OpenCV-Python实战(23)——将OpenCV计算机视觉项目部署到云端
Posted 盼小辉丶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了OpenCV-Python实战(23)——将OpenCV计算机视觉项目部署到云端相关的知识,希望对你有一定的参考价值。
OpenCV-Python实战(23)——将OpenCV计算机视觉项目部署到云端
0. 前言
我们已经学习了如何将在 Web 端部署 OpenCV 计算机视觉项目,但是部署完成的项目只能在局域网中进行访问,如果想要在广域网中进行访问,需要将其部署到云端将其公开。
要将应用程序部署到云端,有很多选择,例如,谷歌云,Microsoft Azure,亚马逊云,阿里云,腾讯云等等。但是上述云环境均需要一定费用,作为初学者或者想要简单测试的话,可以使用 PythonAnywhere,它是一个 Python 在线集成开发环境 (integrated development environment, IDE) 和 Web 托管环境,可以轻松地创建和运行 Python 程序,并且可以创建免费的初学者账户。在本文中,我们将学习如何在 PythonAnywhere 上部署 Flask OpenCV 应用程序。
1. 创建 PythonAnywhere 站点环境
PythonAnywhere 使用起来非常简单,是托管基于机器学习的 Web 应用程序的推荐方式。
为了完整展示如何使用 PythonAnywhere 将 Flask 应用程序部署到云端,我们将从创建站点开始讲解:
- 创建一个
PythonAnywhere帐户,作为初学者,我们创建初学者账户就足够了:

- 注册后可以看到一个简单的新手教程(可以看到,此处创建了
panxiaohui用户),可以快速预览PythonAnywhere的功能,或者也可以选择跳过:

- 单击 “
Open Web tab” 菜单:

- 单击 “
Add a new web app” 按钮添加一个Web应用

- 此时,已准备好创建新的 Web 应用程序,单击 “
Next”:

- 由于我们要使用
Flask框架,因此单击选择Flask:
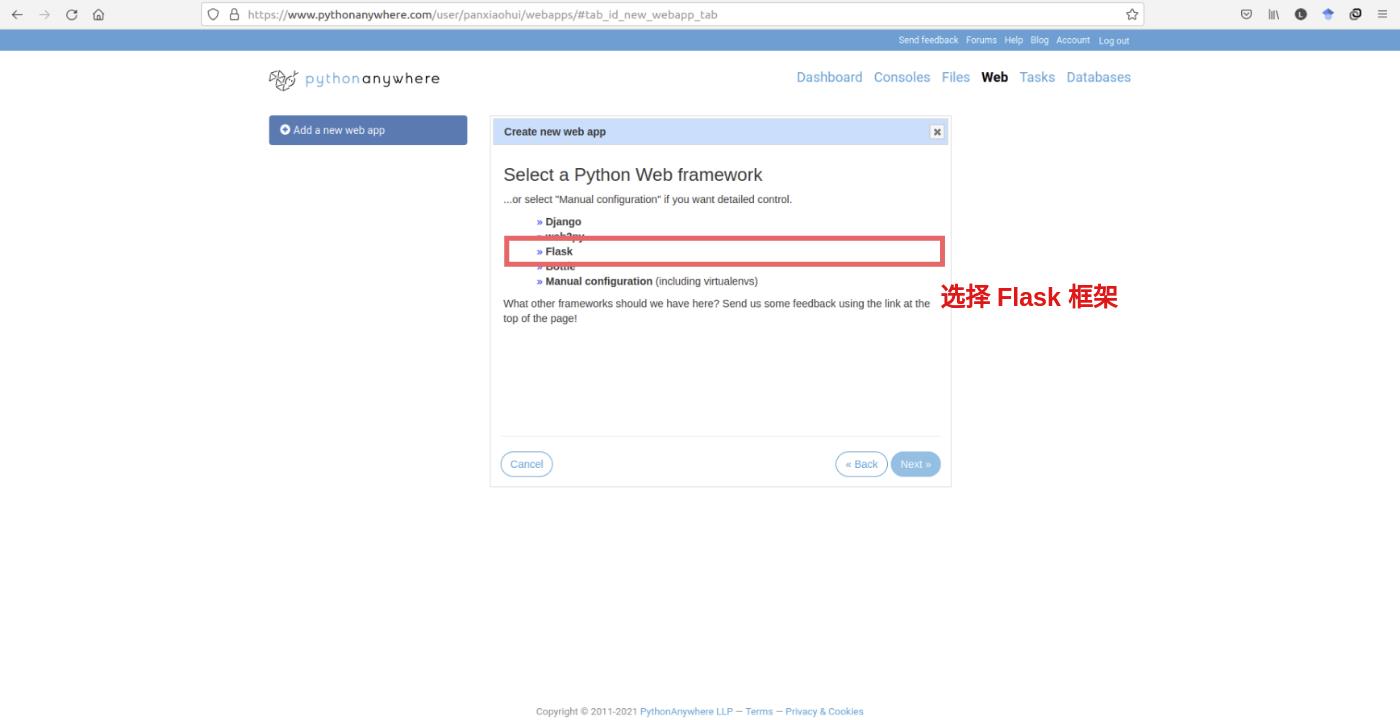
- 单击所需版本的
Python后,点击Next:

- 最后设置项目路径后,单击
Next,完成项目创建:

至此已经完成创建了 Flask 应用程序,可以通过访问 https://user_name.pythonanywhere.com 看到该应用程序(例如,我的用户名为 panxiaohui,因此 URL 为 https://panxiaohui.pythonanywhere.com)。
2. 将 OpenCV 计算机视觉项目部署到云端
完成项目的创建后,就可以上传编写完成的计算机视觉程序了。
- 编写
flask_app.py文件解析请求并构建响应:
from flask import Flask, request, jsonify, make_response
import urllib.request
from image_processing import ImageProcessing
import cv2
import numpy as np
app = Flask(__name__)
od = ImageProcessing()
@app.errorhandler(400)
def bad_request(e):
# return also the code error
return jsonify("status": "Not ok", "message": "This server could not understand your request"), 400
@app.errorhandler(404)
def not_found(e):
# return also the code error
return jsonify("status": "Not found", "message": "Route not found"), 404
@app.errorhandler(500)
def not_found(e):
# return also the code error
return jsonify("status": "Internal error", "message": "Internal error occurred in server"), 500
@app.route('/detect', methods=['GET', 'POST', 'PUT'])
def object_dection():
if request.method == 'GET':
if request.args.get('url'):
with urllib.request.urlopen(request.args.get('url')) as url:
image_byte = url.read()
image_array = np.asarray(bytearray(image_byte), dtype=np.uint8)
output = od.obj_detection(image_byte)
img_opencv = cv2.imdecode(image_array, -1)
for obj in output:
left, top, right, bottom = obj['box']
name = obj['name']
confidence = str(obj['confidence'])
label = name + ': ' + confidence
labelSize, baseLine = cv2.getTextSize(label, cv2.FONT_HERSHEY_SIMPLEX, 1, 2)
yLeftBottom = max(top, labelSize[1])
# 绘制检测框、类别名和置信度
cv2.rectangle(img_opencv, (left, top), (right, bottom), (0, 255, 255), 2)
cv2.rectangle(img_opencv, (left, yLeftBottom - labelSize[1]), (left + labelSize[0], yLeftBottom + 0), (0, 255, 0), cv2.FILLED)
cv2.putText(img_opencv, label, (left, yLeftBottom), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 0), 2)
retval, buffer = cv2.imencode('.jpg', img_opencv)
# 构造响应消息
response = make_response(buffer.tobytes())
response.headers['Content-Type'] = 'image/jpeg'
return response
else:
return jsonify('status': 'Bad request', 'message': 'Parameter url is not present'), 400
elif request.method == 'POST':
if request.files.get('image'):
return jsonify('status': 'Ok', 'result': od.obj_detection(request.files['image'].read())), 200
else:
return jsonify('status': 'Bad request', 'message': 'Parameter image is not present'), 400
else:
return jsonify('status': 'Failure', 'message': 'PUT method not supported for API'), 405
@app.route('/', methods=['GET'])
def info_view():
# List of routes for this API
output =
'info': 'GET /',
'detect object via POST': 'POST /detect',
'detect object via GET': 'GET /detect',
return jsonify(output), 200
if __name__ == '__main__':
app.run(debug=True)
- 编写
image_processing文件,用于检测目标物体:
import os
import cv2
import numpy as np
class ImageProcessing(object):
def __init__(self):
# 在构造函数中实例化 SSD 深度学习模型用于目标检测
# "/home/panxiaohui/mysite/MobileNetSSD_deploy.prototxt.txt" 是上传的模型位置
self.file_prototxt = "/home/panxiaohui/mysite/MobileNetSSD_deploy.prototxt.txt"
# "/home/panxiaohui/mysite/MobileNetSSD_deploy.caffemodel" 是上传的模型权重位置
self.file_caffemodel = "/home/panxiaohui/mysite/MobileNetSSD_deploy.caffemodel"
self.class_names = 0: 'background', 1: 'aeroplane', 2: 'bicycle', 3: 'bird', 4: 'boat', 5: 'bottle', 6: 'bus', 7: 'car',8: 'cat', 9: 'chair', 10: 'cow', 11: 'diningtable', 12: 'dog', 13: 'horse', 14: 'motorbike', 15: 'person', 16: 'pottedplant', 17: 'sheep', 18: 'sofa', 19: 'train', 20: 'tvmonitor'
self.net = cv2.dnn.readNetFromCaffe(self.file_prototxt, self.file_caffemodel)
def obj_detection(self, image):
image_array = np.asarray(bytearray(image), dtype=np.uint8)
img_opencv = cv2.imdecode(image_array, -1)
# 图像预处理
blob = cv2.dnn.blobFromImage(img_opencv, 0.007843, (300, 300), (127.5, 127.5, 127.5))
# 前向计算
self.net.setInput(blob)
detections = self.net.forward()
# 预处理后图像尺寸
dim = 300
output = []
for i in range(detections.shape[2]):
confidence = detections[0, 0, i, 2]
if confidence > 0.1:
# 获取类别标签
class_id = int(detections[0, 0, i, 1])
# 获取对象位置的坐标
left = int(detections[0, 0, i, 3] * dim)
top = int(detections[0, 0, i, 4] * dim)
right = int(detections[0, 0, i, 5] * dim)
bottom = int(detections[0, 0, i, 6] * dim)
# 图像尺寸的比例系数
heightFactor = img_opencv.shape[0] / dim
widthFactor = img_opencv.shape[1] / dim
# 检测框坐标
left = int(widthFactor * left)
top = int(heightFactor * top)
right = int(widthFactor * right)
bottom = int(heightFactor * bottom)
if class_id in self.class_names:
obj = 'name':self.class_names[class_id], 'confidence':float(confidence), 'box': [left, top, right, bottom]
output.append(obj)
return output
- 编写完成代码后,就可以上传代码和模型权重等项目文件了,首先在
Web菜单的Code部分中单击go to directory:

- 使用 “
Upload a file” 按钮将文件上传到云端,包括:flask_app.py、image_processing.py、MobileNetSSD_deploy.prototxt.txt和MobileNetSSD_deploy.caffemodel(项目中使用了MobileNet-SSD目标检测模型,这里对训练后MobileNet-SSD模型架构和模型权重参数文件进行压缩供大家进行下载,也可以自己构建模型训练获得MobileNet-SSD模型参数):

- 上传文件完成后,下一步是设置虚拟环境,通过单击
Open Bash控制台来打开bash控制台:

- 打开控制台后,运行以下命令:
可以看到提示从$ mkvirtualenv --python=/usr/bin/python3.9 my-virtualenv$更改为(my-virtualenv)$,这意味着已经激活了虚拟环境,接下来安装必需的包 (flask和opencv-contrib-python):
可以使用以下命令重新激活已经创建的虚拟环境:(my-virtualenv)$ pip install flask (my-virtualenv)$ pip install opencv-contrib-python$ workon my-virtualenv

- 至此,项目已经可以说基本完成了,最后一步是通过单击菜单中的
Web选项中 “Reload” 来重新加载上传的项目:
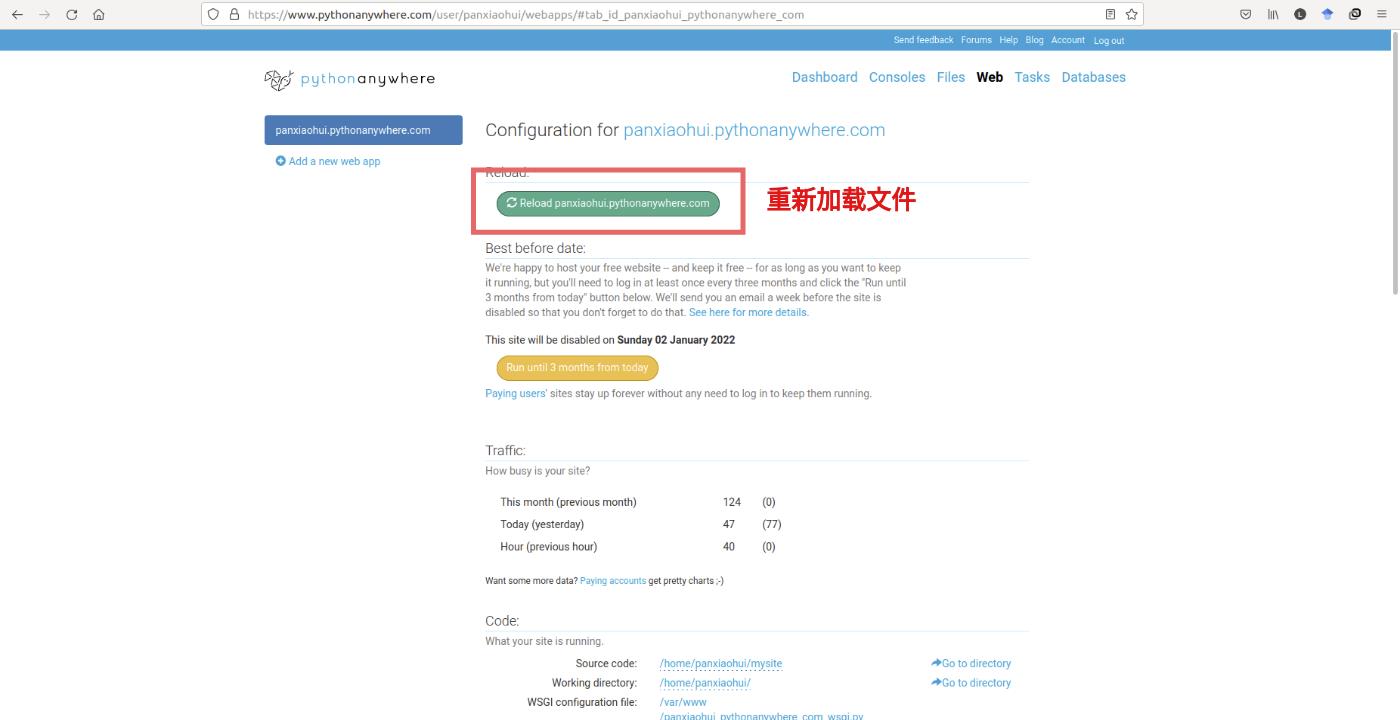
3. 测试部署在云端的计算机视觉项目
接下来,我们测试上传到 PythonAnywhere 的计算机视觉 API,可以使用 https://user_name.pythonanywhere.com/ 访问(其中 user_name 为用户名,例如可以访问 https://panxiaohui.pythonanywhere.com/):

接下来可以看到 JSON 响应,这是因为我们使用 route() 装饰器将 info_view() 函数绑定到 URL /,在访问 https://panxiaohui.pythonanywhere.com/ 时,将获得此 API 的路由列表。
接下来,我们使用 API 进行测试目标检测任务,首先构造 GET 请求:
https://panxiaohui.pythonanywhere.com/detect?url=https://raw.githubusercontent.com/opencv/opencv/master/samples/data/lena.jpg
其中,参数 url 的值为网络图片有效负载,检测结果如下所示:

最后,我们对部署到 PythonAnywhere 的目标检测 API 执行 POST 请求:
import cv2
import numpy as np
import requests
from matplotlib import pyplot as plt
def show_img_with_matplotlib(color_img, title, pos):
img_RGB = color_img[:, :, ::-1]
ax = plt.subplot(1, 1, pos)
plt.imshow(img_RGB)
plt.title(title, fontsize=10)
plt.axis('off')
FACE_DETECTION_REST_API_URL = "http://panxiaohui.pythonanywhere.com/detect"
IMAGE_PATH = "test_img.jpg"
# 加载图像并构造有效负载
image = open(IMAGE_PATH, "rb").read()
payload = "image": image
# 提交 POST 请求
r = requests.post(FACE_DETECTION_REST_API_URL, files=payload)
# 打印响应信息
print("status code: ".format(r.status_code))
print("headers: ".format(r.headers))
print("content: ".format(r.json()))
# 解析响应
json_data = r.json()
result = json_data['result']
# 将加载图像转换为 opencv 格式
image_array = np.asarray(bytearray(image), dtype=np.uint8)
img_opencv = cv2.imdecode(image_array, -1)
for obj in result:
left, top, right, bottom = obj['box']
name = obj['name']
confidence = str(obj['confidence'])
label = name + ': ' + confidence
labelSize, baseLine = cv2.getTextSize(label, cv2.FONT_HERSHEY_SIMPLEX, 1, 2)
yLeftBottom = max(top, labelSize[1])
# 绘制检测框、类别及置信度
cv2.rectangle(img_opencv, (left, top), (right, bottom), (0, 255, 255), 2)
cv2.rectangle(img_opencv, (left, yLeftBottom - labelSize[1]), (left + labelSize[0], yLeftBottom + 0), (0, 255, 0), cv2.FILLED)
cv2.putText(img_opencv, label, (left, yLeftBottom), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 0), 2)
# 可视化
fig = plt.figure(figsize=(8, 6))
plt.suptitle("Using object API at http://panxiaohui.pythonanywhere.com/detect", fontsize=14, fontweight='bold')
show_img_with_matplotlib(img_opencv, "object detection", 1)
plt.show()

通过测试,可以确认我们的目标检测 API 已启动并且可以完美的在云端运行。
小结
在本系列的最后,我们学习了如何使用提供 Web 托管服务的 PythonAnywhere 将 Flask 应用程序部署到云端,我们使用 OpenCV、Keras 和 Flask 开发了完整的 Web 计算机视觉应用程序,并测试构建浏览器的请求(包括 GET 和 POST),确认了我们的目标检测 API 已启动并且可以完美的在云端运行。
系列链接
OpenCV-Python实战(1)——OpenCV简介与图像处理基础
OpenCV-Python实战(2)——图像与视频文件的处理
OpenCV-Python实战(3)——OpenCV中绘制图形与文本
OpenCV-Python实战(4)——OpenCV常见图像处理技术
OpenCV-Python实战(5)——OpenCV图像运算
OpenCV-Python实战(6)——OpenCV中的色彩空间和色彩映射
OpenCV-Python实战(7)——直方图详解
OpenCV-Python实战(8)——直方图均衡化
OpenCV-Python实战(9)——OpenCV用于图像分割的阈值技术
OpenCV-Python实战(10)——OpenCV轮廓检测
OpenCV-Python实战(11)——OpenCV轮廓检测相关应用
OpenCV-Python实战(12)——一文详解AR增强现实
OpenCV-Python实战(13)——OpenCV与机器学习的碰撞
OpenCV-Python实战(14)——人脸检测详解
OpenCV-Python实战(15)——面部特征点检测详解
OpenCV-Python实战(16)——人脸追踪详解
OpenCV-Python实战(17)——人脸识别详解
OpenCV-Python实战(18)——深度学习简介与入门示例
OpenCV-Python实战(19)——OpenCV与深度学习的碰撞
OpenCV-Python实战(20)——OpenCV计算机视觉项目在Web端的部署
OpenCV-Python实战(21)——OpenCV人脸检测项目在Web端的部署
OpenCV-Python实战(22)——使用Keras和Flask在Web端部署图像识别应用
以上是关于OpenCV-Python实战(23)——将OpenCV计算机视觉项目部署到云端的主要内容,如果未能解决你的问题,请参考以下文章
《Nuitka打包实战指南》实战打包OpenCV-Python
《PyInstaller打包实战指南》第二十三节 单文件模式打包OpenCV-Python
《PyInstaller打包实战指南》第二十三节 单文件模式打包OpenCV-Python
OpenCV-Python实战(番外篇)——OpenCV中利用鼠标事件动态绘制图形