Kafka学习笔记
Posted Mr.杨先森
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka学习笔记相关的知识,希望对你有一定的参考价值。
缓存区好处:
- 解耦
- 冗余
- 扩展性
- 灵活性、峰值处理能力
- 可恢复性
- 顺序保证
- 缓冲
- 异步通信
数据单元
- 保证数据单元的完整性
- 各个数据单元没有互相依赖保证了数据单元的独立性
- 颗粒度
Broker (数据节点)
Kafka 集群包含一个或多个服务器,服务器节点为broker
Topic(主题)
每条发布到kafuka集群的消息都有一个类别,这个类别被称为Topic。

Partition
1.Topic 中的数据分割为一个或者多个partition
2.每个topic至少有一个partition,当生产者产生数据的时候,根据分配策略,选择分区,然后将消息追加到指定的分区的末尾(队列)

Leader
每个partition有多个副本,其中有且仅有一个作为Leader,Leader是当前负责数据的读写的partition。
Follower(主)
Follower跟随Leader,所有写请求通过Leader路由,数据变更会广播给所有的Follower,Follower与Leader保持数据同步。
Replication(从)
1.数据会存放到topic的partation中,但是有可能分区会损坏
2.我们需要对分区的数据进行备份
3.我们将分区的分为Leader(1)和Follower(N)
i:Leader负责写入和读取数据
Ii:Follower 只负责备份
iv:保证了数据的一致性
Producer
1.生产者即数据的发布者,该角色将消息发布到kafka的topic中
2.Broker接收到生产者发送的消息后,broker将该消息追加到当前用于追加数据的segment文件中;
3.生产者发送的消息,存储到一个partition中,生产者也可以指定数据存储的partition
Consumer
消费者可以从broker中读取数据,消费者可以消费多个topic中的数据
Consumer group
- 每一个consumer属于一个特定的consumer group(可为每个Consumer指定group name,若不指定group name则属于默认的group)。
- 将多个消费者集中到一起去处理某一个Topic的数据,可以更快的提高数据的消费能力;
- 整个消费者组共享一组偏移量(防止数据被重复读取)因为一个Topic有多个分区
Offset (偏移量)
1.可以唯一的标识一条消息
2.偏移量决定读取数据的位置,不会有线程安全的问题,消费者通过偏移量来决定下次读取的消息
3.消息被消费之后,并不被马上删除,这样多个业务就可以重复使用kafka的消息
4.我们某一个业务也可以通过修改偏移量达到重新读取消息的目的,偏移量由用户控制
5.消息最终还是会被删除的,默认生命周期为1周(7*24小时=168小时)
Zookeeper
Kafka通过zookeeper来存储集群的meta信息。
Kafka环境搭建
基于Zookeeper搭建并开启
- 验证ZK的可用性
- 命令:zkServer.sh start
配置kafka基本操作
-
上传解压拷贝并解压
Dos:tar - zxvf kafka.............tgz 解压压缩包
Mv kafka..... /路径 移除kafka文件夹
cd /opt/sxt/kafka...../进入卡夫卡所在路径
2. 修改配置文件
Dos: vim config/server.properties

3.修改环境变量

4. 将文件目录拷贝到其他机器
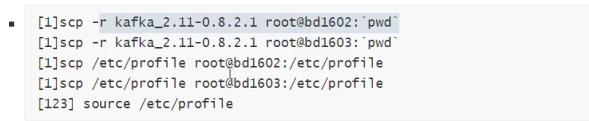
5. 修改其他机器上的配置

6. 启动集群

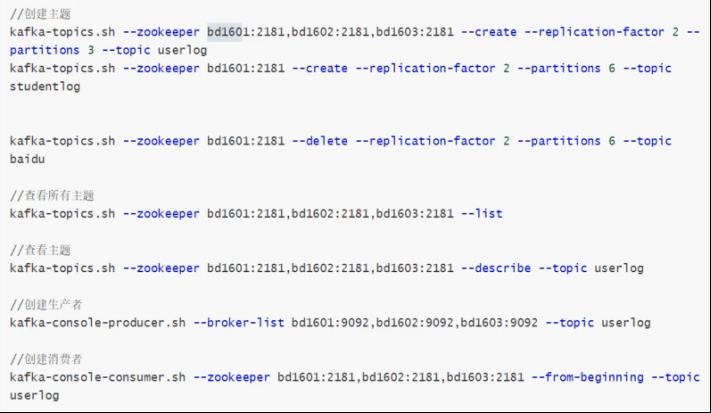
7. 常见命令
Kafka - ISR机制
Broker数据存储机制
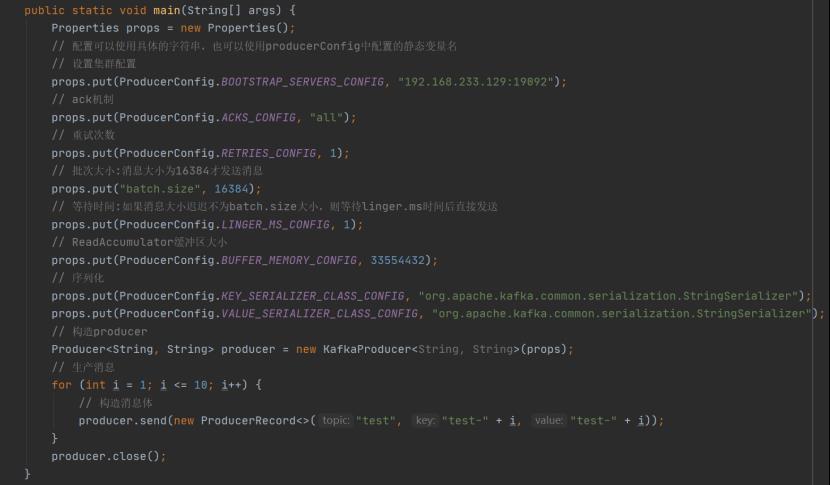
异步发送普通生产者代码操作实现
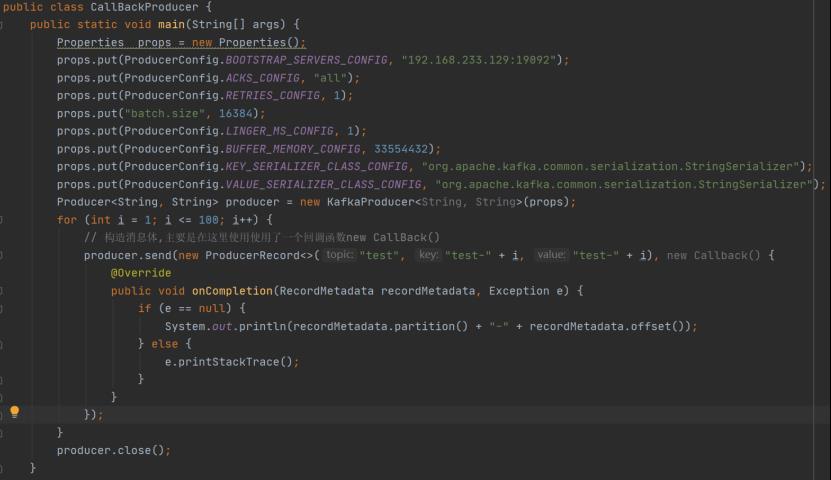
异步发送带回调函数的生产者
Spring Boot 集成kafka
一:yml配置
spring:
kafka:
bootstrap-servers: 192.168.1.108:9092,192.168.1.109:9092,192.168.1.110:9092 #指定kafka server的地址,集群配多个,中间,逗号隔开
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
consumer:
group-id: default_consumer_group #群组ID
#enable-auto-commit: true
#auto-commit-interval: 1000
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
server:
port: 8500
二、添加pom依赖
org.springframework.boot
spring-boot-starter-web
org.springframework.kafka
spring-kafka
com.google.code.gson
gson
三、注解使用:
@EnableKafka -- 配置类
Service 实现类上 批量接收需要声明工厂为batchFactory
@KafkaListener(topics = “”,groupId=””containerFactory = "batchFactory")
以上是关于Kafka学习笔记的主要内容,如果未能解决你的问题,请参考以下文章