Spark基础学习笔记18:掌握RDD分区
Posted howard2005
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark基础学习笔记18:掌握RDD分区相关的知识,希望对你有一定的参考价值。
文章目录
零、本讲学习目标
- 学会如何指定分区数量
- 会定义与使用自定义分区器
一、RRD分区
- RDD是一个大的数据集合,该集合被划分成多个子集合分布到了不同的节点上,而每一个子集合就称为分区(Partition)。因此,也可以说,RDD是由若干个分区组成的。
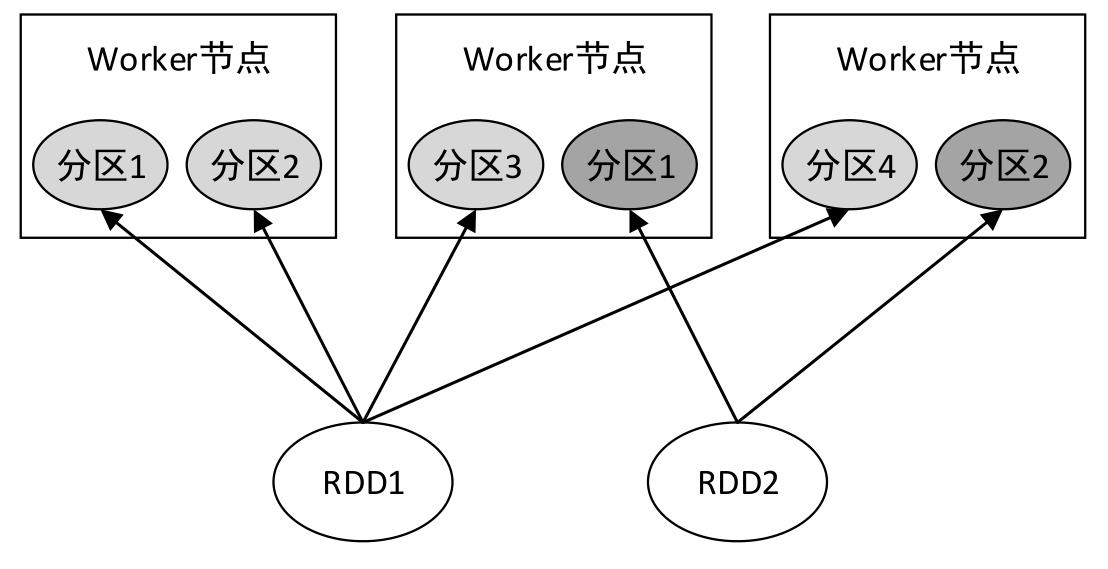
二、RDD分区数量
(一)RDD分区原则
- RDD各个分区中的数据可以并行计算,因此分区的数量决定了并行计算的粒度。Spark会给每一个分区分配一个单独的Task任务对其进行计算,因此并行Task的数量是由分区的数量决定的。RDD分区的一个分区原则是使得分区的数量尽量等于集群中CPU核心数量。
(二)影响分区的因素
- RDD的创建有两种方式:一种是使用parallelize()方法从对象集合创建;另一种是使用textFile()方法从外部存储系统创建。而RDD分区的数量与RDD的创建方式以及Spark集群的运行模式有关。
(三)使用parallelize()方法创建RDD时的分区数量
1、指定分区数量
- 使用parallelize()方法创建RDD时,可以传入第二个参数,指定分区数量。

- 分区的数量应尽量等于集群中所有CPU的核心总数,以便可以最大程度发挥CPU的性能。
- 利用
mapPartitionsWithIndex()函数实现带分区索引的映射

- 第1个分区完成了3个元素的映射,第2个分区完成了3个元素的映射,第3个分区完成了4个元素的映射
2、默认分区数量
- 若不指定分区数量,则默认分区数量为Spark配置文件spark-defaults.conf中的参数spark.default.parallelism的值。若没有配置该参数,则Spark会根据集群的运行模式自动确定分区数量。
- 如果是本地模式,默认分区数量就等于本机CPU核心总数,这样每个CPU核心处理一个分区的计算任务,可以最大程度发挥CPU的性能。
- 如果是Spark Standalone或Spark On YARN模式,默认分区数量就取集群中所有CPU的核心总数与2中的较大值,即最少分区数为2。
3、分区源码分析
parallelize()方法是在SparkContext类定义的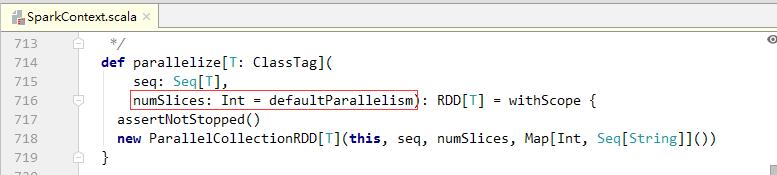
numSlices参数为指定的分区数量,该参数有一个默认值defaultParallelism,是一个无参函数

- 上述代码中的
taskScheduler的类型为特质TaskScheduler,通过调用该特质的defaultParallelism方法取得默认分区数量,而类TaskSchedulerImpl继承了特质TaskScheduler并实现了defaultParallelism方法。


- 上述代码中的
backend的类型为特质SchedulerBackend,通过调用该特质的defaultParallelism()方法取得默认分区数量,特质SchedulerBackend主要用于申请资源和对Task任务的执行和管理;而类LocalSchedulerBackend和类CoarseGrainedSchedulerBackend则继承了特质SchedulerBackend并分别实现了其中的defaultParallelism()方法。
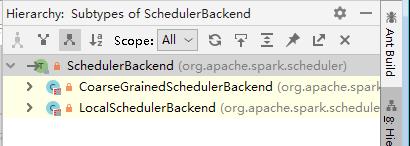
- 类LocalSchedulerBackend用于Spark的本地运行模式(Executor和Master等在同一个JVM中运行),其调用顺序在TaskSchedulerImpl类之后;类CoarseGrainedSchedulerBackend则用于Spark的集群运行模式。
- 类
LocalSchedulerBackend中的defaultParallelism()方法

- 上述代码中的字符串spark.default.parallelism为Spark配置文件spark-defaults.conf中的参数spark.default.parallelism;totalCores为本机CPU核心总数。
- 类
CoarseGrainedSchedulerBackend中的defaultParallelism()方法

- 上述代码中,
math.max(totalCoreCount.get(), 2)表示取集群中所有CPU核心总数与2两者中的较大值。
(四)使用textFile()方法创建RDD时的分区数量
- textFile()方法通常用于读取HDFS中的文本文件,使用该方法创建RDD时,Spark会对文件进行分片操作(类似于MapReduce的分片,实际上调用的是MapReduce的分片接口),分片操作完成后,每个分区将存储一个分片的数据,因此
分区的数量等于分片的数量。
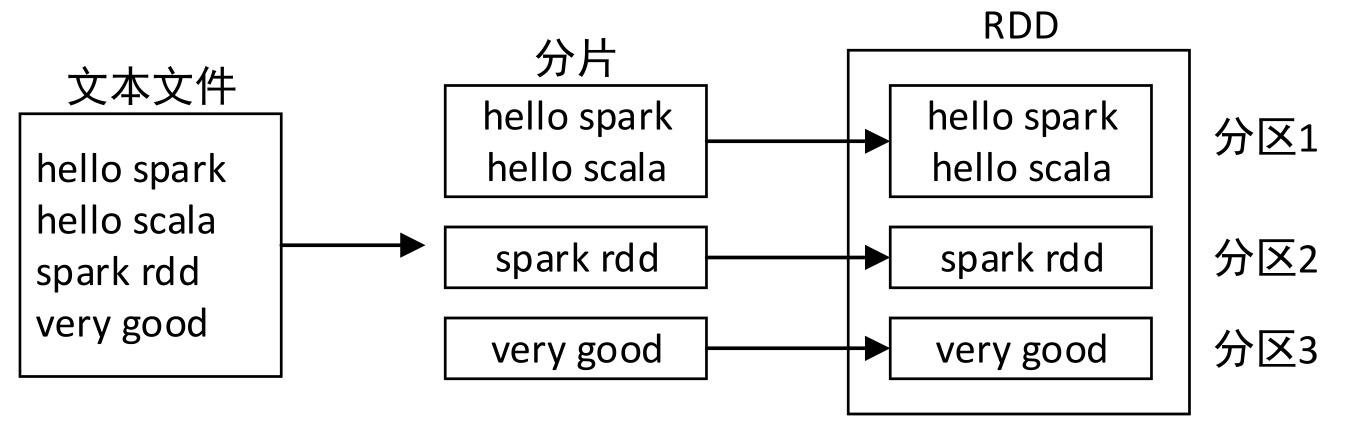
1、指定最小分区数量
- 使用textFile()方法创建RDD时可以传入第二个参数指定最小分区数量。最小分区数量只是
期望的数量,Spark会根据实际文件大小、文件块(Block)大小等情况确定最终分区数量。
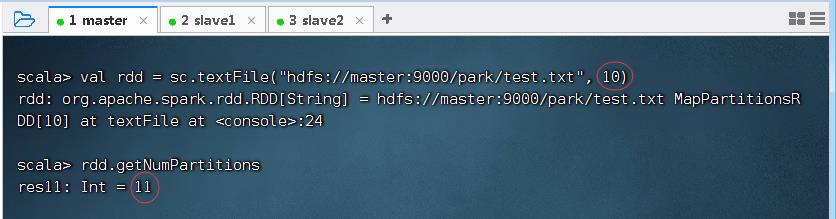
- 在HDFS中有一个文件
/park/test.txt,读取该文件,并指定最小分区数量为10,但是实际分区数量是11。
2、默认最小分区数量
- 若不指定最小分区数量,则Spark将采用默认规则计算默认最小分区数量。
- 查看textFile()源码
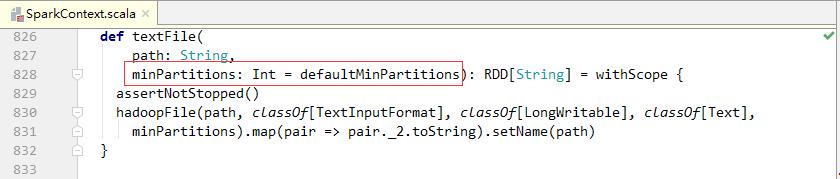
- 上述代码中的minPartitions参数为期望的最小分区数量,该参数有一个默认值defaultMinPartitions,这是一个无参函数,我们来查看其源码。

- 从上述代码中可以看出,默认最小分区数取默认并行度与2中的较小值;而默认并行度则是parallelize()方法的默认分区数。
3、默认实际分区数量
- 最小分区数量确定后,Spark接下来将计算实际分区数量。查看textFile()方法的源码可知,textFile()方法最后调用了一个hadoopFile()方法,并对该方法的结果执行了map()算子。

- 查看hadoopFile()方法的源码
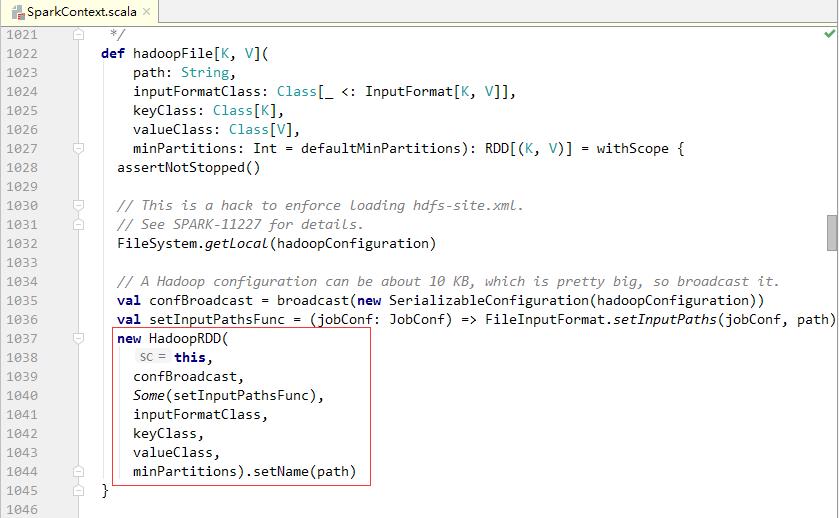
- 从上述代码可以看出,最终返回一个HadoopRDD对象。
- 查看HadoopRDD类的部分源码
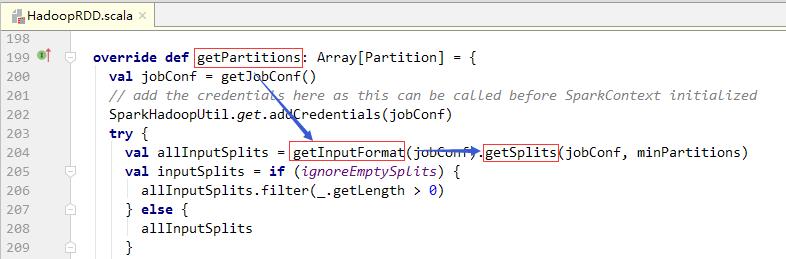
- HadoopRDD类中的
getPartitions()方法的功能是获取实际分区数量。通过调用getInputFormat()方法得到InputFormat的实例,然后调用该实例的getSplits()方法获得输入数据的所有分片,getSplits()方法是决定最终分区数量的关键方法,该方法的第二个参数即为RDD的最小分区数量。 - 查看
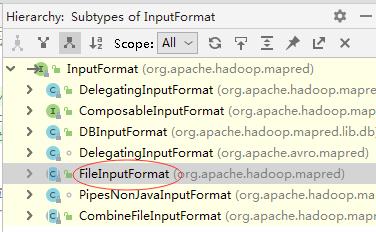
InputFormt接口getSplits()抽象方法

InputFormat有个实现类FileInputFormat,它实现了getSplits()方法
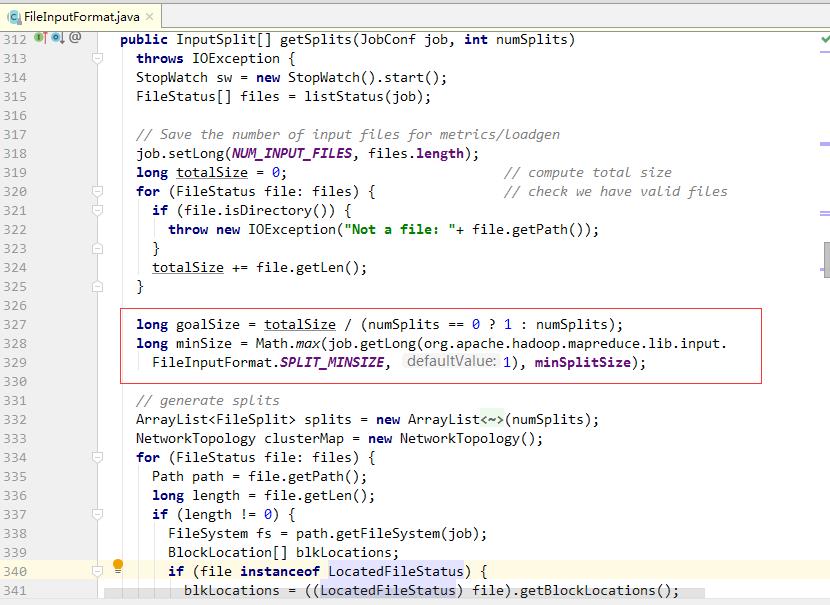
- 根据期望分片数量(numSplits,即最小分区数量)计算期望分片大小(goalSize)。计算实际分片大小(splitSize)。splitSize最终决定了分片的数量。
- splitSize由3个因素决定:最小分片大小(minSize)、期望分片大小(goalSize)、分块大小(blockSize)。
public InputSplit[] getSplits(JobConf job, int numSplits)
throws IOException
StopWatch sw = new StopWatch().start();
FileStatus[] files = listStatus(job);
// Save the number of input files for metrics/loadgen
job.setLong(NUM_INPUT_FILES, files.length);
long totalSize = 0; // compute total size
for (FileStatus file: files) // check we have valid files
if (file.isDirectory())
throw new IOException("Not a file: "+ file.getPath());
totalSize += file.getLen();
long goalSize = totalSize / (numSplits == 0 ? 1 : numSplits);
long minSize = Math.max(job.getLong(org.apache.hadoop.mapreduce.lib.input.
FileInputFormat.SPLIT_MINSIZE, 1), minSplitSize);
// generate splits
ArrayList<FileSplit> splits = new ArrayList<FileSplit>(numSplits);
NetworkTopology clusterMap = new NetworkTopology();
for (FileStatus file: files)
Path path = file.getPath();
long length = file.getLen();
if (length != 0)
FileSystem fs = path.getFileSystem(job);
BlockLocation[] blkLocations;
if (file instanceof LocatedFileStatus)
blkLocations = ((LocatedFileStatus) file).getBlockLocations();
else
blkLocations = fs.getFileBlockLocations(file, 0, length);
if (isSplitable(fs, path))
long blockSize = file.getBlockSize();
long splitSize = computeSplitSize(goalSize, minSize, blockSize);
long bytesRemaining = length;
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP)
String[][] splitHosts = getSplitHostsAndCachedHosts(blkLocations,
length-bytesRemaining, splitSize, clusterMap);
splits.add(makeSplit(path, length-bytesRemaining, splitSize,
splitHosts[0], splitHosts[1]));
bytesRemaining -= splitSize;
if (bytesRemaining != 0)
String[][] splitHosts = getSplitHostsAndCachedHosts(blkLocations, length
- bytesRemaining, bytesRemaining, clusterMap);
splits.add(makeSplit(path, length - bytesRemaining, bytesRemaining,
splitHosts[0], splitHosts[1]));
else
String[][] splitHosts = getSplitHostsAndCachedHosts(blkLocations,0,length,clusterMap);
splits.add(makeSplit(path, 0, length, splitHosts[0], splitHosts[1]));
else
//Create empty hosts array for zero length files
splits.add(makeSplit(path, 0, length, new String[0]));
sw.stop();
if (LOG.isDebugEnabled())
LOG.debug("Total # of splits generated by getSplits: " + splits.size()
+ ", TimeTaken: " + sw.now(TimeUnit.MILLISECONDS));
return splits.toArray(new FileSplit[splits.size()]);
- 结论:在MapReduce中,每个分片对应一个Map任务,多个Map任务以完全并行的方式处理;而在Spark中,每个分片对应一个分区,每个分区对应一个Task任务,多个Task任务以完全并行的方式处理。
三、Spark分区器
(一)分区器 - Partitioner抽象类
- Spark RDD的Shuffle过程与MapReduce类似,涉及数据重组和重新分区,且要求RDD的元素必须是(key, value)形式的。分区规则是由分区器(Partitioner)控制的,Spark的主要分区器是HashPartitioner和RangePartitioner,都继承了抽象类Partitioner。
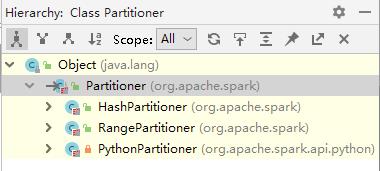
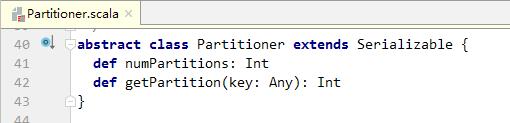
- 抽象类Partitioner中有两个方法,分别用于指定分区数量和设置分区规则
(二)哈希分区器 - HashPartitioner类
- HashPartitioner是Spark使用的默认分区器,其分区规则为:取(key,value)对中key的hashCode值,然后除以分区数量后取余数。若余数小于0(一般余数都大于等于0),则用余数与分区数量的和作为分区ID,否则将余数作为分区ID。分区ID一致的(key,value)对则会被分配到同一个分区。因此,默认情况下,key值相同的(key,value)对一定属于同一个分区,但是同一个分区中可能有多个key值不同的(key,value)对。该分区器还支持key值为null的情况,当key值等于null时,将直接返回0作为分区ID。
- HashPartitioner分区器中,对key取hashCode值实际上调用的是Java类Object中的hashCode()方法。由于Java数组的hashCode值基于的是数组标识,而不是数组内容,因此具有相同内容的数组的hashCode值不同。如果将数组作为RDD的key,就可能导致内容相同的key不能分配到同一个分区中。这个时候可以将数组转为集合,或者使用自定义分区器,根据数组内容进行分区。

四、自定义分区器
(一)提出问题
- 在有些情况下,使用Spark自带的分区器满足不了特定的需求。
- 例如,某学生有以下3科成绩数据:
| 科目 | 成绩 |
|---|---|
| chinese | 98 |
| math | 88 |
| english | 96 |
- 现需要将每一科成绩单独分配到一个分区中,然后将3科成绩输出到HDFS的指定目录(每个分区对应一个结果文件),此时就需要对数据进行自定义分区。
(二)解决问题
1、新建自定义分区器
- 创建
MyPartitioner类

package net.huawei.partition
import org.apache.spark.Partitioner
/**
* 功能:自定义分区器
* 作者:华卫
* 日期:2022年03月30日
*/
class MyPartitioner(partitions: Int) extends Partitioner
/**
* 取得分区数量
*
* @return 分区数量
*/
override def numPartitions: Int = partitions
/**
* 根据key取得分区ID
*
* @param key
* @return 分区ID
*/
override def getPartition(key: Any): Int =
val partitionId = key.toString match
case "chinese" => 0
case "math" => 1
case "english" => 2
partitionId
2、使用自定义分区器
- 调用RDD的partitionBy()方法传入自定义分区器类MyPartitioner的实例,可以对RDD按照自定义规则进行重新分区。
- 创建
TestMyPartitioner单例对象
package net.huawei.partition
import org.apache.spark.rdd.RDD
import org.apache.spark.SparkConf, SparkContext
/**
* 功能:测试自定义分区器
* 作者:华卫
* 日期:2022年03月30日
*/
object TestMyPartitioner
def main(args: Array[String]): Unit =
// 创建Spark配置对象
val conf = new SparkConf()
.setAppName("TestMyPartitioner")
.setMaster("spark://master:7077")
// 基于Spark配置创建Spark上下文
val sc = new SparkContext(conf)
// 构建模拟数据
val arr = Array(
"chinese,94",
"math,88",
"english,91"
)
// 将模拟数据转成RDD,再转成键值对形式的元组
val data: RDD[(String, Int)] = sc.makeRDD(arr).map(line =>
(line.split(",")(0), line.split(",")(1).toInt)
)
// 将数据重新分区并保存到HDFS的/output目录
data.partitionBy(new MyPartitioner(3))
.saveAsTextFile("hdfs://master:9000/output")
3、项目打包上传服务器
- 利用IDEA将项目打包 -
MyPartitioner.jar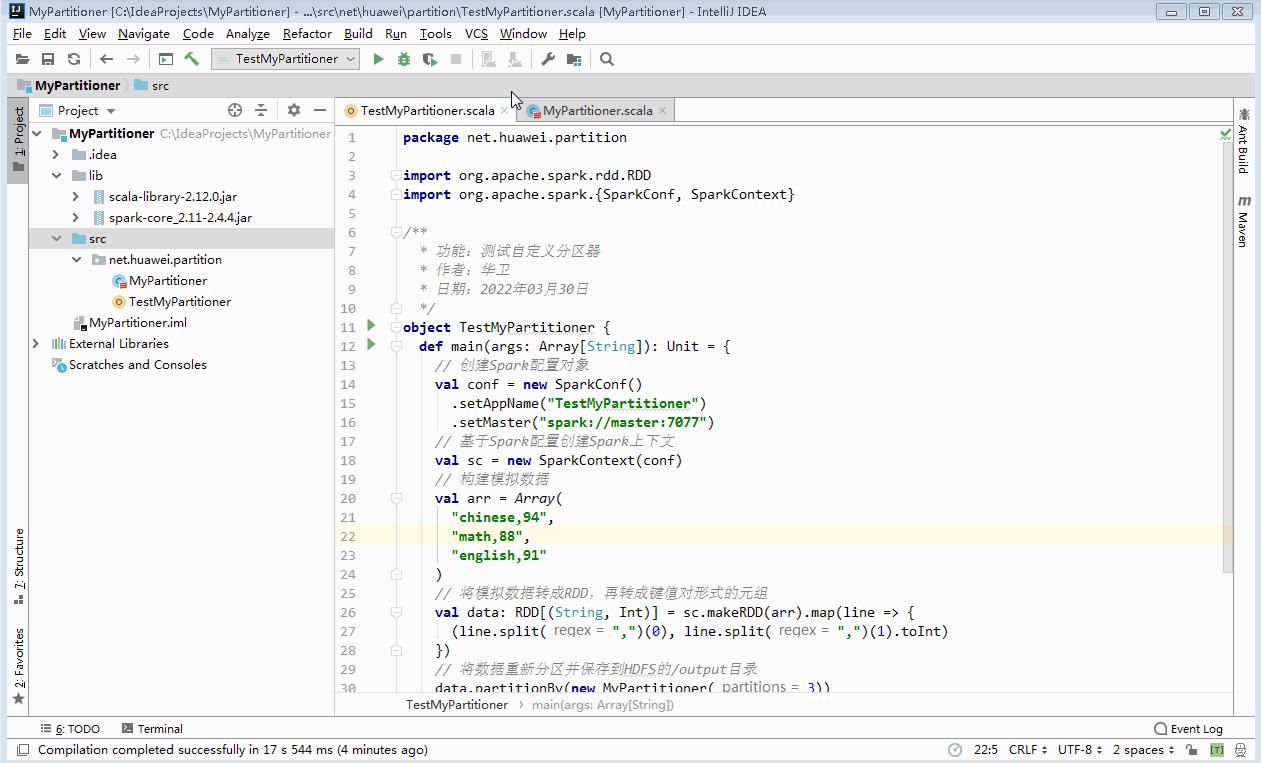

- 上传到Spark集群master节点的
/opt目录

4、提交程序运行
- 执行命令:
spark-submit --master spark://master:7077 --class net.huawei.partition.TestMyPartitioner /opt/MyPartitioner.jar

- 查看输出目录
/output
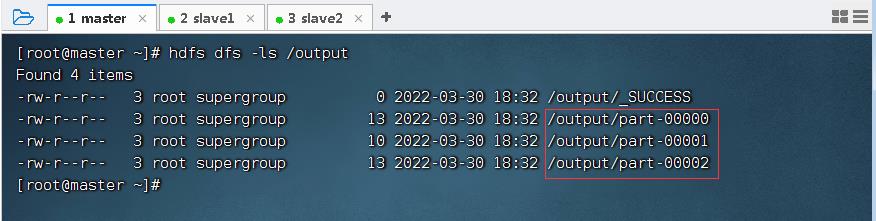
- 查看三个分区的结果文件

以上是关于Spark基础学习笔记18:掌握RDD分区的主要内容,如果未能解决你的问题,请参考以下文章