浅谈HyperLogLog底层算法逻辑
Posted 默辨
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了浅谈HyperLogLog底层算法逻辑相关的知识,希望对你有一定的参考价值。
本文是对hyperloglog原理的梳理,整理自知乎答主张戎的回答:大数据领域的近似分析方法(一)。内容涉及高中数学的期望,大学的高等数学以及概率论。
就像文章所言,HyperLogLog是大数据基数统计中的常见方法,无论是 Redis,Spark 还是 Flink 都提供了这个功能,其目的就是在一定的误差范围内,用最小的空间复杂度来估算一个数据流的基数。
文章目录
一、基数估计法介绍
引出概念:基数估计算法
这种算法(基数估计算法)虽然精准度很高,但是使用的空间复杂度却很高。那么是否存在一些近似的方法,可以估算出数据流的基数呢?其实,在近几十年,不少的学者都提出了很多基数估算的方法,包括 LogLog,HyperLogLog,MinCount 等等
二、HyperLogLog部分
1、理论基础介绍
1、
列举基数估计算法相关的理论基础
这里借助抛硬币的实验案例,我认为这是理解该算法的关键性的第一步(第一个关键点)

其实上面的案例并不难理解,无非就是一个概率的数学逻辑,每次正面1/2,抛两次正面1/2 * 1/2…
2、
概念比较官方,你甚至可以抽象这几个点:
- ρ(x)表示第一个1出现的位置
- max ρ(x) 表示一个集合中的最大值,即ρ(x)的最大值
- M等于最大的ρ(x),元素个数为2的M次
- 此处仅含有一个桶,即几个桶就会有几个maxρ(x),此处只会有一个ρ(x)
明白相关参数的含义(这是第二个关键点)

举一个验证的案例:
集合中的数字分别为(此处的数字理解为hash结果后的数字)
针对这16个数子,可以构成一个ρ(x)集合,从上往下依次为[0, 4, 3, 3, 2, 2, 2, 2, 1, 1, 1, 1, 1, 1, 1, 1],那么就可以得出maxρ(x)的值为4,然后这个数字放在一个桶里面,即数据的个数为2的4次方,16个。
2、引入调和平均数
1、
针对第一点中只出现一个桶,而导致的误差情况,该算法采用求平均值减小误差。当然,进行均值处理也是有很多种的,该算法采用的是调和平均数。(Loglog使用的是算数平均数,HyperLoglog使用的是调和平均数)
知道这个调和平均数这个公式的含义(这是第三个关键点)

2、
此处将数据一分为2,前半部分数字表示具体的数,作用和上面第一点的案例相同,后半部分数字的长度用来表示桶的个数。以此再结合调和平均数,于是就得出了最下面的公式

3、
举例验证说明
还是上面例子,此时,将一个4位长的数字拆分为2+2。此时的:
X = X4 + X3 + X2 + X1
X = Xb+2 + Xb+1 + Xb + x1 (b = 2)
即桶的个数为2的b次,4个。在调和平均数公式中,就是m = 4。
再得出ρ(x)的最大值,我们可以得出每个桶里面的maxρ(x)都等于2,在公式的基础上,可以进行计算,如下图:

当然,这里的计算过程并没有什么实质性的作用,更像是一种别人给了你结论共识,然后你去反推验证公式的正确性。
看明白对应的对应的验证过程(这是第四个关键点)
4、
进一步推演该公式

这里的演算过程,本人已经还给了高数老师,明白意思即可,直接跳过。
3、误差修正
使用上面的算法是能够进行数字的估算,但是是存在误差的,所以针对E的值(基数的值)还需要进行一个微调

知道在调和平均数的基础上,还会根据对应的数值的大小进行误差修正(这是第五个关键点)
下面就是具体的范围说明:
1、小范围:E <= 5m / 2

2、中范围:E值不做调整
3、大范围:E > 2^32 / 30

4、Reids中的HyperLogLog
HyperLogLog是基数估算算法的其中一种体现,其他类似的算法还有LogLog、MinCount等。我是一名Java开发人员,所有接触HyperLogLog的场景为使用Redis的一种高级数据结构HyperLogLog,使用该结构可以在数据量很大的情况下,只需要使用很小的空间就能够近似的统计出所有数据的基数。可用于处理网站的日活统计。
①Redis对于一个输入的字符串,首先得到64位的hash值。
②用前14位来定位桶的位置,即桶的位个数为2^14个,16384个)。
③后面50位为伯努利过程(抛硬币的过程),每个桶有6bit,记录第一次出现1的位置count(6bit最大能表示64-1,63 > 50,满足条件),如果count > oldcount,就用count替换oldcount。
6bit(每个桶的大小) * 16384个 / 8(1B = 8bit) / 1024(B转KB) = 12KB,即这就是我们常说的,HyperLogLog所占用的内存只有12KB。
熟悉Redis五种基本数据类型底层的小伙伴应该都知道,Redis对于内存的压榨是有一手的,这在HyperLogLog中同样如此。如果比较多的计数值都是0,那么就会采用稀疏存储的结构。
对于连续多个计数值为0的桶,Redis使用的存储方式是:00xxxxxx,前缀两个0,后面6位的值加1表示有连续多少个桶的计数值为0,由于6bit最大能表示64个桶,所以Redis又设计了另一种表示方法:01xxxxxx yyyyyyyy,这样后面14bit就可以表示16384个桶了,而一个初始状态的HyperLogLog对象只需要用2个字节来存储。
如果连续的桶数都不是0,那么Redis的表示方式为1vvvvvxx,即为连续(xx+1)个桶的计数值都是(vvvvv+1)。例如,10011110表示连续3个8。这里使用5bit,最大只能表示32。因此,当某个计数值大于32时,Redis会将这个HyperLogLog对象调整为密集存储。
Redis从稀疏存储转换到密集存储的条件是:
- 任意一个计数值从 32 变成 33,因为VAL指令已经无法容纳,它能表示的计数值最大为 32
- 稀疏存储占用的总字节数超过 3000 字节,这个阈值可以通过 hll_sparse_max_bytes 参数进行调整。
三、具体案例讲解
图片来源张戎的案例:(理解了第二部门的内容,这部分就不难理解了)
该图表示,将数据分为两部分,桶占用了6位,即桶有2^6 = 64个,即下方的空格有64个
此处获取ρ(x)的方式于我们上面说到的有区别,他是从右往左开始,但是思想是一致的,该数字得出p(x) = 2,数据不断的增加,不断的增加,遇到相同的桶的位置的时候,如果新的ρ的值更大,则

将所有的大批量的数据都进行运算之后,我们可以得到这样的一张图片:
即在第一个桶的位置,对应的maxρ(x)最大值为15;
第二个桶的位置,对应的maxρ(x)最大值为10;
…
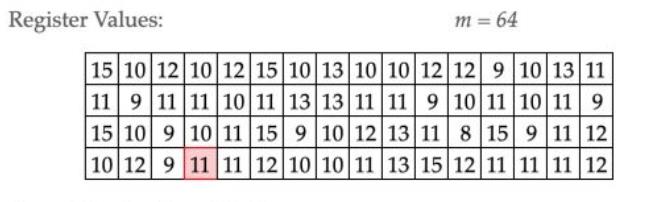
然后再借助调和平均数进行计算,最后再进行误差修正。最终得到这一批数据所代表的基数的个数。
参考阅读:
以上是关于浅谈HyperLogLog底层算法逻辑的主要内容,如果未能解决你的问题,请参考以下文章