泰坦尼克号(titanic)数据集字段解释数据导入实战
Posted Data+Science+Insight
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了泰坦尼克号(titanic)数据集字段解释数据导入实战相关的知识,希望对你有一定的参考价值。
泰坦尼克号(titanic)数据集字段解释、数据导入实战
目录
#数据字段说明
# 尽管在沉船事件中幸存下有‘一些运气’因素,但有些人比其他人更容易存活下来,比如女人,孩子和上流社会。
# “最惨的是下流社会的男人”,至少在西方社会是这样的。
#同时也看到了人道的光辉。
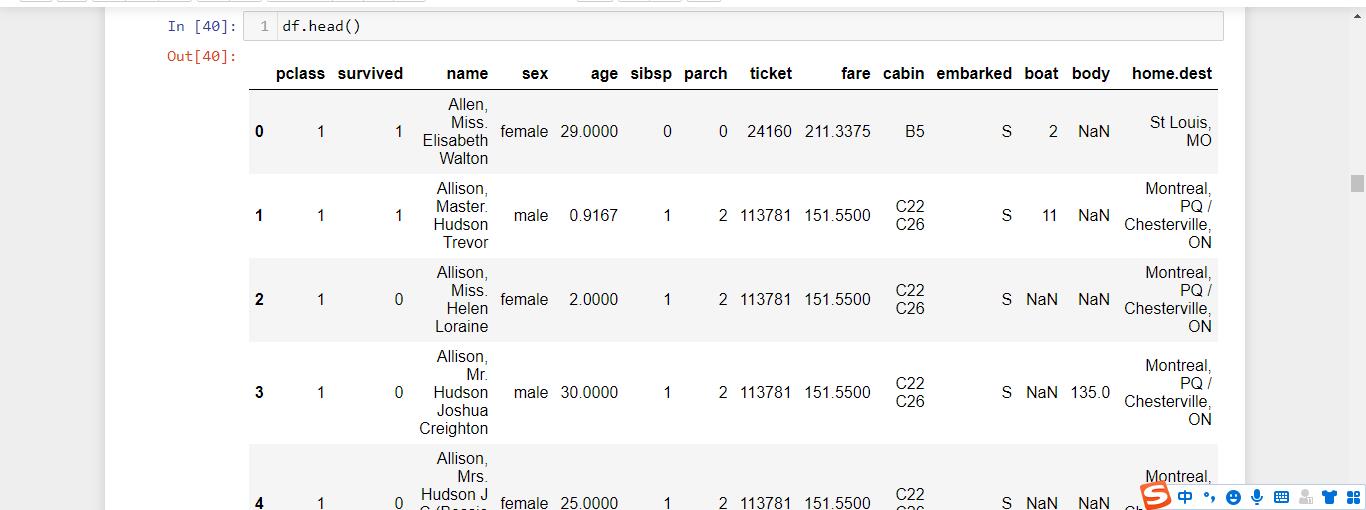
passengerid: 乘客 ID
class: 舱位等级 (1 = 1st, 2 = 2nd, 3 = 3rd)**
name: 乘客姓名
sex: 性别
age: 年龄
sibsp: 在船上的兄弟姐妹/配偶个数
parch: 在船上的父母/小孩个数
ticket: 船票信息
fare: 票价
cabin: 客舱
embarked: 登船港口 (C = Cherbourg, Q = Queenstown, S = Southampton)
survived: 变量预测为值 0 或 1(这里 1 表示幸存,0 表示遇难)
pclass: A proxy for socio-economic status (SES) 1st = Upper 2nd = Middle 3rd = Lower
age: Age is fractional if less than 1. If the age is estimated, is it in the form of xx.5
sibsp: The dataset defines family relations in this way… Sibling = brother, sister, stepbrother, stepsister Spouse = husband, wife (mistresses and fiancés were ignored)
parch: The dataset defines family relations in this way… Parent = mother, father Child = daughter, son, stepdaughter, stepson Some children travelled only with a nanny, therefore parch=0 for them.
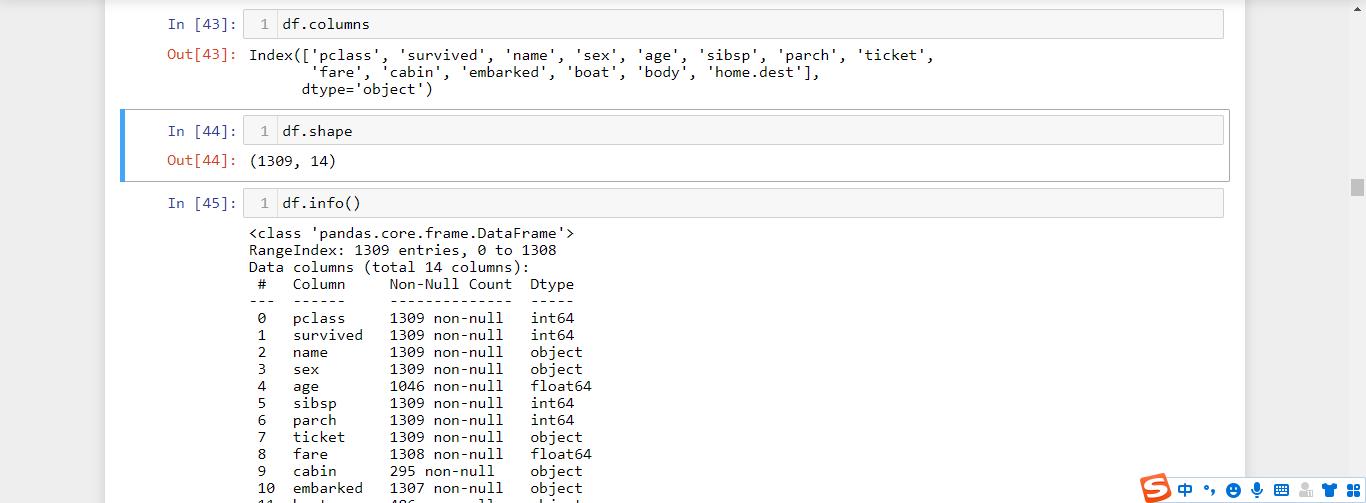
#导入数据
# df=pd.read_csv("E:\\\\projects\\\\EDA\\\\titanic.csv")
df=pd.read_excel("E:\\\\projects\\\\EDA\\\\titanic.xls")
参考:kaggle
参考:titanic
参考:泰坦尼克号数据集_Kaggle | 泰坦尼克号幸存分析(字段介绍)
以上是关于泰坦尼克号(titanic)数据集字段解释数据导入实战的主要内容,如果未能解决你的问题,请参考以下文章
大数据第一课(满分作业)——泰坦尼克号生存者预测(Titanic - Machine Learning from Disaster)
小丸子踏入python之路:python_day05(用Pandas处理泰坦尼克船员获救数据titanic_train.csv)