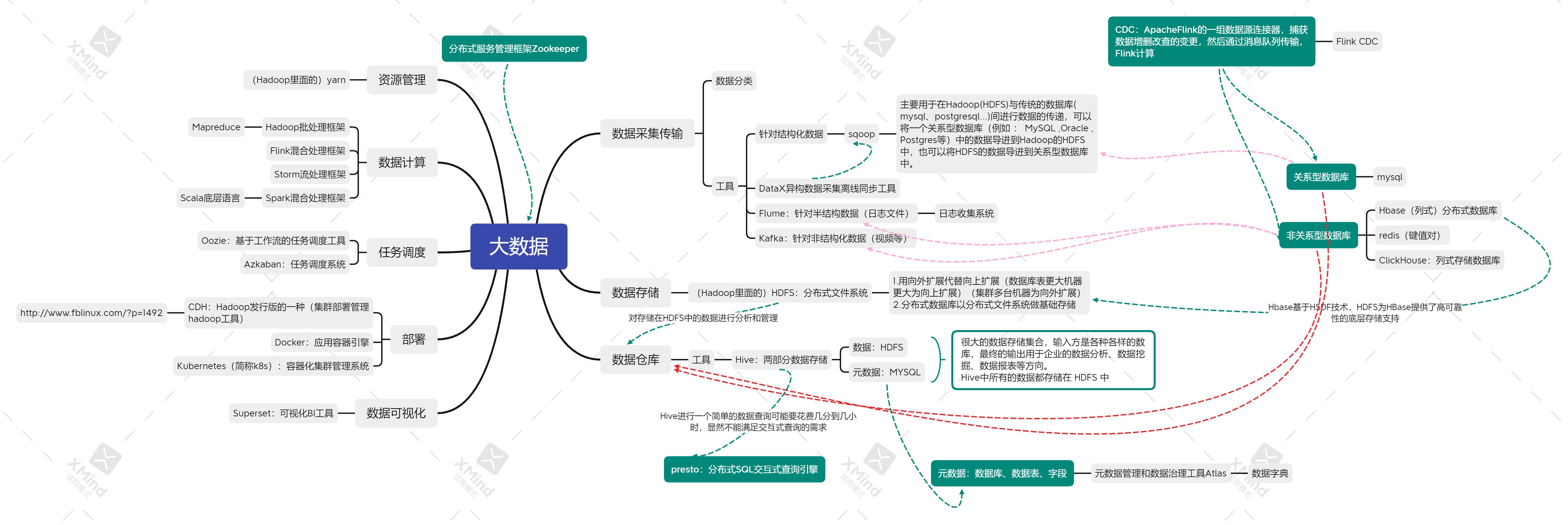
大数据思维导图-数据采集存储数据仓库计算框架资源管理&任务调度部署可视化
Posted 风吹海洋浪
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据思维导图-数据采集存储数据仓库计算框架资源管理&任务调度部署可视化相关的知识,希望对你有一定的参考价值。
【大数据】思维导图
大数据常用流程图
大数据技术分为多个层次

思维导图
大数据相关学习路线分为:
数据保存到数据库中,分为关系型数据库(常用mysql)以及非关系型数据库(Hbase分布式列式数据库),redis键值对数据库,以及clickhouse列式数据库。
数据采集工具:实时产生的日志或者文件视频等数据、以及已经存储到数据库里的数据需要查询出来进行计算,
涉及到的一些工具,例如sqoop能够将关系型数据库的数据和HDFS分布式文件存储系统进行转换。
DataX不仅可以对关系型数据库,也可以对非关系型数据库的数据进行离线同步以及采集功能。
Flume一般针对日志文件进行收集,消息队列可以缓存队列进行缓冲数据。
CDC工具:例如Flink CDC可以将数据库中数据增删改查的变更捕获到,然后写入到消息队列例如kafka中,
然后Flink计算框架进行处理计算。
数据存储:HDFS,因为一般数据库存储是存到安装数据库的机器上,只能向上扩展,
但是hdfs采用分布式存储,其中hbase数据库就是基于hdfs文件存储的列式数据库。
数据仓库:HIVE,对不同数据源的所有数据进行处理,挖掘和分析工作。
其中数据查询引擎效率不高,所以可以采用presto分布式sql交互式查询引擎。
元数据管理和数据治理工具Atlas:hive中的元数据因为有很多库,表,字段,
如何才能更好地管理,将这些元数据做成一个字典形式方便查看,就叫数据字典。
资源管理:yarn可以通过按需进行独立分配资源,
数据计算:根据不同的计算模型,处理不同的数据类型(批量和流式数据)进行分为不同的计算框架。
重点:storm、flink
部署中CDH:如果hadoop自己部署,会产生版本管理混乱、部署过程繁琐、升级过程复杂的问题,
为什么需要CDH?
假如公司要求给500台机器,进行安装hadoop集群。
只给你一天时间,完成以上工作。
或者如果对于以上集群进行hadoop版本升级,你会选择什么升级方案,最少要花费多长时间?
你在过程中会大大考虑新版本的Hadoop,与Hive、Hbase、Flume、Kafka、Spark等等兼容?
CDH通过基于Web的用户界面,支持大多数Hadoop组件,
包括HDFS、MapReduce、Hive、Pig、 Hbase、Zookeeper、Sqoop,简化了大数据平台的安装、使用难度。
以上是关于大数据思维导图-数据采集存储数据仓库计算框架资源管理&任务调度部署可视化的主要内容,如果未能解决你的问题,请参考以下文章