Flink SQL篇,SQL实操Flink HiveCEPCDCGateWay
Posted zhisheng_blog
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink SQL篇,SQL实操Flink HiveCEPCDCGateWay相关的知识,希望对你有一定的参考价值。
Flink源码篇,作业提交流程、作业调度流程、作业内部转换流程图
Flink核心篇,四大基石、容错机制、广播、反压、序列化、内存管理、资源管理
Flink基础篇,基本概念、设计理念、架构模型、编程模型、常用算子
1、Flink SQL有没有使用过?
2、Flink被称作流批一体,从哪个版本开始,真正实现流批一体的?
3、Flink SQL 使用哪种解析器?
4、Calcite主要功能包含哪些?
5、Flink SQL 处理流程说一下?
6、Flink SQL包含哪些优化规则?
7、Flink SQL中涉及到哪些operation?
8、Flink Hive有没有使用过?
9、Flink与Hive集成时都做了哪些操作?
10、HiveCatalog类包含哪些方法?
11、Flink SQL 1.11 新增了实时数仓功能,介绍一下?
12、Flink-Hive实时写数据介绍下?
13、Flink-Hive实时读数据介绍下?
14、Flink-Hive实时写数据时,如何保证已经写入分区的数据何时才能对下游可见呢?
15、源码中分区提交的PartitionCommitTrigger介绍一下?
16、PartitionTimeCommitTigger 是如何知道该提交哪些分区的呢?(源码分析)
17、如何保证已经写入分区的数据对下游可见的标志问题(源码分析)
18、Flink SQL CEP有没有接触过?
19、Flink SQL CEP了解的参数介绍一下?
20、编写一个CEP SQL案例,如银行卡盗刷
21、Flink CDC了解吗?什么是 Flink SQL CDC Connectors?
22、Flink CDC原理介绍一下
23、通过CDC设计一种Flink SQL 采集+计算+传输(ETL)一体化的实时数仓
24、Flink SQL CDC如何实现一致性保障(源码分析)
25、Flink SQL GateWay了解吗?
26、Flink SQL GateWay创建会话讲解一下?
27、Flink SQL GateWay如何处理并发请求?多个提交怎么处理?
28、如何维护多个SQL之间的关联性?
29、SQL字符串如何提交到集群成为代码?
1、Flink SQL有没有使用过?
在Flink中,一共有四种级别的抽象,而Flink SQL作为最上层,是Flink API的一等公民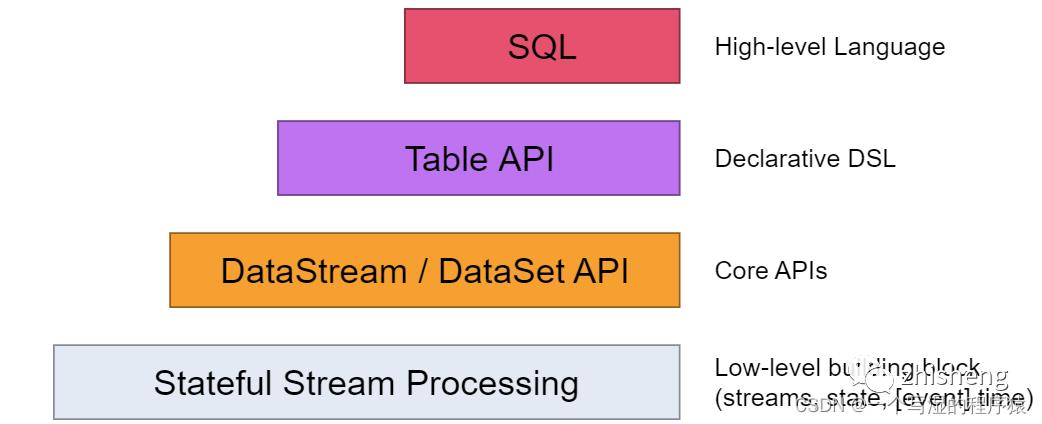
在标准SQL中,SQL语句包含四种类型
DML(Data Manipulation Language):数据操作语言,用来定义数据库记录(数据)。
DCL(Data Control Language):数据控制语言,用来定义访问权限和安全级别。
DQL(Data Query Language):数据查询语言,用来查询记录(数据)。
DDL(Data Definition Language):数据定义语言,用来定义数据库对象(库,表,列等)。
Flink SQL包含 DML 数据操作语言、 DDL 数据语言, DQL 数据查询语言,不包含DCL语言。
2、Flink被称作流批一体,从哪个版本开始,真正实现流批一体的?
从1.9.0版本开始,引入了阿里巴巴的 Blink ,对 FIink TabIe & SQL 模块做了重大的重构,保留了 Flink Planner 的同时,引入了 Blink PIanner,没引入以前,Flink 没考虑流批作业统一,针对流批作业,底层实现两套代码,引入后,基于流批一体理念,重新设计算子,以流为核心,流作业和批作业最终都会被转为 transformation。
3、Flink SQL 使用哪种解析器?
Flink SQL使用 Apache Calcite 作为解析器和优化器。
Calcite 一种动态数据管理框架,它具备很多典型数据库管理系统的功能 如SQL 解析、 SQL 校验、 SQL 查询优化、 SQL 生成以及数据连接查询等,但是又省略了一些关键的功能,如 Calcite并不存储相关的元数据和基本数据,不完全包含相关处理数据的算法等。
4、Calcite主要功能包含哪些?
Calcite 主要包含以下五个部分:
1、SQL 解析(Parser)
Calcite SQL 解析是通过 JavaCC 实现的,使用 JavaCC 编写 SQL 语法描述文件,将 SQL 解析成未经校验的 AST 语法树。
2、SQL 校验(Validato)
校验分两部分
无状态的校验:即验证 SQL 语句是否符合规范。
有状态的校验:即通过与元数据结合验证 SQL 中的 Schema、Field、 Function 是否存在,输入输出类型是否匹配等。
3、SQL 查询优化
对上个步骤的输出(RelNode ,逻辑计划树)进行优化,得到优化后的物理执行计划,优化有两种:基于规则的优化 和 基于代价的优化,后面会详细介绍。
4、SQL 生成
将物理执行计划生成为在特定平台/引擎的可执行程序,如生成符合 mysql 或 Oracle 等不同平台规则的 SQL 查询语句等。
5、数据连接与执行
通过各个执行平台执行查询,得到输出结果。
在Flink 或者其他使用 Calcite 的大数据引擎中,一般到 SQL 查询优化即结束,由各个平台结合 Calcite SQL 代码生成 和 平台实现的代码生成,将优化后的物理执行计划组合成可执行的代码,然后在内存中编译执行。
5、Flink SQL 处理流程说一下?
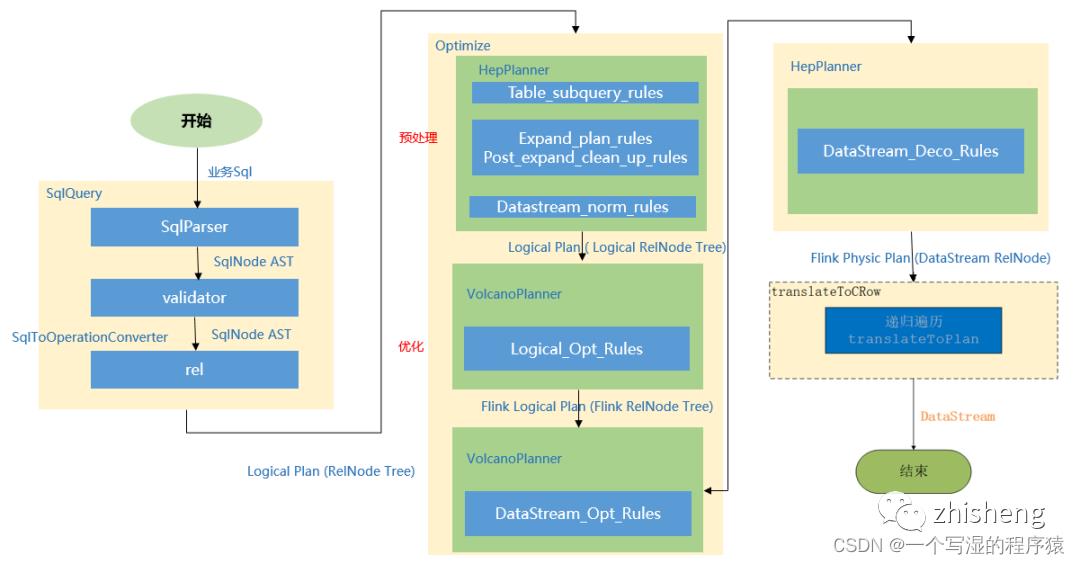
下面举个例子,详细描述一下Flink Sql的处理流程,如下图所示:
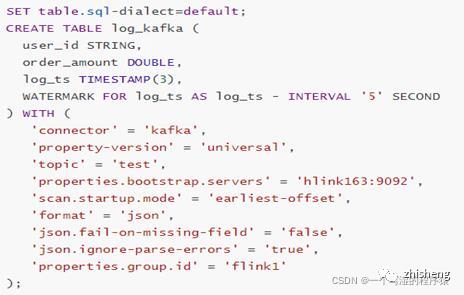
我们写一张source表,来源为kafka,当执行create table log_kafka之后 Flink SQL将做如下操作:
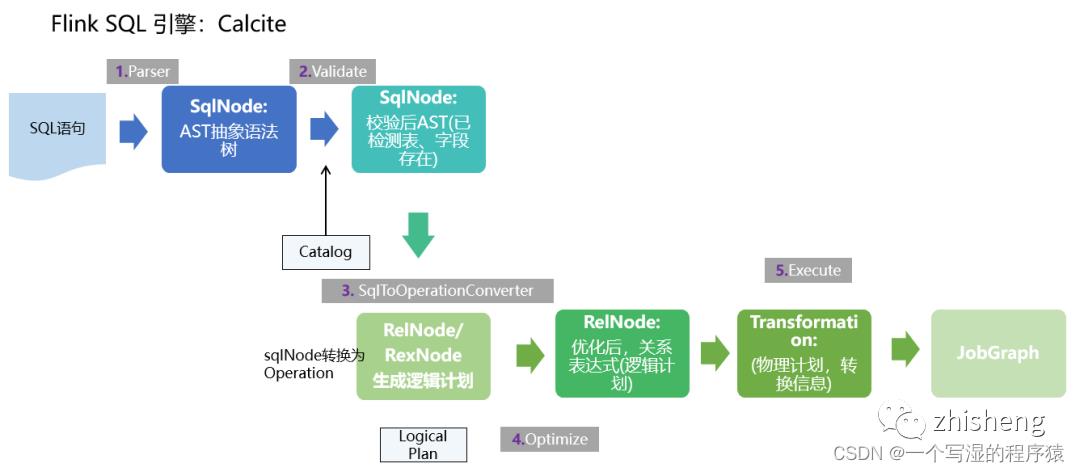
(1)首先,FlinkSQL 底层使用的是 apache Calcite 引擎来处理SQL语句,Calcite会使用 javaCC 做SQL解析,javaCC根据Calcite中定义的 Parser.jj 文件,生成一系列的java代码,生成的java代码会把SQL转换成AST抽象语法树(即SQLNode类型)。
(2)生成的 SqlNode 抽象语法树,他是一个未经验证的抽象语法树,这时 SQL Validator 会获取 Flink Catalog 中的元数据信息来验证 sql 语法,元数据信息检查包括表名,字段名,函数名,数据类型等检查。然后生成一个校验后的SqlNode。
(3)到达这步后,只是将 SQL 解析到 java 数据结构的固定节点上,并没有给出相关节点之间的关联关系以及每个节点的类型信息。
所以,还需要将 SqlNode 转换为逻辑计划,也就是LogicalPlan,在转换过程中,会使用 SqlToOperationConverter 类,来将 SqlNode 转换为 Operation,Operation 会根据SQL语法来执行创建表或者删除表等操作,同时FlinkPlannerImpl.rel()方法会将SQLNode转换成RelNode树,并返回RelRoot。
(4)第4步将执行 Optimize 操作,按照预定义的优化规则 RelOptRule 优化逻辑计划。
Calcite 中的优化器RelOptPlanner有两种,一是基于规则优化(RBO)的HepPlanner,二是基于代价优化(CBO)的VolcanoPlanner。然后得到优化后的RelNode, 再基于Flink里面的rules将优化后的逻辑计划转换成物理计划。
(5)第5步 执行 execute 操作,会通过代码生成 transformation,然后递归遍历各节点,将DataStreamRelNode 转换成DataStream,在这期间,会依次递归调用DataStreamUnion、DataStreamCalc、DataStreamScan类中重写的 translateToPlan方法。递归调用各节点的translateToPlan,实际是利用CodeGen元编成Flink的各种算子,相当于直接利用Flink的DataSet或者DataStream开发程序。
(6)最后进一步编译成可执行的 JobGraph 提交运行。
6、Flink SQL包含哪些优化规则?
如下图为执行流程图
总结:
先解析,然后验证,将SqlNode转化为Operation来创建表,然后调用rel方法将sqlNode变成 逻辑计划 (RelNodeTree)紧接着对逻辑计划进行优化;
优化之前,会根据Calcite中的优化器中的基于规则优化的HepPlanner针对四种规则进行预处理,处理完之后得到Logic RelNode,紧接着使用代价优化的VolcanoPlanner使用 Logical_Opt_Rules(逻辑计划优化)找到最优的执行Planner,并转换为FlinkLogical RelNode。
最后运用 Flink包含的优化规则,如DataStream_Opt_Rules:流式计算优化,DataStream_Deco_Rules:装饰流式计算优化 将优化后的逻辑计划转换为物理计划。
优化规则包含如下:
Table_subquery_rules:子查询优化
Expand_plan_rules:扩展计划优化
Post_expand_clean_up_rules:扩展计划优化
Datastream_norm_rules:正常化流处理
Logical_Opt_Rules:逻辑计划优化
DataStream_Opt_Rules:流式计算优化
DataStream_Deco_Rules:装饰流式计算优化
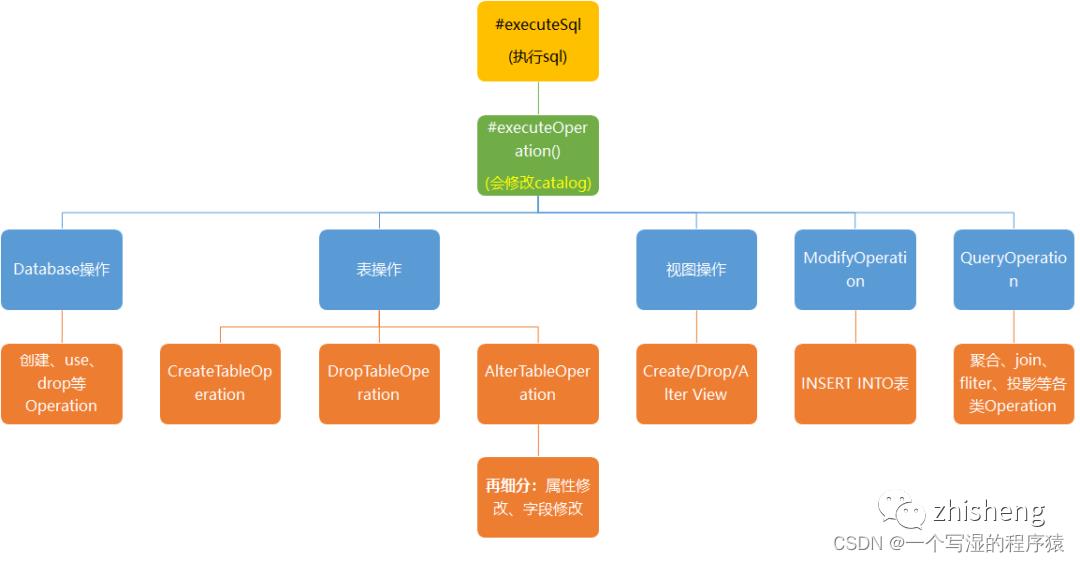
7、Flink SQL中涉及到哪些operation?
先介绍一下什么是Operation
在Flink SQL中,涉及的DDL,DML,DQL操作都是Operation,在 Flink内部表示,Operation可以和SqlNode对应起来。
Operation执行在优化前,执行的函数为executeQperation,如下图所示,为执行的所有Operation。
8、Flink Hive有没有使用过?
Flink社区在Flink1.11版本进行了重大改变,如下图所示:

9、Flink与Hive集成时都做了哪些操作?
如下所示为Flink与HIve进行连接时的执行图:
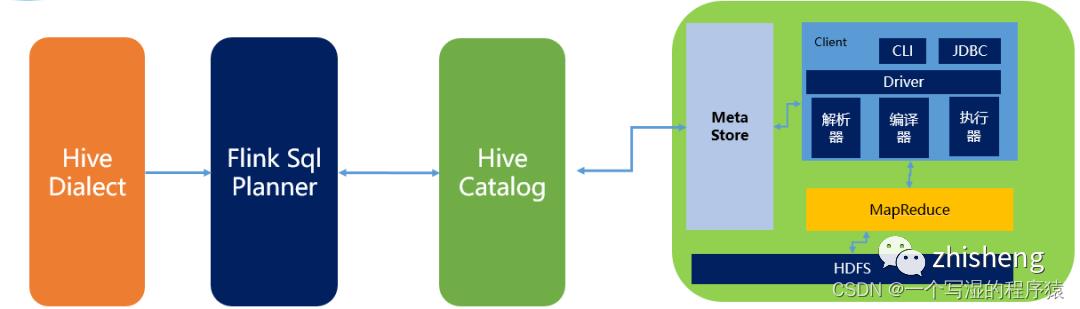
(1)Flink1.1新引入了Hive方言,所以在Flink SQL中可以编写HIve语法,即Hive Dialect。
(2)编写HIve SQL后,FlinkSQL Planner 会将SQL进行解析,验证,转换成逻辑计划,物理计划,最终变成Jobgraph。
(3)HiveCatalog作为Flink和Hive的表元素持久化介质,会将不同会话的Flink元数据存储到Hive Metastore中。用户利用HiveCatalog可以将hive表或者 Kafka表存储到Hive Metastore中。
BlinkPlanner 是在Flink1.9版本新引入的机制,Blink 的查询处理器则实现流批作业接口的统一,底层的 API 都是Transformation。真正实现 流 &批 的统一处理,替代原Flink Planner将流&批区分处理的方式。在1.11版本后 已经默认为Blink Planner。
10、HiveCatalog类包含哪些方法?
重点方法如下:
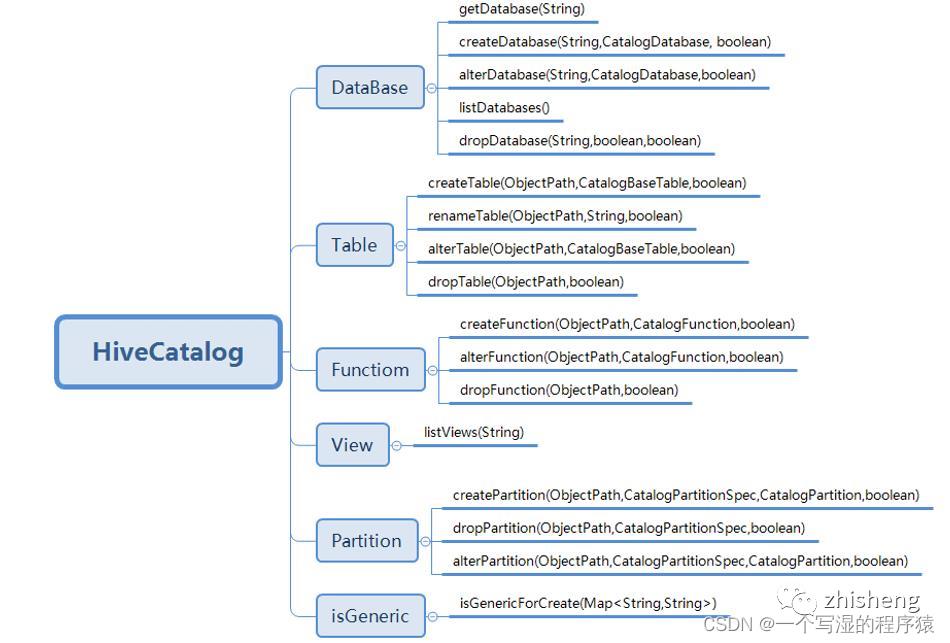
HiveCatalog主要是持久化元数据,所以 一般的创建类型都包含,如 database、Table、View、Function、Partition,还有is_Generic字段判断等。
11、Flink SQL 1.11 新增了实时数仓功能,介绍一下?
Flink1.11 版本新增的一大功能是实时数仓,可以实时的将kafka中的数据插入Hive中,传统的实时数仓基于 Kafka+ Flinkstreaming,定义全流程的流计算作业,有着秒级甚至毫秒的实时性,但实时数仓的一个问题是历史数据只有 3-15天,无法在其上做 Ad-hoc的查询。
针对这个特点,Flink1.11 版本将 FlieSystemStreaming Sink 重新修改,增加了分区提交和滚动策略机制,让HiveStreaming sink 重新使用文件系统流接收器。
Flink 1.11 的 Table/SQL API 中,FileSystemConnector 是靠增强版 StreamingFileSink组件实现,在源码中名为 StreamingFileWriter。只有在Checkpoint 成功时,StreamingFileSink写入的文件才会由 Pending状态变成 Finished状态,从而能够安全地被下游读取。所以,我们一定要打开 Checkpointing,并设定合理的间隔。
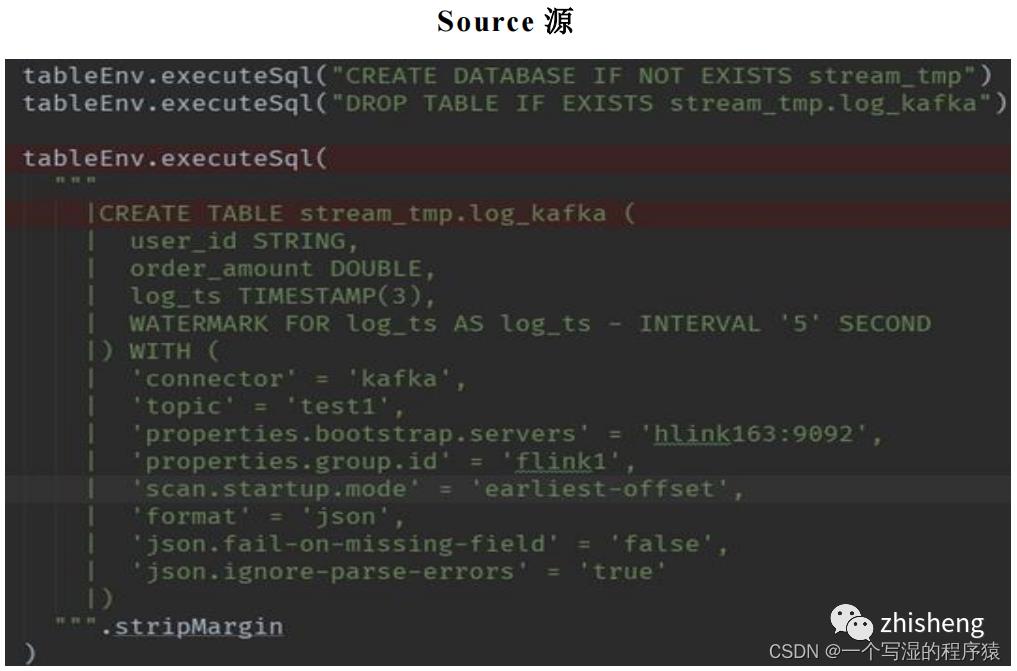
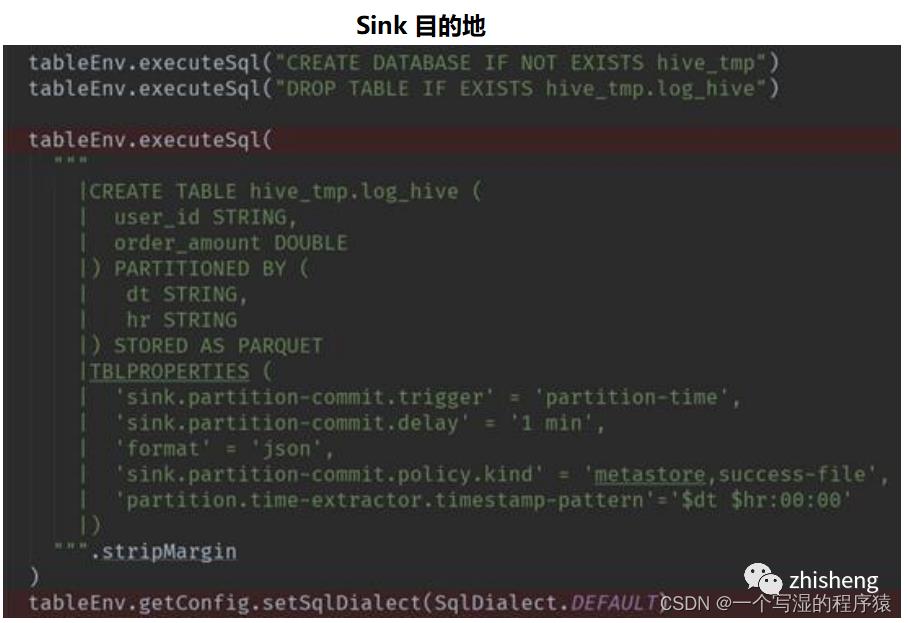
12、Flink-Hive实时写数据介绍下?
StreamingWrite,从kafka 中实时拿到数据,使用分区提交将数据从Kafka写入Hive表中,并运行批处理查询以读取该数据。
Flink -SQL 写法:
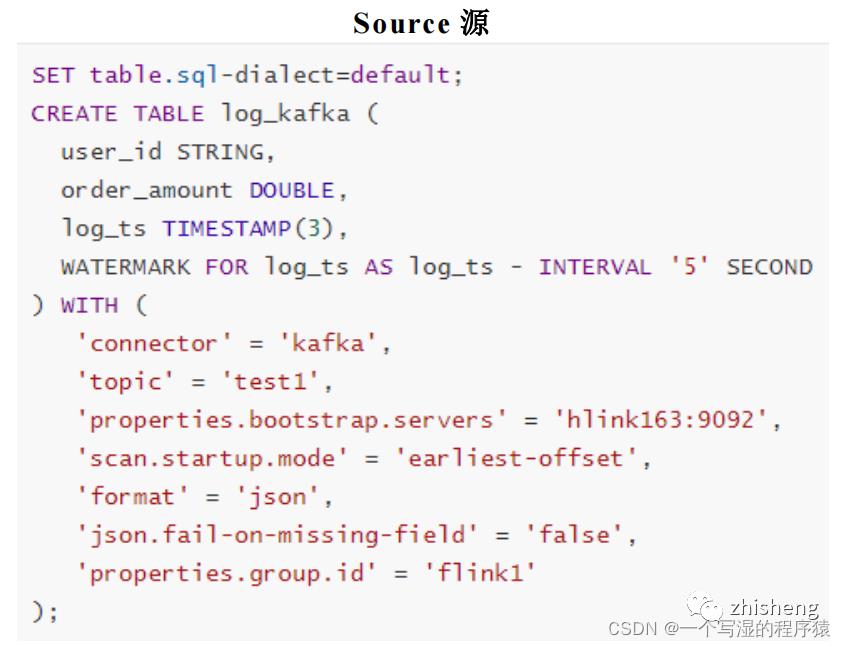

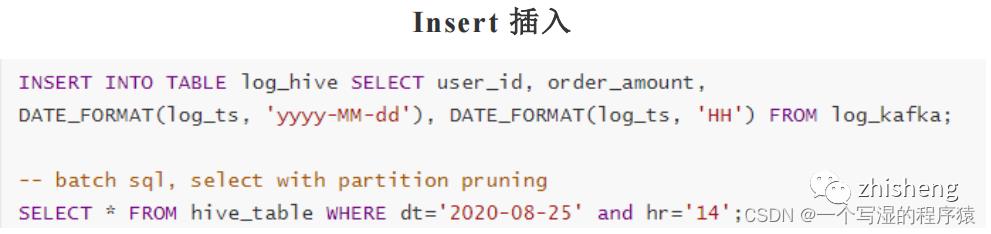
Flink-table写法:
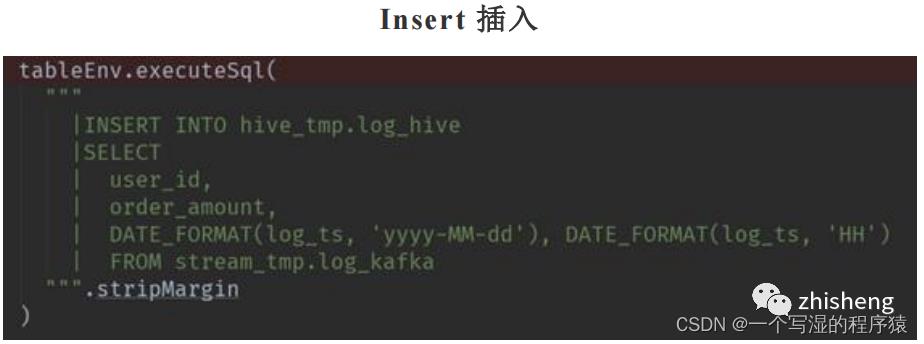
13、Flink-Hive实时读数据介绍下?
如下图所示:
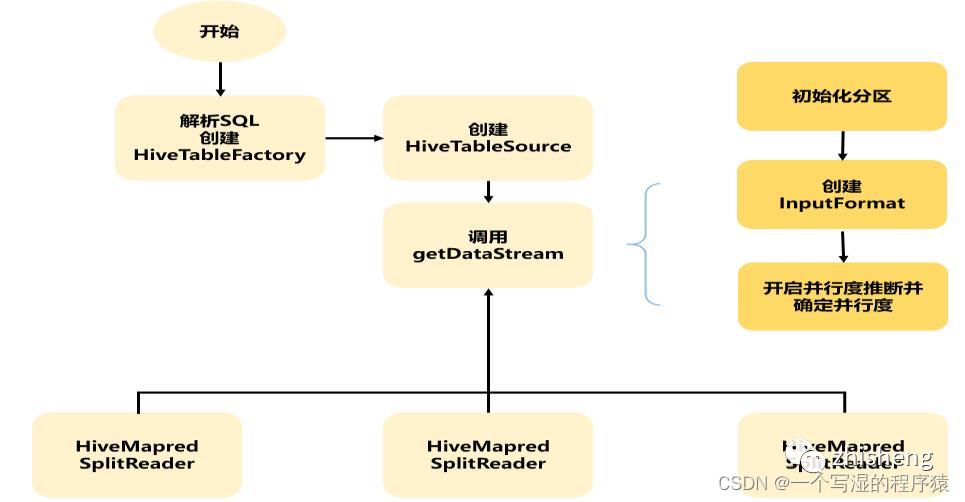
Flink 源码中在对Hive进行读取操作时,会经历以下几个步骤:
1、Flink都是基于calcite先解析sql,确定表来源于hive,如果是Hive表,将会在HiveCatalog中创建HiveTableFactory
2、HiveTableFactory 会基于配置文件创建 HiveTableSource,然后HiveTableSource在真正执行时,会调用getDataStream方法,通过getDataStream方法来确定查询匹配的分区信息,然后创建表对应的InputFormat,然后确定并行度,根据并行度确定slot 分发HiveMapredSplitReader任务。
3、在TaskManager端的slot中,Split会确定读取的内容,基于Hive中定义的序列化工具,InputFormat执行读取反序列化,得到value值。
4、最后循环执行reader.next 获取value,将其解析成Row。
14、Flink-Hive实时写数据时,如何保证已经写入分区的数据何时才能对下游可见呢?
如下图所示:
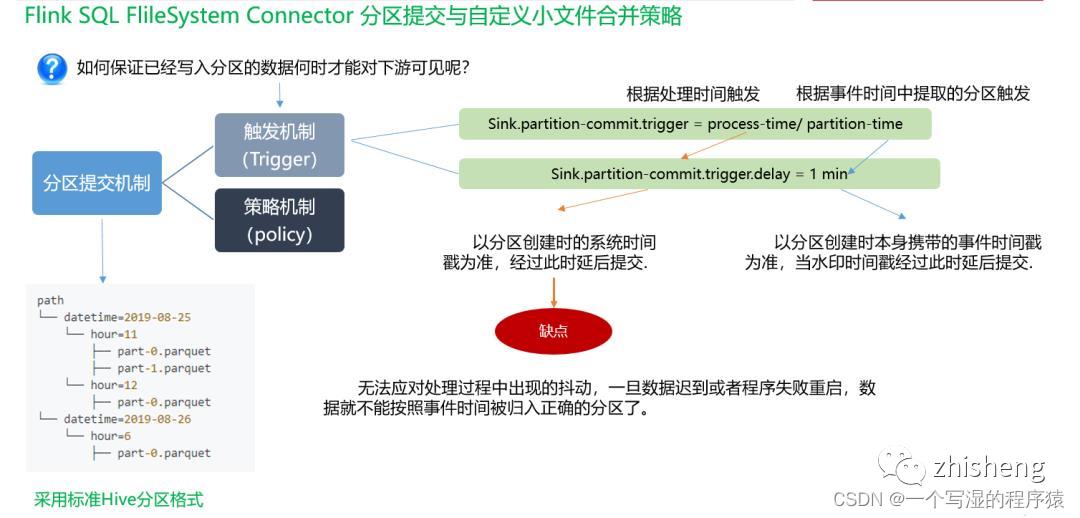
首先可以看一下,在实时的将数据存储到Hive数仓中,FileSystemConnector 为了与 Flink-Hive集成的大环境适配,最大的改变就是分区提交,官方文档给出的,分区可以采取日期 + 小时的策略,或者时分秒的策略。
那如何保证已经写入分区的数据何时才能对下游可见呢?
这就和 触发机制 有关, 触发机制包含process-time和 partition-time以及时延。
partition-time 指的是根据事件时间中提取的分区触发。当'watermark' > 'partition-time' + 'delay' ,选择 partition-time 的数据才能提交成功,
process-time 指根据系统处理时间触发,当加上时延后,要想让分区进行提交,当'currentprocessing time' > 'partition creation time' + 'delay' 选择 process-time 的数据可以提交成功。
但选择process-time触发机制会有缺陷,就是当数据迟到或者程序失败重启时,数据不能按照事件时间被归入正确分区。所以 一般会选择 partition-time。
15、源码中分区提交的PartitionCommitTrigger介绍一下?
在源码中,PartitionCommitTrigger类图如下所示
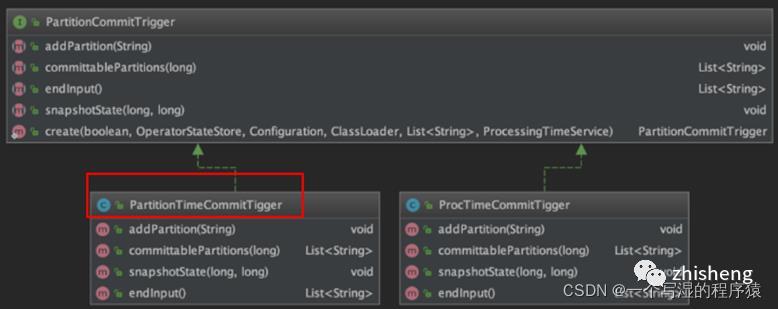
该类中维护了两对必要的信息:
1、pendingPartitions / pendingPartitionsState:等待提交的分区以及对应的状态;
2、watermarks / watermarksState:watermarks(用 TreeMap 存储以保证有序)以及对应的状态。
16、PartitionTimeCommitTigger 是如何知道该提交哪些分区的呢?(源码分析)
1、检查checkpoint ID 是否合法;
2、取出当前checkpoint ID 对应的水印,并调用 TreeMap 的headMap()和 clear() 方法删掉早于当前 checkpoint ID的水印数据(没用了);
3、遍历等待提交的分区,调用之前定义的PartitionTimeExtractor。
(比如$year-$month-$day $hour:00:00)抽取分区时间。
如果watermark > partition - time + delay,说明可以提交,并返回它们
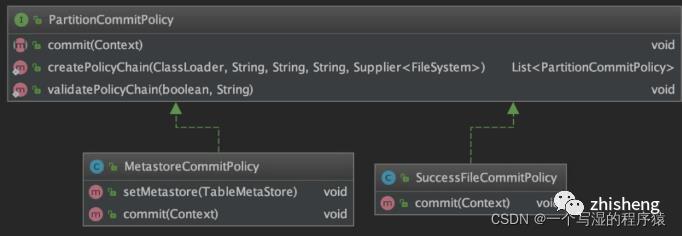
17、如何保证已经写入分区的数据对下游可见的标志问题(源码分析)
在源码中,主要涉及PartitionCommitPolicy类,如下图所示:

18、Flink SQL CEP有没有接触过?
CEP的概念:
复杂事件处理(Complex Event Processing),用于识别输入流中符合指定规则的事件,并按照指定方式输出。
起床—>洗漱—>吃饭—>上班,一系列串联起来的事件流形成的模式
浏览商品—>加入购物车—>创建订单—>支付完成—>发货—>收货,事件流形成的模式。
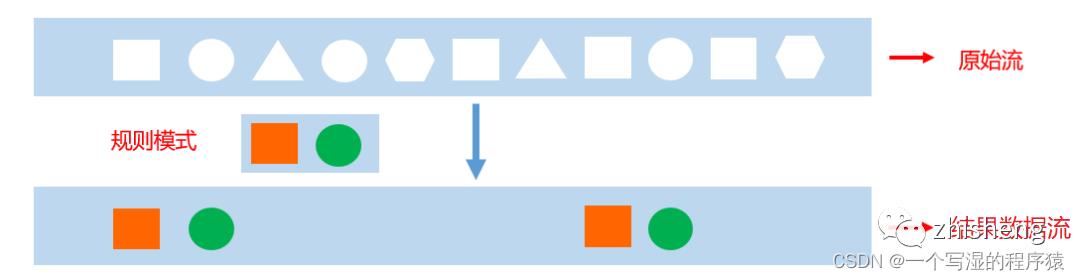
通过概念可以了解,CEP主要是识别输入流中用户指定的一些基本规则的事件,然后将这些事件再通过指定方式输出。
如下图所示:我们指定“方块、圆”为基本规则的事件,在输入的原始流中,将这些事件作为一个结果流输出来。
CEP的使用场景:
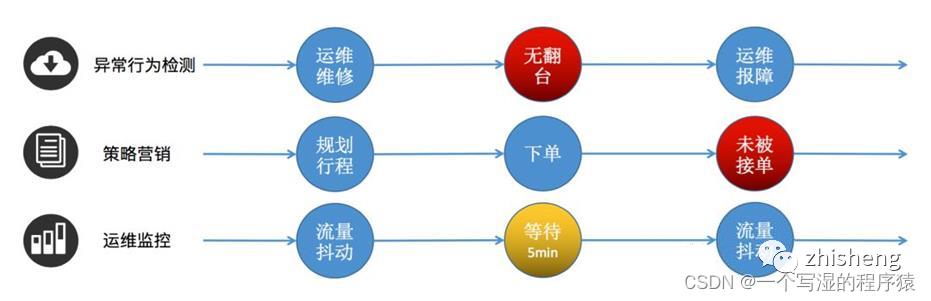

像用户异常检测:我们指定异常操作事件为要输出的结果流;
策略营销:指定符合要求的事件为结果流;
运维监控:指定一定范围的指标为结果流;
银行卡盗刷:指定同一时刻在两个地方被刷两次为异常结果流。
Flink CEP SQL 语法 是通过SQL方式进行复杂事件处理,但是与 Flink SQL语法也不太相同,其中包含许多规则。
19、Flink SQL CEP了解的参数介绍一下?
CEP包含的参数如下:
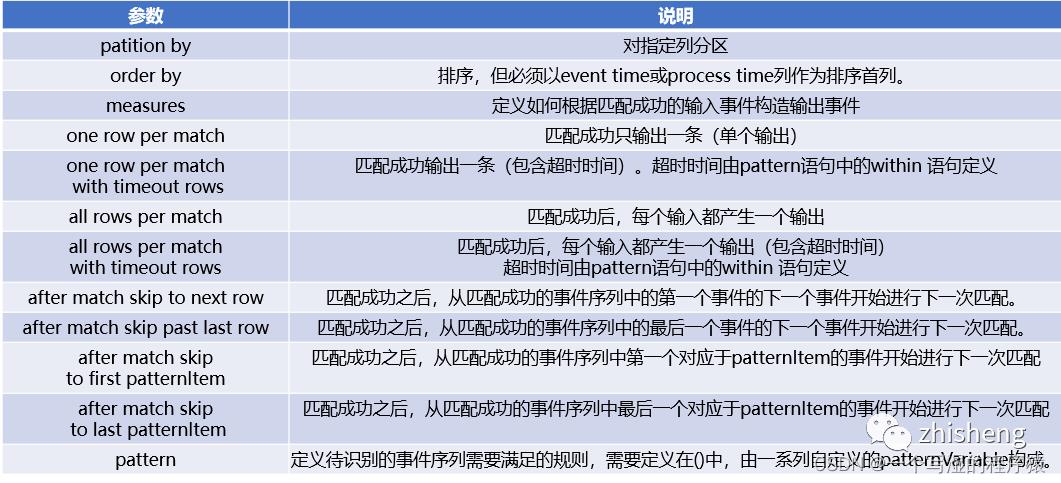
参数介绍
输出模式(每个找到的匹配项应该输出多少行)
one row per match
每次检测到完整的匹配后进行汇总输出
all rows per match (flink暂不支持)
检测到完整的匹配后会把匹配过程中每条具体记录进行输出
running VS final语义
在计算中使用那些匹配的事件
running匹配中和final匹配结束
define语句中只可以使用running,measure两者都可以
输出结果区别
对于one row per match,输出没区别
对于all rows per match,输出不同


匹配后跳转模式介绍
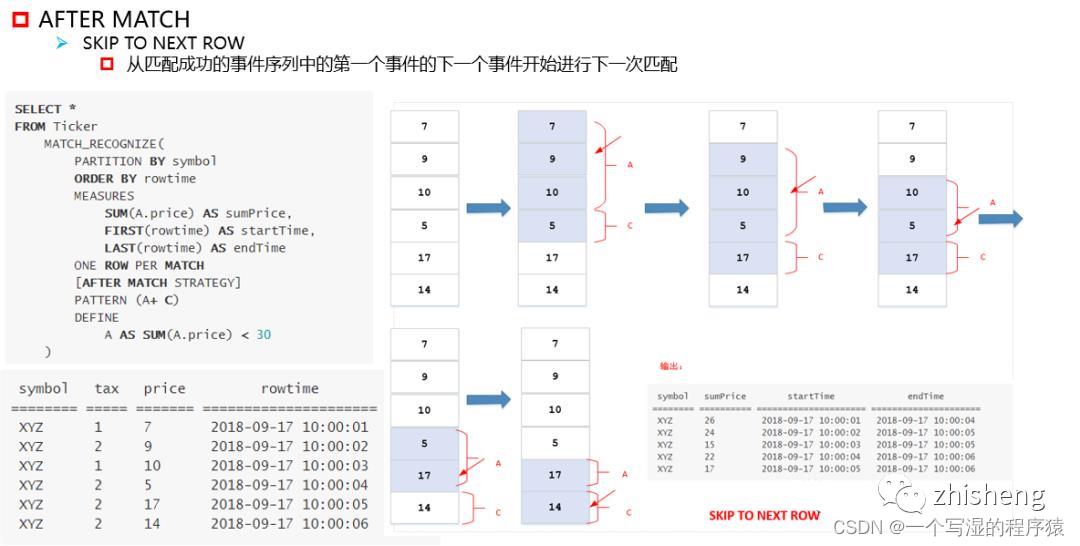
after match(匹配后,从哪里开始重新匹配)
skip to next row
从匹配成功的事件序列中的第一个事件的下一个事件开始进行下一次匹配
skip past last row
从匹配成功的事件序列中的最后一个事件的下一个事件开始进行下一次匹配

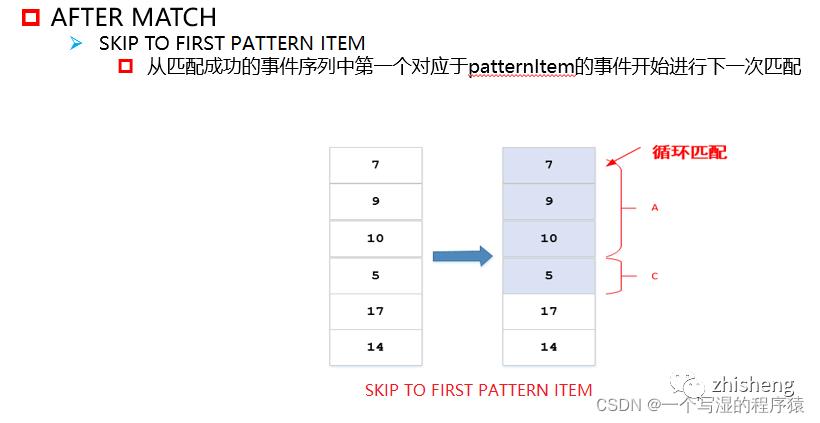
skip to first pattern Item
从匹配成功的事件序列中第一个对应于patternItem的事件开始进行下一次匹配
skip to last pattern Item
从匹配成功的事件序列中最后一个对应于patternItem的事件开始进行下一次匹配

注意:在使用skip to first / last patternItem容易出现循环匹配问题,需要慎重
20、编写一个CEP SQL案例,如银行卡盗刷
通过Flink CEP SQL 写的关于金融场景 银行卡盗刷案例。
案例介绍:在金融场景中,有时会出现银行卡盗刷现象,犯罪分子利用互联网等技术,在间隔10分钟或者更短时间内,使一张银行卡在不同的两个地方出现多次刷卡记录,这从常规操作来说,在间隔时间很多的情况下,用户是无法同时在两个城市进行刷卡交易的,所以出现这种问题,就需要后台做出触发报警机制。
要求:当相同的cardId在十分钟内,从两个不同的Location发生刷卡现象,触发报警机制,以便检测信用卡盗刷现象。

1)编写cep sql时,包含许多技巧,首先我们编写最基础的查询语句,从一张表中查询需要的字段。
select starttime,endtime,cardId,event from dataStream
(2)match_recognize();
该字段是CEP SQL 的前提条件,用于生成一个追加表,所有的 CEP SQL都是书写在这里面。
(3)分区,排序
由于是对同一ID,所以需要使用 partition by,还要根据时间进行排序 order by
(4)理解CEP SQL核心的编写顺序
如上图标的顺序
CEP SQL 的类为Pattern,检测在10分钟内两个地方出现刷卡现象,所以定义两个事件:
Pattern (e1 e2+) within interval '10' minute
定义在Pattern中要求的判断语句,规定使用define
define
e1 as a1.action = ''
e2 as e2.action = '' and e2.location <> e1.location
根据上述的输入条件构建输出条件,规定使用 measures
measures
e2.action as event
e1.timestamp as starttime
last(e2.timestamp) as endtime
输出条件匹配成功,输出一条,规定写法(这块根据不同的规则写不同的语句)
one row per match
匹配后跳转跳转到下一行(根据不同规则写不同语句)
after match skip to next row
21、Flink CDC了解吗?什么是 Flink SQL CDC Connectors?
在 Flink 1.11 引入了 CDC 机制,CDC 的全称是 Change Data Capture,用于捕捉数据库表的增删改查操作,是目前非常成熟的同步数据库变更方案。
Flink CDC Connectors 是 Apache Flink 的一组源连接器,是可以从 MySQL、PostgreSQL 数据直接读取全量数据和增量数据的 Source Connectors,开源地址:https://github.com/ververica/flink-cdc-connectors。
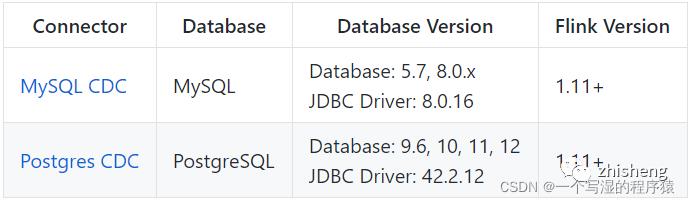
1.13版本支持的 Connectors 如下:
另外支持解析 Kafka 中 debezium-json 和 canal-json 格式的 Change Log,通过Flink 进行计算或者直接写入到其他外部数据存储系统(比如 Elasticsearch),或者将 Changelog Json 格式的 Flink 数据写入到 Kafka:

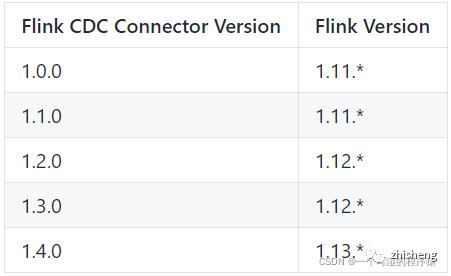
Flink CDC Connectors 和 Flink 之间的版本映射:
22、Flink CDC原理介绍一下
在最新CDC 调研报告中,Debezium 和 Canal 是目前最流行使用的 CDC 工具,这些 CDC 工具的核心原理是抽取数据库日志获取变更。在经过一系列调研后,目前Debezium (支持全量、增量同步,同时支持 MySQL、PostgreSQL、Oracle 等数据库),使用较为广泛。
Flink SQL CDC 内置了 Debezium 引擎,利用其抽取日志获取变更的能力,将 changelog 转换为 Flink SQL 认识的 RowData 数据。(以下右侧是 Debezium 的数据格式,左侧是 Flink 的 RowData 数据格式)。

RowData 代表了一行的数据,在 RowData 上面会有一个元数据的信息 RowKind,RowKind 里面包括了插入(+I)、更新前(-U)、更新后(+U)、删除(-D),这样和数据库里面的 binlog 概念十分类似。
通过 Debezium 采集的数据,包含了旧数据(before)和新数据行(after)以及原数据信息(source),op 的 u 表示是 update 更新操作标识符(op 字段的值 c,u,d,r 分别对应 create,update,delete,reade),ts_ms 表示同步的时间戳。
23、通过CDC设计一种Flink SQL 采集+计算+传输(ETL)一体化的实时数仓
设计图如下:
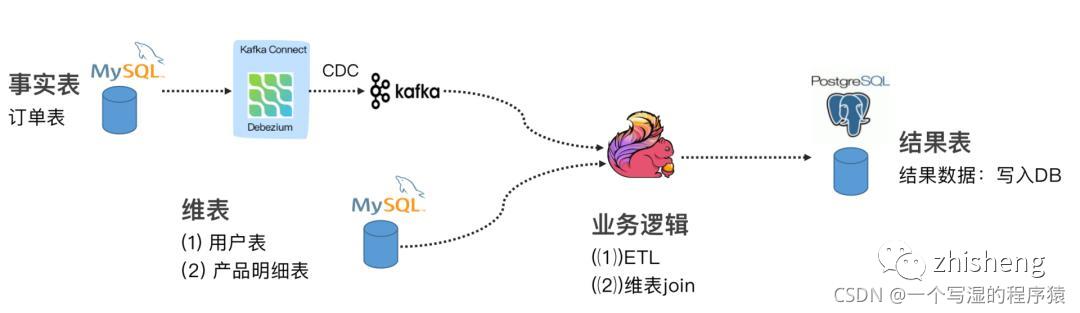
通过 Flink CDC connectors 替换 Debezium+Kafka 的数据采集模块,实现 Flink SQL 采集+计算+传输(ETL)一体化,以Mysql为Source源,Flink CDC中间件为插件,ES或者Kafka,或者其他为Sink,这样设计的优点如下:
开箱即用,简单易上手
减少维护的组件,简化实时链路,减轻部署成本
减小端到端延迟
Flink 自身支持 Exactly Once 的读取和计算
数据不落地,减少存储成本
支持全量和增量流式读取
binlog 采集位点可回溯
24、Flink SQL CDC如何实现一致性保障(源码分析)
Flink SQL CDC 用于获取数据库变更日志的 Source 函数是 DebeziumSourceFunction,且最终返回的类型是 RowData,该函数实现了 CheckpointedFunction,即通过 Checkpoint 机制来保证发生 failure 时不会丢数,实现 exactly once 语义,这部分在函数的注释中有明确的解释。

为实现 CheckpointedFunction,需要实现以下两个方法:
public interface CheckpointedFunction
//做快照,把内存中的数据保存在checkpoint状态中
void snapshotState(FunctionSnapshotContext var1) throws Exception;
//程序异常恢复后从checkpoint状态中恢复数据
void initializeState(FunctionInitializationContext var1) throws Exception;
接下来我们看看 DebeziumSourceFunction 中都记录了哪些状态。
/** Accessor for state in the operator state backend.
* offsetState中记录了读取的binlog文件和位移信息等,对应Debezium中的
*/
private transient ListState<byte[]> offsetState;
/**
* State to store the history records, i.e. schema changes.
* historyRecordsState记录了schema的变化等信息
* @see FlinkDatabaseHistory
*/
private transient ListState<String> historyRecordsState;
我们发现在 Flink SQL CDC 是一个相对简易的场景,没有中间算子,是通过 Checkpoint 持久化 binglog 消费位移和 schema 变化信息的快照,来实现 Exactly Once。
25、Flink SQL GateWay了解吗?
Flink SQL GateWay的概念:
FlinkSql Gateway是Flink集群的“任务网关”,支持以restapi 的形式提交查询、插入、删除等任务,如下图所示:
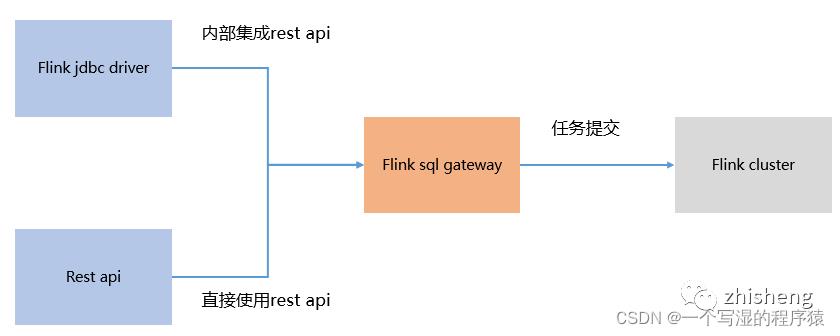
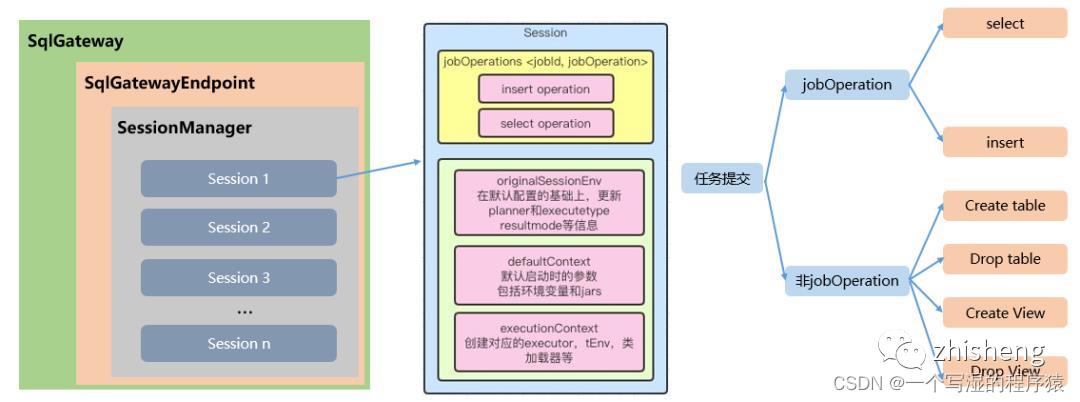
总体架构如下图所示:
26、Flink SQL GateWay创建会话讲解一下?
创建会话流程图如下:
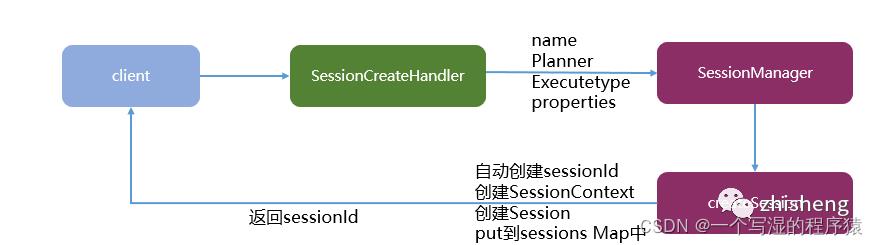
(1)传入参数包含name名称、planner执行引擎(Blink或原生的flink)、executetype(streaming或者batch)、properties(配置参数,如并发度等);
(2)在SessionMnager中,会根据这些参数创建对应的SessionContext;
SessionContext sessionContext= new SessionContext(sessionName, sessionId, sessionEnv, defaultContext);
(3)将创建Session放入Map集合中,最后返回对应的SessionId,方便后续使用。
sessions.put(sessionId,session); return sessionId;
27、Flink SQL GateWay如何处理并发请求?多个提交怎么处理?
sql gateway内部维护SessionManager,里面通过Map维护了各个Session,每个Session的任务执行是独立的。同一个Session通过ExecuteContext内部的tEnv按顺序提交。
28、如何维护多个SQL之间的关联性?
在每个Session中单独维护了tEnv,同一个session中的操作其实是在一个env中执行的。
因此只要是同一个session中的任务,内部使用的tEnv就是同一个。这样就可以实现在session中,先创建一个view,然后执行一个select,最后执行一个insert。
29、SQL字符串如何提交到集群成为代码?
Session中维护了tenv,sql会通过tenv编译生成pipeline(即DAG图),在batch模式下是Plan执行计划;在stream模式下是StreamGraph。
然后Session内部会创建一个ProgramDeployer代码发布器,根据Flink中配置的target创建不同的excutor。最后调用executor.execute方法提交Pipeline和config执行。
end
Flink 从入门到精通 系列文章
基于 Apache Flink 的实时监控告警系统
关于数据中台的深度思考与总结(干干货)
日志收集Agent,阴暗潮湿的地底世界

公众号(zhisheng)里回复 面经、ClickHouse、ES、Flink、 Spring、Java、Kafka、监控 等关键字可以查看更多关键字对应的文章。点个赞+在看,少个 bug 👇以上是关于Flink SQL篇,SQL实操Flink HiveCEPCDCGateWay的主要内容,如果未能解决你的问题,请参考以下文章