ios 原子属性atomic加锁性能与锁对比, 不推荐的原因
Posted 想名真难
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ios 原子属性atomic加锁性能与锁对比, 不推荐的原因相关的知识,希望对你有一定的参考价值。
在设置属性的时候, 我们都会写上nonatomic, 基本没有写过atomic, 苹果建议这么做, 因为atomic严重影响了性能.
但是atomic影响了多少? 如果一个属性真的需要在多线程下读写, 那么使用atomic和其他锁之间的性能差多少?
atomic的底层实现只是在 setter 和 getter 方法中加了一个锁, 这个锁是一个自旋锁, 对,就是苹果不推荐的自旋锁spinlock_t.
写下测试代码测试100W次, 让atomic和信号量 | unfair_lock | NSLock | synchronized 进行PK, 看看到底那个的效率更高.
最终结果, 按照升序排列后, 可以看到 原子性的效率最高, 然后是unfair_lock, 而 synchronized 果然是效率最低, 处于鄙视链的底端.
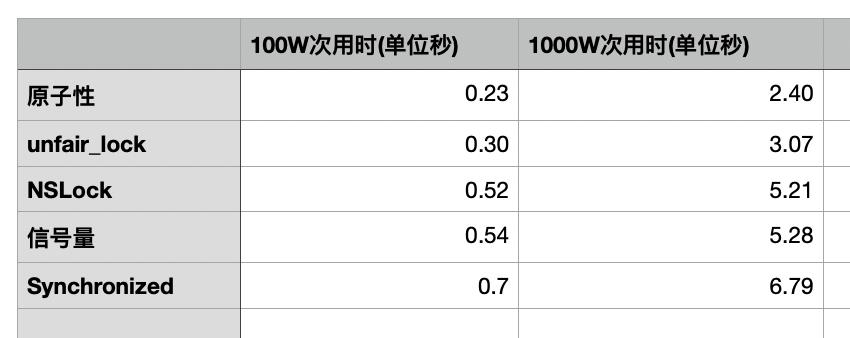
还是用图更直观的感受,
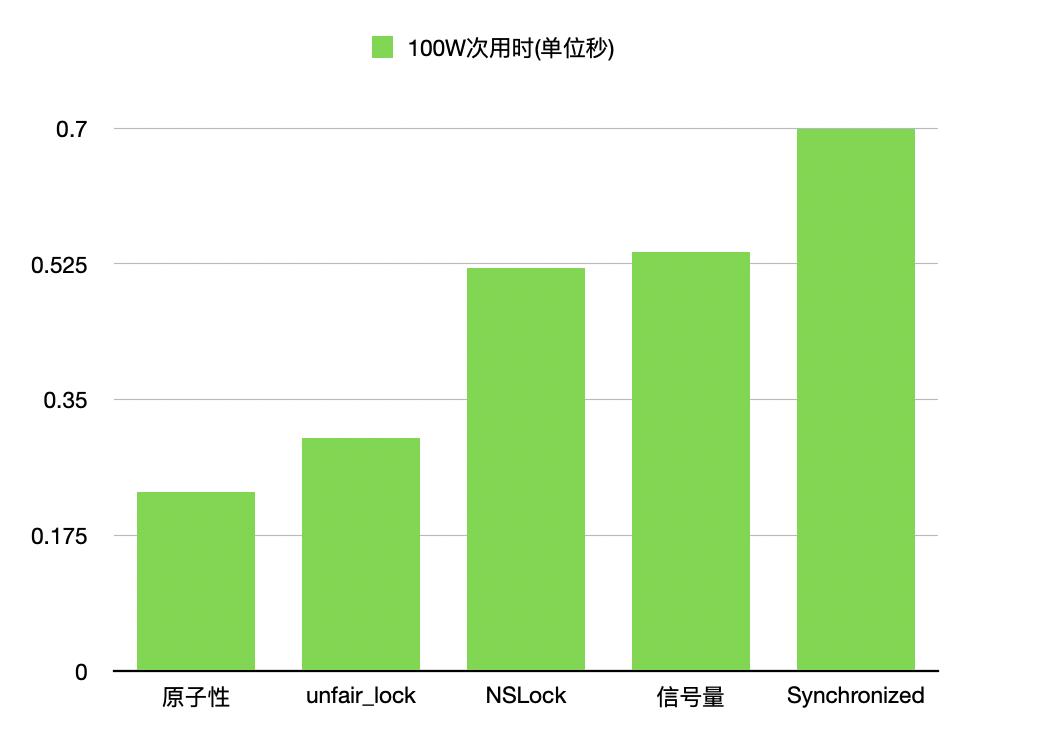
单独来看, atomic的加锁效率是很高的啊, 为什么苹果不推荐使用atomic了? 个人总结为以下3点 ,更详细的原因和原理参考 : ios 原子属性nonatomic/atomic
- 系统用一个全局生效的字典保存属性值与自旋锁的对应关系, 系统最多提供8个自旋锁给atomic加锁解锁, 当一个项目中有几万个属性都是原子性的时候, 几万映射到8个锁上, 很多属性都会对应到同一把锁上, 那么这个属性就得等其他毫不相关的属性完成读写, 自己才能进行操作, 而且set/get是一个特别高频的操作.
- atomic使用的是自旋锁, 自旋锁的特点是忙等待, 当有几万的属性对应到8把锁上, 忙等待就是一个非常常见的状态, 忙等待对cpu的消耗很大, 手机发烫, 效率变低, 而且这样的忙等待是无意义的.
- atomic只针对特定场景保证线程安全, 存在局限性. 只能保证set/get的线程安全, 对于更大范围的线程安全是无法保证的.
举一个很简单的例子,假设定义属性 NSInteger i 是原子的,对i进行 i = i + 1;
这个操作就是不安全的。因为原子性只能保证读写安全,而该表达式需要三步操作:
1.先进行get, 读取i的值存入寄存器;
2.将寄存器的值加1;
3.使用寄存器修改后的值给i赋值;
atomic只能保证1和3是线程安全的, 如果在第1步完成的时候,i被其他线程修改了,那么表达式执行的结果就会与预期的不一样,也就是不安全的。所以要解决这样的线程安全问题, 只能对 整个表达式进行加锁, 单纯对i 设置atomic达不到预期的.
综上3点, atomic在大范围使用的情况下效率低下, 而且效果不太好, 存在局限性, 所以苹果把线程安全的责任交给了开发者, 由开发者来保证线程安全.
经常看到网上有对比加锁/解锁效率,这次我也借这个机会简单对比下, 加锁解锁1000W次, 数据如下
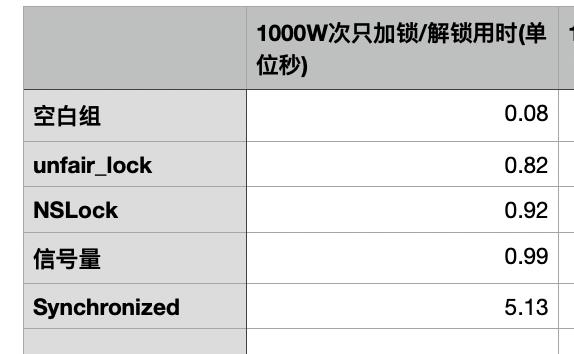
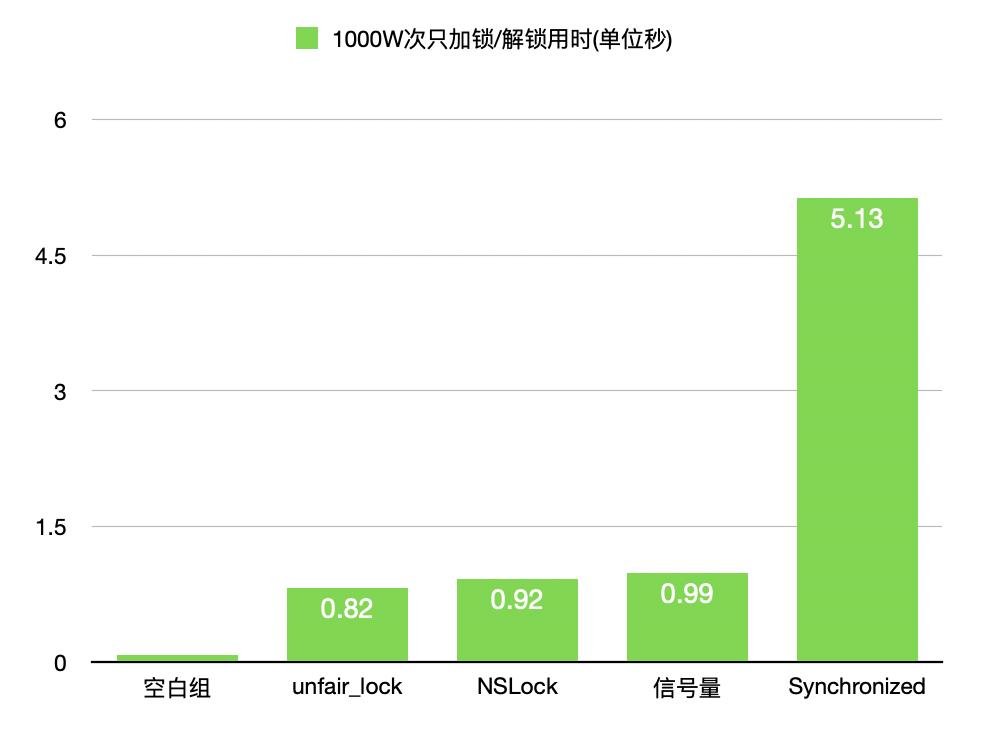
最后, 本次测试使用设备为iPhone 6S, 系统为ios 14.0, 下面是测试的代码
#import "ViewController.h"
@import Darwin.os.lock;
// 循环1000W次
static const NSInteger TestCount = 10000 * 1000;
@interface ViewController ()
// 使用原子性的锁
@property (atomic, strong) NSObject *obj_atomic;
// 外界加锁
@property (nonatomic, strong) NSObject *obj_nonatomic;
@end
@implementation ViewController
- (void)viewDidLoad
[super viewDidLoad];
CFTimeInterval start = 0;
CFTimeInterval end = 0;
// 原子性加锁解锁100W次,耗时:0.23S
start = CACurrentMediaTime();
[self testAtomic];
end = CACurrentMediaTime();
NSLog(@"原子性加锁解锁%zd次,耗时:%.2lfS",TestCount,end-start);
// 信号量加锁解锁100W次,耗时:0.54S
start = CACurrentMediaTime();
[self testSemaphore];
end = CACurrentMediaTime();
NSLog(@"信号量加锁解锁%zd次,耗时:%.2lfS",TestCount,end-start);
// NSLock加锁解锁100W次,耗时:0.52S
start = CACurrentMediaTime();
[self testLock];
end = CACurrentMediaTime();
NSLog(@"NSLock加锁解锁%zd次,耗时:%.2lfS",TestCount,end-start);
// UnfairLock加锁解锁100W次,耗时:0.30S
start = CACurrentMediaTime();
[self testUnfairLock];
end = CACurrentMediaTime();
NSLog(@"UnfairLock加锁解锁%zd次,耗时:%.2lfS",TestCount,end-start);
// Synchronized加锁解锁100W次,耗时:0.70S
start = CACurrentMediaTime();
[self testSynchronized];
end = CACurrentMediaTime();
NSLog(@"Synchronized加锁解锁%zd次,耗时:%.2lfS",TestCount,end-start);
- (void)testAtomic
for (NSInteger i = 0; i < TestCount; i++)
self.obj_atomic = [[NSObject alloc] init];
for (NSInteger i = 0; i < TestCount; i++)
[self.obj_atomic class];
- (void)testSemaphore
dispatch_semaphore_t sem = dispatch_semaphore_create(1);
for (NSInteger i = 0; i < TestCount; i++)
dispatch_semaphore_wait(sem, DISPATCH_TIME_FOREVER);
self.obj_nonatomic = [[NSObject alloc] init];
dispatch_semaphore_signal(sem);
for (NSInteger i = 0; i < TestCount; i++)
dispatch_semaphore_wait(sem, DISPATCH_TIME_FOREVER);
[self.obj_nonatomic class];
dispatch_semaphore_signal(sem);
- (void)testLock
NSLock *lock = [[NSLock alloc] init];
for (NSInteger i = 0; i < TestCount; i++)
[lock lock];
self.obj_nonatomic = [[NSObject alloc] init];
[lock unlock];
for (NSInteger i = 0; i < TestCount; i++)
[lock lock];
[self.obj_nonatomic class];
[lock unlock];
- (void)testUnfairLock
os_unfair_lock_t unfair_lock = &(OS_UNFAIR_LOCK_INIT);
for (NSInteger i = 0; i < TestCount; i++)
os_unfair_lock_lock(unfair_lock);
self.obj_nonatomic = [[NSObject alloc] init];
os_unfair_lock_unlock(unfair_lock);
for (NSInteger i = 0; i < TestCount; i++)
os_unfair_lock_lock(unfair_lock);
[self.obj_nonatomic class];
os_unfair_lock_unlock(unfair_lock);
- (void)testSynchronized
for (NSInteger i = 0; i < TestCount; i++)
@synchronized (self)
self.obj_nonatomic = [[NSObject alloc] init];
for (NSInteger i = 0; i < TestCount; i++)
@synchronized (self)
[self.obj_nonatomic class];
@end
以上是关于ios 原子属性atomic加锁性能与锁对比, 不推荐的原因的主要内容,如果未能解决你的问题,请参考以下文章