GPU — 物理 GPU 虚拟化技术
Posted 范桂飓
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了GPU — 物理 GPU 虚拟化技术相关的知识,希望对你有一定的参考价值。
目录
文章目录
- 目录
- 物理 GPU 虚拟化技术
- SR-IOV Passthrough vGPU
- API Forwarding vGPU
- Mediated Passthrough vGPU
- NIVDIA Multi-Instance vGPU
- Containerized vGPU
物理 GPU 虚拟化技术
物理 GPU 虚拟化技术总的来说有 2 大技术方向:
- Time Sharing:分时轮训,可以细分为 SR-IOV Passthrough vGPU、API Forwarding vGPU、Mediated Passthrough vGPU 方案。
- Hardware Partition:硬件隔离,目前有 NIVDIA Multi-Instance vGPU。
SR-IOV Passthrough vGPU
GPU 作为一种典型 PCIe 设备,可以基于 SR-IOV 规范,将 GPU 切分为多个 PF / VF 后,再通过 PCI Passthrough 的方式分别提供给多个 VM 使用。典型的产品有 AMD S7150 GPU、Nvidia Turing 架构。
一个 PCIe 设备拥有 2 种资源、2 种能力:
- 2 种资源
- 物理的配置空间,设备上的寄存器或存储。
- 物理的 MMIO(Memory Mapped IO),设备上的寄存器或存储,CPU 以内存读写指令来进行直接访问。
- 2 种能力
- 中断能力
- DMA 能力
类似的,一个 VF 也拥有着类似的资源和能力。同时,因为 VF 有自己的 PCIe 协议层的 BDF 标识(Routing ID),从而拥有独立的地址空间。
- 2 种资源
- 虚拟的配置空间(特权资源)
- 物理的 MMIO
- 2 种能力
- 中断能力
- DMA 能力
适合实现 SR-IOV 标准的设备通常需要具备 2 个特征:
- 硬件资源要容易 Partition(划分)。
- 无状态。
例如 SR-IOV 网卡,一或多对 TX/RX Queue、一或多个中断,结合一个 Routing ID,就可以抽象为一个 VF,而且它是近乎无状态的。而对于 GPU 来说,GPU 基本也是无状态的,但是 GPU 的硬件复杂度极高,导致硬件资源的 Partition 很难实现。
所以 SR-IOV Passthrough vGPU 可能不是一个完美的 vGPU。例如 AMD S7150 GPU,表面上它支持 SR-IOV,但事实上硬件只是做了 VF 在 PCIe 层的抽象。Host 上还需要一个 Virtualization-Aware 的 pGPU 驱动,负责 VF 的模拟和调度。
API Forwarding vGPU
API Forwarding vGPU 是一种在软件层面实现了 GPU 虚拟化方案。
以 AWS Elastic GPU 为例,EC2 VM 看不到真的或假的 GPU,但可以调用 OpenGL API 进行渲染。在 OpenGL API 层,软件捕捉到该调用,转发给 Host,然后 Host 请求 GPU 进行渲染,最终 Host 把渲染的结果,转发给 VM。期间 VM 的 API Invoke 在 High-level 的软件层面进行了 Forwarding。
API Forwarding vGPU 是目前业界应用最广泛的 GPU 虚拟化方案。它的好处有:
- 灵活:完全基于软件实现的物理资源管理和优先级调度控制。
- 不依赖于 GPU 硬件厂商。
- 不限于系统虚拟化环境:容器、物理机,都可以使用。
缺点是:
- 复杂度极高:同一功能有多套 API(渲染的 DirectX 和 OpenGL),同一套 API 还有不同版本(如 DirectX 9 和 DirectX 11),兼容性就复杂。
- 功能不完整。
Mediated Passthrough vGPU
MPT(Mediated Passthrough,分片透传)vGPU,是一种完全软件定义的 GPU 虚拟化解决方案,核心思想是:对于与 GPU 性能相关的访问直接透传给 VM,把与性能无关功能的相关访问在 Mdev 模块中来模拟实现。典型产品有 Nvidia GRID vGPU、Intel GVT-g(KVMGT、XenGT)。
- 敏感资源虚拟化实现,如:配置空间。
- 关键资源虚拟化实现,如:MMIO(CSR 部分),以便 Trap-and-emulate(陷入和模仿)。
- 性能资源物理化实现,如:MMIO(GPU Memory、NVMe CMB 等),硬件 Partition 后直接交给 VM。
- Host OS 必须运行一个 Virtualization-Aware 驱动程序,负责模拟和调度,实际上是 vGPU 的 device-model(驱动模块)。
如此的,MPT 使得 VM 可以得到一个看似完整的 GPU PCIe 设备,Guest OS 也可以 Attach 原生的 GPU 驱动。
以渲染为例,vGPU 的基本工作流程是:
- Guest OS 中的 GPU 驱动,准备好一块内存,保存的是渲染 Workload。
- Guest OS 中的 GPU 驱动,把这块内存的物理地址(GPA),写入到 MMIO CSR 中。
- Host OS 中的 GPU 驱动,捕捉到这次的 MMIO CSR 写操作,拿到了 GPA。
- Host OS 中的 GPU 驱动,把 GPA 转换成 HPA,并 Pin(绑定)住相应的内存页。
- Host OS 中的 GPU 驱动,把 HPA(而不是 GPA),写入到 pGPU 的真实的 MMIO CSR 中。
- pGPU 工作,完成这个渲染 Workload,并发送中断给驱动。
- 驱动找到该中断对应哪个 Workload,并注入一个虚拟的中断到相应的 VM 中。
- Guest OS 中的 GPU 驱动,收到中断,知道该 Workload 已完成、结果在内存中。
MPT 的关技术是 Mdev(Mediated Device 框架),是一个基于 VFIO 框架及接口来实现 Virtual PCI 设备,因此能够完全基于软件来实现,将 Host pGPU 切分成为多个 vGPU 设备并进行共享。
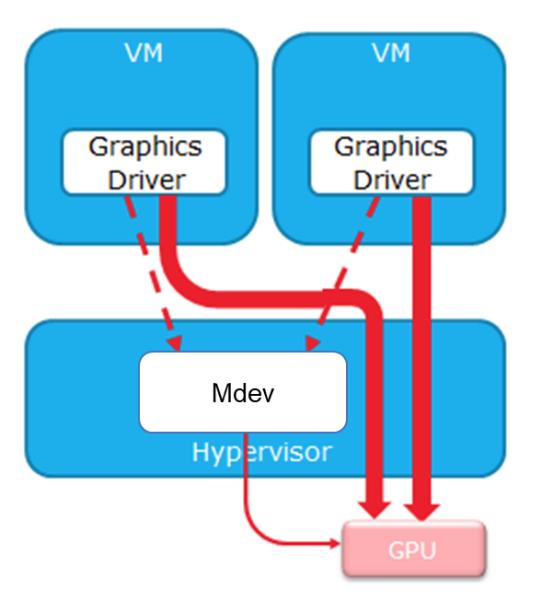
然而,MPT 方案最大的缺陷就是必须在 Host OS 上运行一个 pGPU 驱动,负责 vGPU 的模拟和调度工作。逻辑上它相当于一个实现在内核态的 device-model。而且,由于 GPU 硬件通常并不公开其 PRM,所以事实上就只有 GPU 厂商才有能力提供这样的 Virtualization-Aware pGPU 驱动。使用了厂商提供的 MPT 方案,事实上就形成了对厂商的依赖。
NIVDIA Multi-Instance vGPU
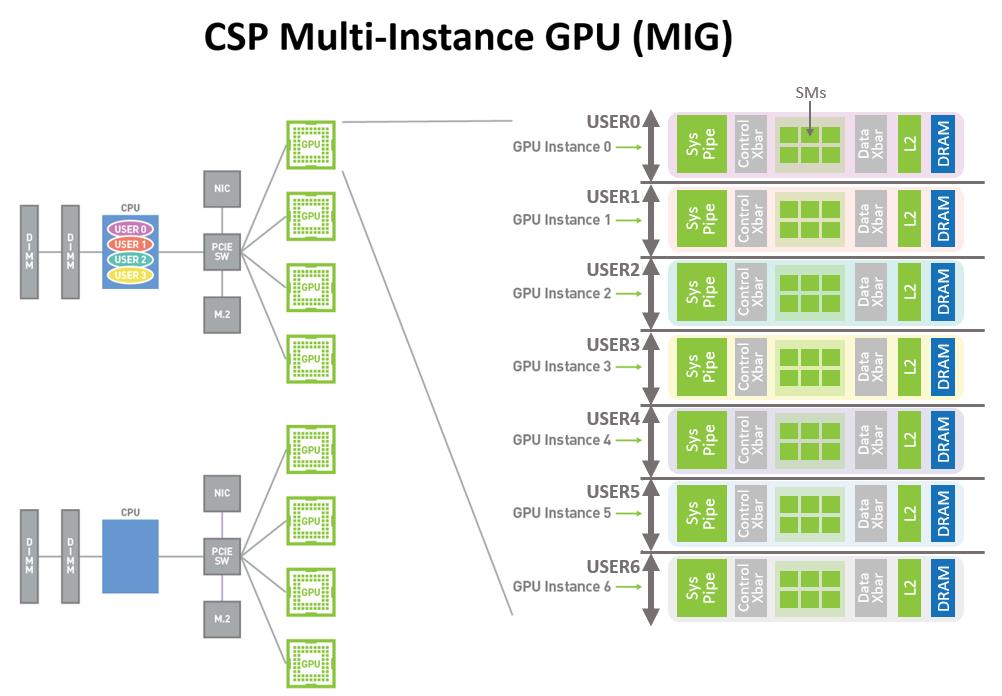
Nvidia 最新的 Ampere 架构支持 Multi-Instance GPU(MIG)技术,它能够水平切分 GPU 资源。
每个 A100 GPU 在硬件底层被拆分成了 7 个 GPU instance,每个 Instance 都有隔离的 Core、Cache 和 Memory,这不仅可以满足数据中心分割 GPU 资源的需要,还能在同一张显卡上并行运行不同的训练任务。
Multi-Instance vGPU 实现了硬件资源隔离、故障隔离,是无可争议的隔离性最好的方案。但它的问题高成本和不灵活:只有高端 GPU 支持、只支持 CUDA、A100 只支持 7 个 MIG 实例。
Containerized vGPU
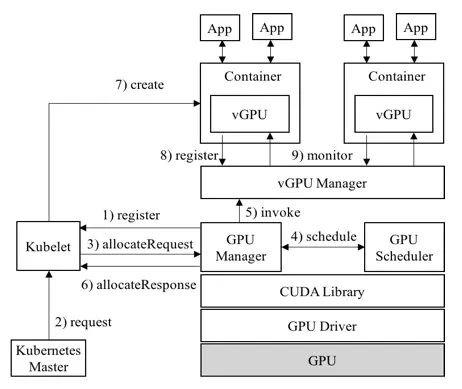
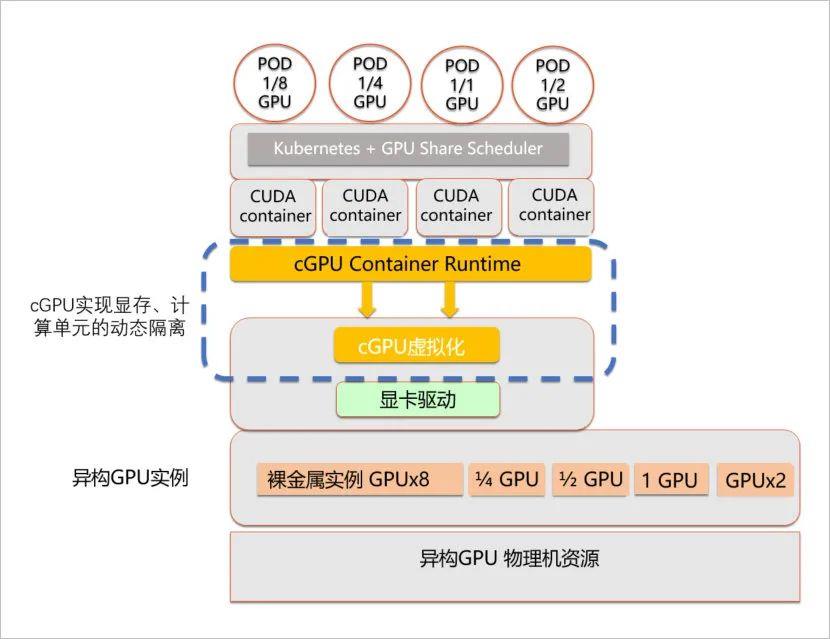
为了让多个 Container 可以共享同一个 pGPU,典型的方案有 vCUDA 和 cGPU。相比下,cGPU 比 vCUDA 更底层,能够实现了无侵入用户环境。
-
vCUDA 架构
-
cGPU 架构
以上是关于GPU — 物理 GPU 虚拟化技术的主要内容,如果未能解决你的问题,请参考以下文章