(项目)Web服务器的实现——自主实现一个Web服务器项目,通过该服务器搭建个人网站(保姆级教程),可写在简历上
Posted 努力学习的少年
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了(项目)Web服务器的实现——自主实现一个Web服务器项目,通过该服务器搭建个人网站(保姆级教程),可写在简历上相关的知识,希望对你有一定的参考价值。
- 💂 个人主页:努力学习的少年
- 🤟 版权: 本文由【努力学习的少年】原创、在CSDN首发、需要转载请联系博主
- 💬 如果文章对你有帮助、欢迎关注、点赞、收藏(一键三连)和订阅专栏哦
目录
前言
这个项目主要是搭建好跟浏览器通信的细节,它涉及的知识包含如下:
- c/c++知识,例如:类与对象,引用,STL的使用,
- 熟悉多进程的创建,进程间通信,信号等等
- 熟悉多线程的创建,熟悉条件变量和互斥量等概念,搭建线程池的创建。
- http协议的认识,认识URI,熟悉http请求和http响应的结构。
- 熟悉TCP网络套接字,因为http协议的底层是TCP
一.项目介绍
1. 什么是Web服务器?
通过http协议构建一个Web服务器,该服务器能够处理浏览器发过来的http请求,并根据http请求返回http响应给浏览器。该服务器的功能上可以存放各种各样的资源(文件,视频),用户可以利用浏览器来访问我的服务器资源,也可以提交数据给服务器,让服务器去处理结果,并返回给浏览器。简单点说,就是搭建个人网站,你可以在服务器上存放各种各样的资源,然后通过浏览器去请求你服务器上的各种各样的资源(视频,网页,音频等等)。
2. 项目展示
主页:
自拍照网页:
点击csdn博客,直接跳转到我csdn博客的主页。
点击计算器:
提交出来的结果:
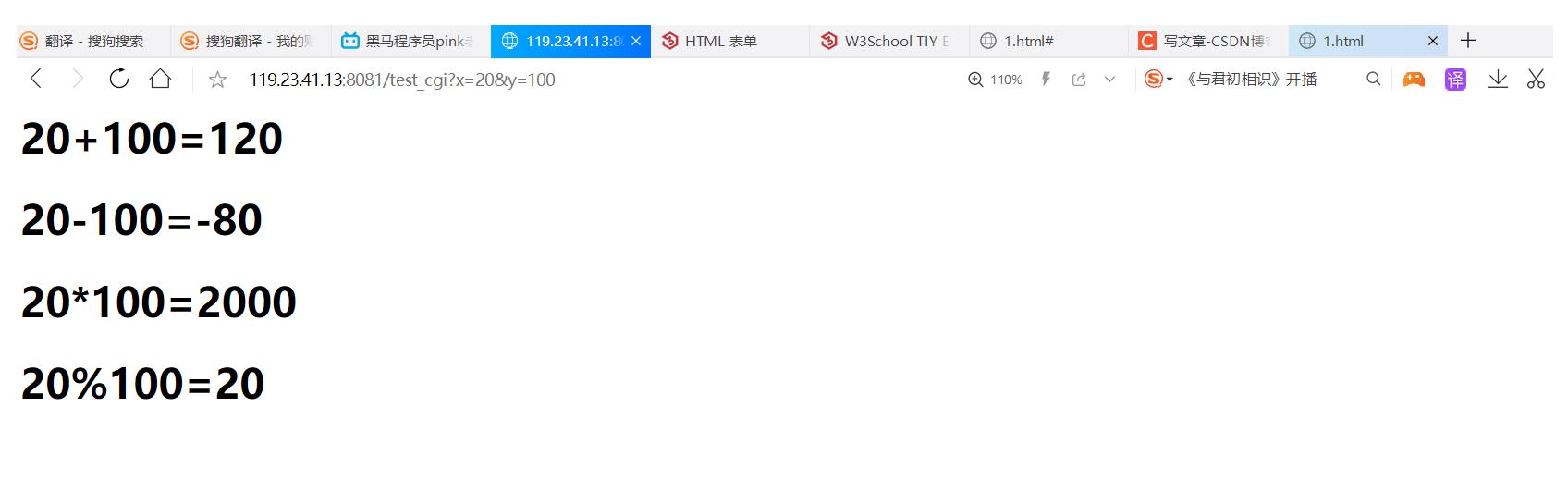
由于博主没怎么学html+css+js的知识,所以网页就做得很一般,如果你们想学前端的话,同时推荐一个网站给你们:HTML 系列教程
二. 认识http协议
1. 什么是URI?
Web上可用的每种资源 - HTML文档、图像 、视频片段、程序等 - 由一个通用资源标志符(Uniform Resource Identifier, 简称"URI")进行定位。URI一般由三部分组成,一.存放资源主机名,二.资源自身的名称(一般由路径表示)三.访问该资源所携带的参数,参数可有可无,例如:http://www.webmonkey.com.cn/html/html40/ 这个URI是这样的:这是一个可通过HTTP协议访问的资源,位于主机www.webmonkey.com.cn上,通过路径“/html/html40”访问。
其中www.webmonkey.com.cn是一个域名地址,它作为将域名和IP地址相互映射的一个分布式数据库,能够使人更方便地访问互联网,而不用去记住能够被机器直接读取的IP数串。
也就是说域名地址是用来唯一标识网络中的的一台机器。访问服务器,也可以直接使用IP地址去寻找服务器,这本质是一样的,只是域名需要先转换为ip地址,再去寻找服务器。找到服务器后,URI中的IP地址就丢掉,URI中的就只剩下资源自身的名称和参数。
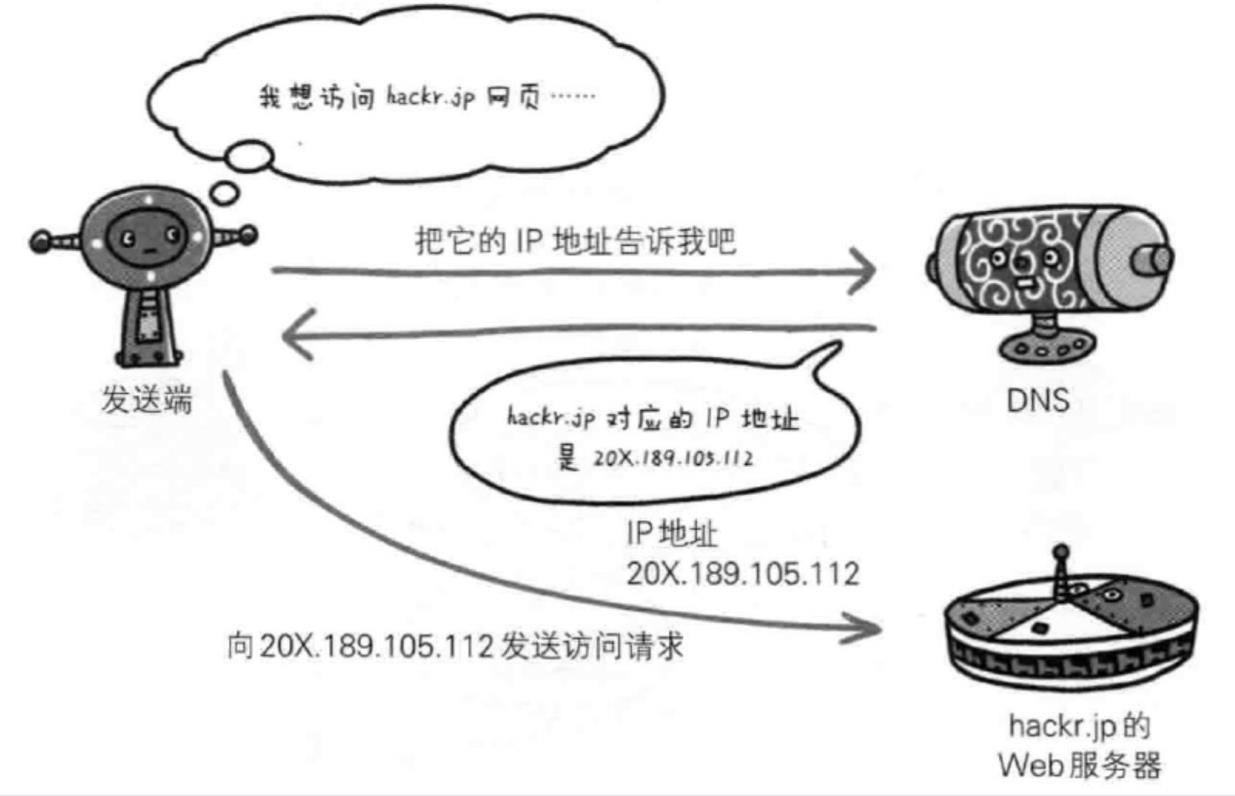
2. http请求和响应过程

浏览器请求服务器的资源需要给服务器发送http请求,而服务器给返回资源是返回一个http响应给浏览器的,所以我们需要记住http请求和http请求的格式,以至便于我们后面的编码。
3. 具体的http请求
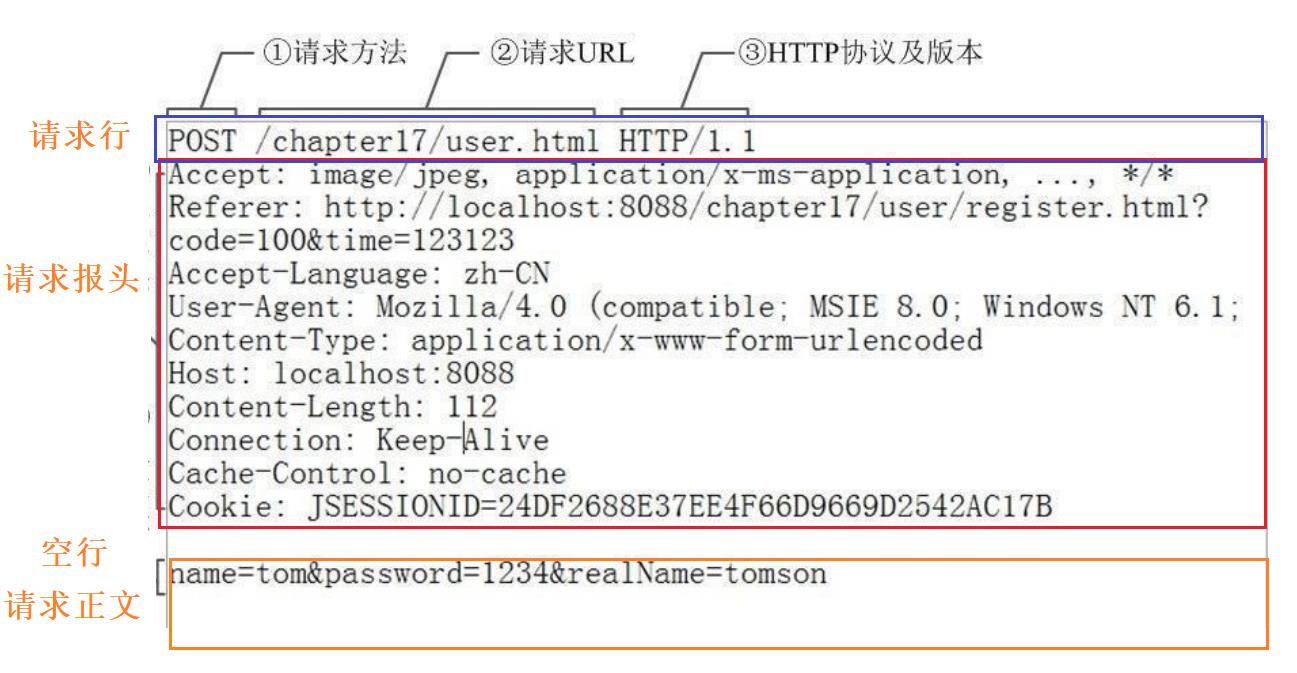
http请求包含4个部分,请求行,请求报头,空行,请求正文。
- 请求行:请求方法 URI Http的版本
- 请求报头:请求的属性,每种属性是用\\n进行分隔开,遇到空行则表示请求报头结束。
- 空行:将请求报头和请求正文分隔开
- 请求正文:空行的后面的内容就是请求正文,如果请求正文存在,那么请求报头中就有一个Content-Length属性来标识正文的大小。
4. 具体http的响应

http响应包含4个部分:响应行,响应报头,响应空行,响应正文
- 响应行:http协议及版本 状态码 状态码描述
- 响应报头:响应的属性,每组属性都用\\n进行分隔,遇到空行则响应报头结束
- 响应空行:用来分隔响应报头和响应正文
- 响应正文:响应空行的后面,响应报头中有一个Content-Length用来标识响应正文的大小。
5. Http支持的方法

在我的服务器,我主要实现了GET和POST方法,因为这两种方法是最常用的,其他的方法后续有补充的话,我将会更新我的博客。。
开始编码
三. 工具类
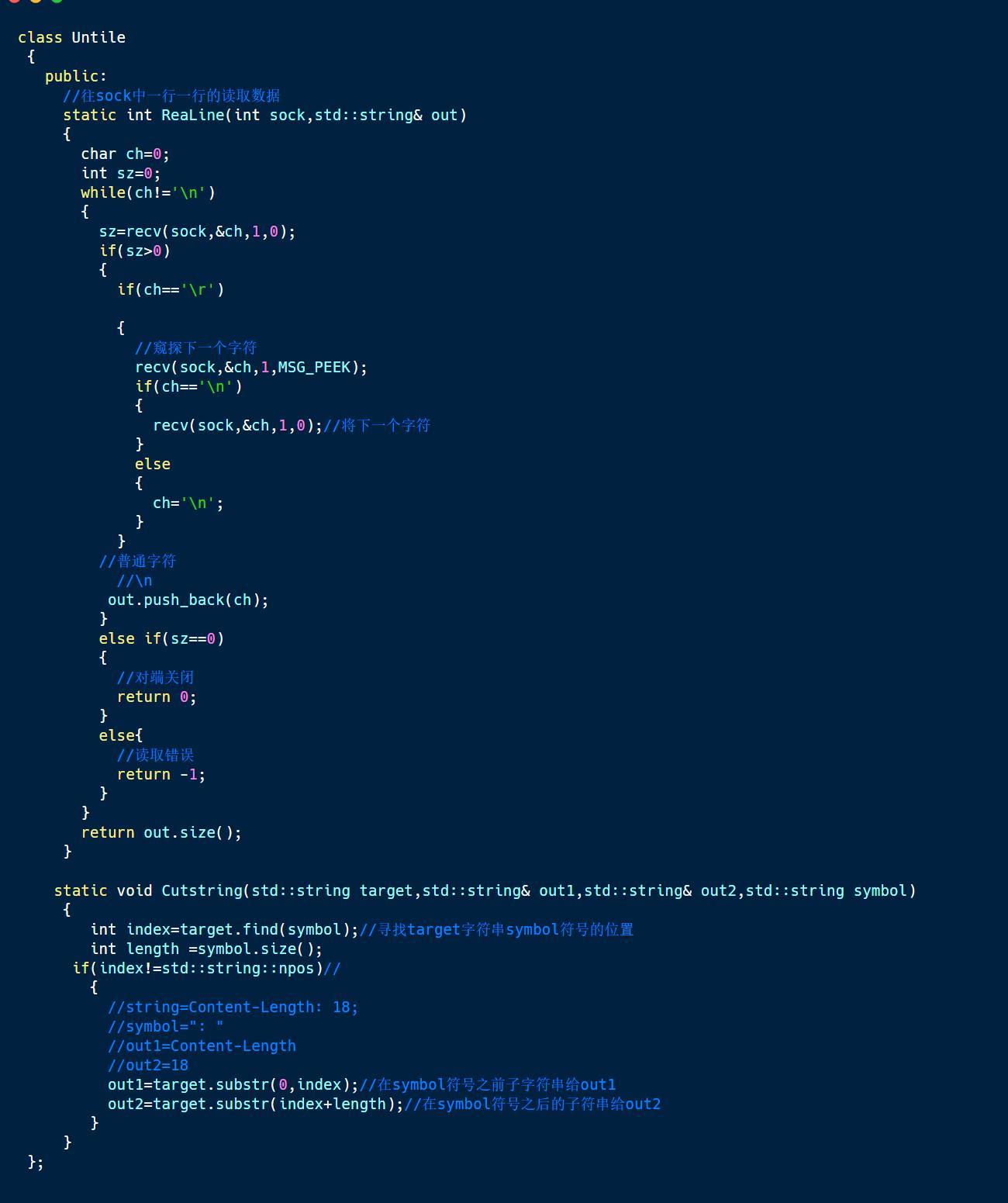
在我们的工具类中,有两个函数在编写协议的时候经常会用到,一个是ReadLine()函数,一个是Cutstring函数(),ReadLine()函数的作用是将sock中的数据一行一行的读取上来,当浏览器发送http请求给服务器的时候,请求行是为第一行,请求报头中的每种属性也是按行区分开来的,所以我们会用该函数去读取http请求。其中,不同浏览器发送过来的http请求中行分隔符是不太一样的,有的是“\\n",有的是"\\r\\n",有的是“\\r",因此,我们可以将所有的行分隔符都处理成”\\n".方便我们后续的处理。
recv()函数中携带MSG_PEEK标志位表示的是只查看sock中数据,但是不将数据拿到应用层上,也就是说,不将这次读取sock中的数据给删除掉。
如果拿到的字符是\\r,那么我们需要判断下一个字符是否为\\r\\n,如果不是\\n,那么该行已经结束,但我们不能破坏下一行的数据,因此就MSG_PEEK进行查看。
四. Http服务器的构建
当http服务器收到一个请求的时候,服务器需要做4件工作:读取请求,分析请求,构建响应,发送响应。
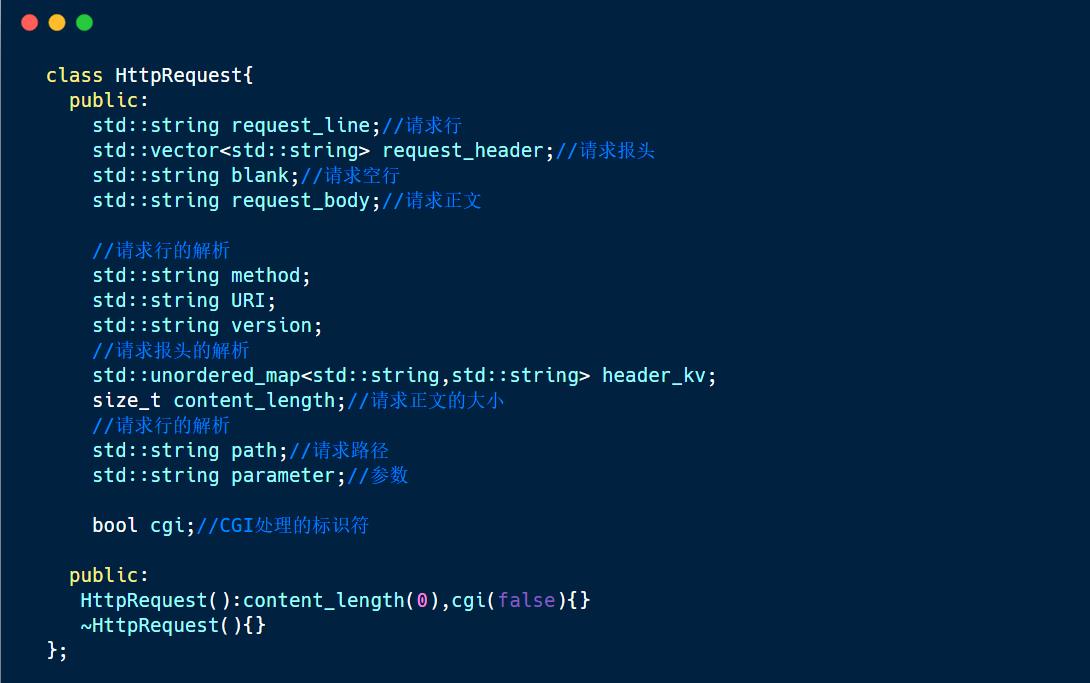
1. http请求类
2. http响应类

五. 读取请求
服务器在sock收到的请求是一堆字符串,那么怎么读取呢?我们可以使用工具类中的ReadLine()函数将sock中的请求一行一行的读取上来然后分类到http请求中的请求行,请求报头,空行,请求正文中。
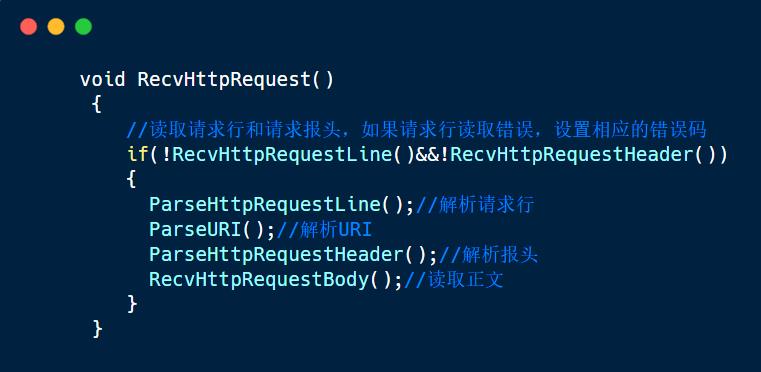
1. 读取请求行
因为第一行一定是请求行,将读取到的第一行放进request_line中。
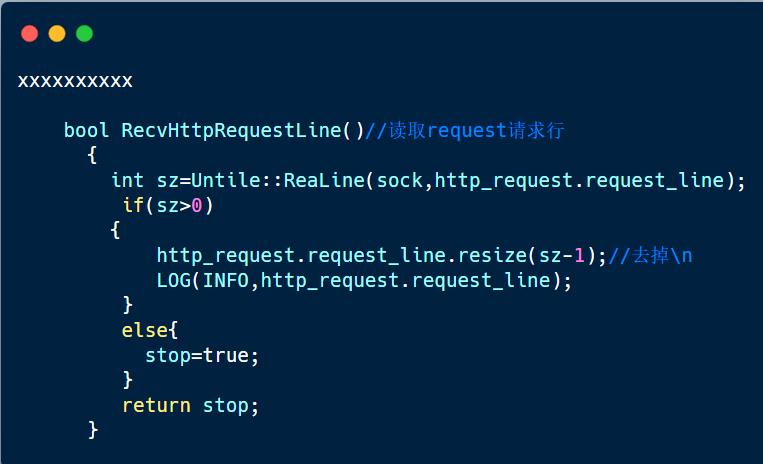
2. 读取请求报头
因为在请求报头的每种属性,是按行为单位的,所以我们从sock中一行一行的读取
请求报头的属性,然后再将读取的属性插入到请求报头中。

3. 解析请求行
分析请求行:我们需要将读取到的请求行拆分成三个部分:请求方法,URI,请求版本,以便我们后续根据请求方法,URI和版本构建响应。
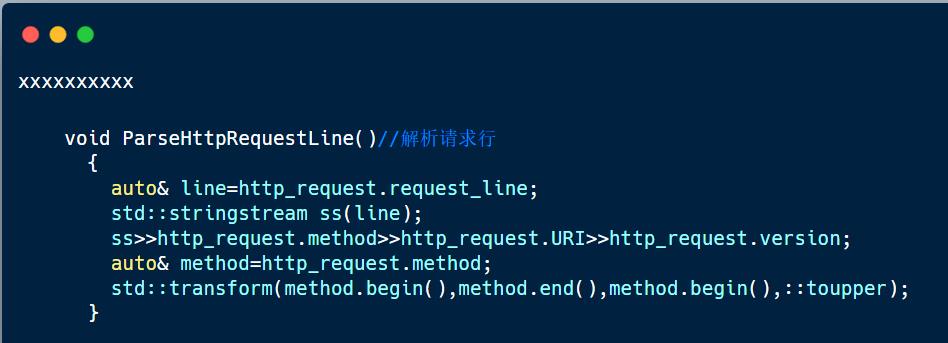
在请求行中,method,uri和version它们之间都隔着空格,所以可以使用streamstring将请求行拆分成method,uri,version,具体使用如下:

输出结果:

tranfrom函数:将method都转换成大写,因为有些浏览器发送的http请求有可能大小写不一样,例如:GET,Get,get,所以我们将拿到的请求都统一转换为大写。
5. 解析URI
URI中包含请求资源的路径或者包含请求资源的路径和参数,资源的路径是指明指明浏览器要访问的资源的位置,参数是直接给传递给找到的资源。所以需要将URI拆分成请求路径和参数。
在GET方法中,URI中可能包含请求资源的路径和参数,路径与参数是用?相隔开的,如下:
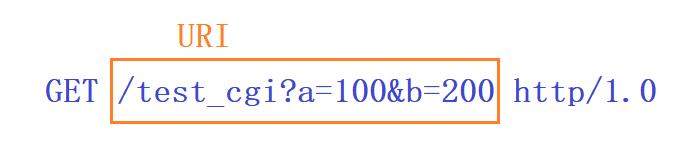
其中/test_cgi是请求路径,a=100&b=200是参数,参数与参数之间是用&分隔开的。
也可能只包含请求路径:

右上图可以得知,我们判断一个GET方法是否带路径,我们只需要判断URI中是否存在?,如果存在,我们将URI拆分成两部分path和parameter,如果不存在直接将URI赋值path。
如果是POST方法,URI只可能包含路径,如果有参数,参数是存放在正文中的,因此如果是POST方法,我们直接将URI赋值给path即可。

6.分析请求报头
请求报头中包含了请求中的各种信息,但是它们都是以 ”属性名:属性信息“ 的形式存储在vector中,例如:“Content-Length: 10",为了方便我们找到请求报头中的各种信息,我们需要将请求报头中的每种属性拆分成属性名-属性信息键对值存放在unordered_map。
每种报头中每种属性里,属性名和属性信息都是用 “:”分隔开的。如下:

因此我们需要根据”:“将属性名和属性信息分隔开来。
代码:
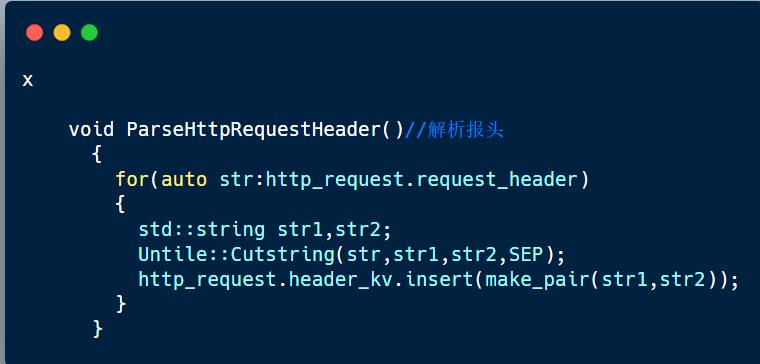
7. 读取请求正文
当解析请求行和请求报头完后,我们就可以知道method和Content-Length,我们就可以判断请求正文中有内容?如果请求正文中有内容,那么就需要读取多少?
在GET方法中,请求正文是被设置为空,所以GET方法是不需要读取请求正文的,如果是POST方法,它的请求正文有可能为空,也有可能存在,如果POST方法中的请求正文存在,Content-Length是不等于0的,在sock读取多少个字节呢,根据Content-Length判断即可,如果POST方法中的请求正文不存在,那么Content-Length是为0,因此是不需要读取请求正文的。
判断是否需要读取request正文
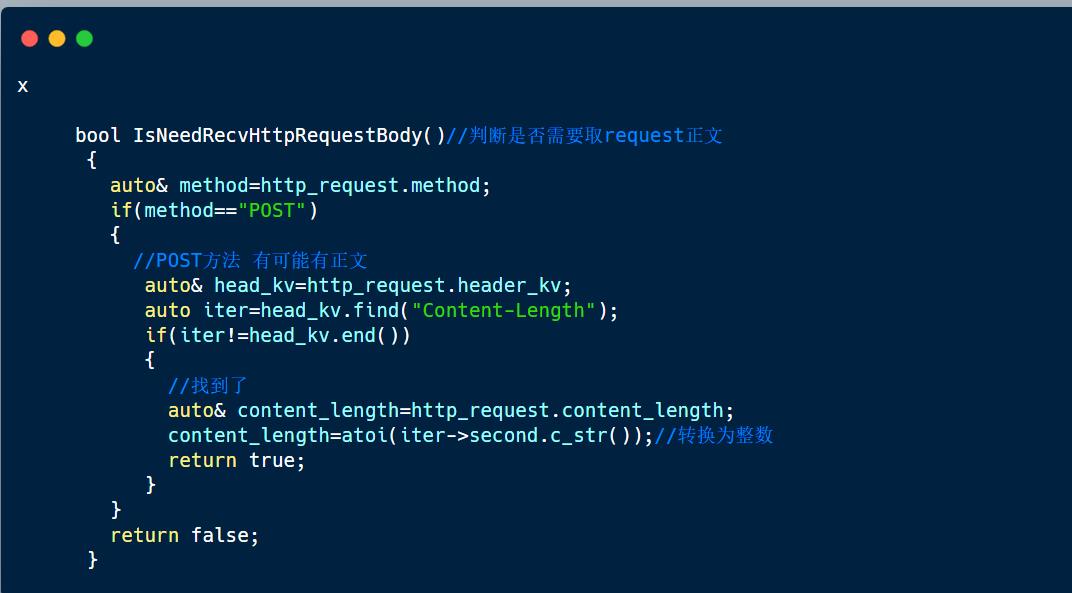
读取正文

六. 构建响应的预处理工作
浏览器给服务器发出一个http请求目的是让服务器完成某种任务,可能是想访问服务器上的某种资源(文本文件,视频,音频等等),也可能让服务器处理某些数据等等,服务器完成的结果是需要返回给我们的浏览器,文本文件的内容,视频,音频,或数据处理的结果都需要返回给浏览器,但服务器的处理结果是不能直接返回给浏览器,是需要构建一个http响应返回浏览器的,处理结果就放在http的响应正文中。
http响应的构建需要包含:响应行,响应报头,响应空行,响应正文。
构建响应行:版本 响应状态码 响应状态码描述
构建响应报头:构建响应报头至少需要构建 Content-Type 和 Content-Length属性,Content-Type描述的是服务器返回资源是什么类型,Content-Length描述的服务器返回的资源的大小。每种属性都以空行作为结尾。
构建响应行:将响应报头和响应正文分隔开。
构建响应正文:存放文本文件的内容,视频,音频或数据的处理结果。
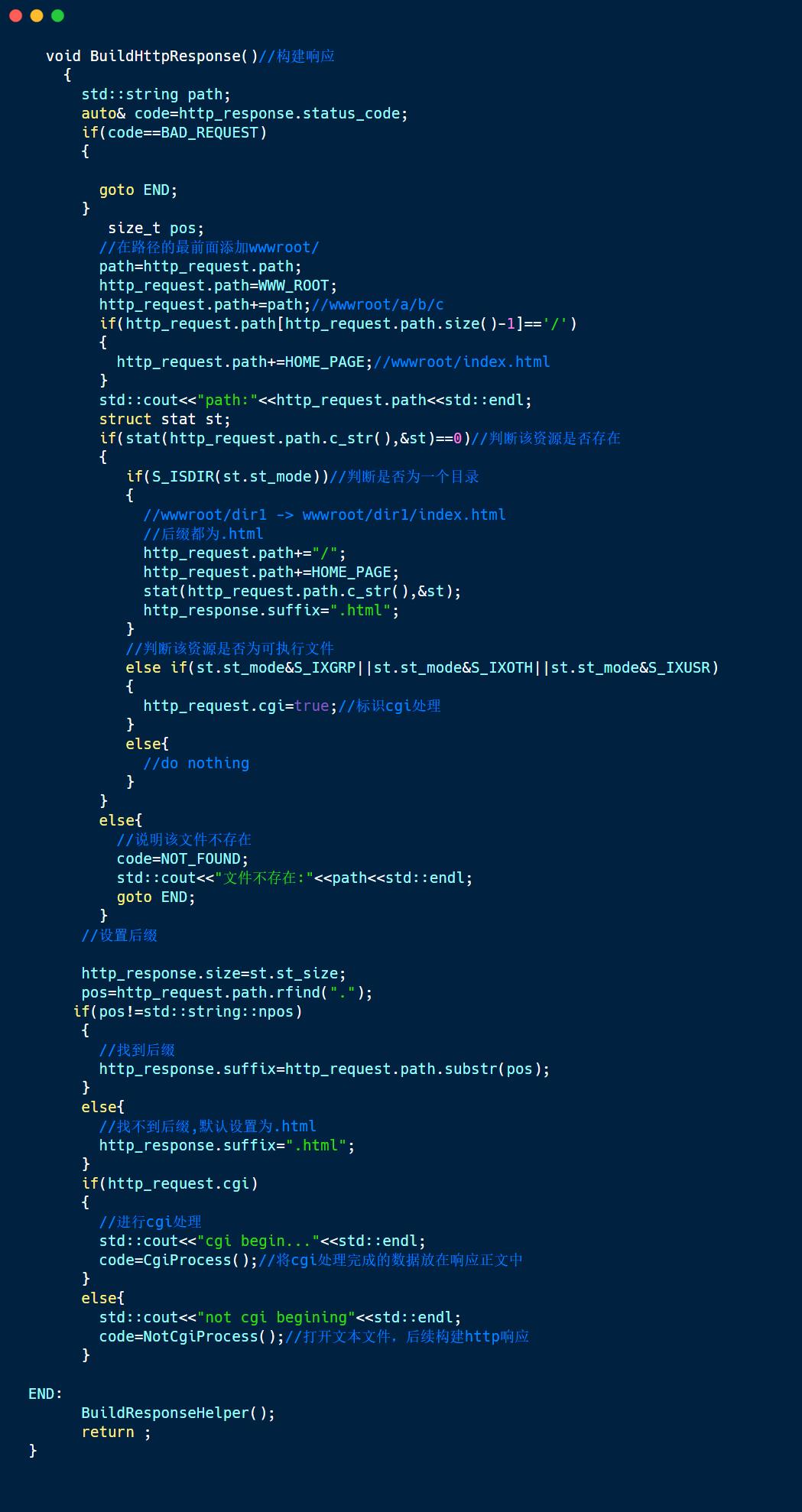
在我们构建响应之前,我们需要根据浏览器发出的http请求来找到我们服务器上的资源,也就是我们的请求路径path。path在解析URI中就已经处理好了,接下来我们直接用就可以了。

我们解析看到的path都是以/开头,此时就有一个问题,浏览器访问资源的路径是从服务器上的根目录下开始找的吗?答案是不一定,在哪里找资源取决于我们把所有资源放在哪一个目录下。举个例子:
我将我的服务器上所有的资源都放在wwwroot目录下,那么浏览器想要访问的服务器上的资源,就需要到wwwroot目录下去寻找资源。
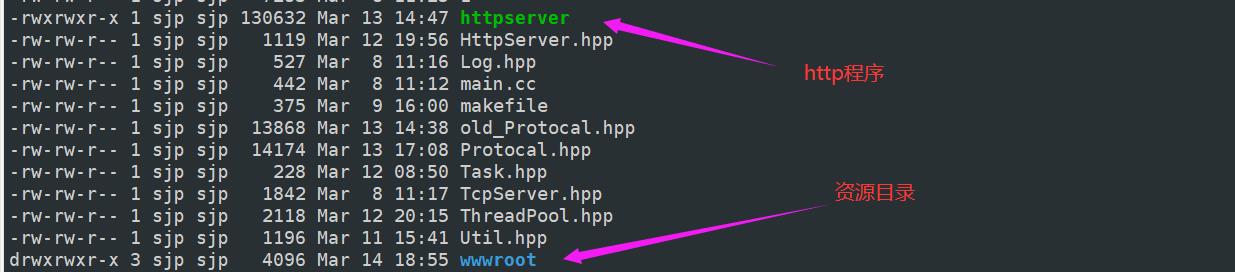
可是浏览器发送过来的路径都是以根路径最开始的呀,http进程是怎么到wwwroot目录下去寻找资源呢?答案是http进程在接收到浏览器的访问路径时,首先会对该路径进行修饰的,例如,我的资源目录是wwwroot,它与http进程是在同一个目录下,所以我的http进程是可以通过相对路径去访问wwwroot目录,因此在编码的时候,我会让我的http进程在路径的前面加上wwwroot,例如请求路径是/test_cgi,修饰后的路径就变为wwwroot/test_cgi,这样我们的http进程就会去wwwroot目录下查找资源。
接下来我们就需要判断该路径下的资源是否存在,如果不存在,那么将状态码设置为404,也就是找不到的意思,如果该资源存在,那么我们还需要再一步判断,如果访问的资源是一个文本文件, 我们需要记录该文件的大小,然后将该文本文件去构建一个http响应,如果是一个可执行程序,那么我们将标识cgi为真,对其进行cgi处理(下面会讲,不懂的可以先跳动下面看以下cgi处理),如果访问的资源是一个目录呢?是不是就不用进行处理呢?或者有什么办法可以解决这个问题?
其中一个解决办法就是在每一个目录下都建立一个index.html文件,这个文件代表的是该目录的首页,如果访问到该目录,并且没指明访问该目录的哪一个资源时,htpt进程就会直接将该目录下的index.html中的内容返回给浏览器。举个例子:如果访问的路径是 /,http进程会将/路径修饰成wwwroot/html,那么http进程就会找到wwwroot下的index.html中并将其文本内容返回给浏览器,如果访问的路径是/dir1, http进程会将/dir路径修饰成wwwroot/dir1/index.html,那么http进程就会找到dir1目录下index.html文件并将其文本内容返回给浏览器。
我的服务器上的wwwroot资源列表:

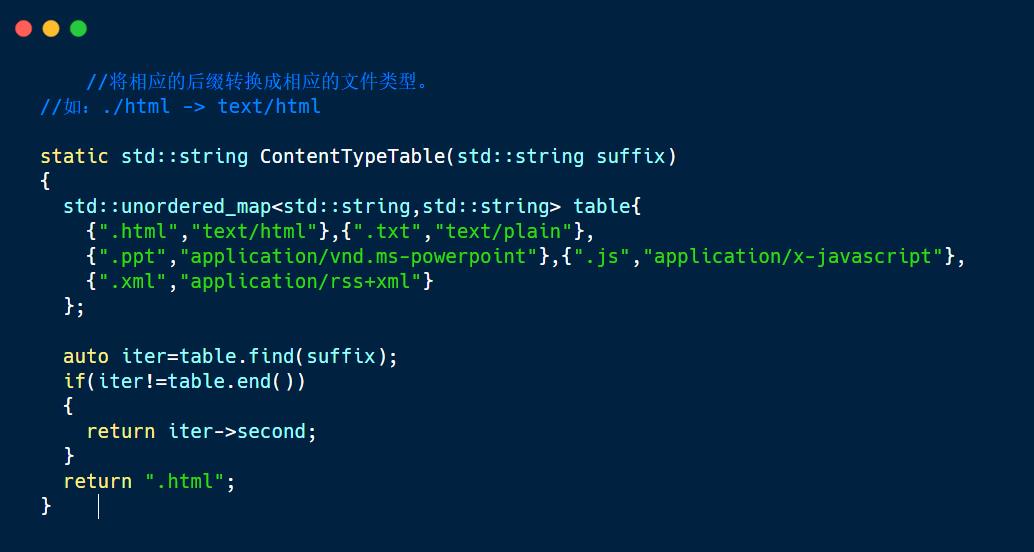
除此之外,我们还需要构建响应报头中的Content-Type,所以再拿去已经找到的资源的后缀将其放进suffix中,如果没有后缀,则统一设置为".html",然后根据后缀去构建Content-Type。
stat()函数
作用:查看一个文件是否存在,并将文件的属性存放在struct stat变量中。
返回值:成功返回0,失败返回-1.
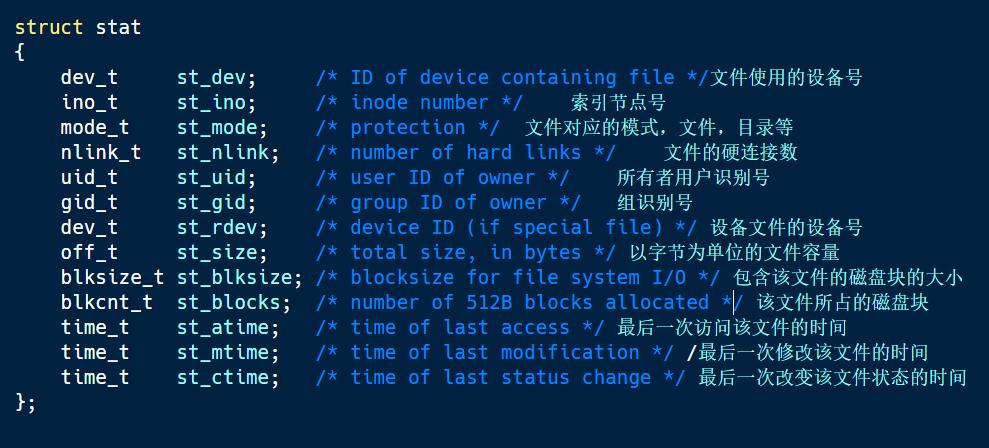
其中st_size属性是查看文件的大小,以字节为单位,st_mode存储了文件的类型和权限。
S_ISDIR (st_mode) 是一个宏定义,作用判断文件是否为目录。
st.st_mode&S_IXGRP
st.st_mode&S_IXOTH
st.st_mode&S_IXUSR,
分别判断文件所属组,文件的其他人,文件所属人是否具有可执行权限,如果其中有一个为真,那么该文件具有可执行权限。
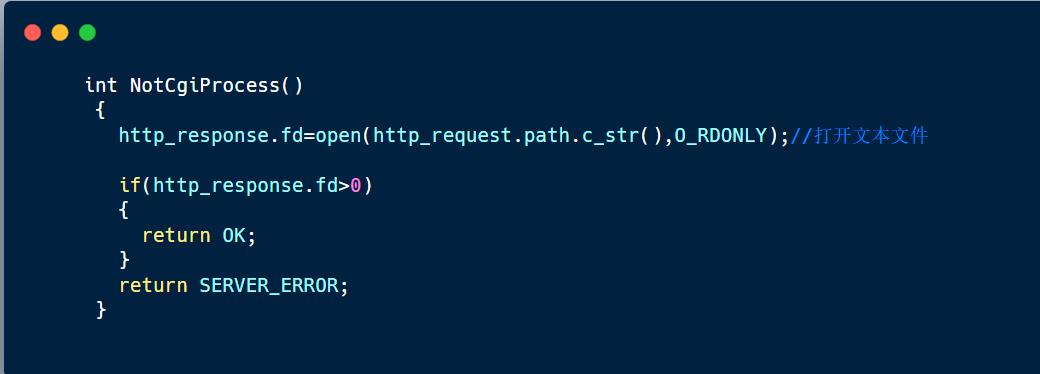
七. 返回网页(NotCgiPocess函数)
网页本质是一个超文本文件,也就是我们的前端代码,当返回这些代码给浏览器的时候,浏览器就会解析成一个网页。

因此如果浏览器访问的资源是是一个文件,那么http进程就直接将该文本文件直接打开,等到发送的响应的时候直接通过sendfile将文件的内容发送给浏览器即可。
八. CGI机制
1.CGI机制的基本概念
CGI(Common Gateway Interface) 是WWW技术中最重要的技术之一,有着不可替代的重要地位。CGI是外部应用程序(CGI程序)与WEB服务器之间的接口标准,是在CGI程序和Web服务器之间传递信息的过程。
所谓的CGI程序就是部署在服务器上的一个一个的可执行程序,这些可执行程序具有处理数据的功能。为了大家能够更好的理解cgi机制,我就举一个具体的情况,如果浏览器使用GET方法或者POST方法中访问的资源是一个可执行程序,那么http进程就会通过fork创建一个子进程,然后通过execl将可执行程序替换子进程,然后http进程就把参数通过传递给子进程,子进程就会解析该参数,例如”a=100&b=200“字符串解析成a=100,b=200.子进程将参数处理的结果返回给http进程,http进程在通过网络返回给浏览器。这种http进程去调用CGI处理数据的方式就叫做CGI机制。(GET方法和POST传进来的参数需要与调用的CGI程序能解析的参数互相匹配,例如:如果调用的CGI程序只能解析两个参数,那么GET方法和POST方法传进来的就必须是两个参数
2.CGI函数的实现
http进程本身是不会处理参数的,他的功能只是与浏览器互相进行数据的传输,如果要想让服务器具有处理各种参数的功能,那么就需要在服务器上部署各种各样的参数处理的CGI程序,这样就能够使我们的服务器有多种处理数据的功能。
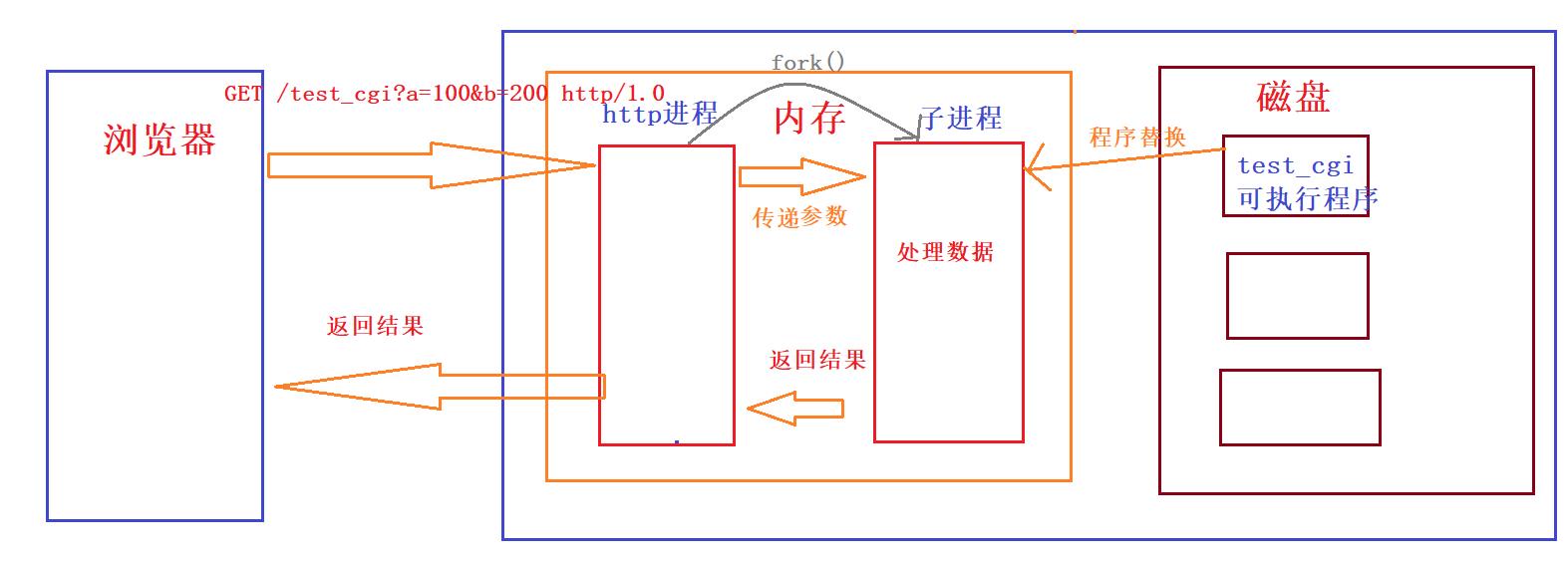
http进程给CGI进程之间需要互相通信,http进程需要传递参数给子进程,而CGI进程需要返回结果给http进程。因为http进程和CGI进程是父子进程,所以在互相通信的时候,创建匿名管道是最方便的,但管道的数据传输是单向的,为了能够使http进程和子进程之间都能互相传递数据,因此需要创建两个匿名管道。
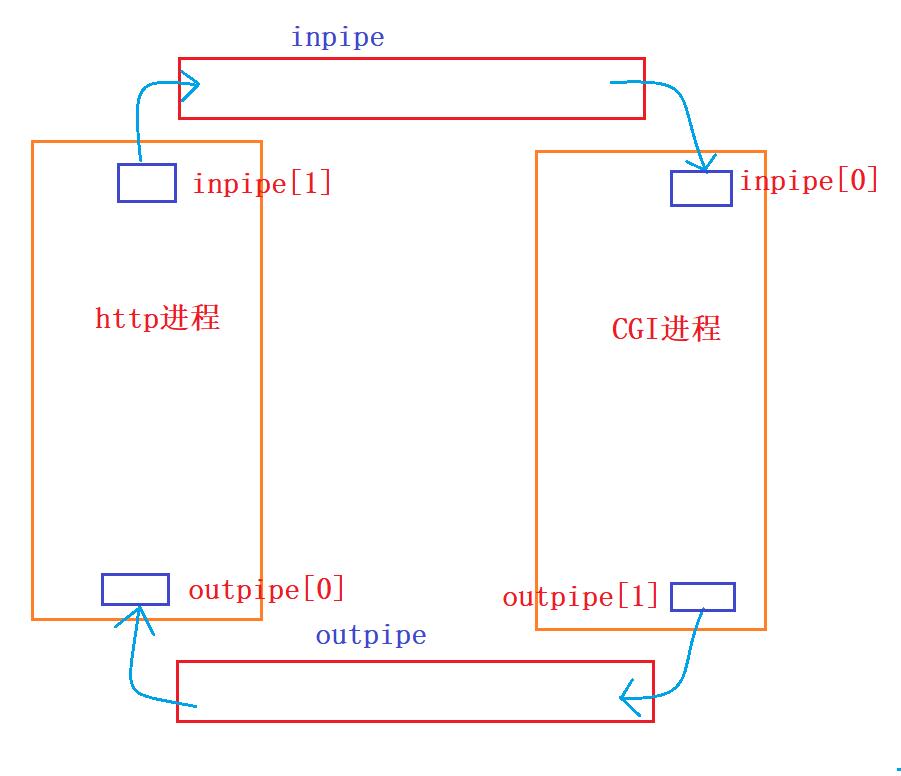
对于子进程来说,如果子进程被程序替换后,那么它拿到两个管道的文件描述符的数据也会被替换掉,此时子进程就不知道两个管道的文件描述符,就无法去input管道中读取数据,不能再outpipe中的写入数据。因为cin是一直往0号文件描述符中的file文件读入数据,cout一直往1号文件描述符中的file文件写入数据,所以在程序替换之前将子进程inpipe[0]的file*重定向到0号文件符,将子进程的outpipe[1]文件描述符就替换到1号文件描述符中去,所以,子进程据可以通过cin去inpipe管道中读取数据,通过cout往outpipe中写入数据。
创建管道对应的文件描述符:
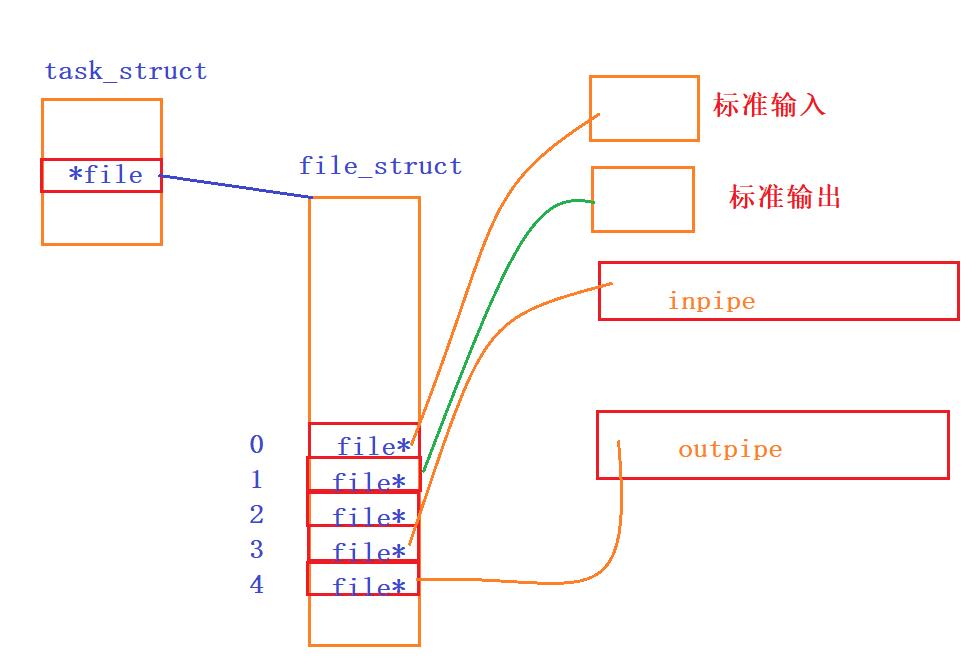
dup2重定向后,0号文件描述符标识的是inpipe管道,1号文件描述符标识的outpipe管道。所以子进程cin写入数据,就是往inpipe中写入数据,cou输出数据,就是往outpipe输出数据。
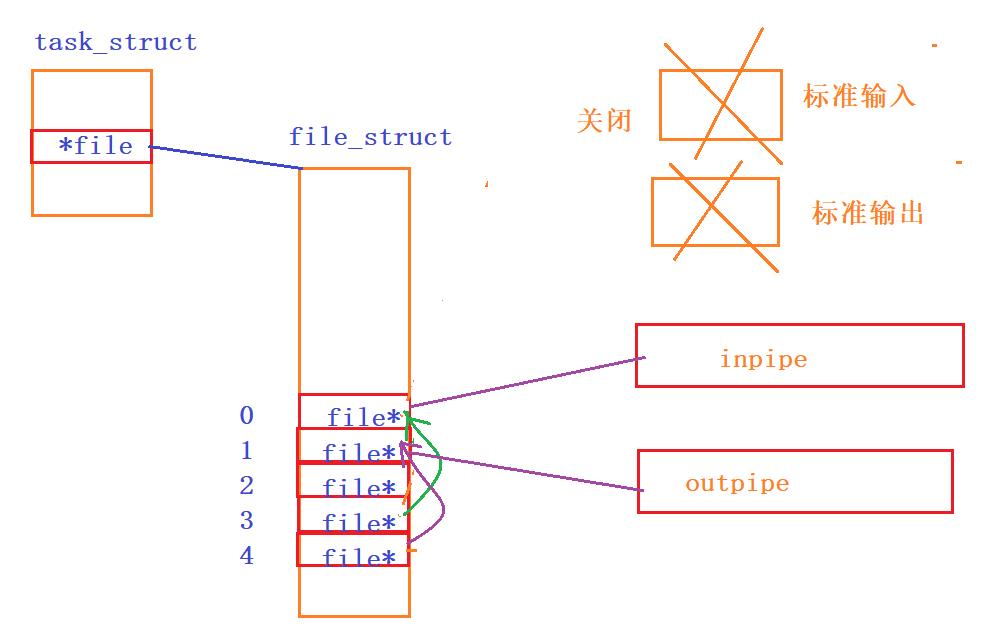
http进程给子进程传参的时候,GET请求和POST请求传参方式是不同的。
如果是GET方法,传递参数给子进程是通过设置环境变量的方式给子进程,因为URI中参数是有大小限制,一般都不会太长,并且程序替换,只替换进程的代码和数据,不会替换环境变量,因此在子进程被execl之前,提前设置一个PATAMETER的环境变量。
如果是POST方法,传递参数给子进程是通过管道的方式给子进程,因为POST中的请求正文的参数是没有限制的。但是子进程怎么知道要在管道中读取多少个字符呢?此时就需要将通过设置一个环境变量Content-Length来标识参数的大小,让子进程知道需要从管道中读取多少个字符。
可是子进程怎么知道要是GET请求还是POST请求,此时就需要在设置一个环境变量METHOD来标识请求方法。
http进程就从ouput[0]中读取到的结果放进response_body中。
CGI代码的实现:
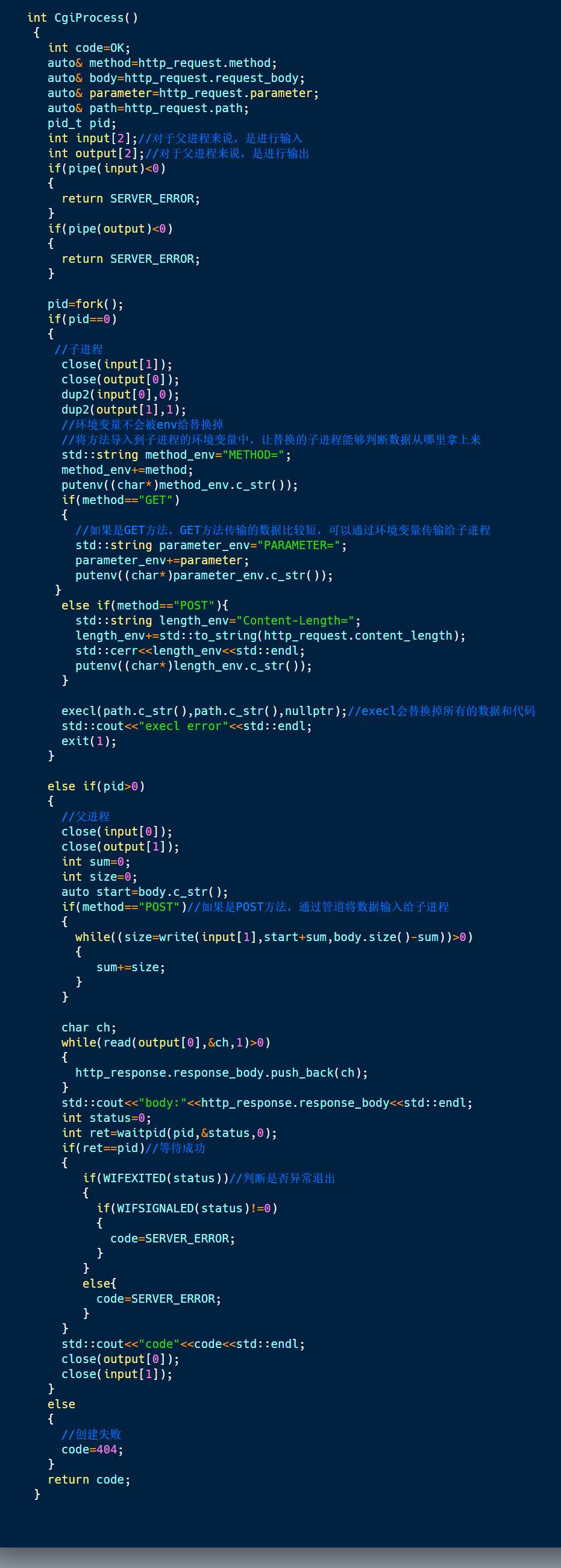
(ps:putenv()函数的作用是导入环境变量)
3.子cgi程序

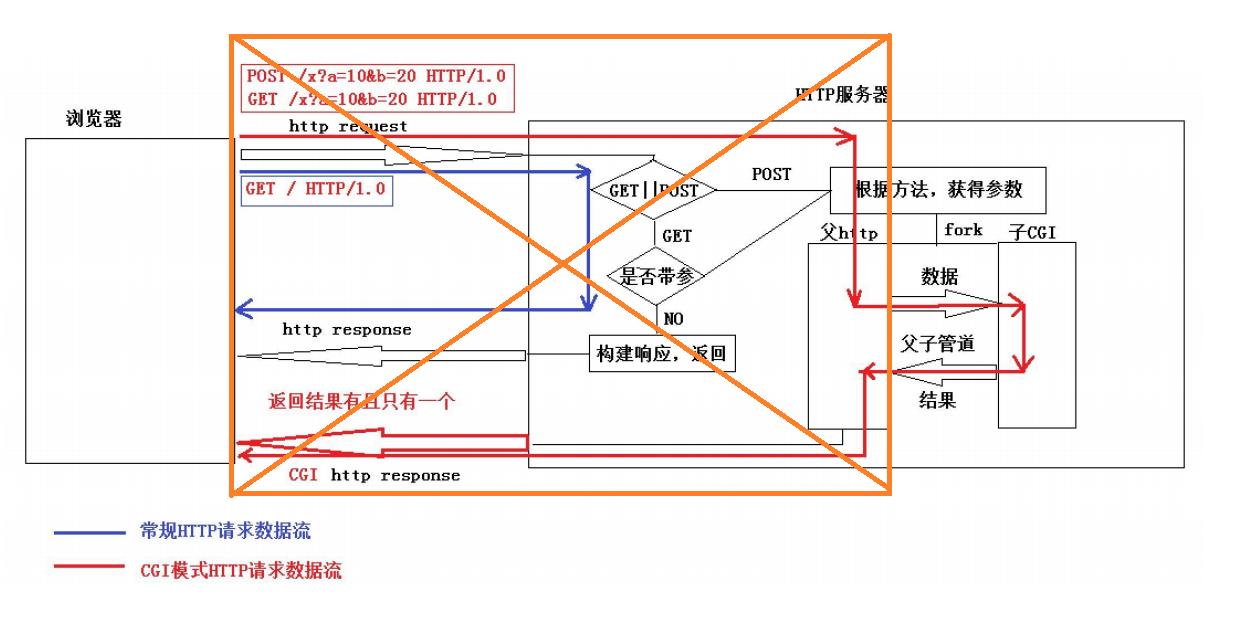
4.一张图总结cgi机制
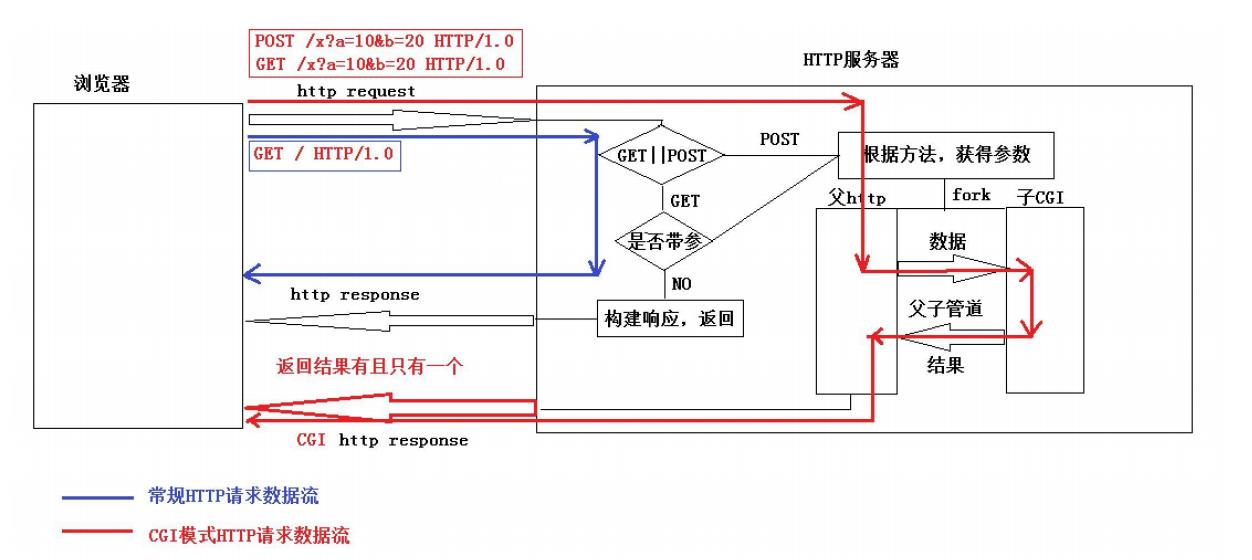
在我们编写cgi子程序的时候,我们可以忽略浏览器和子CGI之间的通信细节,我们可以认为子cgi中的cgi是读取浏览器中的参数,cout是往浏览器中输出数据,这样就大大减低了理解cgi子程序的 成本。
九. 构建响应
1.构建响应行
当我们处理完cgi函数后和非cgi函数后,我们就已经确定状态码,所以我们就可以构建我们的响应行,在响应行中,版本,状态码和状态码描述两两之间是以空格分隔开的,最后响应行以\\r\\n结尾。
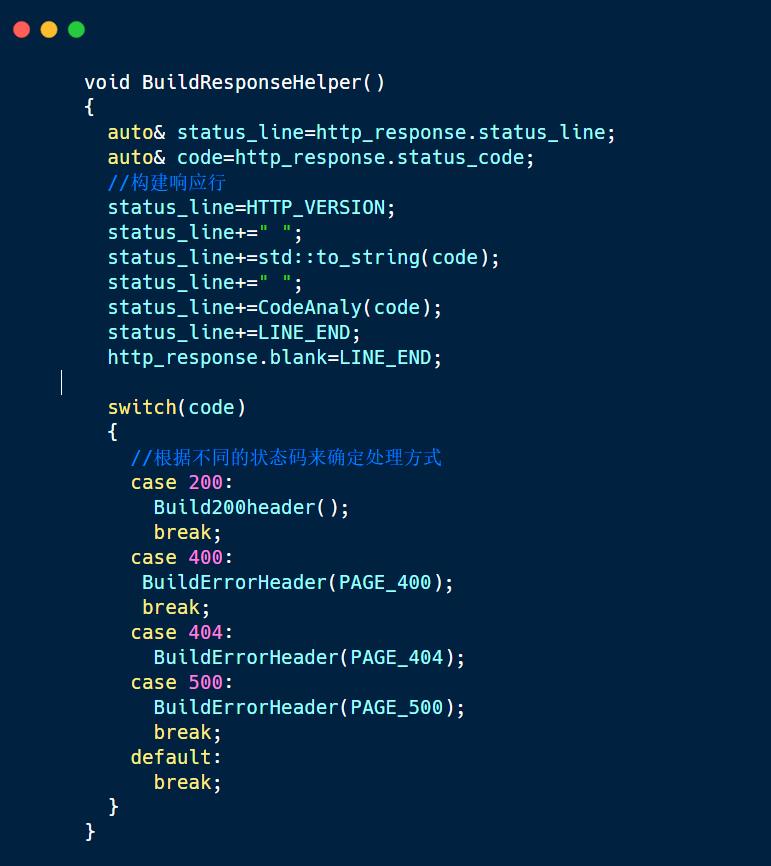
CodeAnaly()函数,将状态码转换为状态码描述,如200转换为“OK".

2. 构建响应报头
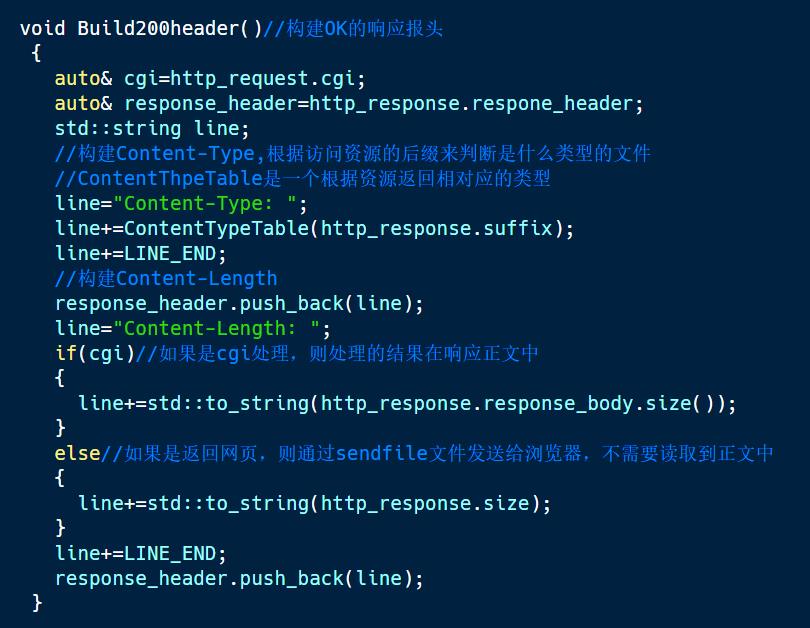
2.1 构建OK的响应报头
根据之前解析出来的资源后缀,我们就可以通过后缀判断出返回的资源是一个什么样的类型,接下来就可以构建出报头中的Content-Type,最后在以”\\r\\n"结尾
ContentTypeTable()函数可以根据后缀类型判断相应的文件类型并返回。
接下来就开始构建Content-Length,构建Contnet-Length需要根据cgi去判定,如果之前是cgi处理,那么它之前处理的结果已经放进了响应正文中了,也就是response_body,所以Content-Length就是我们response_body的大小,如果是非cgi处理,那么它就直接将文件中的所有内容返回给浏览器,文件的大小放在http_response.size,所以Content-Length就是http_response.size.最后在以”\\r\\n"结尾。
2.2 构建错误码的响应报头
除了成功的状态码外,其他状态码都会返回一个错误页面,因此这个函数可以直接将根据不同的状态码,然后将错误页面的的路径传给该函数,打开该文件,然后构建响应报头。
例如:
如果错误码是404,那么我们直接将传一个404页面的路径给下面的函数,详情看构建响应行的图。
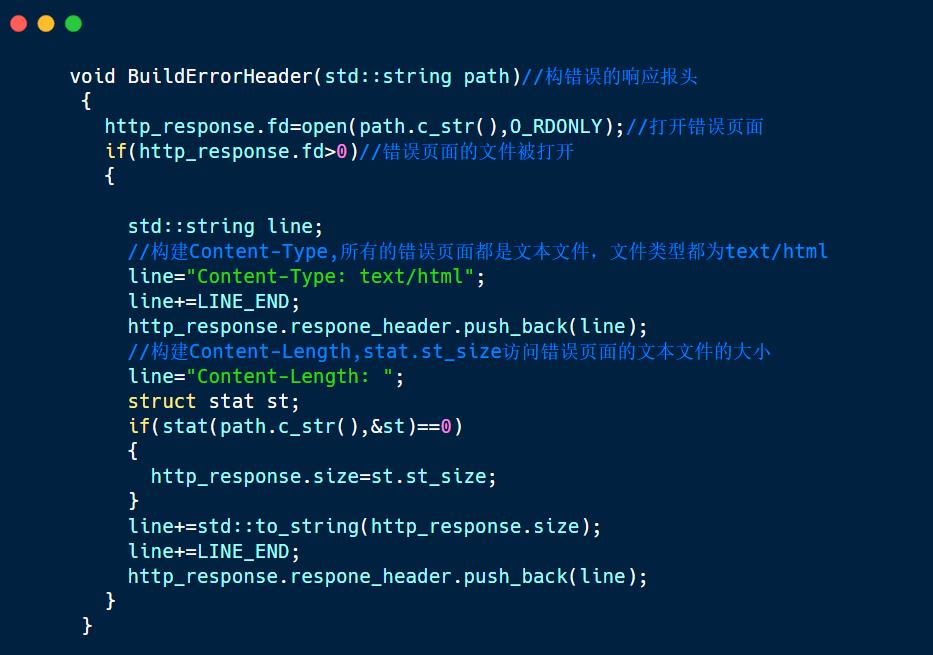
十. 发送响应
构建完响应后,我们就需要响应中的响应行,响应报头,响应空行,和响应正文依次发送给浏览器。在发送响应正文的时候,如果是cgi处理,cgi的处理结果已经放进响应正文中,所以直接将其发送给sock即可,如果是非cgi处理(返回错误页面,返回请求网页),因为之前未构建响应正文,但我们已经将需要返回的网页已经打开,所以在发送响应行,响应报头,响应空行后,我们最后再将文件中的内容发送出去。

为什么非cgi处理(返回错误页面,或者返回请求网页)不直接将文件内容存放到响应正文response_body中,而是使用sendfile()函数发送给浏览器呢?
sendfile()函数可以将内核中的文件缓冲区直接拷贝给另一个文件缓冲区,如下:

如果使用read()函数将index.html的文件缓冲区中的内容拷贝到用户去中的response_body,再使用write()函数拷贝给sock缓冲区,数据就会经过三个步骤:内核区->用户区->内核区,相比较sendfile()函数,效率会慢一些,因此我们就使用sendfile()函数将响应正文发送给sock().

十一 .处理错误
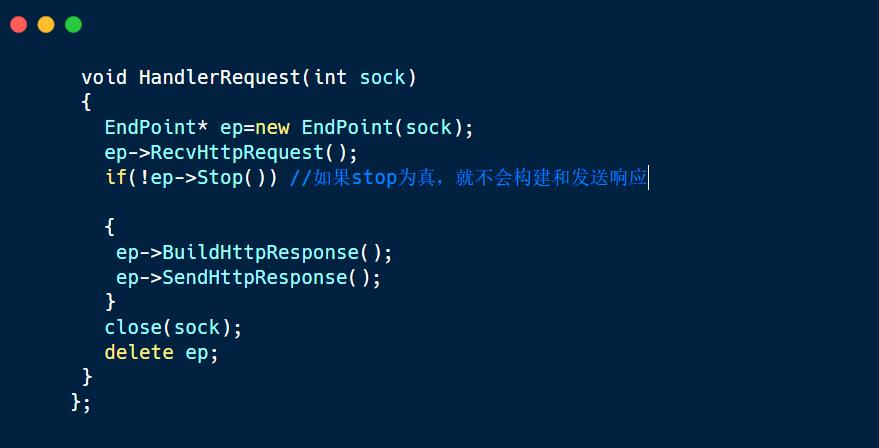
如果是服务器处理的逻辑错误,例如创建子进程失败,http请求路径错误等,那么我们直接返回一个错误页面即可,但如果是服务器在读http请求的时候,服务器读到一半请求,浏览器就将连接关掉,那么此时服务器就可能会崩掉,因此服务器读到错误的请求的时候,服务器中不会对http请求进行处理,然后关掉该连接即可。

如果读取正文失败,就会设置stop为真,然后就不会构建响应和发送响应,直接与浏览器连接给关闭。
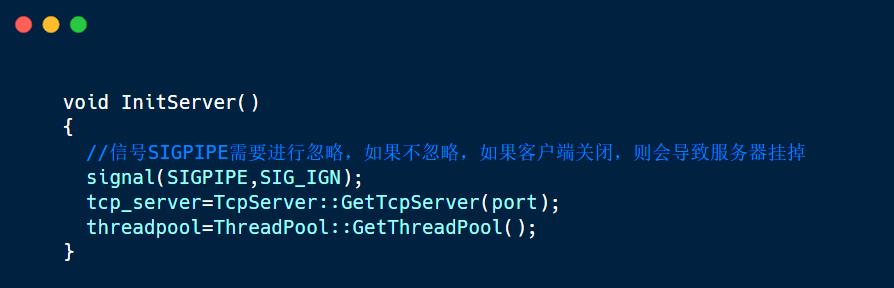
如果是服务器正往sock中写入,而浏览器将连接关掉后,那么浏览器就会收到一个SIGPIPE的信号,此时服务器就会崩掉,因此我们在初始化服务器的时候需要忽略该SIGPIPE信号。
十二.如何测试post方法
在我们浏览器去访问我们的服务器,浏览器大都是采用GET方法,但是如果我们编写好了服务器,我们应该怎样测试我们的post方法是否正确呢?
方法一:
使用telnet命令,如下:

方法二:
使用postman软件,具体怎么操作,请各位读者自行百度。
十三.写到最后
到此为止,我的服务器中的重难点已经讲解完。当然,项目中还引入了Tcp套接字的编写和线程池,具体的详细可以在我的码云上看完整代码(下面附上码云链接),同时也欢迎大家在评论区上同博主进行交流,如果在做项目的过程中,如果有什么问题,我也可以给大家提供支持。
最后,如果觉得文章对你有帮助的话,请给博主关注,点赞,收藏,博主将会不断做出优质的文章给大家。
码云链接:https://gitee.com/shen-jiapeng/http-server/tree/master/HttpServer
十四. 系列文章
- 【Linux网络(C++)】——网络套接字(TCP/UDP编程模型)多进程,多线程,线程池服务器开发(画图解析)
- 【linux多线程(四)】——线程池的详细解析(含代码)
- 【线程(三)】———条件变量的详细解析
- 【线程(二)】——互斥量的详细解析
以上是关于(项目)Web服务器的实现——自主实现一个Web服务器项目,通过该服务器搭建个人网站(保姆级教程),可写在简历上的主要内容,如果未能解决你的问题,请参考以下文章