数据治理:数据仓库数据质量管理
Posted Lansonli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据治理:数据仓库数据质量管理相关的知识,希望对你有一定的参考价值。
目录
9、编写Azkaban job 并打包,提交到Azkaban执行:
1、在Hive中创建存储数据质量监控数据库“data_quality”
2、创建存储ODS层数据质量监控数据表“check_ods_info”
数据仓库数据质量管理
下面我们针对音乐数据中心数仓项目第四个业务:“统计地区营收情况业务”来说明数据质量如何进行管理。此业务数据质量管理重点放在 ODS层,EDS层(DWD层、DWS层)、DM层几个方面,每层数据校验的内容不一样,我们可以通过自己编写通用shell+Hive脚本或者使用质量监控工具Griffin来进行数据质量监控。
一、“商户营收统计”业务
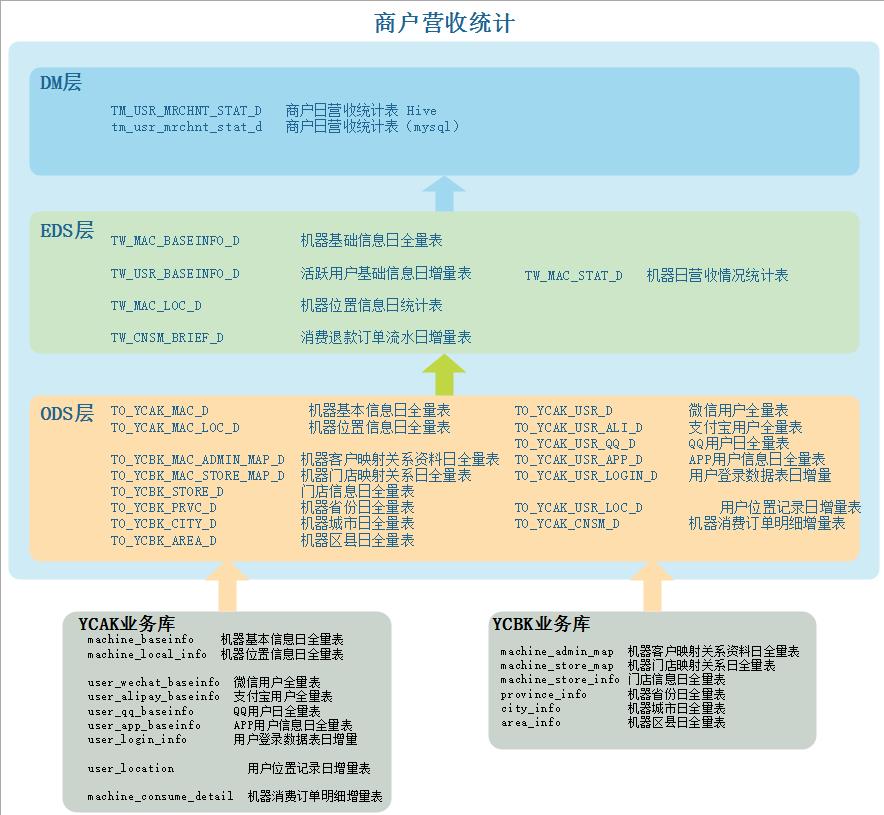
1、商户营收统计数据分层信息
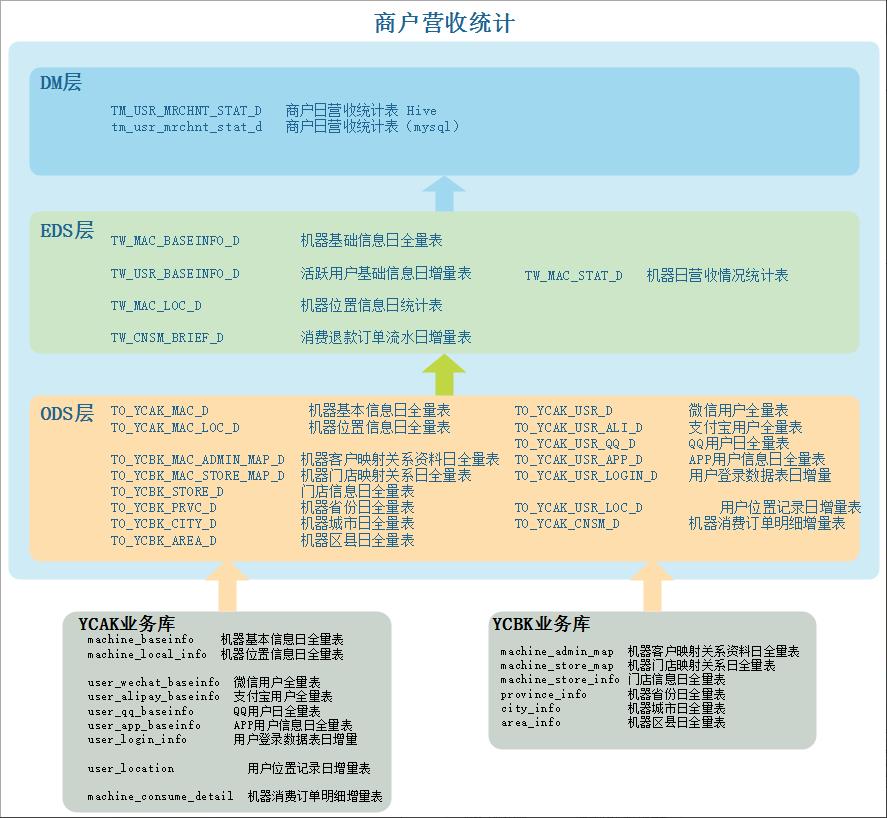
以上业务涉及到的数仓所有表:
数据仓库分层设计:
源业务系统:
ycak - user_location - 用户上报经纬度信息表
ycak - user_machine_consume_detail - 机器消费订单明细表
ODS:
user_location -- TO_YCAK_USR_LOC_D :用户位置记录日增量表 【增量导入】
user_machine_consume_detail -- TO_YCAK_CNSM_D :机器消费订单明细增量表 【增量导入】
machine_baseinfo -- TO_YCAK_MAC_D :机器基本信息日全量表 【全量导入】
machine_local_info -- TO_YCAK_MAC_LOC_D :机器位置信息日全量表 【全量导入】
machine_admin_map -- TO_YCBK_MAC_ADMIN_MAP_D :机器客户映射关系资料日全量表 【全量导入】
machine_store_map -- TO_YCBK_MAC_STORE_MAP_D :机器门店映射关系日全量表 【全量导入】
machine_store_info -- TO_YCBK_STORE_D :门店信息日全量表 【全量导入】
province_info -- TO_YCBK_PRVC_D :机器省份日全量表 【全量导入】
city_info -- TO_YCBK_CITY_D :机器城市日全量表 【全量导入】
area_info -- TO_YCBK_AREA_D :机器区县日全量表 【全量导入】
user_alipay_baseinfo -- TO_YCAK_USR_ALI_D :支付宝用户全量表 【全量导入】
user_wechat_baseinfo -- TO_YCAK_USR_D :微信用户全量表 【全量导入】
user_qq_baseinfo -- TO_YCAK_USR_QQ_D :QQ用户日全量表 【全量导入】
user_app_baseinfo -- TO_YCAK_USR_APP_D :APP用户信息日全量表 【全量导入】
user_login_info -- TO_YCAK_USR_LOGIN_D :用户登录数据表日增量 【增量导入】
EDS:
TW_MAC_LOC_D - 机器位置信息日统计表
TW_CNSM_BRIEF_D - 消费退款订单流水日增量表
TW_MAC_BASEINFO_D - 机器基础信息日全量表 【第二个业务】
TW_USR_BASEINFO_D - 活跃用户基础信息日增量表 【第三个业务】
TW_MAC_STAT_D - 机器日营收情况统计表
DM:
TM_USR_MRCHNT_STAT_D - 商户日营收统计表【mysql中也有对应的表ODS层:
TO_YCAK_USR_LOC_D :用户位置记录日增量表 【增量导入】
TO_YCAK_CNSM_D :机器消费订单明细增量表 【增量导入】
TO_YCAK_MAC_D :机器基本信息日全量表 【全量导入】
TO_YCAK_MAC_LOC_D :机器位置信息日全量表 【全量导入】
TO_YCBK_MAC_ADMIN_MAP_D :机器客户映射关系资料日全量表 【全量导入】
TO_YCBK_MAC_STORE_MAP_D :机器门店映射关系日全量表 【全量导入】
TO_YCBK_STORE_D :门店信息日全量表 【全量导入】
TO_YCBK_PRVC_D :机器省份日全量表 【全量导入】
TO_YCBK_CITY_D :机器城市日全量表 【全量导入】
TO_YCBK_AREA_D :机器区县日全量表 【全量导入】
TO_YCAK_USR_ALI_D :支付宝用户全量表 【全量导入】
TO_YCAK_USR_D :微信用户全量表 【全量导入】
TO_YCAK_USR_QQ_D :QQ用户日全量表 【全量导入】
TO_YCAK_USR_APP_D :APP用户信息日全量表 【全量导入】
TO_YCAK_USR_LOGIN_D :用户登录数据表日增量 【增量导入】
EDS层:
TW_MAC_LOC_D - 机器位置信息日统计表
TW_CNSM_BRIEF_D - 消费退款订单流水日增量表
TW_MAC_BASEINFO_D - 机器基础信息日全量表 【第二个业务】
TW_USR_BASEINFO_D - 活跃用户基础信息日增量表 【第三个业务】
TW_MAC_STAT_D - 机器日营收情况统计表
DM层:
TM_USR_MRCHNT_STAT_D - 商户日营收统计表2、清空之前业务执行的数据
#删除Mysql中ycak与ycbk库即可
#删除所有Hive表脚本
drop table TO_YCAK_MAC_D;
drop table TO_YCAK_MAC_LOC_D;
drop table TO_YCBK_AREA_D;
drop table TO_YCBK_CITY_D;
drop table TO_YCBK_MAC_ADMIN_MAP_D;
drop table TO_YCBK_MAC_STORE_MAP_D;
drop table TO_YCBK_PRVC_D;
drop table TO_YCBK_STORE_D;
drop table TW_MAC_BASEINFO_D;
drop table TO_YCAK_USR_D;
drop table TO_YCAK_USR_ALI_D;
drop table TO_YCAK_USR_QQ_D;
drop table TO_YCAK_USR_APP_D;
drop table TO_YCAK_USR_LOGIN_D;
drop table TW_USR_BASEINFO_D;
drop table TO_YCAK_USR_LOC_D;
drop table TW_MAC_LOC_D;
drop table TO_YCAK_CNSM_D;
drop table TW_CNSM_BRIEF_D;
drop table TW_MAC_STAT_D;
drop table TM_USR_MRCHNT_STAT_D;
drop table TM_MAC_REGION_STAT_D;
#执行以下命令,清空HDFS 目录即可
hdfs dfs -rm -r /user/hive/warehouse/data/
3、重新创建Hive 各层数据表:
#执行如下脚本,直接创建,所有Hive中需要的表
CREATE EXTERNAL TABLE `TO_YCAK_MAC_D`(
`MID` int,
`SRL_ID` string,
`HARD_ID` string,
`SONG_WHSE_VER` string,
`EXEC_VER` string,
`UI_VER` string,
`IS_ONLINE` string,
`STS` int,
`CUR_LOGIN_TM` string,
`PAY_SW` string,
`LANG` int,
`SONG_WHSE_TYPE` int,
`SCR_TYPE` int)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\\t'
LOCATION 'hdfs://mycluster/user/hive/warehouse/data/machine/TO_YCAK_MAC_D';
CREATE EXTERNAL TABLE `TO_YCAK_MAC_LOC_D`(
`MID` int,
`PRVC_ID` int,
`CTY_ID` int,
`PRVC` string,
`CTY` string,
`MAP_CLSS` string,
`LON` string,
`LAT` string,
`ADDR` string,
`ADDR_FMT` string,
`REV_TM` string,
`SALE_TM` string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\\t'
LOCATION 'hdfs://mycluster/user/hive/warehouse/data/machine/TO_YCAK_MAC_LOC_D';
CREATE EXTERNAL TABLE `TO_YCBK_MAC_ADMIN_MAP_D`(
`MID` int,
`MAC_NM` string,
`PKG_NUM` int,
`PKG_NM` string,
`INV_RATE` double,
`AGE_RATE` double,
`COM_RATE` double,
`PAR_RATE` double,
`DEPOSIT` double,
`SCENE_PRVC_ID` string,
`SCENE_CTY_ID` string,
`SCENE_AREA_ID` string,
`SCENE_ADDR` string,
`PRDCT_TYPE` string,
`SERIAL_NUM` string,
`HAD_MPAY_FUNC` int,
`IS_ACTV` int,
`ACTV_TM` string,
`ORDER_TM` string,
`GROUND_NM` string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\\t'
LOCATION 'hdfs://mycluster/user/hive/warehouse/data/machine/TO_YCBK_MAC_ADMIN_MAP_D';
CREATE EXTERNAL TABLE `TO_YCBK_MAC_STORE_MAP_D`(
`STORE_ID` int,
`MID` int,
`PRDCT_TYPE` int,
`ADMINID` int,
`CREAT_TM` string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\\t'
LOCATION 'hdfs://mycluster/user/hive/warehouse/data/machine/TO_YCBK_MAC_STORE_MAP_D';
CREATE EXTERNAL TABLE `TO_YCBK_STORE_D`(
`ID` int,
`STORE_NM` string,
`TAG_ID` string,
`TAG_NM` string,
`SUB_TAG_ID` string,
`SUB_TAG_NM` string,
`PRVC_ID` string,
`CTY_ID` string,
`AREA_ID` string,
`ADDR` string,
`GROUND_NM` string,
`BUS_TM` string,
`CLOS_TM` string,
`SUB_SCENE_CATGY_ID` string,
`SUB_SCENE_CATGY_NM` string,
`SUB_SCENE_ID` string,
`SUB_SCENE_NM` string,
`BRND_ID` string,
`BRND_NM` string,
`SUB_BRND_ID` string,
`SUB_BRND_NM` string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\\t'
LOCATION 'hdfs://mycluster/user/hive/warehouse/data/machine/TO_YCBK_STORE_D';
CREATE EXTERNAL TABLE `TO_YCBK_PRVC_D`(
`PRVC_ID` int,
`PRVC` string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\\t'
LOCATION 'hdfs://mycluster/user/hive/warehouse/data/machine/TO_YCBK_PRVC_D';
CREATE EXTERNAL TABLE `TO_YCBK_CITY_D`(
`PRVC_ID` int,
`CTY_ID` int,
`CTY` string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\\t'
LOCATION 'hdfs://mycluster/user/hive/warehouse/data/machine/TO_YCBK_CITY_D';
CREATE EXTERNAL TABLE `TO_YCBK_AREA_D`(
`CTY_ID` int,
`AREA_ID` int,
`AREA` string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\\t'
LOCATION 'hdfs://mycluster/user/hive/warehouse/data/machine/TO_YCBK_AREA_D';
CREATE EXTERNAL TABLE `TW_MAC_BASEINFO_D`(
`MID` int,
`MAC_NM` string,
`SONG_WHSE_VER` string,
`EXEC_VER` string,
`UI_VER` string,
`HARD_ID` string,
`SALE_TM` string,
`REV_TM` string,
`OPER_NM` string,
`PRVC` string,
`CTY` string,
`AREA` string,
`ADDR` string,
`STORE_NM` string,
`SCENCE_CATGY` string,
`SUB_SCENCE_CATGY` string,
`SCENE` string,
`SUB_SCENE` string,
`BRND` string,
`SUB_BRND` string,
`PRDCT_NM` string,
`PRDCT_TYP` int,
`BUS_MODE` string,
`INV_RATE` double,
`AGE_RATE` double,
`COM_RATE` double,
`PAR_RATE` double,
`IS_ACTV` int,
`ACTV_TM` string,
`PAY_SW` int,
`PRTN_NM` string,
`CUR_LOGIN_TM` string
)
PARTITIONED BY (data_dt string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\\t'
LOCATION 'hdfs://mycluster/user/hive/warehouse/data/machine/TW_MAC_BASEINFO_D';
CREATE EXTERNAL TABLE `TO_YCAK_USR_D`(
`UID` int,
`REG_MID` int,
`GDR` string,
`BIRTHDAY` string,
`MSISDN` string,
`LOC_ID` int,
`LOG_MDE` int,
`REG_TM` string,
`USR_EXP` string,
`SCORE` int,
`LEVEL` int,
`WX_ID` string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\\t'
LOCATION 'hdfs://mycluster/user/hive/warehouse/data/user/TO_YCAK_USR_D';
CREATE EXTERNAL TABLE `TO_YCAK_USR_ALI_D`(
`UID` int,
`REG_MID` int,
`GDR` string,
`BIRTHDAY` string,
`MSISDN` string,
`LOC_ID` int,
`LOG_MDE` int,
`REG_TM` string,
`USR_EXP` string,
`SCORE` int,
`LEVEL` int,
`USR_TYPE` string,
`IS_CERT` string,
`IS_STDNT` string,
`ALY_ID` string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\\t'
LOCATION 'hdfs://mycluster/user/hive/warehouse/data/user/TO_YCAK_USR_ALI_D';
CREATE EXTERNAL TABLE `TO_YCAK_USR_QQ_D`(
`UID` int,
`REG_MID` int,
`GDR` string,
`BIRTHDAY` string,
`MSISDN` string,
`LOC_ID` int,
`LOG_MDE` int,
`REG_TM` string,
`USR_EXP` string,
`SCORE` int,
`LEVEL` int,
`QQID` string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\\t'
LOCATION 'hdfs://mycluster/user/hive/warehouse/data/user/TO_YCAK_USR_QQ_D';
CREATE EXTERNAL TABLE `TO_YCAK_USR_APP_D`(
`UID` int,
`REG_MID` int,
`GDR` string,
`BIRTHDAY` string,
`MSISDN` string,
`LOC_ID` int,
`REG_TM` string,
`USR_EXP` string,
`LEVEL` int,
`APP_ID` string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\\t'
LOCATION 'hdfs://mycluster/user/hive/warehouse/data/user/TO_YCAK_USR_APP_D';
CREATE EXTERNAL TABLE `TO_YCAK_USR_LOGIN_D`(
`ID` int,
`UID` int,
`MID` int,
`LOGIN_TM` string,
`LOGOUT_TM` string,
`MODE_TYPE` int
)
PARTITIONED BY (`data_dt` string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\\t'
LOCATION 'hdfs://mycluster/user/hive/warehouse/data/user/TO_YCAK_USR_LOGIN_D';
CREATE EXTERNAL TABLE `TW_USR_BASEINFO_D`(
`UID` int,
`REG_MID` int,
`REG_CHNL` string,
`REF_UID` string,
`GDR` string,
`BIRTHDAY` string,
`MSISDN` string,
`LOC_ID` int,
`LOG_MDE` string,
`REG_DT` string,
`REG_TM` string,
`USR_EXP` string,
`SCORE` int,
`LEVEL` int,
`USR_TYPE` string,
`IS_CERT` string,
`IS_STDNT` string
)
PARTITIONED BY (`data_dt` string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\\t'
LOCATION 'hdfs://mycluster/user/hive/warehouse/data/user/TW_USR_BASEINFO_D';
CREATE EXTERNAL TABLE `TO_YCAK_USR_LOC_D`(
`ID` int,
`UID` int,
`LAT` string,
`LNG` string,
`DATETIME` string,
`MID` string
)
PARTITIONED BY (data_dt string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\\t'
LOCATION 'hdfs://mycluster/user/hive/warehouse/data/user/TO_YCAK_USR_LOC_D';
CREATE EXTERNAL TABLE `TW_MAC_LOC_D`(
`MID` int,
`X` string,
`Y` string,
`CNT` int,
`ADDER` string,
`PRVC` string,
`CTY` string,
`CTY_CD` string,
`DISTRICT` string,
`AD_CD` string,
`TOWN_SHIP` string,
`TOWN_CD` string,
`NB_NM` string,
`NB_TP` string,
`BD_NM` string,
`BD_TP` string,
`STREET` string,
`STREET_NB` string,
`STREET_LOC` string,
`STREET_DRCTION` string,
`STREET_DSTANCE` string,
`BUS_INFO` string
)
PARTITIONED BY (data_dt string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\\t'
LOCATION 'hdfs://mycluster/user/hive/warehouse/data/machine/TW_MAC_LOC_D';
CREATE EXTERNAL TABLE `TO_YCAK_CNSM_D`(
`ID` int,
`MID` int,
`PRDCD_TYPE` int,
`PAY_TYPE` int,
`PKG_ID` int,
`PKG_NM` string,
`AMT` int,
`CNSM_ID` string,
`ORDR_ID` string,
`TRD_ID` string,
`ACT_TM` string,
`UID` int,
`NICK_NM` string,
`ACTV_ID` int,
`ACTV_NM` string,
`CPN_TYPE` int,
`CPN_TYPE_NM` string,
`PKG_PRC` int,
`PKG_DSCNT` int,
`ORDR_TYPE` int,
`BILL_DT` int
)
PARTITIONED BY (data_dt string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\\t'
LOCATION 'hdfs://mycluster/user/hive/warehouse/data/user/TO_YCAK_CNSM_D';
CREATE EXTERNAL TABLE `TW_CNSM_BRIEF_D`(
`ID` int,
`TRD_ID` string,
`UID` string,
`MID` int,
`PRDCD_TYPE` int,
`PAY_TYPE` int,
`ACT_TM` string,
`PKG_ID` int,
`COIN_PRC` int,
`COIN_CNT` int,
`UPDATE_TM` string,
`ORDR_ID` string,
`ACTV_NM` string,
`PKG_PRC` int,
`PKG_DSCNT` int,
`CPN_TYPE` int,
`ABN_TYP` int
)
PARTITIONED BY (data_dt string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\\t'
LOCATION 'hdfs://mycluster/user/hive/warehouse/data/user/TW_CNSM_BRIEF_D';
CREATE EXTERNAL TABLE `TW_MAC_STAT_D`(
`MID` int,
`MAC_NM` string,
`PRDCT_TYPE` string,
`STORE_NM` int,
`BUS_MODE` string,
`PAY_SW` string,
`SCENCE_CATGY` string,
`SUB_SCENCE_CATGY` string,
`SCENE` string,
`SUB_SCENE` string,
`BRND` string,
`SUB_BRND` string,
`PRVC` string,
`CTY` string,
`AREA` string,
`AGE_ID` string,
`INV_RATE` string,
`AGE_RATE` string,
`COM_RATE` string,
`PAR_RATE` string,
`PKG_ID` string,
`PAY_TYPE` string,
`CNSM_USR_CNT` string,
`REF_USR_CNT` string,
`NEW_USR_CNT` string,
`REV_ORDR_CNT` string,
`REF_ORDR_CNT` string,
`TOT_REV` string,
`TOT_REF` string
)
PARTITIONED BY (data_dt string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\\t'
LOCATION 'hdfs://mycluster/user/hive/warehouse/data/machine/TW_MAC_STAT_D';
CREATE EXTERNAL TABLE `TM_USR_MRCHNT_STAT_D`(
`ADMIN_ID` string,
`PAY_TYPE` int,
`REV_ORDR_CNT` int,
`REF_ORDR_CNT` int,
`TOT_REV` double,
`TOT_REF` double,
`TOT_INV_REV` DECIMAL(10,2),
`TOT_AGE_REV` DECIMAL(10,2),
`TOT_COM_REV` DECIMAL(10,2),
`TOT_PAR_REV` DECIMAL(10,2)
)
PARTITIONED BY (DATA_DT string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\\t'
LOCATION 'hdfs://mycluster/user/hive/warehouse/data/user/TM_USR_MRCHNT_STAT_D';
4、向MySQL中导入对应库的数据
向MySQL中导入ycak 与ycbk两个库数据。
5、准备ODS层导入数据脚本:
#在安装SQOOP的node3节点/root/test下,上传导入数据脚本
ods_mysqltohive_to_ycak_cnsm_d.sh
ods_mysqltohive_to_ycak_mac_d.sh
ods_mysqltohive_to_ycak_mac_loc_d.sh
ods_mysqltohive_to_ycak_usr_ali_d.sh
ods_mysqltohive_to_ycak_usr_app_d.sh
ods_mysqltohive_to_ycak_usr_d.sh
ods_mysqltohive_to_ycak_usr_loc_d.sh
ods_mysqltohive_to_ycak_usr_login_d.sh
ods_mysqltohive_to_ycak_usr_qq_d.sh
ods_mysqltohive_to_ycbk_area_d.sh
ods_mysqltohive_to_ycbk_city_d.sh
ods_mysqltohive_to_ycbk_mac_admin_map_d.sh
ods_mysqltohive_to_ycbk_mac_store_map_d.sh
ods_mysqltohive_to_ycbk_prvc_d.sh
ods_mysqltohive_to_ycbk_store_d.sh6、将项目代码打包上传
将项目代码中本地执行改成集群执行,打包上传到node4节点/root/test下
7、准备执行的任务脚本
#在node5节点/root/test下上传执行任务脚本
produce1.sh
produce2.sh
produce3.sh
produce4.sh
produce5.sh
produce6.sh8、启动Azkaban
#启动Azkaban-Executor
/software/azkaban/azkaban-exec-server/bin/start-exec.sh
#激活Azkaban Executor
http://node5:12321/executor?action=activate
#启动Azkaban-Server
/software/azkaban/azkaban-web-server/bin/start-web.sh
#访问Azkaban user:azkaban pwd:azkaban
http://node5:8081/
9、编写Azkaban job 并打包,提交到Azkaban执行:

二、ODS层数据质量监控
由于ODS层数据是贴源层,是数仓开始的地方,所以这里检验时一般不需要验证与原始数据条目是否相同,在ODS层数据质量监控中一般验证当日导入数据的记录数、当日导入表中关注字段为空的记录数、当日导入数据关注字段重复记录数、全表总记录数指标即可。
1、在Hive中创建存储数据质量监控数据库“data_quality”
hive> create database data_quality;2、创建存储ODS层数据质量监控数据表“check_ods_info”
create table data_quality.check_ods_info(
dt String comment '执行日期',
db String comment '数据库名称',
tbl String comment '校验表名',
tbl_type string comment '增量导入/全量导入',
check_col String comment '校验为空的列名',
current_dt_rowcnt bigint comment '当日导入数据记录数',
check_null_rowcnt bigint comment '当日检查列为空的记录数',
duplication_rowcnt bigint comment '重复记录数',
total_rowcnt bigint comment '表总记录数'
) row format delimited fields terminated by '\\t';注意以上中文注释在Hive中不支持,可以在Hive的mysql元数据对应的库中执行如下SQL支持中文显示:
alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;
alter table TABLE_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
alter table PARTITION_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
alter table PARTITION_KEYS modify column PKEY_COMMENT varchar(4000) character set utf8;
alter table INDEX_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;3、编写数据校验脚本
ods数据质量校验脚本名称为:“ods_data_check.sh”编写的脚本需要传入5个参数:校验数据日期、Hive库名、校验表名、是否增量(1代表增量,2代表全量)、校验为空的字段。脚本内容如下:
#!/bin/bash
# 数据检查执行的日期
current_dt=$1
# 校验数据的库名
db_name=$2
# 校验数据的表名
table_name=$3
# 表增量导入/全量导入 1-增量 2-全量
is_increment=$4
# 需要校验为空的列名,以逗号隔开
check_col=$5
# 切割列,获取数组
array=($check_col//,/ )
#where sql
where_sql=""
#动态拼接SQL where 条件
for((i=0;i<$#array[@];i++))
do
if [ $i -eq 0 ];
then
where_sql=" where $array[i] is null"
else
where_sql="$where_sql or $array[i] is null"
fi
done
#判断全量或增量来区分处理SQL
if [ $is_increment -eq 1 ];
then
is_increment='increment'
#HQL获取当日增量导入数据的记录数据
current_dt_rowcnt=`hive -e "select count(*) from $table_name where data_dt = '$current_dt'"`
check_null_rowcnt=`hive -e "select count(*) from $table_name $where_sql and data_dt = '$current_dt'"`
duplication_rowcnt=`hive -e "select nvl(sum(tmp.cnt),0) from (select count(*) as cnt from $table_name where data_dt = '$current_dt' group by $check_col having count(*) >1) tmp"`
else
is_increment='all'
#HQL获取当日增量导入数据的记录数据
current_dt_rowcnt=`hive -e "select count(*) from $table_name"`
check_null_rowcnt=`hive -e "select count(*) from $table_name $where_sql"`
duplication_rowcnt=`hive -e "select nvl(sum(tmp.cnt),0) from (select count(*) as cnt from $table_name group by $check_col having count(*) >1) tmp"`
fi
# HQL获取全表总记录数
total_cnt=`hive -e "select count(*) from $table_name"`
echo "日期:$current_dt ,库名:$db_name,表名:$table_name,是否增量:$is_increment, 需要校验的列:$check_col"
echo "当日导入数据记录数:$current_dt_rowcnt,当日检查列为空的记录数:$check_null_rowcnt,当日导入数据重复数:$duplication_rowcnt ,表总记录数:$total_cnt"
#将数据结果插入到 data_quality.check_ods_info 表中
`hive -e "insert into data_quality.check_ods_info values ('$current_dt','$db_name','$table_name','$is_increment','$check_col',$current_dt_rowcnt,$check_null_rowcnt,$duplication_rowcnt,$total_cnt)"`
echo "------ finish ------"
4、使用以上脚本对ODS部分表数据进行校验
#这里对ODS层部分增量表和全量表进行校验,部分表如下
#TO_YCAK_USR_LOC_D :用户位置记录日增量表 【增量导入】
#TO_YCAK_CNSM_D :机器消费订单明细增量表 【增量导入】
#TO_YCAK_MAC_D :机器基本信息日全量表 【全量导入】
#TO_YCAK_MAC_LOC_D :机器位置信息日全量表 【全量导入】
# 命令如下:
sh /root/test/ods_data_check.sh 20210315 default TO_YCAK_USR_LOC_D 1 UID,MID
sh /root/test/ods_data_check.sh 20210315 default TO_YCAK_CNSM_D 1 MID,PRDCD_TYPE,PAY_TYPE,ORDR_ID,UID
sh /root/test/ods_data_check.sh 20210315 default TO_YCAK_MAC_D 2 MID,SRL_ID
sh /root/test/ods_data_check.sh 20210315 default TO_YCAK_MAC_LOC_D 2 MID,PRVC,CTY5、查看ODS层校验结果
#登录Hive ,切换data_quality库,查询数据
select * from check_ods_info;
三、EDS层数据质量监控
EDS层相当于数据仓库中的DW层,DW层详细划分又分为DWD、DWS层,此业务中也有DWD和DWS层数据,只是在EDS层中没有详细区分,在EDS层中具体哪些是DWD层与DWS层数据可以参照数据分层图。
EDS层质量校验分为对DWD层数据质量进行校验,对DWS层数据质量进行校验两个方面。对DWD层数据质量校验关注点在于是否与ODS层对应的数据来源表数据记录数是否一致、导入到DWD层的数据有效比例等,针对不同的DWD层的数据表也可以根据具体业务来决定质量检验的内容。
由于DWS层数据基于DWD层数据进行了聚合,所以对于DWS层数据质量校验关注点可以放在数据条目是否和上一层一致(需要分清主题重要字段),更重要的是这里检验DWS层表中数据总条数,某些重要字段为空的记录数,关注的聚合字段值异常条数等。针对不同的DWS层的数据表也可以根据具体业务来决定质量检验的内容。
以上EDS层中各层数据质量校验具体校验的内容一般根据业务不同是不同的,不能抛开业务来谈数据质量,可以使用具体脚本个性化校验。
1、DWD层数据质量校验
这里DWD层数据质量校验以“机器详细信息统计”业务为例,来说明DWD层数据质量如何校验。“机器详细信息统计”分层信息如下:

以上ODS层机器数据到EDS层机器数据,是由ODS层多张表数据“TO_YACK_MAC_D”、“TO_YCBK_MAC_ADMIN_MAP_D”合并统计得到EDS层“TW_MAC_BASEINFO_D”表数据,基于以上我们可以校验以下几个方面来确定数据质量:
- ODS层源表记录总数
- EDS层目标表记录总数
- 数据记录有效比例(由于EDS层数据一定来自于ODS层,可能中间会有清洗数据,导致EDS层数据缺少一部分,所以这里记录有效比例就是使用“目标表数据总记录/源表数据总记录”来反应质量情况)
- 目标表重复记录数(可能会由于ODS转到EDS层过程中,业务上关联其他表查询导致目标表数据会有重复)
基于以上方面,进行EDS-DWD层数据质量监控,步骤如下:
1)创建DWD数据质量结果存储表
create table data_quality.check_dwd_info(
dt String comment '执行日期',
db String comment '数据库名称',
check_cols String comment '校验字段',
source_tbl String comment 'ODS层源表表名',
source_tbl_rowcnt bigint comment '源表数据总记录数',
target_tbl String comment 'DWD层目标表表名',
target_tbl_rowcnt bigint comment '目标表数据总记录数',
rt Decimal(5,2) comment '数据有效比例',
target_duplication_rowcnt bigint comment '目标表数据重复记录数'
) row format delimited fields terminated by '\\t';2)编写DWD层数据校验脚本
DWD层数据质量校验脚本名称为:“dwd_data_check.sh”编写的脚本需要传入5个参数:校验数据日期、Hive库名、校验字段、ODS层数据源表(可能多张)、EDS层目标表。脚本内容如下:
#!/bin/bash
# 数据检查执行的日期
current_dt=$1
# 校验数据的库名
db_name=$2
# 校验字段,多个字段使用逗号隔开
check_cols=$3
# ODS层源表表名,多表用逗号隔开
ods_tbls=$4
# DWD层目标表表名
target_tbl=$5
# 切割多个源表,查询源表关注字段的总条数
tbl_arr=($ods_tbls//,/ )
# 查询源表数据SQL
source_sql=""
# 动态拼接SQL union 各个源表数据
for((i=0;i<$#tbl_arr[@];i++))
do
if [ $i -eq 0 ];
then
source_sql="select $check_cols from $tbl_arr[i] "
else
source_sql="$source_sql union all select $check_cols from $tbl_arr[i] "
fi
done
# 查询SQL 获取源表关注字段总条数
source_tbl_rowcnt=`hive -e "select count(*) from ( $source_sql ) t1"`
# 查询SQL 获取目标表关注字段总条数
target_tbl_rowcnt=`hive -e "select count(*) from (select $check_cols from $target_tbl) t2"`
# 统计目标表与源表数据比例
rt=`awk 'BEGINprintf "%0.2f",'$target_tbl_rowcnt'/'$source_tbl_rowcnt''`
# 查询SQL 统计目标表数据重复记录数
target_duplication_rowcnt=`hive -e "select nvl(sum(tmp.cnt),0) from (select count(*) as cnt from $target_tbl where data_dt = '$current_dt' group by $check_cols having count(*) >1) tmp"`
echo "日期:$current_dt ,库名:$db_name,ODS源表表名:$ods_tbls,目标表表名:$target_tbl, 需要校验的列:$check_cols"
echo "源表数据记录总数:$source_tbl_rowcnt,目标表记录数:$target_tbl_rowcnt,目标表与源表数据比例:$rt ,目标表重复记录数:$target_duplication_rowcnt"
#将数据结果插入到 data_quality.check_dwd_info 表中
`hive -e "insert into data_quality.check_dwd_info values ('$current_dt','$db_name','$check_cols','$ods_tbls',$source_tbl_rowcnt,'$target_tbl',$target_tbl_rowcnt,$rt,$target_duplication_rowcnt)"`
echo "------ finish ------"3)使用以上脚本对EDS-DWD层数据部分表进行校验
#这里针对“机器详情统计”业务对应的ODS-EDS层的表进行校验,命令如下:
sh dwd_data_check.sh 20210315 default mid TO_YCAK_MAC_D,TO_YCBK_MAC_ADMIN_MAP_D TW_MAC_BASEINFO_D
#此外,针对“消费退款统计”业务可执行校验,命令如下:
sh dwd_data_check.sh 20210315 default MID,PRDCD_TYPE TO_YCAK_CNSM_D TW_CNSM_BRIEF_D4)查看结果
#登录Hive ,切换data_quality库,查询数据
select * from check_dwd_info;
2、DWS层数据质量校验
DWS层数据质量校验,这里校验“机器详情信息”业务中,EDS-DWS层表“TW_MAC_STAT_D”表的质量,这里由于DWS层数据由EDS层聚合而来组成的宽表,所以,这里校验时可以校验主题数据是否和上层一致,更重要的是校验DWS层表中数据总条数,某些重要字段为空的记录数,关注的聚合字段值异常条数等。
这里针对“TW_MAC_STAT_D”表我们校验表中以下内容:
- 表中数据总记录数
- 省份、城市字段为空的记录数
- 总营收不合理记录数
校验步骤如下:
1)创建DWS层校验结果存放表
create table data_quality.check_dws_info(
dt String comment '执行日期',
db String comment '数据库名称',
target_tbl string comment '校验表名',
check_null_cols String comment '校验空值字段',
null_row_cnt bigint comment '当日空值字段记录数',
check_value_cols String comment '校验值字段',
maxValue Decimal(10,2) comment '合理值最大值',
abnormal_rowcnt bigint comment '当日异常值记录数',
total_rowcnt bigint comment '当日表中总记录数'
) row format delimited fields terminated by '\\t';2)编写校验脚本
DWS层数据质量校验脚本名称为:“dws_data_check.sh”编写的脚本需要传入5个参数:校验数据日期、Hive库名、校验表名、校验Null值字段(可多列)、校验值字段(单列),标准值最大值。脚本内容如下:
#!/bin/bash
# 数据检查执行的日期
current_dt=$1
# 校验数据的库名
db_name=$2
# 校验表名
dws_tbl_name=$3
# 校验null值字段,多个字段使用逗号隔开
check_null_cols=$4
echo "$check_null_cols"
# 校验值字段
check_value_col=$5
# 标准值的最大值
max_value=$6
# 切割校验null值字段
array=($check_null_cols//,/ )
# 查询DWS表数据SQL
check_sql=""
# 动态拼接SQL 检查null值条数
for((i=0;i<$#array[@];i++))
do
if [ $i -eq 0 ];
then
check_sql="select count(*) from $db_name.$dws_tbl_name where data_dt=$current_dt and $array[i] is null "
else
check_sql="$check_sql and $array[i] is null "
fi
done
# 查询SQL 获取DWS表中空值数据记录数
null_row_cnt=`hive -e "$check_sql"`
# 查询SQL 获取校验值异常记录数
abnormal_rowcnt=`hive -e "select sum(if($check_value_col>$max_value,1,0)) from $db_name.$dws_tbl_name where data_dt = $current_dt"`
# 统计当前日期下表中统计总记录数
total_rowcnt=`hive -e "select count(*) from $db_name.$dws_tbl_name where data_dt = $current_dt"`
echo "日期:$current_dt ,库名:$db_name,DWS校验表名:$dws_tbl_name,需要校验为null的列:$check_null_cols,检验值是否合理的列:$check_value_col,合理值最大值:$max_value"
echo "当日空值字段记录数:$null_row_cnt,当日异常值记录数:$abnormal_rowcnt,当日表数据总记录数:$total_rowcnt"
#将数据结果插入到 data_quality.check_dws_info 表中
`hive -e "insert into data_quality.check_dws_info values ('$current_dt','$db_name','$dws_tbl_name','$check_null_cols',$null_row_cnt,'$check_value_col',$max_value,$abnormal_rowcnt,$total_rowcnt)"`
echo "------ finish ------"3)使用以上脚本对EDS-DWS数据进行校验
#对 EDS-DWS层数据表“TW_MAC_STAT_D”进行校验
sh dws_data_check.sh 20210315 default TW_MAC_STAT_D PRVC,CTY TOT_REV 100004)查看结果数据
#登录Hive ,切换data_quality库,查询数据
select * from check_dws_info;
四、DM层数据质量监控
DM层存放数仓中对宽表进行聚合统计得到的结果值数据,所以这里对DM层数据进行质量校验时,无法使用通用的脚本处理,而是每个报表数据都要不同的校验指标,DM层主要校验数据值是否在合理范围内,与DWS层校验类似,这里不再校验“商户营收统计”业务中DM层表“TM_USR_MRCHNT_STAT_D”。
- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢大数据系列文章会每天更新,停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨
以上是关于数据治理:数据仓库数据质量管理的主要内容,如果未能解决你的问题,请参考以下文章