Hadoop的简单使用
Posted God is Love
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop的简单使用相关的知识,希望对你有一定的参考价值。
Hadoop的简单使用
-
使用Hadoop提供的命令行,向文件系统中创建一个文件。
./hadoop fs -put temp.txt hdfs://localhost:8888/
说明:
-
./hadoop 是bin目录下
-
fs 表明对文件系统进行操作
-
-put 就是传输
-
temp.txt 是我要传输的文件
-
hdfs://localhost:8888 是hdfs的入口
-
检测是否成功上传:
然后点击browse the filesystem
可以看到:

一个简单的MapReduce任务
任务说明: 使用Hadoop自动的一个案例,来统计多个文件的的各个单词出现的次数。
步骤如下:
-
通过ssh上传一些文件。为了方便,我们最好上传文本文件。从 apache的extra目录下把文件上传到ubuntu下

-
将这些文件上传到hadoop的文件系统
2.1先创建一个目录
./hadoop fs -mkdir /task1 【如果要看 hadoop有哪些指令,可以 ./hadoop 如果要看 还可以通过 ./hadoop fs 来看分项的命令】
-
将 /home/hsp/test 的所有文件上传到 /task1目录下
./hadoop fs -put /home/hsp/test/*.* /task1
-
执行一个MapReduce任务,这个是已经写好的,自带的,后面详解,现在体验
./bin/hadoop jar hadoop-examples-1.0.3.jar wordcount /task1 /result1
说明:这个指令一定要在 hadoop的bin目录下执行,因为 hadoop-examples-1.0.3.jar 是在hadoop/bin 目录下的.
结果:

-
-
验证是否正确
http://localhost:50030 , [这个就是MapReduce的管理界面]可以看到MapReduce 任务的完成情况

点击job_201506...可以看到详细情况,如下:
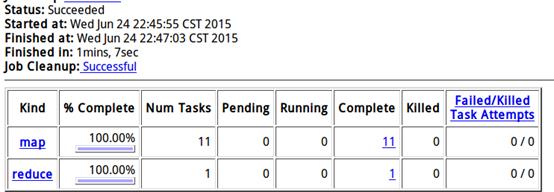
说明: 这个任务被Map了11个,有一个reduce操作。
http://localhost:50070 ,点击 part-r-00000 ,就可以看到结果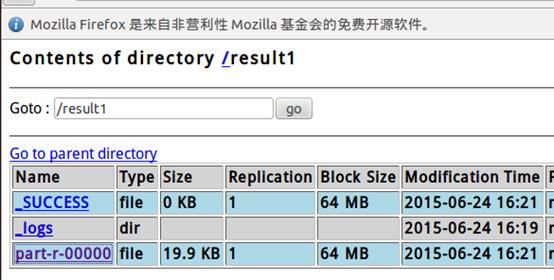
both 是5次,我们在ubuntu 直接统计一下
grep both /home/hsp/test/*.* 可以看到一个5个
grep both /home/hsp/test/*.*|wc 也可以直接得到结果.
以上是关于Hadoop的简单使用的主要内容,如果未能解决你的问题,请参考以下文章