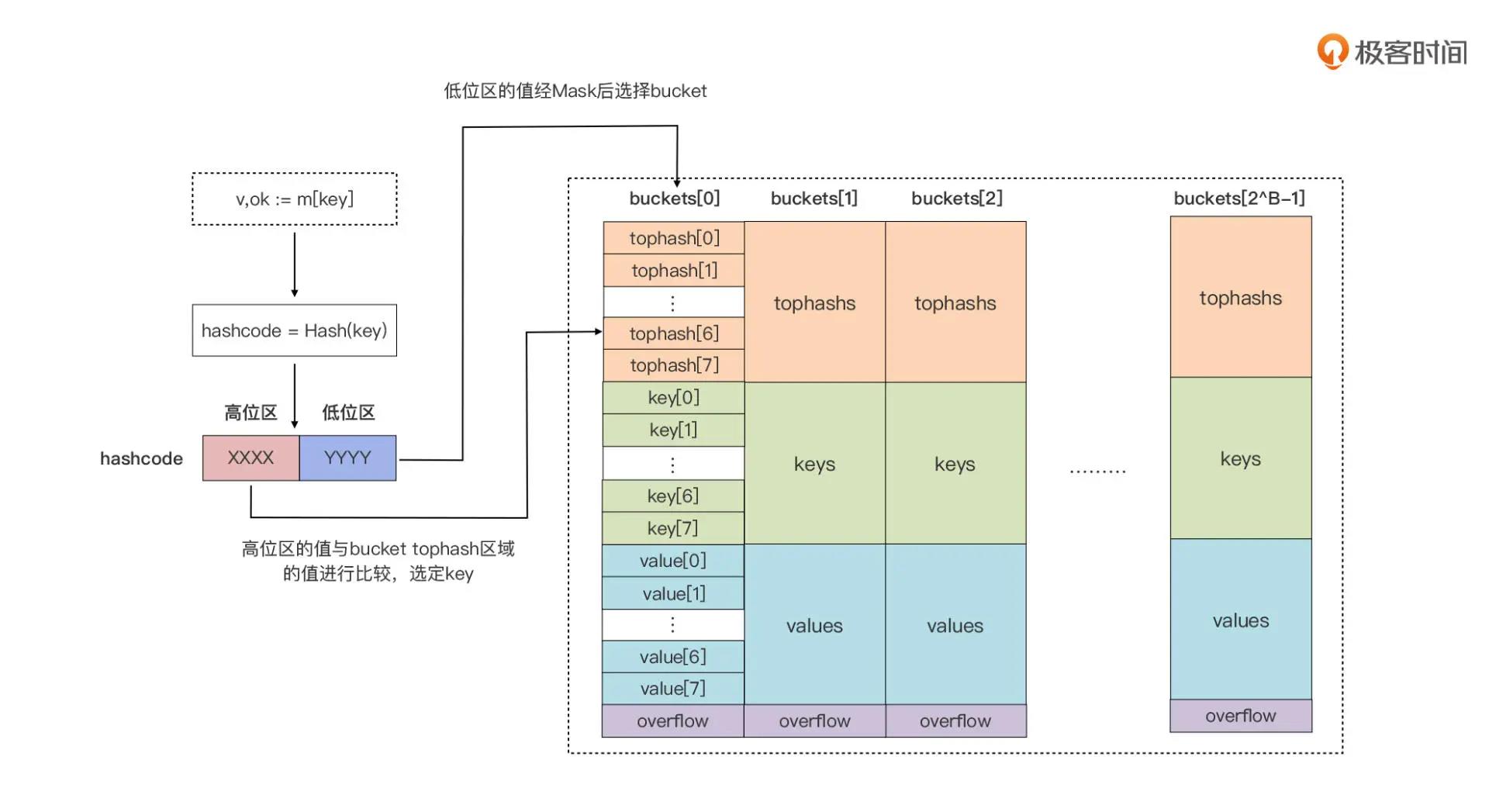
Go 运行时采用了把 key 和 value 分开存储的方式,而不是采用一个 kv 接着一个 kv 的 kv 紧邻方式存储,这带来的其实是算法上的复杂性,但却减少了因内存对齐带来的内存浪费。

// $GOROOT/src/runtime/map.go
const (
// Maximum number of key/elem pairs a bucket can hold.
bucketCntBits = 3
bucketCnt = 1 << bucketCntBits
// Maximum average load of a bucket that triggers growth is 6.5.
// Represent as loadFactorNum/loadFactorDen, to allow integer math.
loadFactorNum = 13
loadFactorDen = 2
// Maximum key or elem size to keep inline (instead of mallocing per element).
// Must fit in a uint8.
// Fast versions cannot handle big elems - the cutoff size for
// fast versions in cmd/compile/internal/gc/walk.go must be at most this elem.
maxKeySize = 128
maxElemSize = 128
)
map 扩容的两个场景:
- map 的元素个数 > LoadFactor * 2^B
- overflow bucket 过多时
目前 Go 最新 1.17 版本 LoadFactor 设置为 6.5 (loadFactorNum/loadFactorDen)
// Like mapaccess, but allocates a slot for the key if it is not present in the map.
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer
// If we hit the max load factor or we have too many overflow buckets,
// and we're not already in the middle of growing, start growing.
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B))
hashGrow(t, h)
goto again // Growing the table invalidates everything, so try again
// overLoadFactor reports whether count items placed in 1<<B buckets is over loadFactor.
func overLoadFactor(count int, B uint8) bool
return count > bucketCnt && uintptr(count) > loadFactorNum*(bucketShift(B)/loadFactorDen)
// tooManyOverflowBuckets reports whether noverflow buckets is too many for a map with 1<<B buckets.
// Note that most of these overflow buckets must be in sparse use;
// if use was dense, then we'd have already triggered regular map growth.
func tooManyOverflowBuckets(noverflow uint16, B uint8) bool
// If the threshold is too low, we do extraneous work.
// If the threshold is too high, maps that grow and shrink can hold on to lots of unused memory.
// "too many" means (approximately) as many overflow buckets as regular buckets.
// See incrnoverflow for more details.
if B > 15
B = 15
// The compiler doesn't see here that B < 16; mask B to generate shorter shift code.
return noverflow >= uint16(1)<<(B&15)
如果是元素个数超出负载因子,会创建一个 2 倍大小的桶数组,原始桶数据会保存在 hmap 的 oldbuckets 下,直到所有原始桶数据复制到新数组。

map 实例不是并发写安全的,也不支持并发读写。如果我们对 map 实例进行并发读写,程序运行时就会抛出异常。如果要并发读写 map,可以使用 sync.Map。
struct
https://time.geekbang.org/column/article/446840
类型定义也支持一次性定义多个:
type (
T1 int
T2 T1
)
type T struct
my T // compile error: Invalid recursive type 'MyStruct'
t *T // ok
st []T // ok
m map[string]T // ok
空结构体内存占用为 0:
var em EmptyStruct
fmt.Println("size of empty struct: ", unsafe.Sizeof(em)) //size of empty struct: 0
空结构体类型的变量不占用内存空间,十分适合作为一种“事件”在并发的 Goroutine 间传递。
Go struct 是零值可用的,可以声明后就直接使用。
同时也支持声明值时通过字面值初始化,共有这几种方式:
- 按顺序赋值:
p := Position1,2 - 通过指定参数名称进行赋值:
q := Positiony: 3, x: 6
如果一个结构体的构造比较复杂,传入参数后需要内部做很多工作,我们可以为结构体类型定义一个函数,用于构造这个结构体:
func NewT(field1, field2, ...) *T
... ...
例如:
func NewPosition(center float64) *Position
return &Position
x: center - 10,
y: center + 10,
struct 的内存布局
在运行时,Go 结构体的元素(成员、方法)存放在一个连续内存块中。
内存对齐,是出于提升处理器存取数据效率的考虑。
对于各种基本数据类型来说,它的变量的内存地址值必须是其类型本身大小的整数倍。
比如:一个 int64 类型的变量的内存地址,应该能被 int64 类型自身的大小,也就是 8 整除;一个 uint16 类型的变量的内存地址,应该能被 uint16 类型自身的大小,也就是 2 整除。
为了合理使用内存,编译器可能会给结构体中填充数据(和 C/C++ 类似),包括两种:
- 字段填充:让字段的地址可以被自己的类型占用字节数整除
- 尾部填充:保证每个结构体变量的地址是一个值的整数倍,这个值是 结构体内最长字段的长度 和 系统内存对齐系数 的最小值
64 位处理器上,内存对齐系数一般为 8。

我们开发者在定义结构体时,尽量合理安排字段顺序,否则填充过多会导致占用空间更大。
- Go 中循环语句只有 for,没有 while 和 do while
- Go 中的 switch,类型也可以作为条件;case 不需要写 break
if 自用变量
https://time.geekbang.org/column/article/447723
操作符优先级:

注意:逻辑与和逻辑或的优先级很低,如果在一个条件语句里有其他操作符,逻辑与和或最后执行。
比如这个例子:
func main()
a, b := false,true
if a && b != true
println("(a && b) != true")
return
println("a && (b != true) == false")
第一直觉是先执行 a && b。⚠️ 实际上,!= 比 && 优先级更高,所以先执行 !=。
if 语句的自用变量:在布尔表达式前声明的变量,作用范围只在 if 代码块中(包括 else 里)。
第一直觉是只在声明的代码块里,⚠️ 实际上,else 里也可以访问到。
//if 的自用变量,在 if 的 else 代码块里也可以访问
if tempA := 1; tempA > 0
//...
else
fmt.Println(tempA) //仍然可以访问
fmt.Println(tempA) //Unresolved reference 'tempA'
为什么多个条件逻辑中,最容易命中的写到前面,是最好的呢?
这里面主要涉及到2个技术点:流水线技术和分支预测
流水线技术:简单的说,一条 CPU 指令的执行是由 取指令-指令译码-指令执行-结果回写组成的(简单的说哈,真实的流水线是更长更复杂的);第一条指令译码的时候,就可以去取第二条指令,因此可以通过流水线技术提高CPU的使用率。
分支预测:如果没有任何分支预测,那么就是按照程序的代码顺序执行,那么执行到if上一句的时候,指令译码就是if语句,取指令就是if语句块的第一句,那么if如果不满足的话,就会执行JMP指令,跳转到else,因此流水线中的取指令与指令译码其实是无用功。因此在没有任何分支预测优化的情况下,if语句需要把概率更高的条件写到最上面,更能体现流水线的威力。
现代计算机都有分支预测的优化,比如动态分支预测等技术,但是不管怎么说,把概率最大的放到最上面,以上是关于Golang 入门总结:Go Module, for range, 切片, map, struct 等使用和实现的主要内容,如果未能解决你的问题,请参考以下文章