RabbitMQ高可用原理
Posted IT-老牛
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了RabbitMQ高可用原理相关的知识,希望对你有一定的参考价值。
单个的 RabbitMQ 肯定无法实现高可用,要想高可用,还得上集群。
在正式的聊聊集群的原理之前,我们先简单了解下RabbitMQ的优缺点,然后为什么要使用RabbitMQ的集群模式,他能为我们解决那些问题,各种不同的集群模式有什么区别,又有什么优缺点;
1.RabbitMQ的优缺点
RabbitMQ的优点,其实已经介绍过了,无外乎三大点:解耦、削峰、异步通讯等,我们这里简单提下,但是相对于优点来说,RabbitMQ同样也有缺点:
- 增加了系统应用的复杂性
- RabbitMQ服务如果出现问题,则整个服务将会瘫痪
- 新增了很多异常情况的处理, 比如消息丢失、消息消费失败, 消息重复消费等
- RabbitMQ服务在高并发情况下很容易出现性能瓶颈,进而影响整个系统的运行
其中1和3的问题都可以通过代码和配置来解决,但是问题2和4就不好解决了,为了解决上面的问题,就出现了RabbitMQ服务的集群
2 .RabbitMQ两种集群
2.1.普通集群
什么是普通集群呢? 就是在多个联通的服务器上安装不同的RabbitMQ的服务,这些服务器上的RabbitMQ服务组成一个个节点,通过RabbitMQ内部提供的命令或者配置来构建集群,形成了RabbitMQ的普通集群模式.
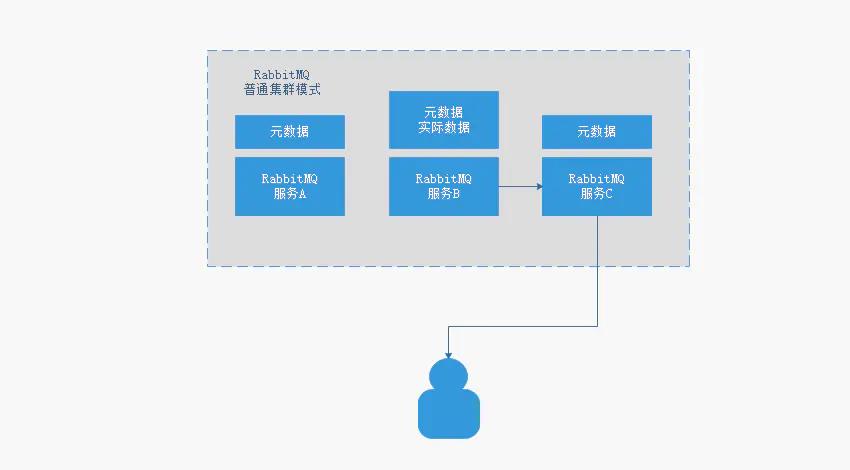
- 当用户向服务注册一个队列,该队列会随机保存到某一个服务节点上,然后将对应的元数据同步到各个不同的服务节点上
- RabbitMQ的普通集群模式中,每个RabbitMQ都保存有相同的元数据
用户只需要链接到任一一个服务节点中,就可以监听消费到对应队列上的消息数据 - 但是RabbitMQ的实际数据却不是保存在每个RabbitMQ的服务节点中,这就意味着用户可能联系的是RabbitMQ服务节点C,但是C上并没有对应的实际数据,也就是说RabbitMQ服务节点C,并不能提供消息供用户来消费,那么RabbitMQ的普通集群模式如何解决这个问题呢?
- RabbitMQ服务节点C发现自己本服务节点并没有对应的实际数据后,因为每个服务节点上都会保存相同的元数据,所以服务节点C会根据元数据,向服务节点B(该服务节点上有实际数据可供消费)请求实际数据,然后提供给用户进行消费
- 这样给用户的感觉就是,在RabbitMQ的普通集群模式中,用户连接任一服务节点都可以消费到消息
- 普通集群模式的优点:提高消费的吞吐量
普通集群模式的原理比较简单,但是并不能真正意义上的实现高可用,他也存在以下的以下缺点:
-
为了请求RabbitMQ的实际数据以提供给用户,可能会在RabbitMQ内部服务节点之间进行频繁的进行数据交互,这样的交互比较耗费资源
-
当其中一个RabbitMQ的服务节点宕机了,那么该节点上的实际数据就会丢失,用户再次请求时,就会请求不到数据,系统的功能就会出现异常
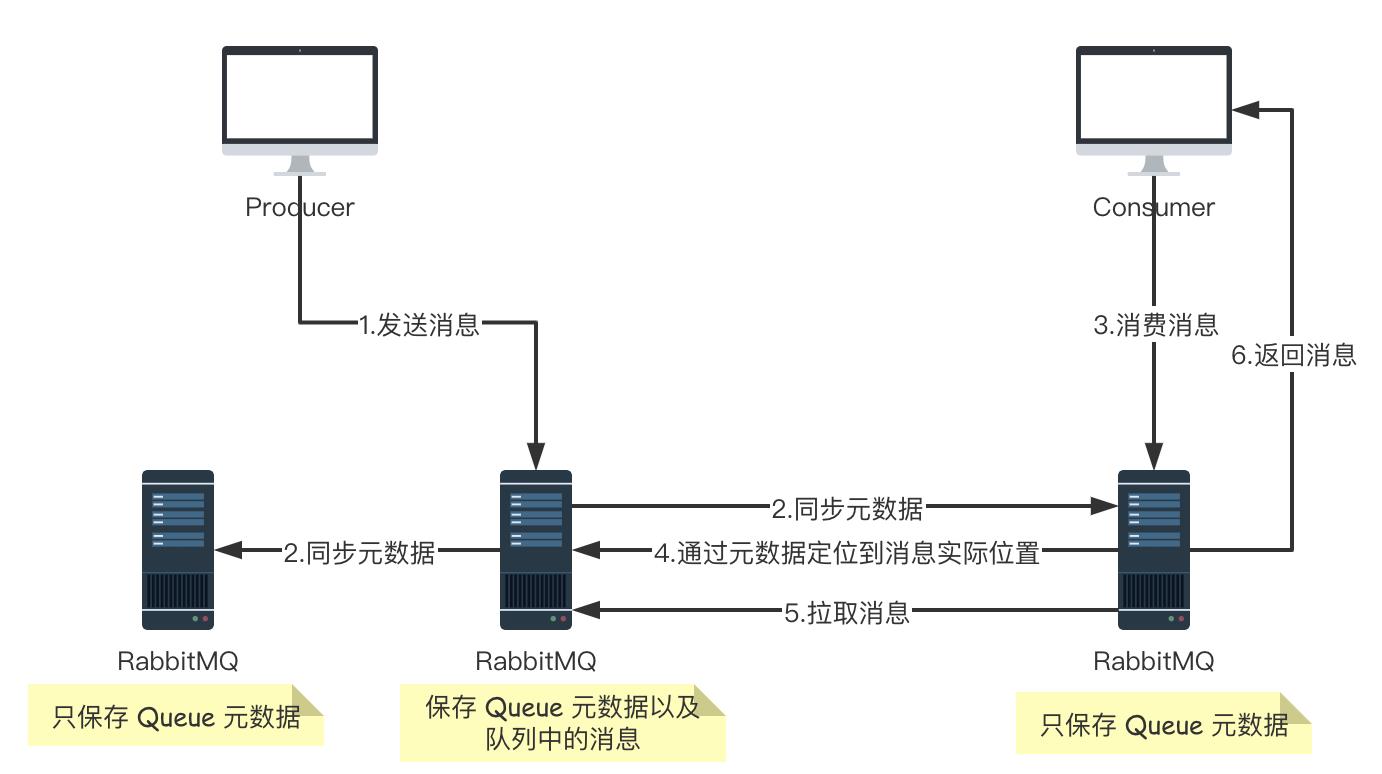
普通集群模式,就是将 RabbitMQ 部署到多台服务器上,每个服务器启动一个 RabbitMQ 实例,多个实例之间进行消息通信。
此时我们创建的队列 Queue,它的元数据(主要就是 Queue 的一些配置信息)会在所有的 RabbitMQ 实例中进行同步,但是队列中的消息只会存在于一个 RabbitMQ 实例上,而不会同步到其他队列。
当我们消费消息的时候,如果连接到了另外一个实例,那么那个实例会通过元数据定位到 Queue 所在的位置,然后访问 Queue 所在的实例,拉取数据过来发送给消费者。
这种集群可以提高 RabbitMQ 的消息吞吐能力,但是无法保证高可用,因为一旦一个 RabbitMQ 实例挂了,消息就没法访问了,如果消息队列做了持久化,那么等 RabbitMQ 实例恢复后,就可以继续访问了;如果消息队列没做持久化,那么消息就丢了。
大致的流程图如下图:
那么该怎么解决上述的问题呢?
2.2.镜像集群
为了解决上面普通模式的两个显著的缺点,RabbitMQ官方提供另外一种集群模式:镜像集群模式
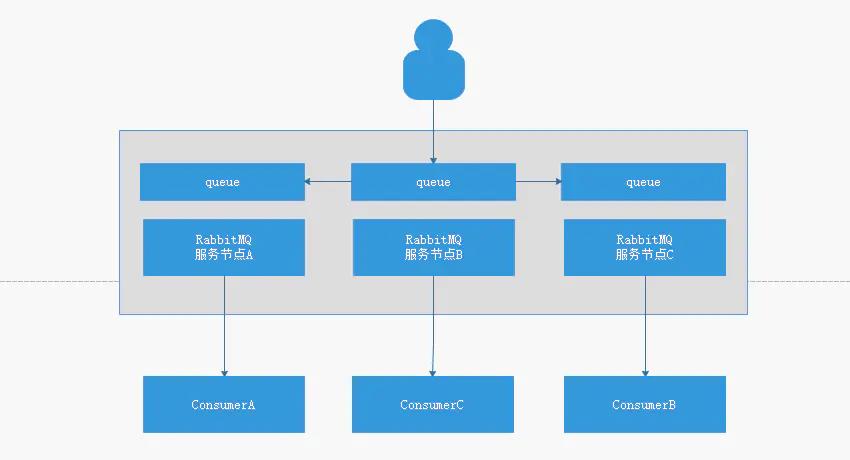
镜像集群模式和普通集群模式大体是一样的,不一样的是:
- 生产者向任一服务节点注册队列,该队列相关信息会同步到其他节点上
- 任一消费者向任一节点请求消费,可以直接获取到消费的消息,因为每个节点上都有相同的实际数据
- 任一节点宕机,不影响消息在其他节点上进行消费
镜像集群模式是怎么开启的呢?这里简单说下,在普通集群模式的基础上,我们可以通过web控制端来配置数据的同步策略,可以配置同步所有的节点,也可以配置同步到指定数量的服务节点
虽然镜像集群模式能够解决普通集群模式的缺点,当任一节点宕机了,不能正常提供服务了,也不影响该消息的正常消费,但是其本身也有相应的缺点:
- 性能开销非常大,因为要同步消息到对应的节点,这个会造成网络之间的数据量的频繁交互,对于网络带宽的消耗和压力都是比较重的
- 没有扩展可言,rabbitMQ是集群,不是分布式的,所以当某个Queue负载过重,我们并不能通过新增节点来缓解压力,因为所以节点上的数据都是相同的,这样就没办法进行扩展了.
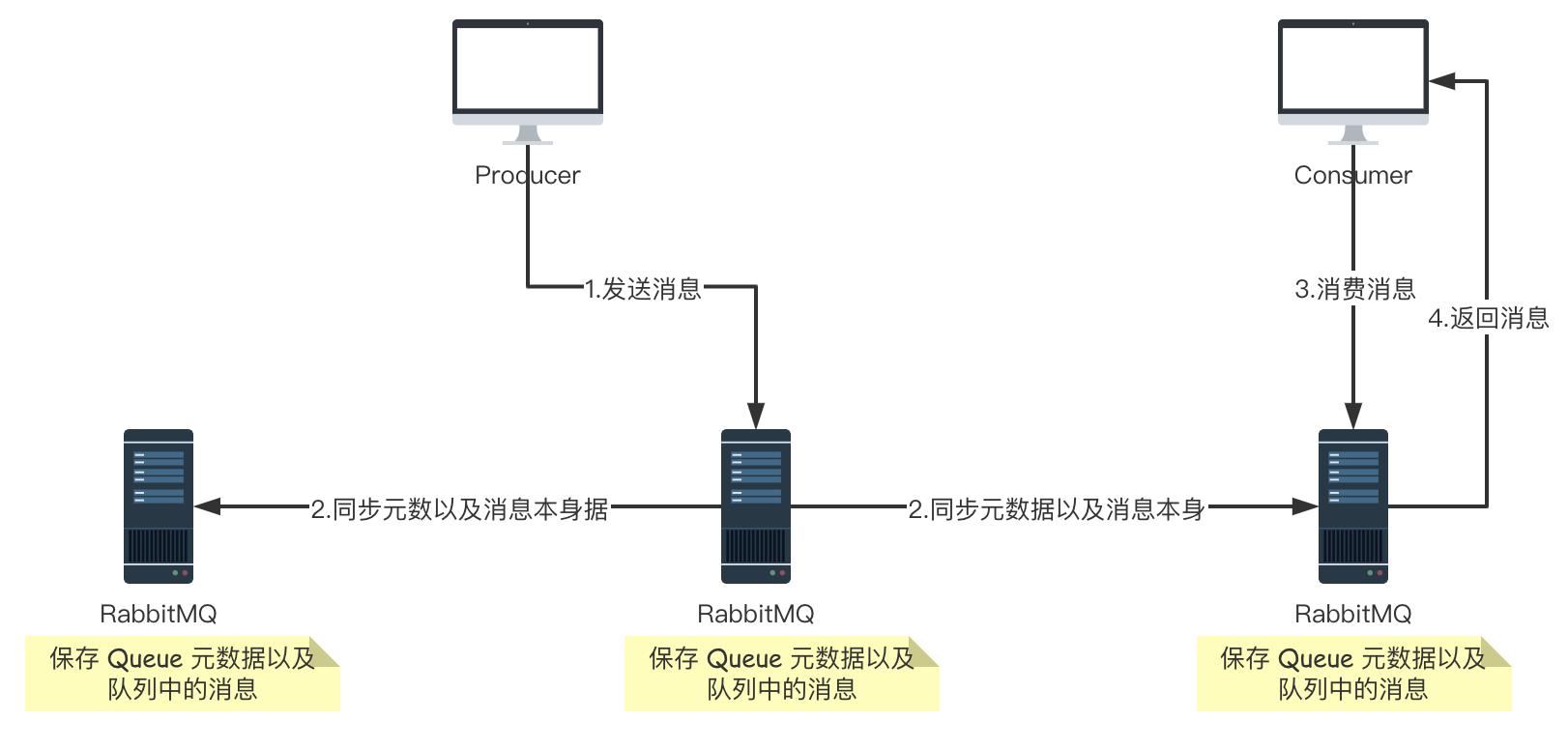
它和普通集群最大的区别在于 Queue 数据和原数据不再是单独存储在一台机器上,而是同时存储在多台机器上。也就是说每个 RabbitMQ 实例都有一份镜像数据(副本数据)。每次写入消息的时候都会自动把数据同步到多台实例上去,这样一旦其中一台机器发生故障,其他机器还有一份副本数据可以继续提供服务,也就实现了高可用。
大致流程图如下图:
以上是关于RabbitMQ高可用原理的主要内容,如果未能解决你的问题,请参考以下文章
RabbitMQ集群架构之使用Haproxy实现高可用负载均衡
因为一次 Kafka 宕机,我明白了 Kafka 高可用原理!