LeetCode算法技巧汇总 -- 持续更新,学无止境!
Posted 木兮同学
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了LeetCode算法技巧汇总 -- 持续更新,学无止境!相关的知识,希望对你有一定的参考价值。
此篇是本人 LeetCode 算法刷题技巧总结,还包括刷过的算法题分类,自己记录以便后续二刷三刷,也分享给大家欢迎一起交流探讨。话说现在非常遗憾大学期间没能坚持搞 ACM,出来社会才越发觉得后悔,但是遗憾归遗憾,我还是相信种一棵树是十年前,其次是现在,所以重新再来为时不晚!刷起!!!
文章目录
- 一、数组、链表、跳表
- 二、栈、队列、树
- 三、递归、分治、回溯、DFS、BFS
- 四、贪心算法
- 五、二分查找
- 六、动态规划
- 七、字典树
- 八、并查集
- 九、AVL树、红黑树
- 十、位运算
- 十一、布隆过滤器、LRU 缓存
- 十二、排序算法
- 十三、算法常用库函数小技巧(Java版)
一、数组、链表、跳表
-
小技巧
暴力能解决绝大部分算法题,但纯暴力往往都会超时,要学会剪枝。双指针法,前后指针(左右夹逼),快慢指针。升维:空间换时间。- 要记住:
所有算法都是找重复性,机器的世界很简单(不像人心),基本上只会if...else...、for、while、recursion,也就是它只会做重复的事,重复做事正好也是它所擅长的。 - 看完题目懵逼了怎么办?
- 先看看暴力能否解决
- 案例分解查看基本情况
- 找最近重复子问题
-
实战
二、栈、队列、树
-
小技巧
链表:比较简单直接,多写。- 如果有个东西有
最近相关性的话,可以尝试用栈解决。 单调(递增/递减)栈,算法中比较常用,算法模板类似如下:stack<int> st; // 此处一般需要给数组最后添加结束标志符 for (遍历这个数组) while (栈不为空 && 栈顶元素小于当前元素) 栈顶元素出栈; 更新结果; 当前数据入栈;
-
实战
三、递归、分治、回溯、DFS、BFS
-
小技巧
- 思维误区:
递归不慢,傻递归才慢,要想不傻,剪枝!或缓存中间结果。 - 分治:
分而治之,利用递归将大问题拆成小问题,直到最终子问题,逐步返回子问题结果,直到解决最初的问题。 - 回溯:深度优先搜索的一种,关键在于
不合适就退回上一步,同时将数据状态也回到上一步。 - DFS:(Depth First Search)
深度优先搜索,递归的一种,利用栈做回退,找所有解,或者遍历所有情况中途剪枝(遍所有)。 - BFS:(Breadth First Search)
广度优先搜索,递归的一种,一般利用队列,找最近或者最优解(遍部分)。 - 递归模板如下:
void recursion(level, param1, param2, ...) // 递归终结条件 if (level > MAX_LEVEL) // 处理结果 return; // 处理当前层逻辑 process(...) // 递归到下一层 recursion(level + 1, ...) // 清理当前层
- 思维误区:
-
实战
- 17_电话号码的字母组合
- 39_组合总和
- 40_组合总和II
- 46_全排列
- 47_全排列II
- 60_排列序列
- 77_组合
- 78_子集
- 79_单词搜索
- 90_子集II
- 93_复原IP地址
- 98_验证二叉搜索树
- 104_二叉树的最大深度
- 105_从前序与中序遍历序列构建二叉树
- 111_二叉树的最小深度
- 130_被围绕的区域
- 200_岛屿数量
- 226_翻转二叉树
- 236_二叉树的最近公共祖先
- 297_二叉树的序列化与反序列化
- 733_图像渲染
- 784_字母大小写全排列
- 102_二叉树的层序遍历
- 127_单词接龙
- 126_单词接龙II
- 131_分割回文串
- 169_多数元素
- 37_解数独
- 433_最小基因变化
- 488_祖玛游戏
- 50_Pow_x_n
- 515_在每个树行中找最大值
- 51_N皇后
- 529_扫雷游戏
四、贪心算法
-
小技巧
- 贪心算法是一种在每一步选择中都采取在当前状态下最好或最优的选择,从而希望最终导致的结果是最好或最优的算法。
- 简单地说,问题能够分解成子问题来解决,
子问题的最优解能递推到最终问题的最优解。这种子问题最优解称为最优子结构。 - 贪心、回溯、动态规划对比:
贪心:当下做局部最优判断回溯:能够回退动态规划:最优判断 + 回退
-
实战
五、二分查找
-
好文参考:我作了首诗,保你闭着眼睛也能写对二分查找
-
小技巧
- 二分查找前提:
- 目标函数单调性(
单调递增或者单调递减或者局部单调) - 存在
上下界 - 能够通过
索引访问
- 目标函数单调性(
- 注意
- 慢慢分析,确认边界,
二分查找很容易,但是极易出错。 - 找最小,你能排除的是比中间值大的范围,例如:153_寻找旋转排序数组中的最小值
- 【right > mid】能排除最小值一定不在右边
- 【mid > right】能确定最小值一定在右边
- 而【left < mid】却不能排除最小值不在左边
- 找最大,你能排除的是比中间值小的范围
- 慢慢分析,确认边界,
- 代码模板:
int l = 0, r = nums.length - 1; while (l < r) int mid = (l + r) / 2; if (nums[mid] == target) return result or break; else if(nums[mid] < target) l = mid + 1; else r = mid -1;
- 二分查找前提:
-
实战
六、动态规划
-
小技巧
- 第一步:状态定义
- 第二步:状态转移方程或者 DP 方程
- 第三步:确认边界情况,开始撸码
-
实战
- 1143_最长公共子序列
- 120_三角形最小路径和
- 121_买卖股票的最佳时机
- 122_买卖股票的最佳时机II
- 123_买卖股票的最佳时机III
- 188_买卖股票的最佳时机IV
- 309_最佳买卖股票时机含冷冻期
- 714_买卖股票的最佳时机含手续费
- 152_乘积最大子数组
- 198_打家劫舍
- 213_打家劫舍II
- 221_解码正方形
- 279_完全平方数
- 322_零钱兑换
- 518_零钱兑换II
- 53_最大子序和
- 62_不同路径
- 63_不同路径II
- 980_不同路径III
- 64_最小路径和
- 70_爬楼梯
- 91_解码方法
- 300_最长递增子序列
- 363_矩形区域不超过K的最大数值和
- 403_青蛙过河
- 647_回文子串
- 72_编辑距离
- 746_使用最小花费爬楼梯
- 76_最小覆盖子串
七、字典树
-
小技巧
- 字典树,即 Trie 树,又称单词查找树或键树,是一种树形结构(
每个父节点最多只有26个子节点)。典型的应用是用于统计和排序大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。 - 优点是最大限度的减少无谓的字符串比较,查询效率比哈希高。
- 核心代码:
class Trie private Trie[] children; private final Integer R = 26; private boolean end; Trie() children = new Trie[R]; public void insert(String word) Trie node = this; for (int i = 0; i < word.length(); i++) char c = word.charAt(i); int index = c - 'a'; if (node.children[index] == null) node.children[index] = new Trie(); node = node.children[index]; node.end = true; public boolean search(String word) Trie node = this.searchWith(word); return node != null && node.end; public boolean startsWith(String word) Trie node = this.searchWith(word); return node != null; private Trie searchWith(String word) Trie node = this; for (int i = 0; i < word.length(); i++) char c = word.charAt(i); int index = c - 'a'; if (node.children[index] != null) node = node.children[index]; else return null; return node;
- 字典树,即 Trie 树,又称单词查找树或键树,是一种树形结构(
-
实战
八、并查集
-
小技巧
- 适用场景:组团、配对问题
- 核心代码:
private class UnionFind /** * 连通分量的个数 */ private int count; private int[] parent; public int getCount() return count; /* * 一开始各个节点都是指向自己 */ public UnionFind(int n) this.count = n; parent = new int[n]; for (int i = 0; i < n; i++) parent[i] = i; /* * 查询根节点 */ private int find(int x) while (x != parent[x]) parent[x] = parent[parent[x]]; x = parent[x]; return x; /* * 合并节点 */ public void union(int x, int y) int xRoot = find(x); int yRoot = find(y); if (xRoot == yRoot) return; parent[xRoot] = yRoot; count--;
-
实战
九、AVL树、红黑树
- AVL树
- 即平衡二叉树,
任何节点左右子树高度差不超过 1,通过旋转来进行平衡- 左旋
- 右旋
- 左右旋
- 右左旋
- 即平衡二叉树,
- 红黑树
- 是近似平衡的二叉搜索树,
任何节点左右子树高度差小于 2 倍。它满足以下条件:- 每个节点要么是红色要么是黑色
- 根节点是黑色
- 每个叶子节点是黑色
- 不能有相邻的两个红色节点
- 从任一节点到每个叶子节点的路径都包含相同数目的黑色节点。
- 是近似平衡的二叉搜索树,
十、位运算
判断m是否是奇数:(m & 1) == 1 // 奇数,或者除2余数不为0:m % 2 != 0
x除以2:x >> 1 // mid = (left + right) / 2 --> mid = (left + right) >> 1
清零x最低位的1:x = x & (x - 1) // 10010 -> 10000 、0001000 -> 0000000
得到x最低位为1的x:x = x & -x
将x最右边的n位清零:x & (~0 << n)
获取x的第n位值:(x >> n) & 1
获取x的第n位的幂值:x & (1 << (n-1))
将第n位设为1:x | (1 << n)
将第n位设为0:x & (~(1 << n))
将x最高位至第n位(含)清零:x & ((1 << n) - 1)
将第n位至第0位(含)清零:x & (~((1 << (n + 1))-1))
十一、布隆过滤器、LRU 缓存
- 布隆过滤器
- 一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。
- 优点:空间效率和查询效率都远远超过一般的算法。
- 缺点:有一定的误识别率(能确定“一定不在”,但不能确定“一定在”)和删除困难。
- 例如下图,能确定 C 一定不是目标元素,但不确定 A 和 B 是目标元素,虽然都在布隆过滤器能找到,但是实际上 B 并非目标元素。
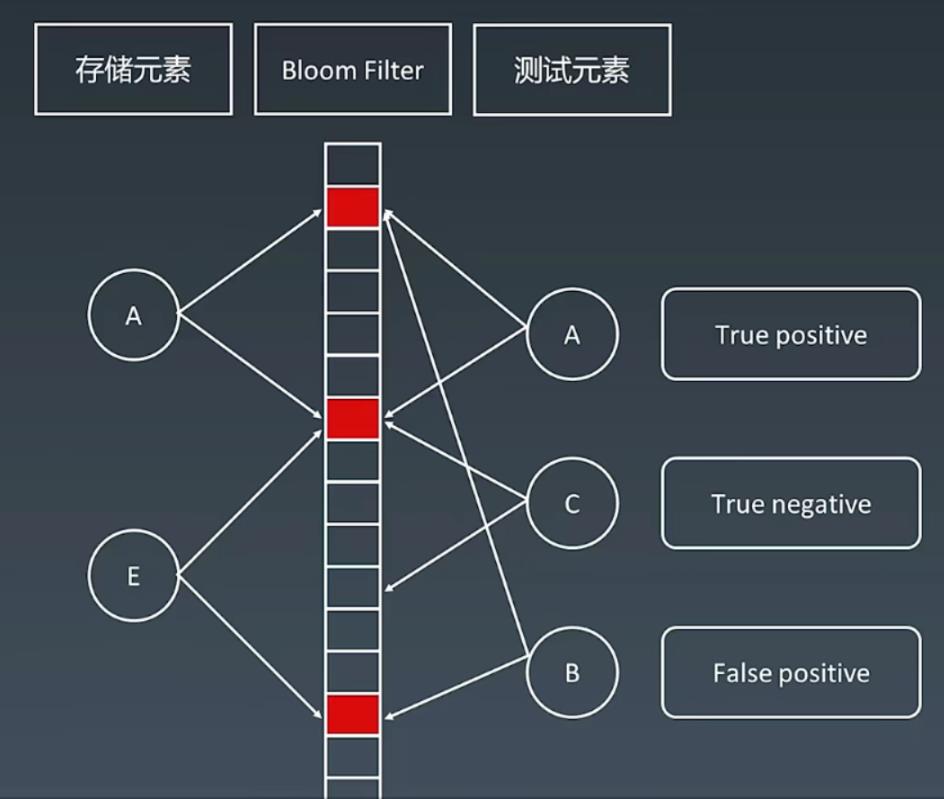
- LRU 缓存
- 全称:least recently used,即最少最近使用到的。
- LFU:least frequently used,最近最不常用置换算法。
- 实战
十二、排序算法
- 十大排序算法,详情请点击 这里 。
十三、算法常用库函数小技巧(Java版)
数组排序:Arrays.sort(nums) // 对nums数组排序
数组填充:Arrays.fill(chars, '-') // 将chars数组全部填充为"-"
数组Copy:Arrays.copyOfRange(chars, 0, 10) // 复制chars中0(包含)-10(不包含)位为一个新数组
翻转字符串:new StringBuilder(strTmp).reverse().toString() // 将strTmp字符串翻转
拼接字符串:String.join(".", tmp) // 用"."拼接tmp(Iterable子类)中的数据为一个串
字符型数字转成Integer数字:减字符0 // 例如'5' - '0' 会等于 5
未完待续...
以上是关于LeetCode算法技巧汇总 -- 持续更新,学无止境!的主要内容,如果未能解决你的问题,请参考以下文章