论文分享小样本文本分类方法 EGNN-Proto:Few-Shot Text Classification with Edge-Labeling Graph Network-Based Proto
Posted vector<>
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文分享小样本文本分类方法 EGNN-Proto:Few-Shot Text Classification with Edge-Labeling Graph Network-Based Proto相关的知识,希望对你有一定的参考价值。
- 题目:Few-Shot Text Classification with Edge-Labeling Graph Neural Network-Based Prototypical Network
- 链接:https://aclanthology.org/2020.coling-main.485.pdf
- 源码:-
- 时间:2020.12
- 会议:COLING (CCF-B)
- 机构:北京大学
- 摘要:提出了一个小样本文本分类模型:EGNN-Proto。利用预训练语言模型BERT学习文本嵌入,并通过edge-labeling graph neural network改进了prototypical network,以更好地刻画和利用文本之间的关系,从而在小样本的文本分类任务中获得更好的性能。
- 其他:这篇文章去掉参考文献,一共就4页,方法也比较简单,但是确实一篇B诶,留下羡慕的眼泪~😭😭
目录
介绍
动机:
- 第一:现存的小样本文本分类方法都采用GloVe词嵌入结合CNN或RNN结构进行文本嵌入,而不是近年来提出的更高级的预训练语言模型,如ELMo 、GPT 和BERT。
- 第二:这些方法更多地关注文本本身的语义特征,而忽略了文本之间的潜在关系
贡献:
- 提出一个小样本文本分类模型 Edge-Labeling Graph Neural Network-Based Prototypical Network (EGNN-Proto)。据我们所知,我们的模型是第一个将图神经网络与 prototypical network 相结合的模型,也是第一个利用 edge-labeling graph neural network 来解决文本分类问题的模型。
- 该方法在两个小样本文本分类数据集ARSC和 FewRel上的性能优于目前最先进的模型。
方法
小样本文本分类
- 采用元学习的策略,这里是小样本的基础知识,不做过多赘述,可以参考:【小样本基础】N-way K-shot 模式和训练策略
- 目标是对训练集进行元学习,然后提取可转移的知识,使在支持集S上进行更好的小样本学习,并尽可能准确地对查询集Q中的样本进行分类。
方法概述
该模型分为三个部分:
- 1️⃣text embedding:从文本中提取语义特征,并将原始文本序列转换为文本嵌入
- 2️⃣edge-labeling graph neural network:对文本的类内相似度和类间不相似度进行建模,从而度量文本样本之间的潜在关系。
- 3️⃣prototypical network:用prototypical network 分类
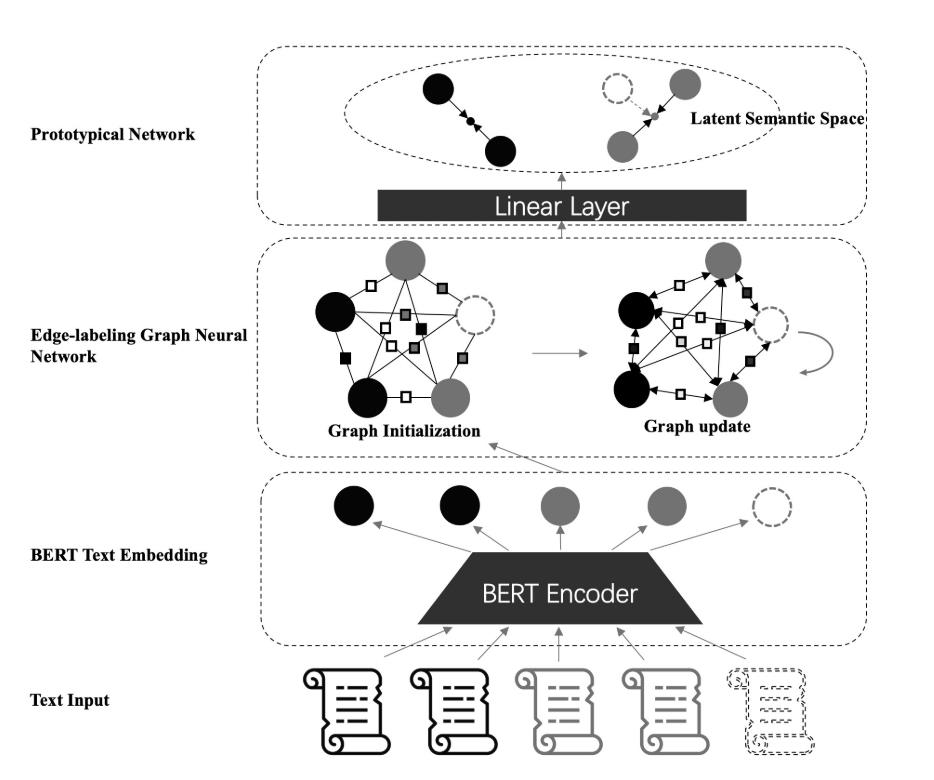
1️⃣Text Embedding
- bert 由12 层 Transformer Encoder 组成,每一层encoder包含1个自注意力层和一个全连接层。
- 每一个输入token先被映射为一个已知的d维的嵌入,然后在每次遍历BERT编码器层时逐步转换。
- 从理论上讲,每个编码层的词嵌入输出都包含了整个文本的特征。
- 倒数第二层[CLS]位置上的输出作为整个文本t的文本嵌入,表示为 e = f e m b ( t ∣ θ e m b ) e=f_e m b\\left(t \\mid \\theta_e m b\\right) e=femb(t∣θemb),其中 θ e m b \\theta_e m b θemb表示文本嵌入中的参数,在训练时进行微调。
2️⃣Ege-labeling graph neural network
- edge-labeling graph neural network 是在这篇文章中 Edge-Labeling Graph Neural Network for Few-shot Learning被提出来的,被应用于小样本图片分类。
- 首先构造一个全连通图,其中每个节点代表每个样本,每个边代表连通节点之间的关系。
- 结点特征:由第一步得到的文本嵌入进行初始化
- 边特征:根据连接结点是否属于同一类初始化边缘特征,交替更新边缘特征直至收敛。
3️⃣Prototypical network
- 本篇文章没有直接通过边特征和节点特征计算查询节点的预测概率,而是引入了原型网络Prototypical network,从更一般的角度对样本进行分类。
- 原型网络计算出一个原型向量作为每个类的表示,该表示是类中support样本的平均向量表示。
- 比较所有原型向量与查询向量之间的距离,然后对查询样本进行分类。
Prototypical network
- 先把样本投影到一个空间,计算每个样本类别的中心,在分类的时候,通过对比目标到每个中心的距离,从而分析出目标的类别.
实验
数据集
Amazon Review Sentiment Classification (ARSC)
- ARSC数据集包含了亚马逊上23种产品的英文评论,我们在该数据集上创建了一个12-way 5-shot 的文本分类任务。
Few-shot Relation classification dataset (FewRel)
- FewRel 是一个大规模的监督数据集,包含来自维基百科的100个关系上的70000个实例。在我们的实验中,创建了 5-way 5-shot 和10-way 5-shot 的实验。
结果

ARSC和FewRel实验结果如上图所示。EGNN-Proto模型在ARSC数据集上的准确率为88.26%,比现有的最先进的感应网络模型提高了2.6%。在FewRel数据集上,EGNN-Proto算法的精度也有很大提高。
结论
本工作解决了小样本文本分类的问题。我们利用高级的预训练语言模型BERT来提取文本的语义特征。然后引入edgelabeling graph neural network,进一步模拟文本之间的潜在关系。最后,我们利用一个原型网络对查询文本进行分类。在实验中,我们的方法在ARSC和FewRel数据集上都取得了最先进的性能。在未来的工作中,我们可以考虑将我们的方法推广到其他小样本的NLP问题,甚至非NLP任务。
以上是关于论文分享小样本文本分类方法 EGNN-Proto:Few-Shot Text Classification with Edge-Labeling Graph Network-Based Proto的主要内容,如果未能解决你的问题,请参考以下文章