关于 Java 18 你想知道的一切
Posted 干货满满张哈希
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了关于 Java 18 你想知道的一切相关的知识,希望对你有一定的参考价值。
个人创作公约:本人声明创作的所有文章皆为自己原创,如果有参考任何文章的地方,会标注出来,如果有疏漏,欢迎大家批判。如果大家发现网上有抄袭本文章的,欢迎举报,并且积极向这个 github 仓库 提交 issue,谢谢支持~
如果你不喜欢这个文字版的,可以参考官方做的这个 Java 内幕新闻第 20 期 - 关于 Java 18 你想知道的一切:
-B站视频地址
-知乎视频地址
Java 18 于今天(2022-3-22)发布 GA 版本了,今天也是我和我宝宝领证一周年的日子,为了纪念今天,特此奉上 - 关于 Java 18 你想知道的一切
正式发布的新特性
简易 HTTP 服务器
相关 JEP:
- JEP 408: Simple Web Server
如果大家想要深入了解用法,强烈大家看一下这个视频:Java内幕新闻第16期[熟肉]-Java18 web服务器
为了方便大家快速建立一个 HTTP 服务器来挂载一些静态文件,实现快速简易测试,演示某些功能,JDK 18 附带了一个简易的 HTTP 服务器 - 在 bin 目录下多了一个工具 jwebserver
可以通过下面的命令行来启动一个简易的 HTTP 服务器:

可以指定的参数包括:
-b addror--bind-address addr:指定绑定地址,默认 addr 是:127.0.0.1 or ::1 (loopback)-d diror--directory dir:指定挂载目录,默认 dir 是当前目录,挂载后可以获取文件夹内的内容-o levelor--output level:指定日志级别,默认 level 是 info(可以是:none | info | verbose)-p portor--port port:指定端口,默认 port 是 8000
访问可以看到这个相当于是挂载目录的简单文件服务器:

同时也能在启动的 console 中看到请求的 accesslog:
127.0.0.1 - - [March 21st, 2022:14:25:48 +0800] "GET / HTTP/1.1" 200 -
它只服务于 HEAD 和 GET 请求,不支持身份验证、访问控制、加密等。
你可以通过使用 com.sun.net.httpserver 下的类,自定义这个 HTTP 服务器的配置,自定义 HttpHandler,Filter 这些,例如:

互联网地址解析 SPI
相关 JEP:
原来 Java 中的互联网地址解析是内置的解析器,即使用本地 ‘hosts’ 文件和 DNS 的组合;Java 18 之后,为互联网地址解析定义了 SPI,这样,‘java.net.InetAddress’ 可以使用除内置的解析器之外的解析器。
这个主要是为了:
- 为 Project Loom 做准备:‘java.net.InetAddress’ 的解析操作目前在操作系统调用中阻塞。这对于 Loom 的虚拟线程来说是个问题,因为这也会阻塞虚拟线程使得调度器无法切换到另一个虚拟线程。通过抽象这个为 SPI 来提供另一个解析器实现非阻塞的 DNS 解析。
- 兼容新的网络协议:可以实现新的解析协议的无缝集成,比如 DNS over QUIC/TLS/HTTPS。
- 定制改造解析结果:使框架和应用程序能够更好地控制解析结果,并允许现有的库使用自定义解析器进行改造。
- 更好的测试:比如你可以实现自己的 SPI 模拟远程请求实际解析到本地的某些地址等等。
这个 SPI 究竟是哪个类,可以参考 java.util.ServiceLoader 的使用,通过里面的 api 指定如下 SPI 接口的实现:java.net.spi.InetAddressResolverProvider
Finalization 的 Deprecate For Removal
相关 JEP:
Java finalization 是 Java 一开始就有的特性,当初设计出来的时候是为了让我们避免资源泄漏:当没有人引用保存资源的实例时然后执行一段代码来回收资源。本着这个思路,就会联想到垃圾回收器知道什么时候是要回收一个对象,所以就利用垃圾回收的机制来执行这段代码就好了。所以,设计出 Object 的 finalize() 方法,Java 类可以覆盖这个方法,在里面填写关闭资源的代码。这段代码会在对象被回收的某个时候被调用。但是这种机制带来了如下几个问题:
- 假设你的 JVM 老年代增长的很慢,如果你的需要 finalize 的对象进入了老年代,那么可能很久对象都不会被回收。
- 假设你的需要 finalize 的对象突然增多,创建这种对象的速度要快于 GC 进行收集以及执行
finalize()方法的速度,这样会造成雪崩 - 由于无法确定哪个线程执行
finalize()方法,按照什么顺序执行这些finalize()方法,因此在这个方法中不能有影响线程安全的代码,以及乱引用外部对象导致对象又“复活”了
并且,这种 Finalization 还是一个历史包袱,所有的垃圾回收器代码都要不断维护这个执行这些 finalize() 方法的机制,影响了这些垃圾回收器的迭代,并且由于 Finalization 的存在导致 GC 要占用的内存页增加了,ZGC 估计 1.5% 的内存占用只是为了 Finalization 用的。
所以,其实从 Java 9 开始就标记 Object 的 finalize() 方法为 Deprecated 了,现在从 Java 18 开始,正式标记为 Deprecated for removal,也就是不久的将来,这个方法会被完全去掉。
如何验证移除 Finalization 对你的项目是否有影响?
如果你使用了 JFR,可以通过 Java 18 后加入的 JFR 事件 jdk.FinalizerStatistics,来看出你的 JVM 中是否有 Finalization
如果你没有开启 JFR,那么我推荐你使用下 JFR,很好用,参考:JFR 全解
如果你不想通过 JFR,那么你可以先在你的程序运行的时候,记录下:
- JVM 内存使用情况,建议开启 Native Memory Tracking,参考:JVM相关 - 深入理解 System.gc()
- 进程相关的文件描述符数量
- Direct Buffer 以及 MMAP Buffer 使用量:可以通过 JMX 的 MBean 查看,例如:

记录好之后,启动参数加上 --finalization=disabled,这个参数让所有的 Finalization 机制失效,对比下内存用量,判断是否依赖了 Finalization。
默认编码为 UTF-8
相关 JEP:
Java 中很多方法都带有字符编码集的参数,例如:
new String(new byte[10]);
new String(new byte[10], Charset.defaultCharset());
如果不传的话,就是使用系统的默认字符集,例如 Linux, MacOS 上面一般是 UTF-8,Windows 上面就不是 UTF-8 了。从 Java 18 开始,默认字符集不再和操作系统有关,就是 UTF-8。
如果你的运行操作系统就是 Linux, MacOS,或者你的启动参数本身有 -Dfile.encoding=COMPAT 那么基本对你没有任何影响。
如果你想改回原来那种根据操作系统环境指定默认字符集的方式,可以使用这个启动参数:-Dfile.encoding=COMPAT
通过方法句柄(MethodHandle)重新实现 Java 反射接口
相关 JEP:
在 JDK 18 之前,有三种用于反射操作的 JDK 内部机制:
- 虚拟机本地方法
- 动态生成的字节码 stub (Method::invoke, Constructor::newInstance) 和依赖 Unsafe 类的字段访问(Field::get and set):主要在
java.lang.reflect下 - 方法句柄(MethodHandle 类):主要在
java.lang.invoke下
每次给 Java 添加一些新的结构特性,例如 Record 这些,都需要同时修改这三个的代码,太费劲了。所以 Java 18 中通过使用 java.lang.invoke 下的类实现了第二种的这些 API,来减少未来添加新的语言特性所需要的工作量。这也是为了 Project Valhalla 的原生值类型(可以栈上分配,类似于 c 语言的 struct,还有其他语言的 inline class)做准备。
可编译的 Javadoc 代码段
相关 JEP:
干净整洁更新及时并且有规范的示例的 API 文档会让你获益良多,并且如果 API 文档的代码如果能编译,能随着你的源码变化而变化,就更完美了,Java 18 就给了 Javadoc 这些特性。
我们编写一个 Maven 项目试一下(代码库地址:https://github.com/HashZhang/code-snippet-test )
首先,我们想在普通 maven 项目的 src/main/java 和 src/test/java 以外新添加一个目录 src/demo/java 用于存放示例代码。因为示例代码我们并不想打包到最后发布的 jar 包,示例代码也需要编译,所以我们把这个示例代码目录标记为测试代码目录(为啥不放入 src/test/java,因为我们还是想区分开示例代码与单元测试代码的):

我们需要 maven 插件来执行生成 javadoc,同时我们要指定代码段扫描的目录(即你的源码中,执行代码段文件所处于的目录,这个目录我们这里和源码目录 src/main/java 隔离开了,是 src/demo/java):

首先,我们创建我们的 API 类,即:

可以看到,我们在注释中指定了代码段读取的文件以及读取的区域,我们现在来编写示例代码:

从示例代码中,我们可以看到对于引用区域的指定(位于 @start 与 @end 之间).
目前项目结构是:

执行 mvn javadoc:javadoc,在 target/site 目录下就能看到生成的 Javadoc,Javadoc 中可以包含你项目中的代码段:

你还可以高亮你的一些注释,或者使用 CSS 编辑样式,这里就不再赘述了
预览的新特性
Switch 模式匹配(第二次预览)
Java 17 中正式发布了 Sealed Class(封闭类),在这特性的基础上,我们可以在 Switch 中进行模式匹配了,举一个简单的例子:
在某些情况下,我们可能想枚举一个接口的所有实现类,例如:
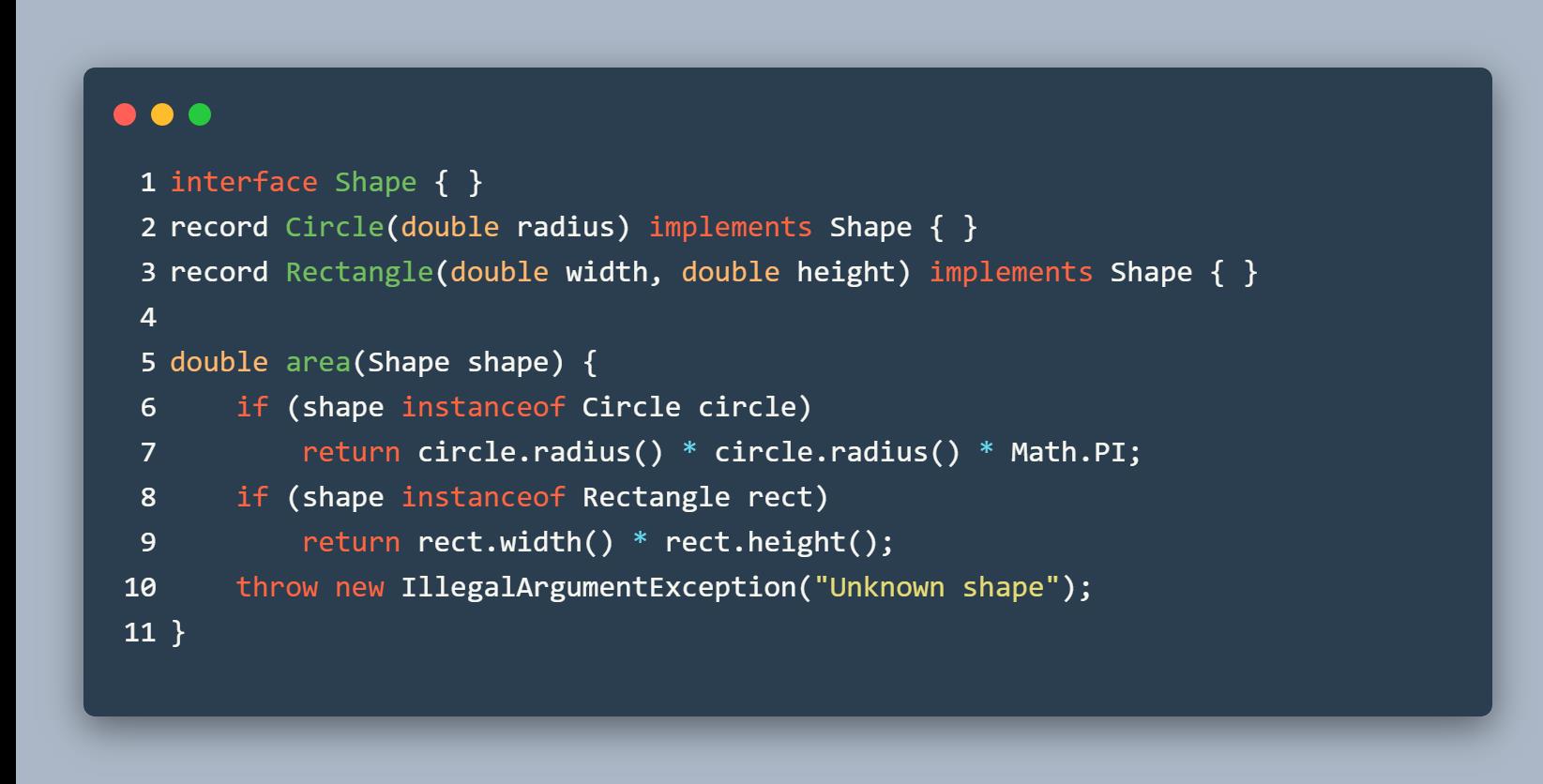
我们如何能确定我们枚举完了所有的 Shape 呢? Sealed Class 这个特性为我们解决这个问题,Sealed Class 可以在声明的时候就决定这个类可以被哪些类继承:

Sealed Class (可以是 abstract class 或者 interface )在声明时需要指定所有的实现类的名称。针对继承类,有如下限制:
- Sealed Class 的继承类必须和 Sealed Class 在同一个模块下,如果没有指定模块,就必须在同一个包下
- 每个继承类必须直接继承 Sealed Class,不能间接继承
- 每个继承类必须是下面三种之一:
- final 的 class,Java Record 本身就是 final 的
- sealed 的 class,可以进一步指定会被哪些子类实现
- non-sealed 的 class,也是一种扩展,但是打破 Sealed Class 的限制,Sealed Class 不知道也不关心这种的继承类还会有哪些子类。
举个例子即:

加入了 Switch 模式匹配之后,上面的 area 方法就可以改写成(我们需要在编译参数和启动参数中加上 --enable-preview 启用预览):
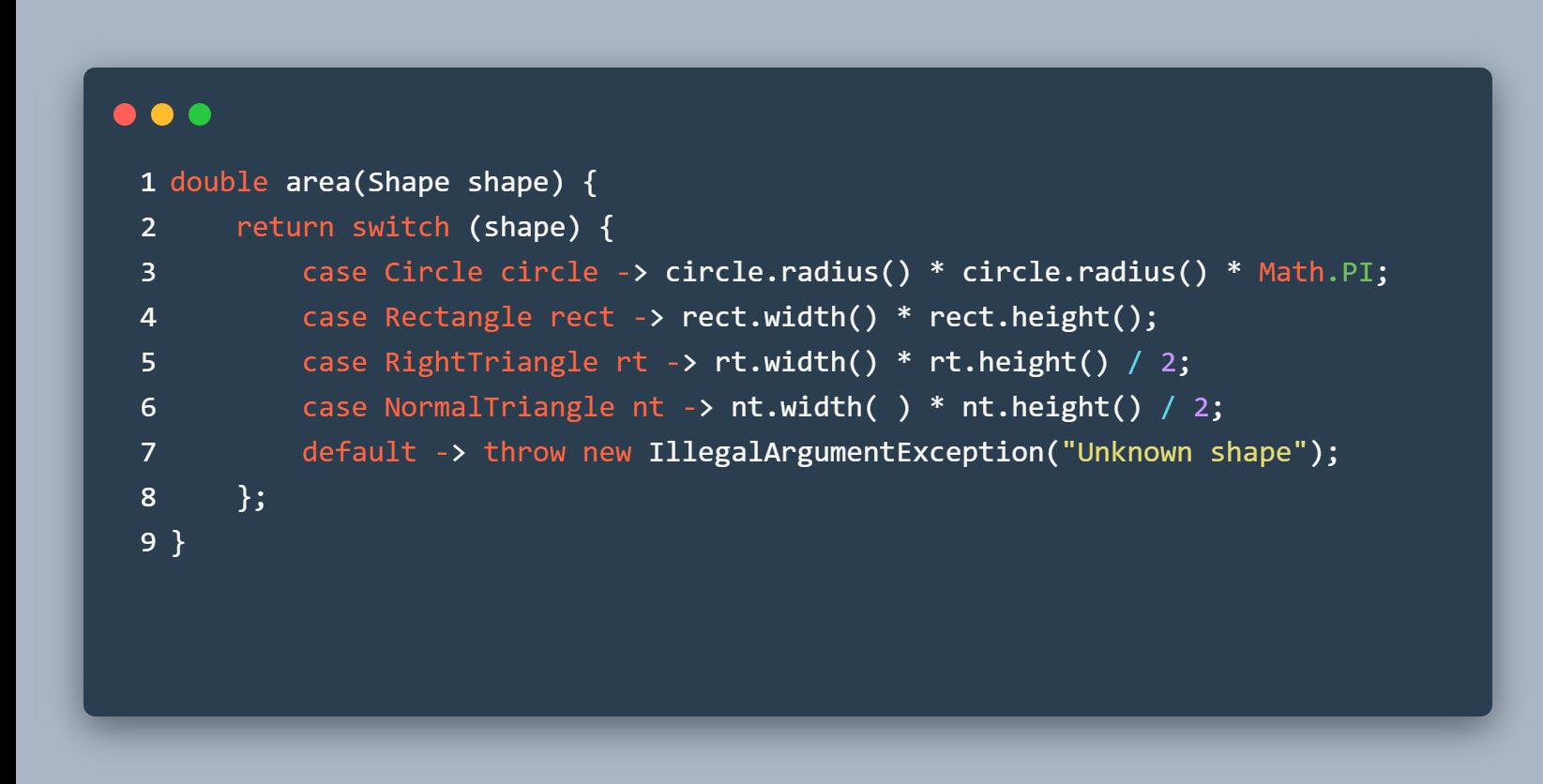
如果你这里不写 default,并且,少了一种类型的话,例如:

那么就会报编译错误,这就是 switch 模式匹配的穷举性检查
在第二次预览中,主要修复了针对包含参数泛型的封闭类的穷举性检查,即有如下封闭类:

对于下面的代码,穷举性检查就不会误报编译错误了:

这个特性还在不断改善,大家可以试一下,并可以向这里提意见交流:https://mail.openjdk.java.net/pipermail/amber-spec-experts/2022-February/003240.html
孵化中的新特性
外部函数与内存 API(第二次孵化)
相关 JEP:
这个是 Project Panama(取名自巴拿马运河)带来的一个很重要的孵化中的特性,就像连接太平洋和大西洋的巴拿马运河一样,Project Panama 希望将 Java 虚拟机与外部的非 Java 库连接起来。这个特性就是其中最重要的一部分
这个特性主要目的是:
- 首先,提供具有类似性能和安全特性 ByteBuffer API 的替代方案,修补了原有 API 的一些缺点(很多需要访问堆外内存的库,例如 Netty 操作直接内存作为缓存池这种,都会从中受益)
- 其次,通过用更多面向 Java 的 API 来代替 JNI,使本机库更易访问,也就是你可以通过 Java 代码直接调用系统库
- 最后,统一替换掉
sun.misc.Unsafe里面关于内存访问的 API,换成了更易于使用的封装。
这里有一个例子,是关于使用 Foreign Linker API 实现使用 Java 直接调用 Windows 上面的 user32 库里面的 MessageBoxW 函数:

感兴趣可以看一下这个视频:Foreign Linker API: Java native access without C | Modern Java | JDK16 |Head Crashing Informatics 27
目前,一些有意思的正在使用外部函数与内存 API 实验的项目:
Vector API(第三次孵化)
相关 JEP:
这也是 Project Panama 中的一个重要组成部分。其中最主要的应用就是使用了 CPU 的 SIMD(单指令多数据)处理,它提供了通过程序的多通道数据流,可能有 4 条通道或 8 条通道或任意数量的单个数据元素流经的通道。并且 CPU 一次在所有通道上并行组织操作,这可以极大增加 CPU 吞吐量。通过 Vector API,Java 团队正在努力让 Java 程序员使用 Java 代码直接访问它;过去,他们必须在汇编代码级别对向量数学进行编程,或者使用 C/C++ 与 Intrinsic 一起使用,然后通过 JNI 提供给 Java。
一个主要的优化点就是循环,过去的循环(标量循环),一次在一个元素上执行,那很慢。现在,您可以使用 Vector API 将标量算法转换为速度更快的数据并行算法。一个使用 Vector 的例子:

注意使用处于孵化的 Java 特性需要加上额外的启动参数将模块暴露,这里是--add-modules jdk.incubator.vector,需要在 javac 编译和 java 运行都加上这些参数,使用 IDEA 即:


测试结果:

其他使用,请参考:fizzbuzz-simd-style,这是一篇比较有意思的文章(虽然这个性能优化感觉不只由于 SIMD,还有算法优化的功劳,哈哈)
关于一些更加详细的使用,以及设计思路,可以参考这个音频:Vector API: SIMD Programming in Java
微信搜索“我的编程喵”关注公众号,每日一刷,轻松提升技术,斩获各种offer:

我会经常发一些很好的各种框架的官方社区的新闻视频资料并加上个人翻译字幕到如下地址(也包括上面的公众号),欢迎关注:
- 知乎:https://www.zhihu.com/people/zhxhash
- B 站:https://space.bilibili.com/31359187
以上是关于关于 Java 18 你想知道的一切的主要内容,如果未能解决你的问题,请参考以下文章