可微硬件:AI将如何重振摩尔定律的良性循环
Posted OneFlow深度学习框架
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了可微硬件:AI将如何重振摩尔定律的良性循环相关的知识,希望对你有一定的参考价值。

本文阐述了当今AI硬件渊源,跳脱过去芯片设计窠臼,以可微分GPU及可微分ISP为例,提倡以AI为本的可微分硬件理念。希望借此可重振软硬件彼此加持的雄风,缓解甚至逆转摩尔定律的衰退。
撰文|吕坚平
据报道,正值全球芯片短缺之际,台积电提高了芯片价格并推迟了3nm制程的生产进程。无论这类新闻是否准确或预示着一种长期趋势,这都在提醒我们,摩尔定律的衰退将带来越来越严重的影响,并迫使我们重新思考人工智能硬件——它会受到这种衰退的影响,还是会帮助扭转这种趋势?
如果我们希望恢复摩尔定律的良性循环,这其中,软件和硬件曾经相互加持,使一部现代智能手机比过去10年占据整个仓库的超级计算机功能更强大。人们普遍接受后摩尔时代的良性循环是基于更大的数据迸发更大的模型并需要更强大的机器。但事实上,这样的循环是不可持续的。
除非我们重新定义并行性,我们不能再指望缩小晶体管来制造越来越宽的并行处理器。我们也不能依赖于它,除非特定领域架构(DSA)有助于促进及适应软件的发展。
与其搞清楚哪类硬件是用于 AI 这个不断发展的移动目标,我们不如从AI以可微分编程为核心的角度来看待AI 硬件。这样说,人工智能软件程序是一个计算图,由一组通过训练来实现端到端目标的计算节点组成。只要一个深度流水线起来的DSA硬件是可微的,它就可以作为一个计算节点。软件程序员可以自由地将可微硬件插入计算图中,以实现高性能和以创意解决问题,就像预构建的可定制软件组件一样。AI 硬件不应再有"血统纯正度"审查,毕竟它现在可以包括各样可微硬件。
但愿这样,软件和硬件将再次通过良性循环并行发展,就像摩尔定律盛行时那样。
1
人工智能硬件架构师的苦恼
在人工智能市场的众多GPU竞争者中,特斯拉推出了Dojo超级计算机。Dojo似乎是网络、集成和可延展性方面的杰作。而另一方面,Dojo 的组件 D1 芯片则称不上是架构上的突破。
我们可以将GPU竞争者分为两个阵营,Many-Core 和Many-MAC。D1是Many-Core阵营的一个例子,它是将多个CPU核心连接起来的“网格”。另一方面,特斯拉FSD或谷歌TPU是Many-MAC阵营的缩影,其特点是少量大型矩阵乘法(MM)加速器,每个都在一个“网格”中封装许多乘累积(MAC)单元。正如我们所看到的,关于AI架构的争论可以说是处于上述网格架构和GPU之间。
在制造芯片带来的飞速增长的冲力下,AI硬件架构师面对着巨大压力,总是胆战心惊的看待媒体对基准测试和学术大会的报导。人工智能硬件常常跑不动基准测试和最新出炉的NN模型,而讽刺的是,这些模型在所谓“老掉牙”的GPU上,却运行良好。
如下图所示,Many-Core和GPU本质上只是数据交换方式有所不同。前者通过一个互联的网格传递数据,而后者通过一个存储器层次结构共享数据。这种差异与人工智能没有什么关系。Many-Core芯片(如D1芯片)是否最终会超过GPU,还有待观察,稍后我将介绍Many-MAC 。
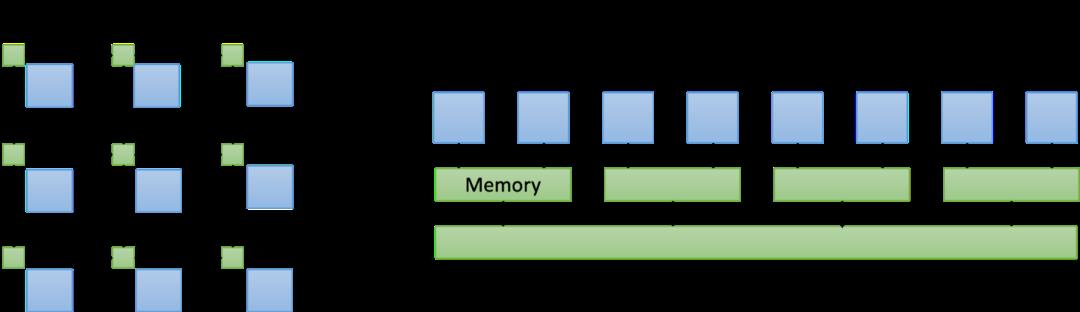
比较 Many-Core(左)和GPU(右)的概念上的连接方式
现在,让我们快速回顾一下网格架构和GPU在高性能计算(HPC)中的共同根源。
2
HPC的传承
HPC用于解决计算密集的如军事研究、科学发现、油气勘探等问题。超级计算机(简称超算)一直是高性能计算的关键硬件解决方案。与处理指针丰富的数据结构(如树和链表)的通用程序相比,HPC程序主要花时间在“循环”中重复数据并行计算。
矢量优先理念的兴衰
在20世纪70年代和90年代,矢量优先理念,通过将数据并行循环展开成矢量来加速高性能计算程序,主导了高性能计算市场。在那期间,矢量优先理念等同于超级计算机。
在 1990 年代,正当摩尔定律鼎盛之时,通过将许多现成的 CPU 排列在网格或某种类似的拓扑结构中来构建超级计算机变得可行。这种趋势导致了分布式优先理念的出现。
尚未接受分布式优先理念的HPC 社区抗拒地将其称为 The Attack of the Killer Micros,其中“Micro”意味着微处理器。这种观点源于一个芯片上的CPU在早期被称之为微处理器,而“CPU”通常是一个由独立组件组成的系统。最终,分布式优先理念取代了矢量优先理念,成为今天超级计算机的代名词。
矢量优先理念以GPGPU的身份王者再临
在21世纪初,摩尔定律开始呈现老化,导致CPU时钟速度竞赛戛然而止。然而CPU时钟速度曾是单晶片计算性能的主要来源。业界的回应是在一个芯片上安装多个CPU核,期望并行性成为新的主要性能来源。这一趋势带来双核、四核以及最终的多核,有效地形成了分布式优先理念集于一芯,将多个CPU核心排列在一个网格中。Many-Core的例子包括英特尔在市场上挑战GPU的两次挫败,Larrabee在3D市场,以及Larrabee的后代Xeon Phi系列在HPC。
GPU传统上对顶点、三角形和像素等图形单元上展开“循环”。GPU架构师将这种能力扩展到HPC应用中的环路,使GPU有效地成为矢量优先理念集于“一芯”。然后他们将GPU在HPC中的使用命名为通用GPU (即GPGPU)。当矢量优先理念在HPC市场让位给分布式优先理念时,后者就化身为GPU来报复它的竞争对手。我们可以看到GPU在顶级超算机上的商业成功,比如橡树岭国家实验室的Titan超算机和瑞士国家超算中心的Piz Daint。

简而言之:
-
分布式优先机将矢量优先机从HPC市场踢出局
-
Many-Core是分布式优先“集于一芯”
-
GPU是将高性能计算的矢量优先“集于一芯”
3
矩阵乘法(MM)和AI
网格,计算机架构中的“旧锤子”,如何自我升级改造视人工智能为“新钉子”?
MM和HPC
计算机体系结构中的一条永恒规则是,移动数据比计算数据更昂贵,因此计算机架构希望在较少的数据上进行更多的计算(也就是较高的计算访存比或计算强度)。
幸运的是, HPC社区从几十年的实战经验中学到,他们可以用矩阵乘(MM)来表达大多数 HPC问题,大致说来,MM运算具有很高的计算-通信比。如果运用得当,使用MM解决问题可以通过隐藏数据传输来实现高性能。
因此,HPC程序员只需要超算机供应商提供的一个健全的MM程序库。当计算MM时,今天的分布式优先计算机可以充分利用分布在数十万平方英尺上的数十万节点,有效地令每个单个节点都忙于计算。
矩阵乘法(MM)在AI中的崛起
运用基于神经网络(NN)的机器学习(ML)是现代人工智能的特征。神经网络模型由多层ML核心程序组成。在卷积神经网络(CNN)之前,最流行的神经网络(NN)是多层感知器(MLP)。MLP的基本ML核心程序是矩阵矢量乘法(MVM),它对数据进行粗略的MAC操作,几乎没有数据重用。
另一方面,CNN目前主要的运算是张量卷积(Tensor Convolution, TC)。正如我在我的文章“All Tensors Secretly Wish to Be Themselves”中解释的那样,在数据搬动和共享方面,MM和TC在结构上是等价的,所以我们经常可以互换使用张量和矩阵。
将MM作为运算单元给HPC和人工智能带来了突破。CNN主要使用了MM,引发了计算机视觉领域人工智能的突破。Transformer也广泛使用了MM,点燃了人工智能在自然语言理解(NLP)方面的突破。
多亏了人工智能及其对MM的大量使用,计算机体系结构社区才有了一个世纪一遇的机会,能够聚焦在优化MM这单纯的目标,而又能同时对计算产生广泛的影响——等于是事半功倍。
Many-Core 可以运行与分布式优先机器相同的MM算法。从某种意义上说,从事人工智能的Many-Core 可以说是归宗到HPC。
Many-MAC的浪潮
1982年,脉动阵列被引入加速MM和其他应用。如果当年在人工智能的背景下加速MM像今天一样酷,那么脉动阵列的研究人员就不会为MM之外的应用而费心了。
脉动阵列是一种比CPU内核更密集地封装MAC单元的机制。它的缺点是,我们不能把MM MAC单元用在其它场景。由于缺乏通用性,直到因为AI成为MM的杀手级应用,谷歌在TPU上采用脉动阵列作为MM加速器之后,脉动阵列才被市场接受。从那时起,市场上就出现了许多改进原作的版本。在这里,我将原始的脉动阵列及其变体称为Many-MAC。为了处理非MM操作,Many-MAC增加了配套处理器。
另一方面,Many-Core 中的 CPU 核心,例如 D1 芯片或GPU 的着色器核心,可以使用更小的 Many-MAC,从而有效地成为 Many-MAC 容器。
简而言之:
-
AI和HPC因为使用大量MM而命运交汇
-
Many-Core 和 Many-MAC基本上不比GPU更适配AI
4
领域转移和领域特定的并行性
暗硅和功耗墙
在2010年之后,业界共识虽然理论上来说,拥有两倍的CPU核心,并行度加倍是计算性能的主要来源,然而不可能一直保持这种良性循环。这是因为每个 CPU 核无法将其功耗降低一半,或每瓦并行度翻倍。在几次迭代的核加倍后,我们会看到大多数核在相同的功率预算下无法被供电,从而产生了暗硅,或者更准确地说,是暗核。
如下图的概念图所示,当我们从 2 核变为 4 核时,4 个核中只有 3 个可以供电,而当我们从 4 核变为 8 核时,只能为 4 个核供电。最后,16 个内核中只有 4 个可以供电,因此从 8 核变为 16 核没有任何好处。我们将这种现象称为“功耗墙(hitting the Power Wall)”。
由于这个原因,相当一部分计算机架构社区成员疏远并行化。此外,悲观主义者倾向于将并行度低、指针丰富的计算作为主流,并将具有并行性的HPC视为一个小众市场。他们认为,良性循环将过早止于阿姆达尔上限,也就是并行运算的极致。

暗硅或暗核
人工智能的完美救援
巧合的是,在这种悲观情绪中出现了人工智能。根据斯坦福 AI 指数报告,人工智能一直不断进步,就好像功耗墙不存在一样!
关键在于主流软件可能会发生领域转移,导致不同并行模式。如下面的概念图所示,当主流软件从指针丰富计算转向数据并行计算时,它将一个并行度重新定义为单指令多数据(Single-Instruction-Multiple-Data, SIMD)的一条通道而不是一个CPU核。我们看到一条比CPU核曲线更高的曲线(标记为SIMD lanes for data-parallel)。
接下来,当主流软件进入着重于MM的AI领域时,添加了更高的曲线(标记为MM MACs for MM-heavy),一个MM MAC代表一个并行度。正如我们所看到的,通过探索更有效的领域特定并行模式和提高阿姆达尔定律的上限,计算性能在功耗墙之内继续增长。
顺带一句,着重于MM的AI 有自己的阿姆达尔上限。AI 应用程序需要有循环前奏,将 MM 操作分配到并行计算资源,以及循环尾声收集计算结果进行串行操作(如归一化或 softmax)的结果。当有足够多的 MM MAC 来加速 MM 时,阿姆达尔定律就会发挥作用,从而使循环前奏和尾声成为瓶颈。
此外,随着摩尔定律的衰落越来越严重,制造更宽的加速MM的机器是否能维持AI的良性循环就成了问题。为了解决这个问题,进一步提高阿姆达尔的上限,我们需要转移到更新的领域并探索新的领域特定并行性。换句话说,我们要考虑是否需要在下面的概念图中添加一条新的曲线。
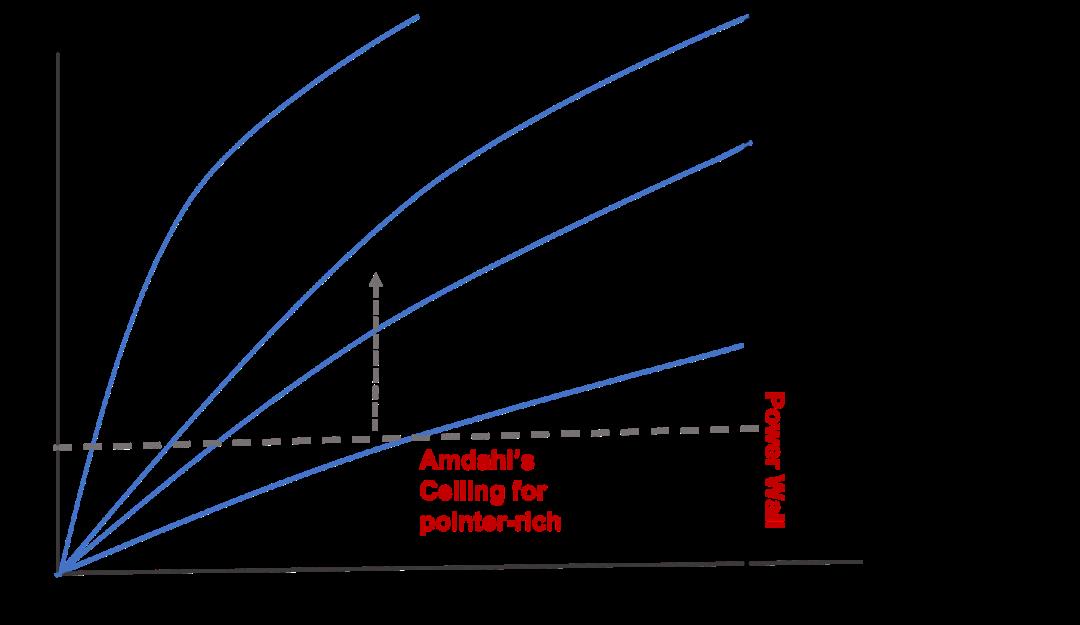
通过不同领域转移扩展平行度的概念图
简而言之:通过将指针丰富的领域转移到数据并行,进而到重于MM的计算,我们不断在功耗墙内提升性能。
5
下一个领域转移
可微分编程
英特尔的 Raja Koduri 表示,“神经网络是新的应用程序。我们看到的是,每个插槽,[无论是] CPU、GPU 还是 IPU,都将具有矩阵加速功能。”
特斯拉的Ganesh Venkataramanan将他们的D1芯片描述为“纯正”ML机器,专门运行“ML核心程序”,无需传统硬件。或许,他在暗示GPU不像D1那样血统纯正,因为它的图形专用硬件在AI处理过程中处于闲置状态。
以上两种观点引出了两个问题——人工智能的领域转移应该止于加速矩阵乘法吗? 服务于传统领域的设计是否该被排除在人工智能硬件之外?
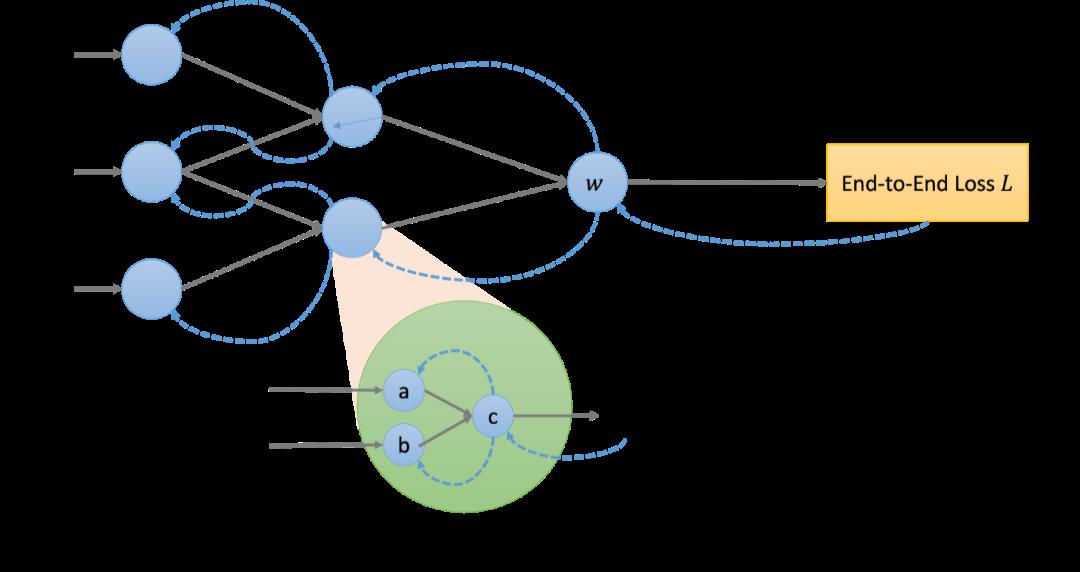
现在,我们从AI的核心是可微编程(DP)的角度来探索AI硬件的不同观点。AI软件程序是一个计算图,如下图所示,由参数化计算节点组成,每个节点将上游节点的输出作为输入,并将计算输出提供给下游节点。我们通过“训练”决定所有计算节点的参数,训练程序首先计算用到最终输出的端到端损失,然后计算该损失的输出梯度。沿着用于计算输出的相反方向,它进一步使用标准的微积分链规则重复计算中间梯度。
DP只要求任一个计算节点是可微的,使得它可以与所有其他节点共同优化,通过梯度下降最小化端到端损失。计算节点的可微性使其能够维持一条从下游到上游的反馈路径,最终完成一个端到端的反馈循环。在DP下,计算节点不一定是传统的“ML核心程序”。计算图可以是异构的,包括非ML软件和硬件节点,只要它们满足可微性要求。
6
计算图
概念上的计算图
一个计算节点,使用参数w 及输入x计算输出y, 同时计算并记住用于计算输入梯度的输出/输入微分。反馈路径将输入梯度传播到上游节点,如蓝色虚线所示。如果有必要,它计算并记住输出/参数微分,以计算参数梯度来调整参数。让我们来看一些例子。
可微分图形环路
越来越多的神经网络模型具有异构计算节点符合可微分编程的定义。那些解决逆向图形问题是很好的例子。与正向图形(从三维场景参数生成二维图像)不同,逆向图形从二维图像恢复场景参数。新兴的基于人工智能的逆向图形解决方案通常包括一个不同于传统的可微分图形渲染器。它将梯度逆向传播到上游节点,参与梯度下降以最小化端到端损失。具有可微图形环路的逆图形管线的强大功能在于使逆图形“自我监督”化,如下图所示。
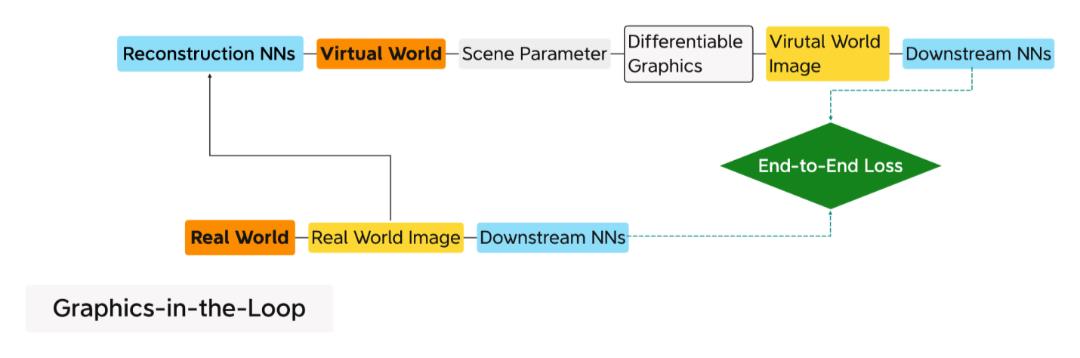
重建神经网络从真实图像中获取场景参数,可微图形根据场景参数绘制虚拟图像。两个共享下游NN处理好真实世界和虚拟世界的图像来计算它们之间的端到端损失。假设环路中没有可微图形,我们必须为场景参数准备3D的基本事实。相反,真实世界的图像有效地充当虚拟世界图像的基本事实,使过程自我监督化。
目前的可微分渲染器,如Soft Rasterizer, DIB-R,以及那些在AI框架中使用的渲染器,如PyTorch3D, TensorFlow Graphics,都是不使用特定于图形硬件的软件渲染器。这种软件实现不像典型的ML核那样着重MM,因此不能利用MM加速。
另一方面,GPU架构师用足够深的管线设计和提供特定于图形的硬件,以便它们速度快,不再成为瓶颈。现在,假设我们制作了这样一个流水线“可微硬件”。软件程序员可以在计算图中有效地使用可微硬件,类似于使用预构建的软件组件。由于图形专用硬件的深层流水线并行性,这种硬件图形环路应该比其软件对应物快得多。
可微分ISP环路
除了使用微分硬件作为预构建的软件组件外,我们还可以通过梯度下降调整其参数来“编程”,就像我们“训练”ML核心程序一样。例如,图像信号处理器(ISP)通过镜头捕获图像,并在线上对其进行处理,以生成供人类观赏或下游图像理解(IU)任务(如物件侦测或语义分割)使用的图像。传统的ISP有充足的参数空间,但需要专家对其进行调整,以满足人类的需求。
目前为止,人类专家没有能力针对下游IU神经网络模型调整该参数空间。相反,ISP在特定参数设置下预捕获和预处理的图像被用来训练神经网络模型。此外,捕获图像的透镜系统在制造和操作期间可能存在缺陷。如果没有与ISP的联合优化和设备调整,IU NN模型将无法令人满意地执行任务。
目前已经有很多提议用 NN 模型替换某些 ISP 处理阶段,当然,这在具有特定功率和实时要求的场景中不一定实用或更好。另一方面,已经有新兴研究试图利用 ISP 的未开发的参数空间。
这里有些例子:
-
环路中的不可微ISP硬件,用于非ML优化的参数自动调整。
-
经过训练的 NN 模型模仿 ISP的可微代理, 用 于基于ML 的参数自动调整。
上述研究表明,通过为特定 IU 任务设置端到端目标,自动调整的 ISP 优于没有自动调整的 ISP。
第一种方法,不可微ISP不能与其他神经网络模型联合优化。另一方面,虽然使用可微代理的第二种方法有助于训练,但其缺点是我们需要在仔细控制的环境中单独训练此代理。
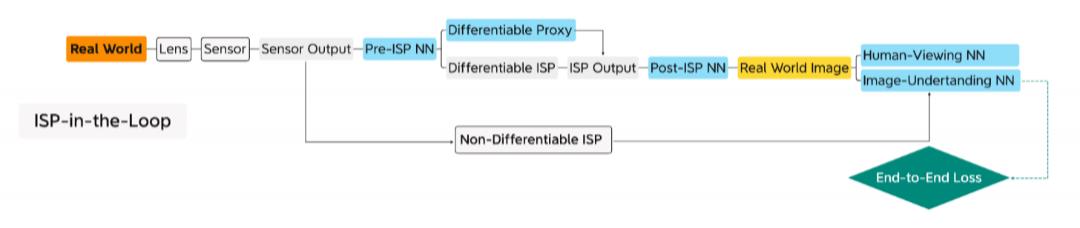
现在,想象一下使ISP可微。我们可以在环路中使用ISP组成一个自适应传感线程,如下图所示。它可以在具有ISP前和ISP后NN模型的设备上联合调整自身,以适应操作环境和特定UI任务。请注意,我们不固定ISP前和ISP后NN模型,就像GPU架构师不指定图形着色器一样(请参阅文章《GPU将成为计算机体系结构黄金时代的明星》)。
7
结论
我们使用图形环路和ISP环路的例子介绍了可微分硬件的概念。更进一步,假设我们已经在芯片上同时拥有可微分 ISP 和可微分 GPU。我们还需要自监督逆向图形和自适应传感。如下所示,我们可以通过连接图形回路和ISP回路组成一个新管线。
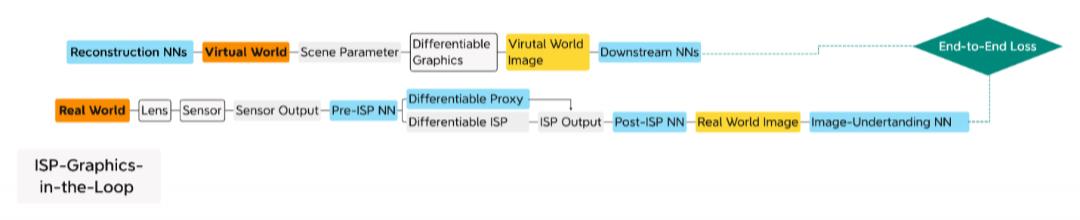
我们可以看到,一个可微分硬件单元在以下三个方面看,是可编程的:
1.AI程序员可以在计算图中使用它,相当于他们在软件开发中使用预构建和可定制的软件组件。
2.AI程序员可以使用用于训练NN模型的相同ML框架自动调整此可微硬件单元的参数。
3.AI程序员可以自由选择各种NN模型来搭配这种可微硬件单元,就像图形编程人员可以自由编程不同类型的着色器一样。
AI 已将主流软件的领域转移到着重MM的计算。软件程序员可以将广泛的应用程序简化为 ML 核心程序。为了重振摩尔定律的良性循环,我们需要另一个领域转移。与其搞清楚哪些硬件是用于 AI 这个不断发展的移动目标,我们应该遵循 AI 的精神——可微分编程,改变我们设计和使用计算硬件的方式。不再对 AI 硬件进行“血统纯度”审查,它可以包括MM之外的可微分硬件。
如此一来,硬件有望在创新软件中延长其生命周期,软件可以利用硬件作为预构建和可定制的组件。希望双方都能加持彼此进入一个新的良性循环,就像摩尔定律鼎盛时那样。
(本文由作者吕坚平博士授权后发布,原文:
https://towardsdatascience.com/differentiable-hardware-9bb03aad4563)

作者简介:吕坚平毕业于耶鲁大学并获计算机科学博士学位,曾在英伟达、英特尔、三星等跨国半导体巨头担任要职,是GPU领域的著名专家,去年九月,吕博士正式加盟上海天数智芯半导体有限公司,任首席技术官(CTO)。
其他人都在看
欢迎下载体验OneFlow新一代开源深度学习框架:https://github.com/Oneflow-Inc/oneflow/ https://github.com/Oneflow-Inc/oneflow/
https://github.com/Oneflow-Inc/oneflow/
以上是关于可微硬件:AI将如何重振摩尔定律的良性循环的主要内容,如果未能解决你的问题,请参考以下文章
MIT新研究:43%算法改进速度超摩尔定律,解决超大规模问题,算法比硬件更有用...
一周AI新鲜事“擎天柱”霸气登场/全球创新指数中国排名11位/摩尔定律死了,又活了?...