kakfa从入门到放弃: 分区和副本机制
Posted 浅弋、璃鱼
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kakfa从入门到放弃: 分区和副本机制相关的知识,希望对你有一定的参考价值。
文章目录
一、分区和副本机制:
1. 生产者分区写入策略:
生产者写入消息到topic, kafak将依据不同的策略将数据分配到不同的分区中:
- 轮训分区策略;
- 随机分区策略;
- 按key分区分配策略;
- 自定义分区策略;
1.1 轮训分配策略:
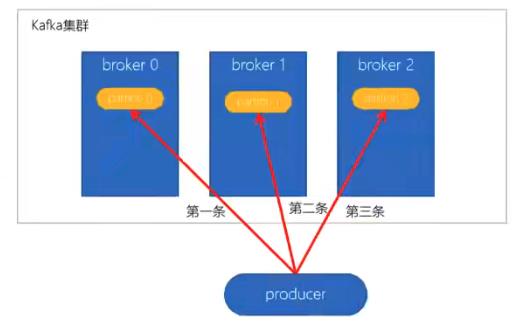
- 默认的策略, 也是使用最多的策略, 可以最大限度的保证所有消息平均分配到一个分区;
- 如果在生产消息时, key为null, 则使用轮训算法均衡的分配分区;
1.2 随机策略(不用):
随机策略, 每次都随机地将消息分配到每个分区; 在较早的版本, 默认的分区策略师随机策略; 也是为了将消息均衡的写入每个分区; 但后续轮训策略表现更加, 所以基本上很少使用随机策略;

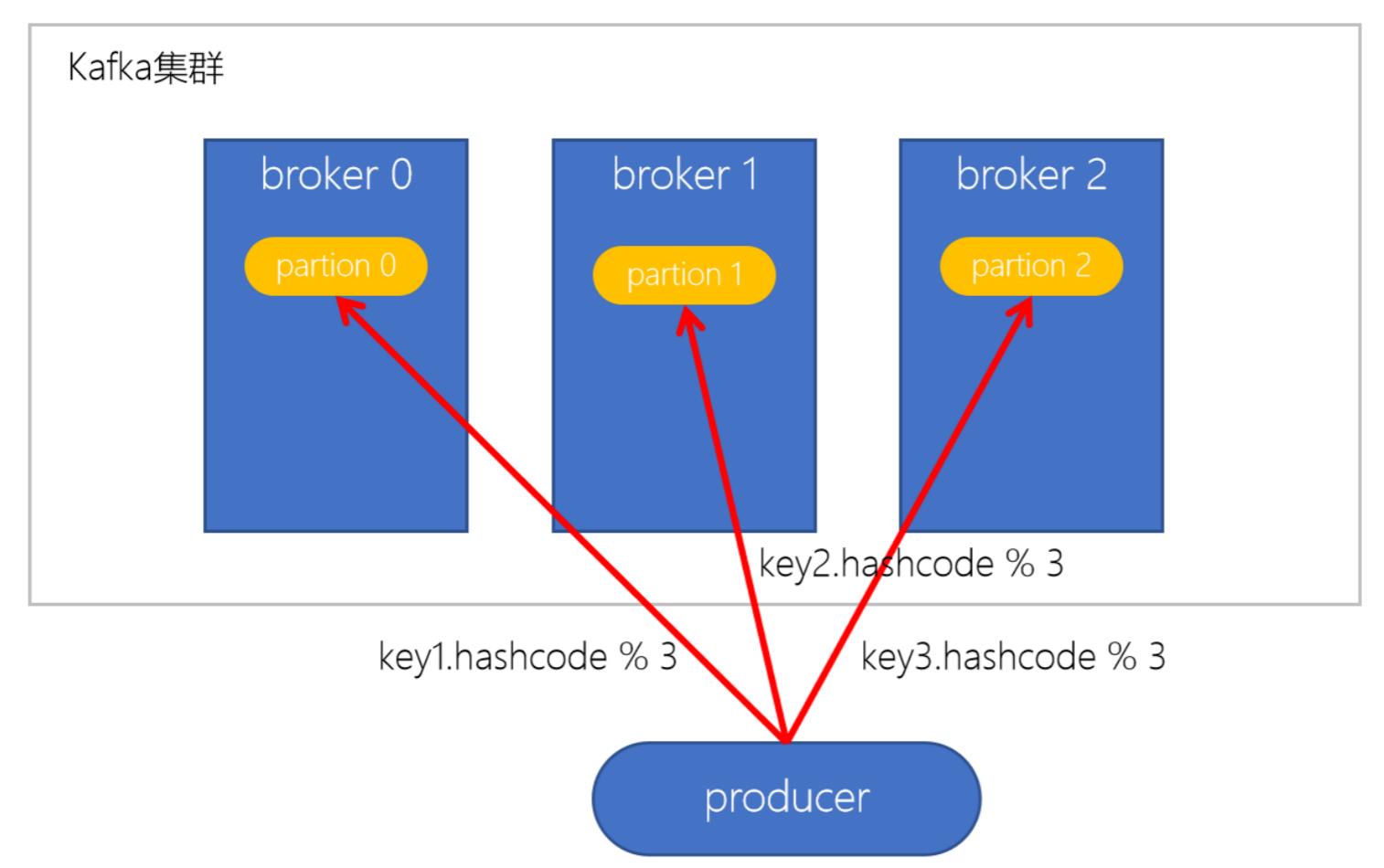
1.3 按key分配策略:
按key分配策略, 有可能出现 数据倾斜; 例如: 某个key包含大量的数据, 因为key值一样, 所以, 所有的数据都将分配到一个分区中, 造成改分区的消息数量远大于其他分区;
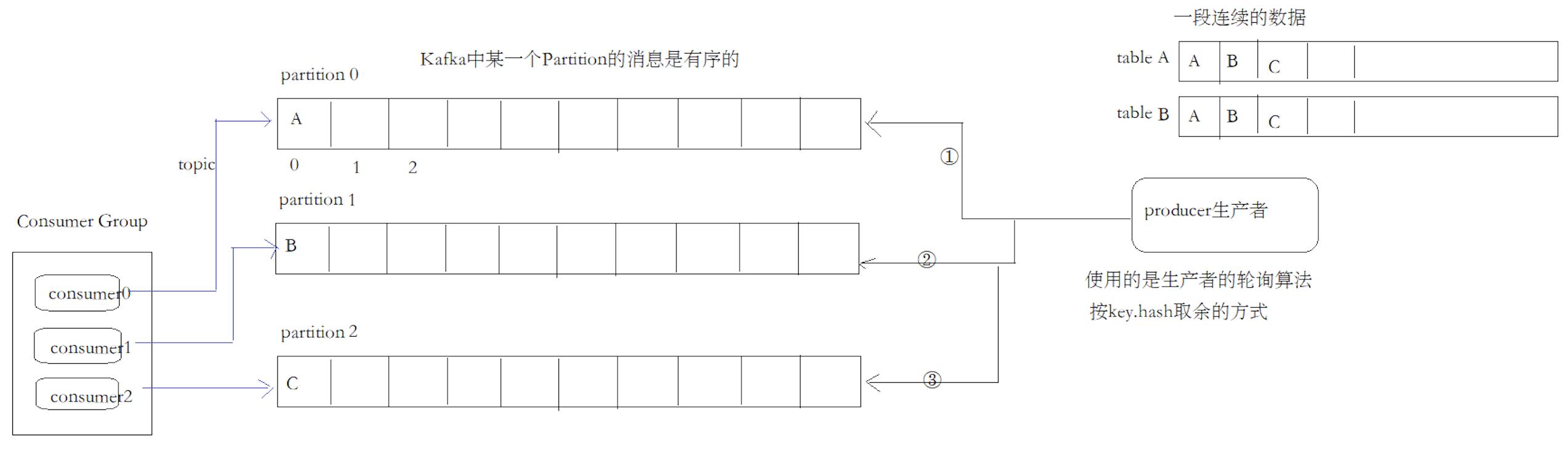
1.4 乱序问题:
轮训策略, 随机策略都会产生一个问题, 生产到kafka中的数据是乱序存储的, 而按key分区可以在一定程度上实现数据有序存储–也就是局部有序, 但这又可能导致数据倾斜, 所以在实际生产环境中要结合实际情况来取舍; 即: kafka中的消息是全局乱序, 局部partition是有序的; 如果要实现消息总是有序的, 可以将连续的消息放到一个partition, 但kafka失去了分布式的意义;
1.5 自动以分区策略:
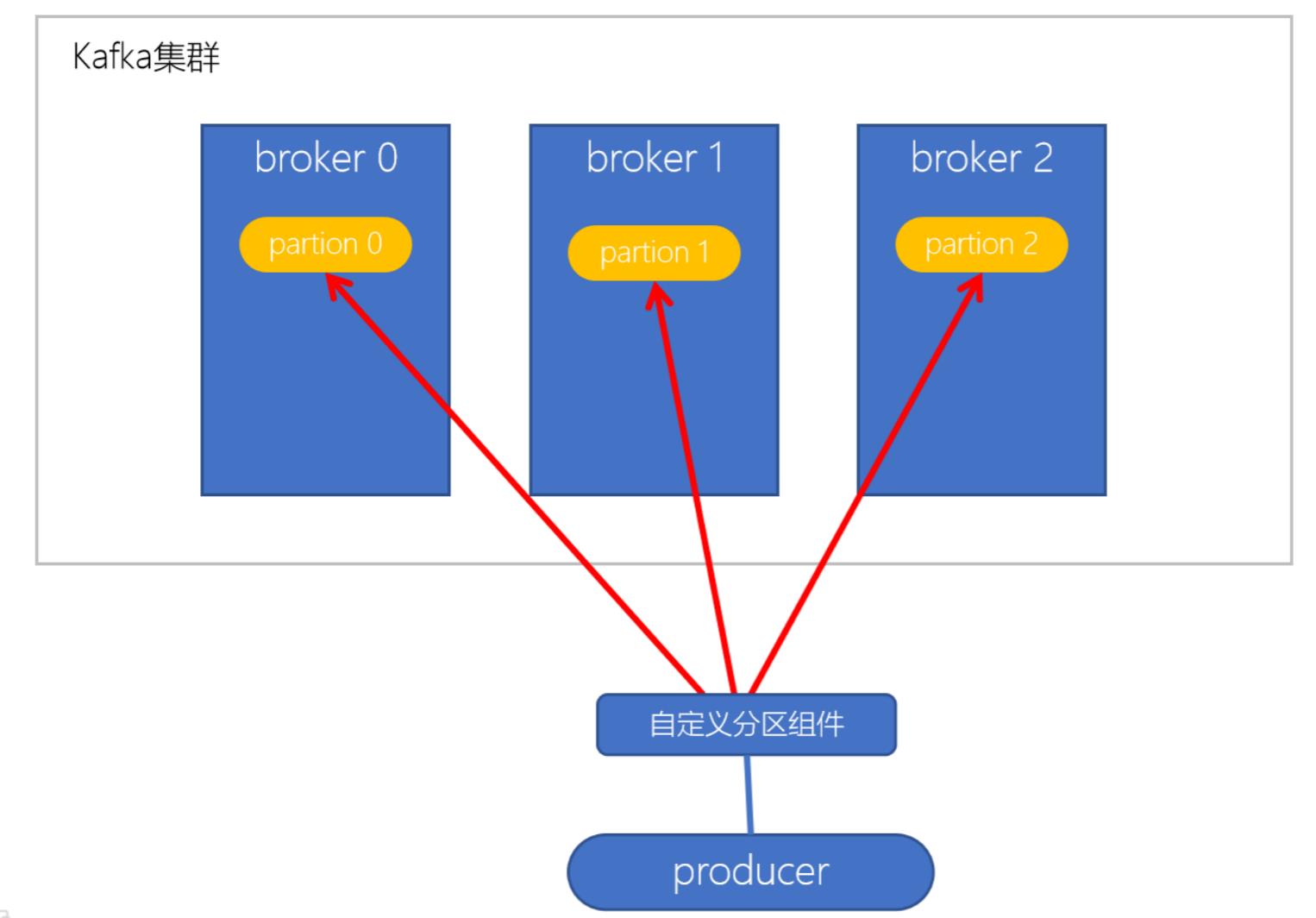
实现步骤:
- 创建自定义分区器;
- 在kafka生产者中, 自定的使用自定义分区器;
2. 消费者组Rebalance机制:
2.1 Rebalance 再平衡:
kafka中rebalance称之为"再平衡’, 是kafka中确保Consumer Group下所有的consumer如何达成一致, 分配订阅的topic的每个分区的机制;
Rebalance触发时机有:
- 消费者组中consumer的个数发生变化; 例如: 有新的消费者加入, 或者是某个consumer停止;

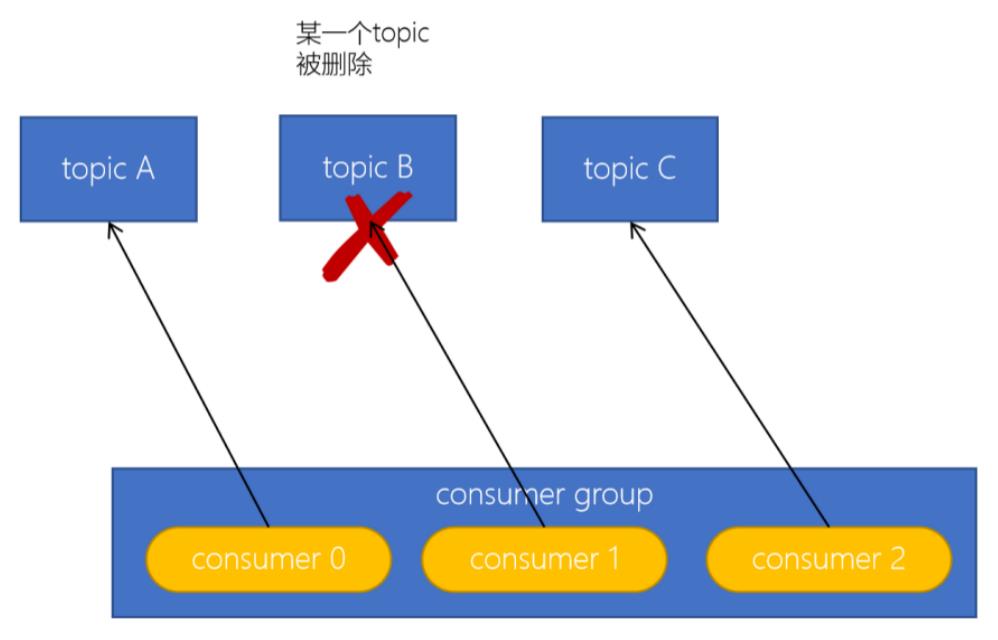
- 订阅的topic个数发生变化:
消费者可以订阅多个主题, 假设当前的消费者组订阅了三个topic, 但又一个topic突然被删除了, 此时需要再平衡;
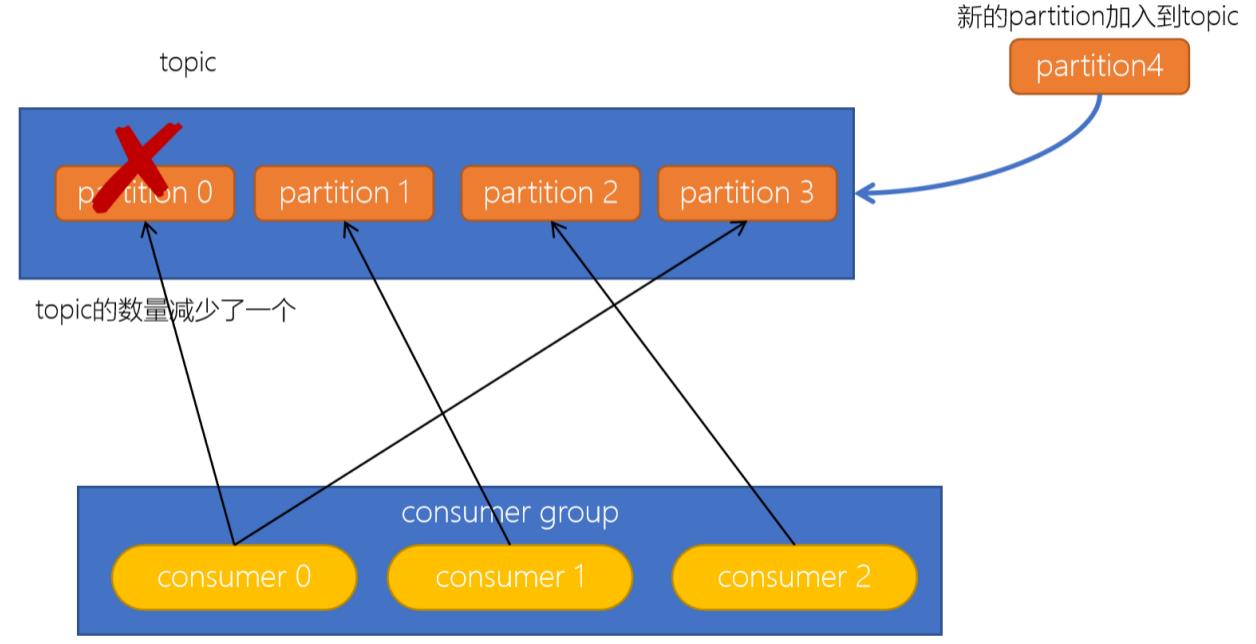
- 订阅的topic分区数发生变化
2.2 rebalance的不良影响:
- 发生rebalance时, consumer group下的所有consumer都会协调在一起共同参与, kafka使用分配策略尽可能达到公平分配;
- rebalance过程会对consumer group产生非常严重的影响, rebalance的过程中所有的consumer都将停止工作, 直到rebalance完成;
3. 消费者分区消费策略:
3.1 Range范围分配策略:
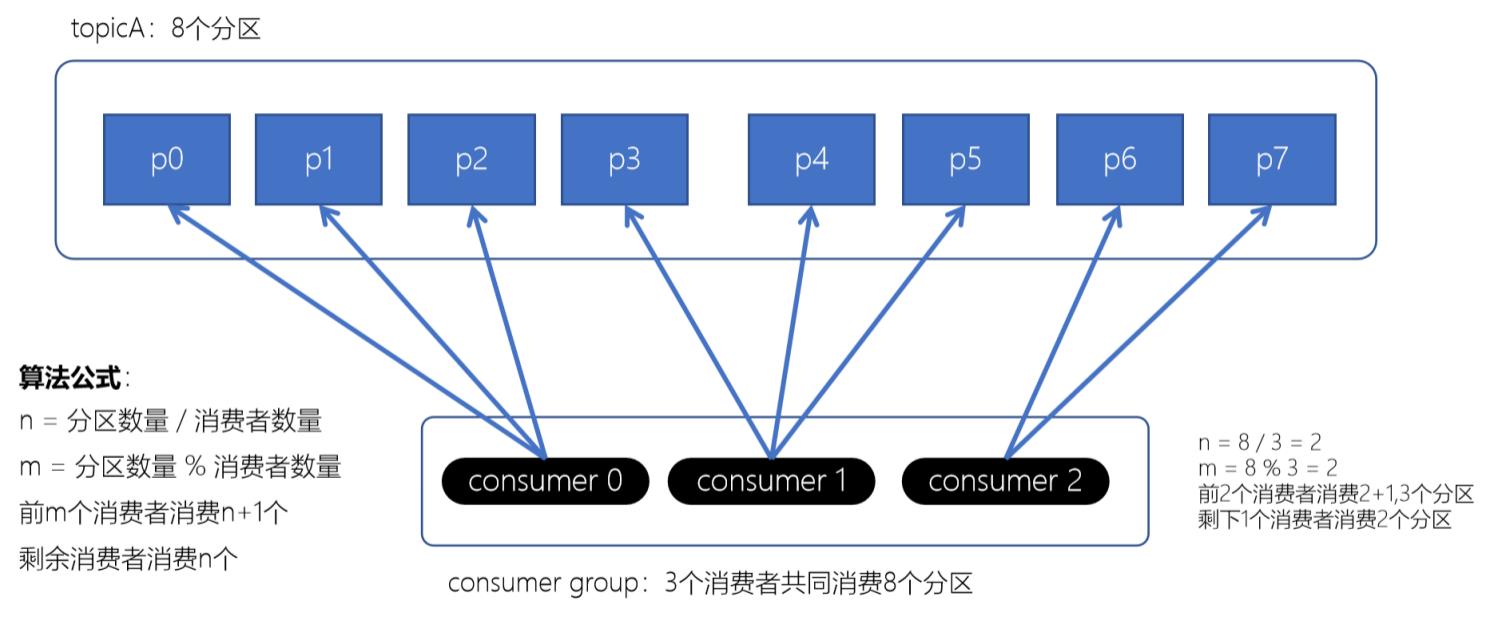
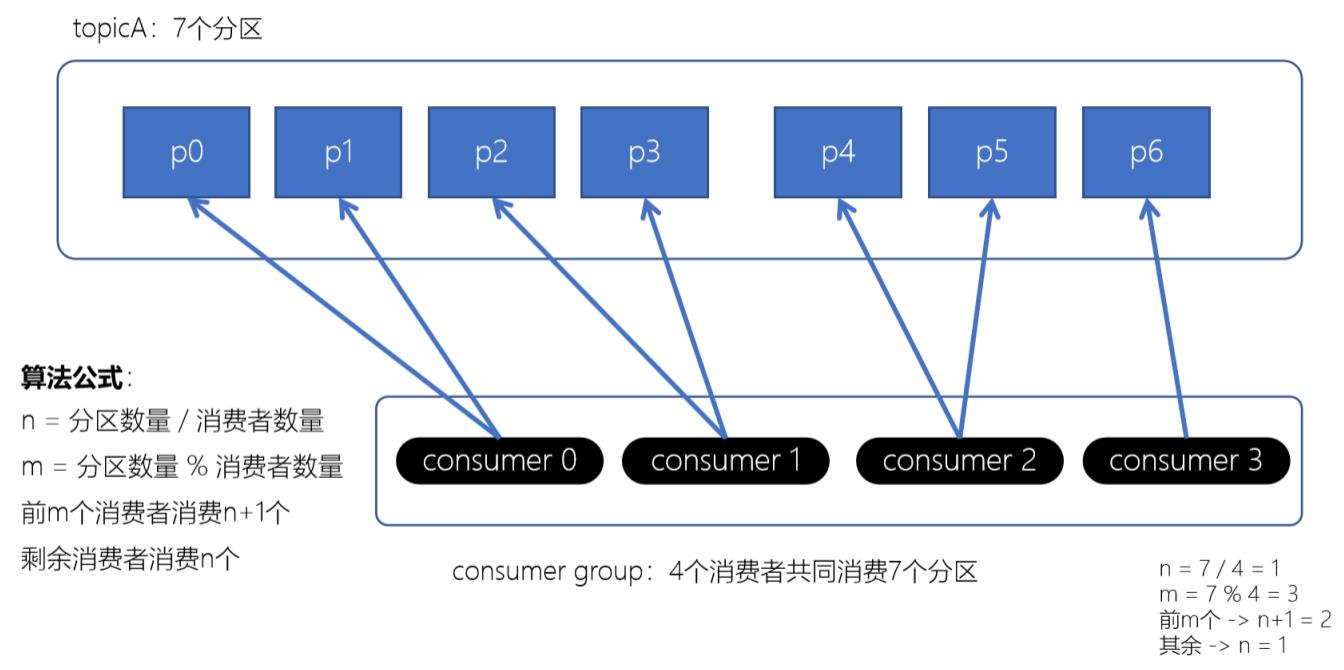
Range范围分配策略是kafka默认的分配策略, 它可以确保每个消费者消费的分区数量是均衡的;
注意: Range范围分配策略是针对每个topic的
配置
配置消费者的partition.assignment.strategy为org.apache.kafka.clients.consumer.RangeAssignor
算法公式
n = 分区数量 / 消费者数量
m = 分区数量 % 消费者数量
前m个消费者消费n+1, 剩余消费者消费n个
3.2 RoundRobin轮训策略:
RoundRobinAssignor轮询策略是将消费者组所有消费者以及消费者所订阅的所有的topic的partition按照字典顺序排序(topic和partition的hashcode进行排序), 然后通过轮训方式逐个将分区一次分配给每个消费者;
配置
配置消费者的partition.assignment.strategy为org.apache.kafka.clients.consumer.RoundRobinAssignor
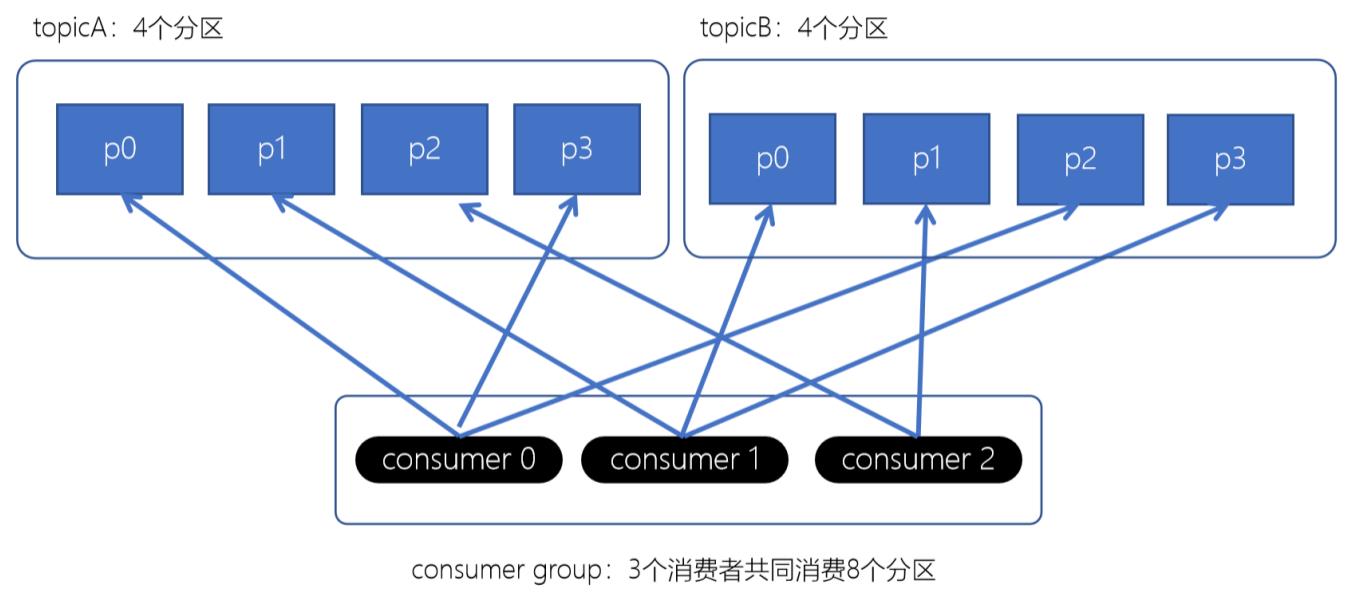
3.3 Stricky粘性分配策略:
从kafak 0.11.x开始, 引入此类分配策略; 主要目的:
- 分区分配尽可能均匀;
- 在发生rebalance的时候, 分区的分配尽可能与上一次分配保持相同;
- 没有发生rebalance时, stricky粘性分配策略和RoundRobin分配策略类似;
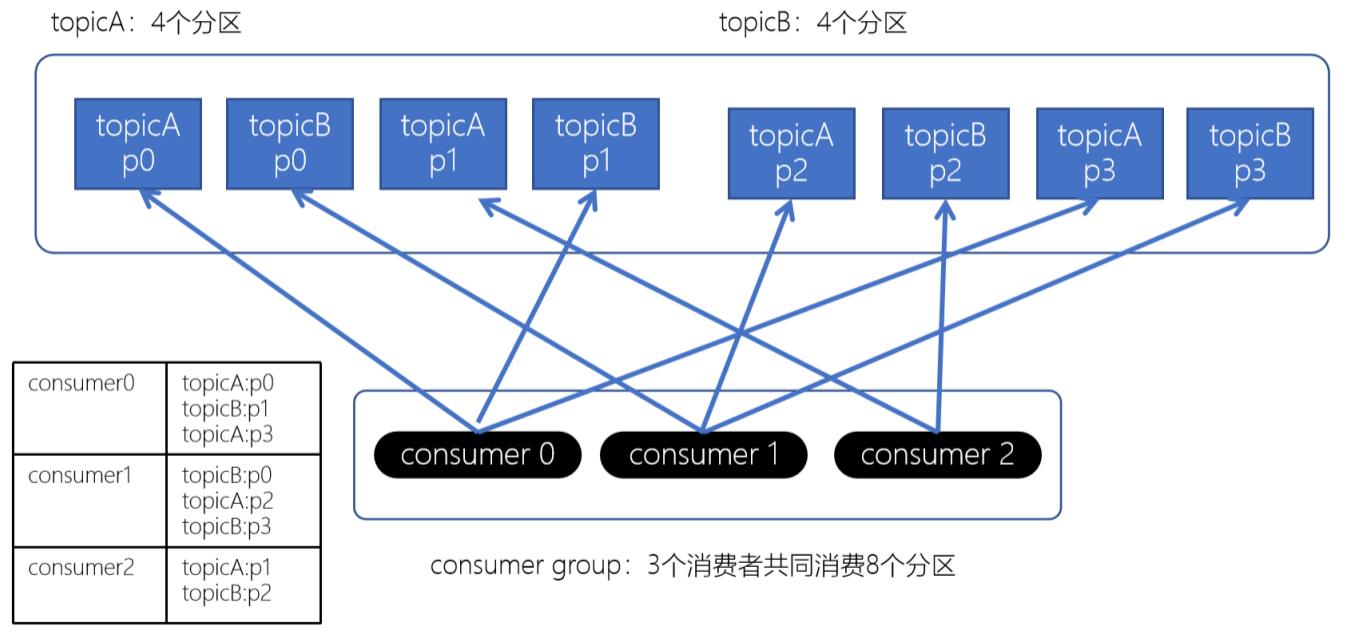
如果consumer2崩溃了, 此时需要进行rebalance; 如果是Range分配和轮询分配都会重新进行分配;
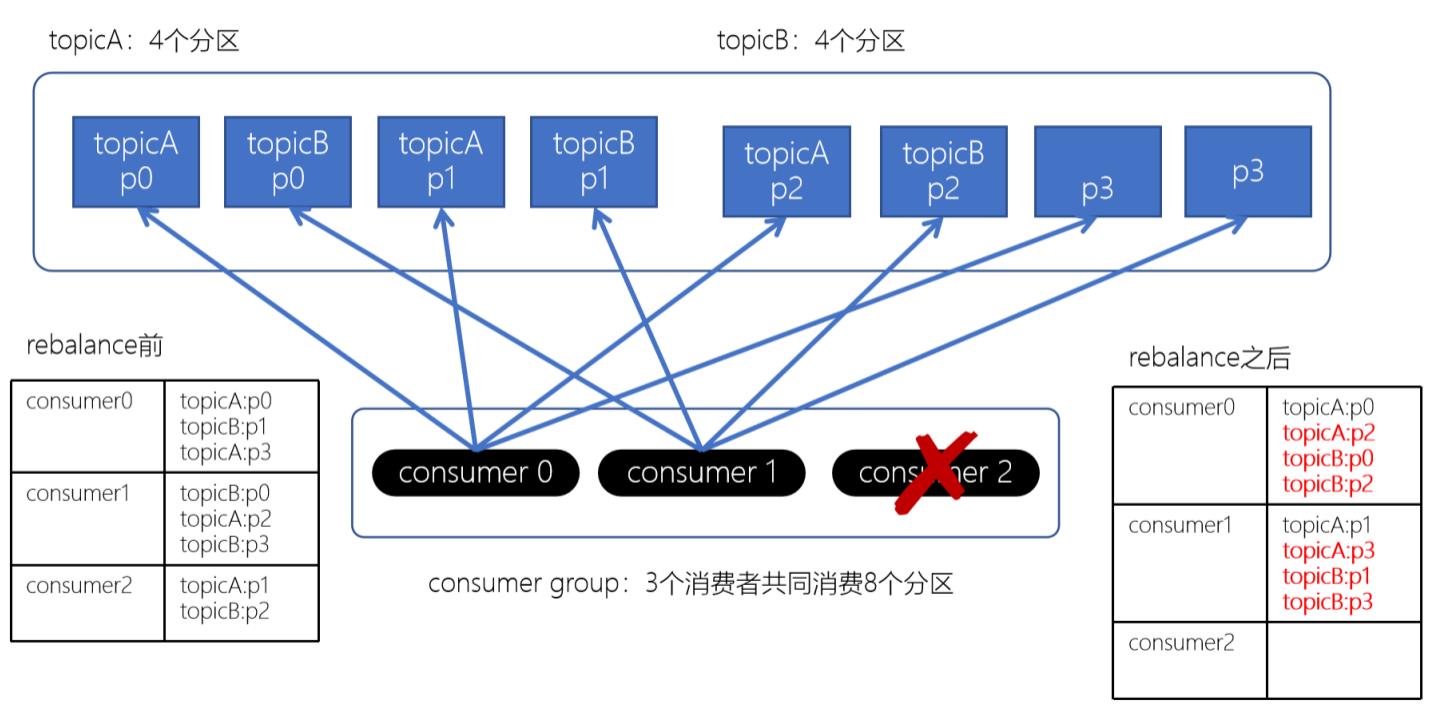
此时, consumer0和consumer1原来消费的分区大多发生了改变;
粘性分配方式:
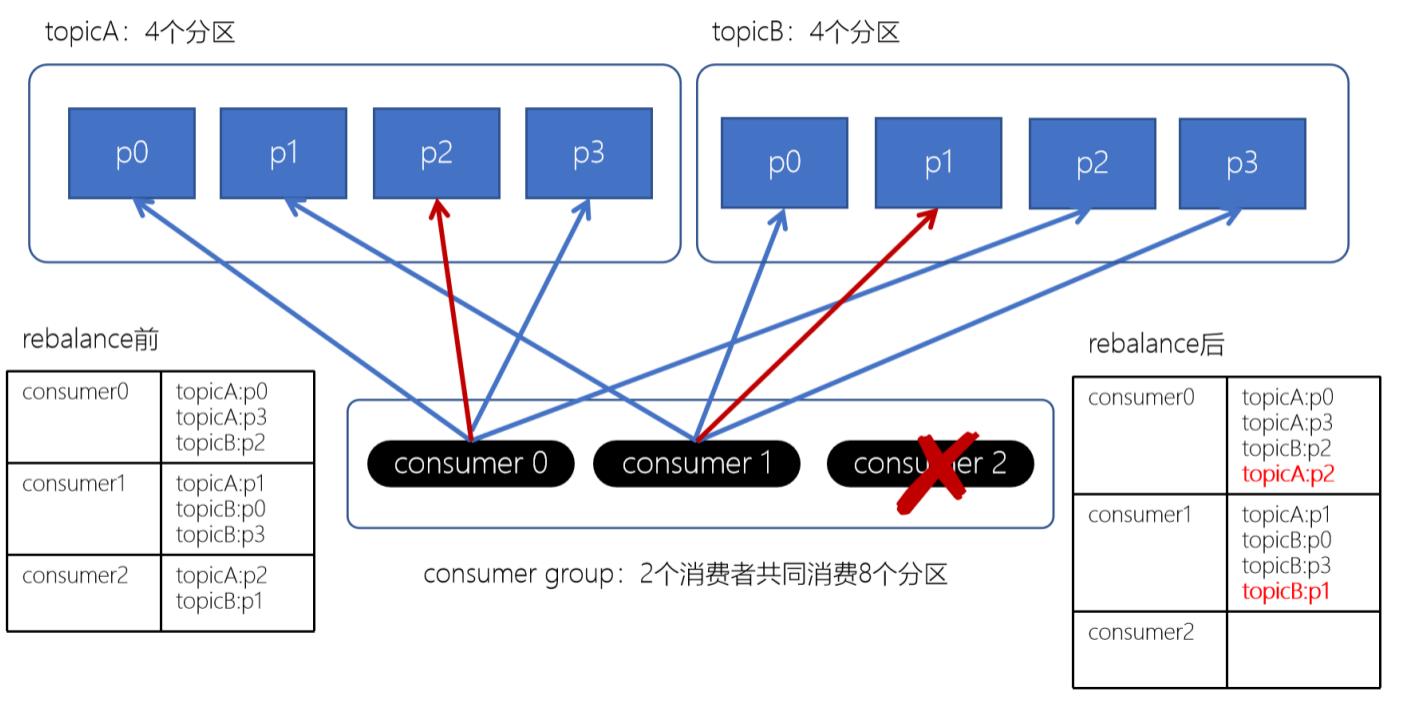
粘性分配策略, 保留rebalance之前的分配结果, 只是将原先的consumer2负责的两个分区再均匀分配给consumer0、consumer1; 这样可以明显减少系统资源的浪费, 例如: 之前consumer0、consumer1之前正在消费某几个分区, 但由于rebalance发生, 导致consumer0和consumer1需要重新消费之前正在处理的分区, 导致不必要的系统开销;
4. 副本机制:
副本的目的就是冗余备份, 当某个Broker上的分区数据丢失时, 依然可以保障数据可用; 因为在其他的broker上的副本是可用的;
4.1 producer的ACKs参数
对副本关系较大的就是, producer配置的acks参数;
acks参数表示当生产者生产消息的时候, 写入到副本的要求严格程度; 它决定了生产者如何在性能和可靠性之间的取舍:
配置
conf := sarama.NewConfig()
conf.Producer.RequiredAcks = sarama.WaitForAll
const (
// NoResponse doesn't send any response, the TCP ACK is all you get.
NoResponse RequiredAcks = 0
// WaitForLocal waits for only the local commit to succeed before responding.
WaitForLocal RequiredAcks = 1
// WaitForAll waits for all in-sync replicas to commit before responding.
// The minimum number of in-sync replicas is configured on the broker via
// the `min.insync.replicas` configuration key.
WaitForAll RequiredAcks = -1
)
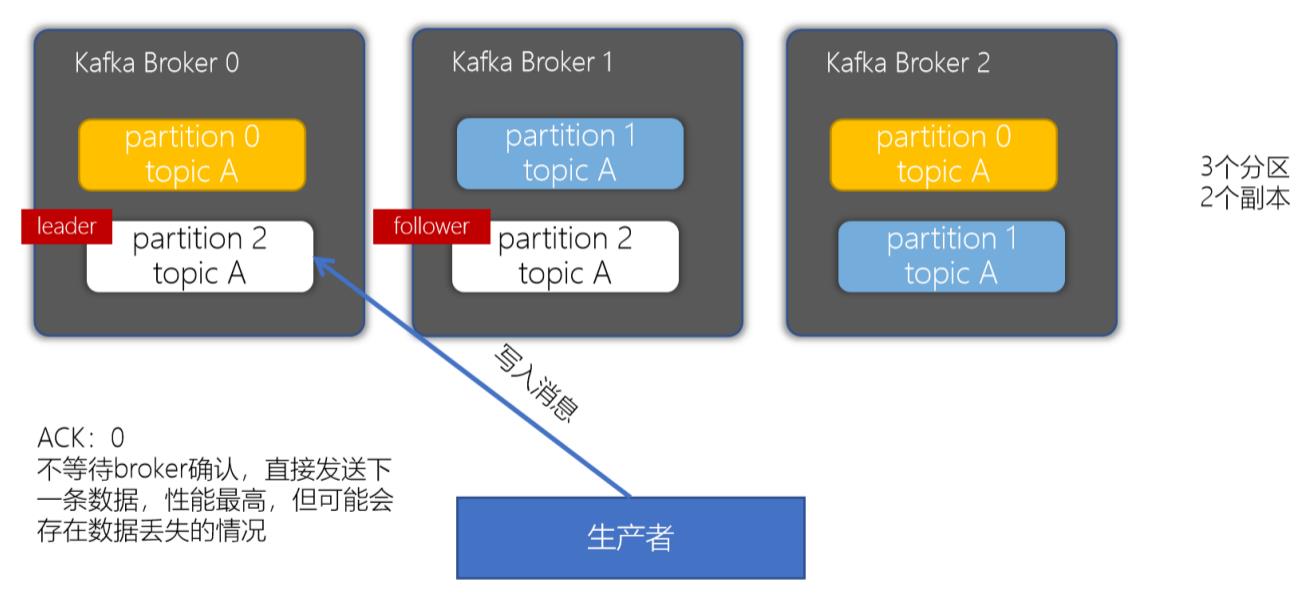
4.2 ack配置为0
4.3 ack配置为1

当生产者的ACK配置为1时, 生产者会等待leader副本确认接收后, 才会发送下一条数据, 性能中等;
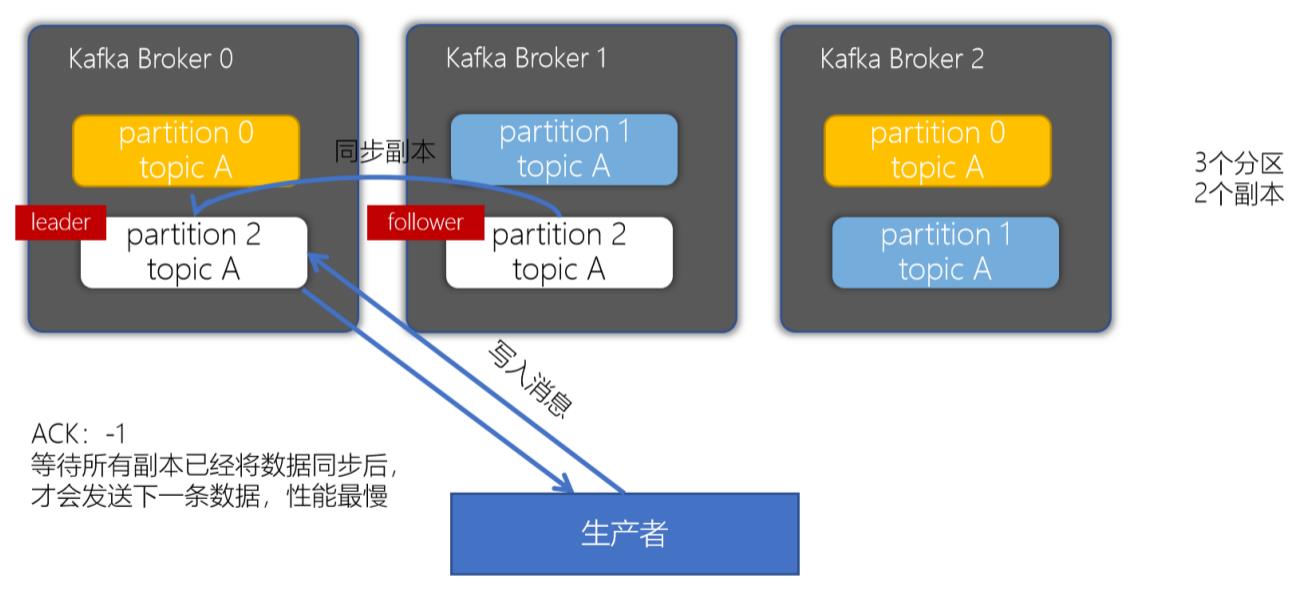
4.4 ack配置为-1或all
bin/kafka-producer-perf-test.sh --topic benchmark --num-records 5000000 --throughput -1 --record-size 1000 --producer-props bootstrap.servers=node1:9092,node2:9092,node3:9092 acks=all
| 指标 | 单分区单副本(ack=0) | 单分区单副本(ack=1) | 单分区单副本(ack=-1/all) |
|---|---|---|---|
| 吞吐量 | 16.5W/s | 9.3W/s | 7.3W/s |
| 吞吐速率 | 158.19 MB/sec | 88.78 MB/sec | 70.18 MB/sec |
| 平均延迟时间 | 192.43 ms | 346.62 ms | 438.77 ms |
| 最大延迟时间 | 670.00 ms | 1003.00 ms | 1884.00 ms |
二、高级API和低级API
以上是关于kakfa从入门到放弃: 分区和副本机制的主要内容,如果未能解决你的问题,请参考以下文章