撸了几行骚代码,解放了双手
Posted 沉默王二
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了撸了几行骚代码,解放了双手相关的知识,希望对你有一定的参考价值。
大家好,我是二哥呀~
作为一名技术博主,经常需要把同一份 MD 文件同步到不同的博客平台,以求获得更多的曝光,从而帮助到更多的小伙伴——瞧我这“达则兼济天下”的雄心壮志。像 CSDN 和掘金这两个博客平台都有自己的外链图片解析功能。
当我把 MD 源文档复制到 CSDN 或者掘金的编辑器中,它们会自动地帮我把外链转成内链,这样我就不用再重新上传图片,也不需要配置自己的图床了,否则图片会因为防盗链的原因显示不出来。
举个例子,现在有这样一段 MD 文档,里面有一张图片。

把上面的 MD 文档复制到掘金编辑器的时候,就会出现「图片解析中…」!但会一直卡在这里,再也解析不下去了。

这是因为图片加了防盗链,掘金这么牛逼的社区在解析的时候也会失败。CSDN 的转链功能更牛逼一点,基本上可以无视防盗链。

还有一些博客平台是没有转链功能的,比如说二哥的静态小破站《Java 程序员进阶之路》。怎么办呢?我一开始的解决方案是:
- 先将图片手动一张张下载到本地
- 再将本地图片上传到 GitHub 指定的仓库
- 修改 MD 文档中的图片链接,使用 CDN 加速服务
这样就能解决问题,但是需要手动去做这些重复的动作,尤其遇到一篇文章有二三十张图片的时候就很烦。这有点丧失我作为程序员的尊严啊!
首先要解决的是图片下载的问题,可以利用爬虫技术:爬虫爬得早,局子进的早。

二、关于 Java 爬虫
Java 爬虫的类库非常多,比如说 crawler4j,我个人更喜欢 jsoup,它更轻量级。jsoup 是一款用于解析 html 的 Java 类库,提供了一套非常便捷的 API,用于提取和操作数据。
官网地址:https://jsoup.org/
jsoup 目前在 GitHub 上已经收获 9.3k+ 的 star,可以说是非常的受欢迎了。
jsoup 有以下特性:
- 可以从 URL、文件或者字符串中抓取和解析
- 可以使用 DOM 遍历或者 CSS 选择器查找和提取数据
- 可以操作 HTML 元素、属性和文本
- 可以输出整洁的 HTML
三、实战 jsoup
第一步,添加 jsoup 依赖到项目中。
<dependency>
<!-- jsoup HTML parser library @ https://jsoup.org/ -->
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.14.3</version>
</dependency>
第二步, 获取网页文档。
就拿二哥之前发表的一篇文章《二哥的小破站终于上线了,颜值贼高》来举例吧。通过以下代码就可以拿到网页文档了。
Document doc = Jsoup.connect("https://blog.csdn.net/qing_gee/article/details/122407829").get();
String title = doc.title();
Jsoup 类是 jsoup 的入口类,通过 connect 方法可以从指定链接中加载 HTML 文档(用 Document 对象来表示)。
第三步,获取图片节点。
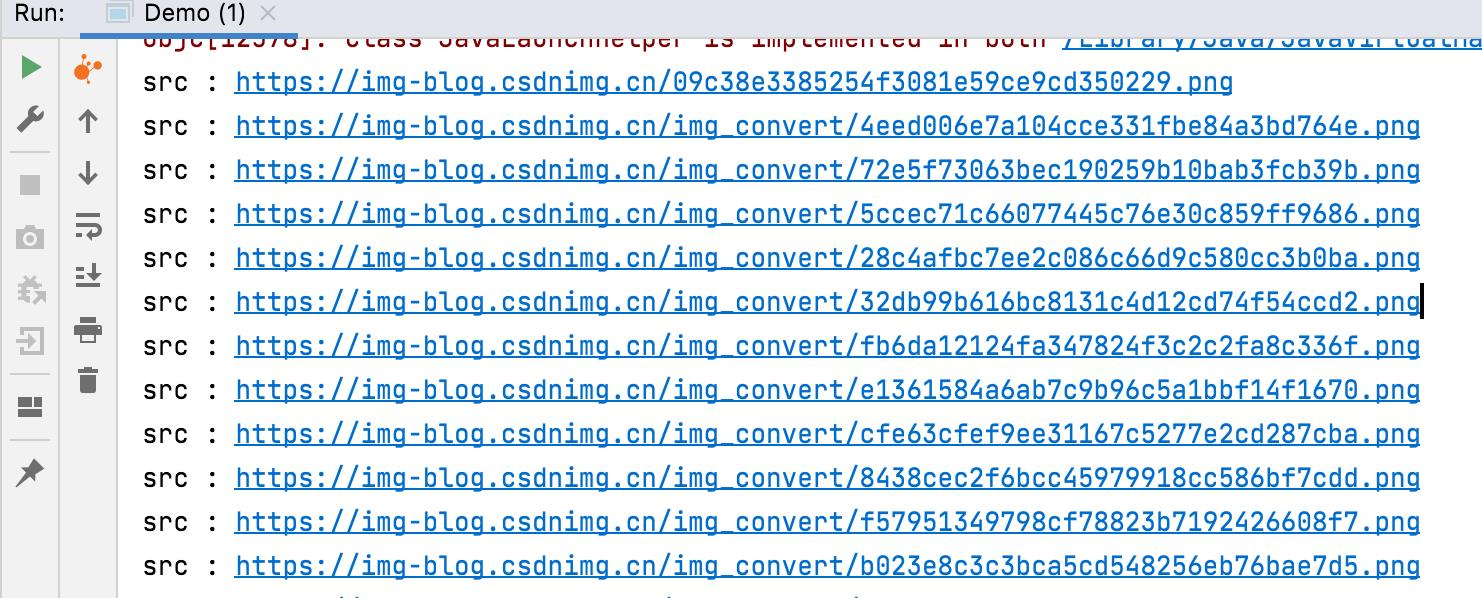
再通过以下代码可以获取文章所有的图片节点:
Elements images = doc.select(".article_content img[src~=(?i)\\\\.(png|jpe?g|gif)]");
for (Element image : images)
System.out.println("src : " + image.attr("src"));
输出结构如下所示:
四、下载图片
拿到图片的 URL 地址后,事情就好办了,可以直接通过 JDK 的原生 API 下载图片到指定文件夹。
String downloadPath = "/tobebetterjavaer-beian-";
for (Element image : images)
URL url = new URL(image.attr("src"));
InputStream inputStream = url.openStream();
OutputStream outputStream = new FileOutputStream(downloadPath + i + ".png");
byte[] buffer = new byte[2048];
int length = 0;
while ((length = inputStream.read(buffer)) != -1)
outputStream.write(buffer, 0, length);
如果想加快节奏的话,可以把上面的代码封装一下,然后开个多线程,简单点的话,可以每张图片起一个线程,速度杠杠的。
new Thread(new MyRunnable(originImgUrl, destinationImgPath)).start()
五、使用 CDN 加速图片
图片下载到本地后,接下来的工作就更简单了,读取原 MD 文档,修改图片链接,使用 CDN 进行加速。我的图床采用的是 GitHub+jsDelivr CDN 的方式,不过由于 jsDelivr 的国内节点逐渐撤离了,图片在某些网络环境下访问的时候还是有点慢,后面打算用 OSS+CDN 的方式,更靠谱一点。
读取文件可以借助一下 hutool 这款 GitHub 上开源的工具类库,省去很多繁琐的 IO 操作。
官网:https://hutool.cn/
第一步,将 hutool 添加到 pom.xml 文件中
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.7.20</version>
</dependency>
第二步,按照行读取 MD 文件,需要用到 hutool 的 FileReader 类:
FileReader fileReader = FileReader.create(new File(docPath +fileName),
Charset.forName("utf-8"));
List<String> list = fileReader.readLines();
第三步,通过正则表达式来匹配是否有需要替换的图片标签,MD 中的图片标记关键字为 ![]()。

如果匹配到,就替换为 jsDelivr CDN 链接的地址,写文件时需要用到 hutool 的FileWriter 类。
FileWriter writer = new FileWriter(docPath + fileName);
for (String line : list)
Matcher m = pattern.matcher(line);
if (m.matches())
writer.append("\\n");
else
writer.append(line+"\\n");
writer.flush();
到此为止,整个代码的编写工作就告一段落了。很简单,两个类库,几行代码就搞定了!
转换前的 MD 文件如下所示:
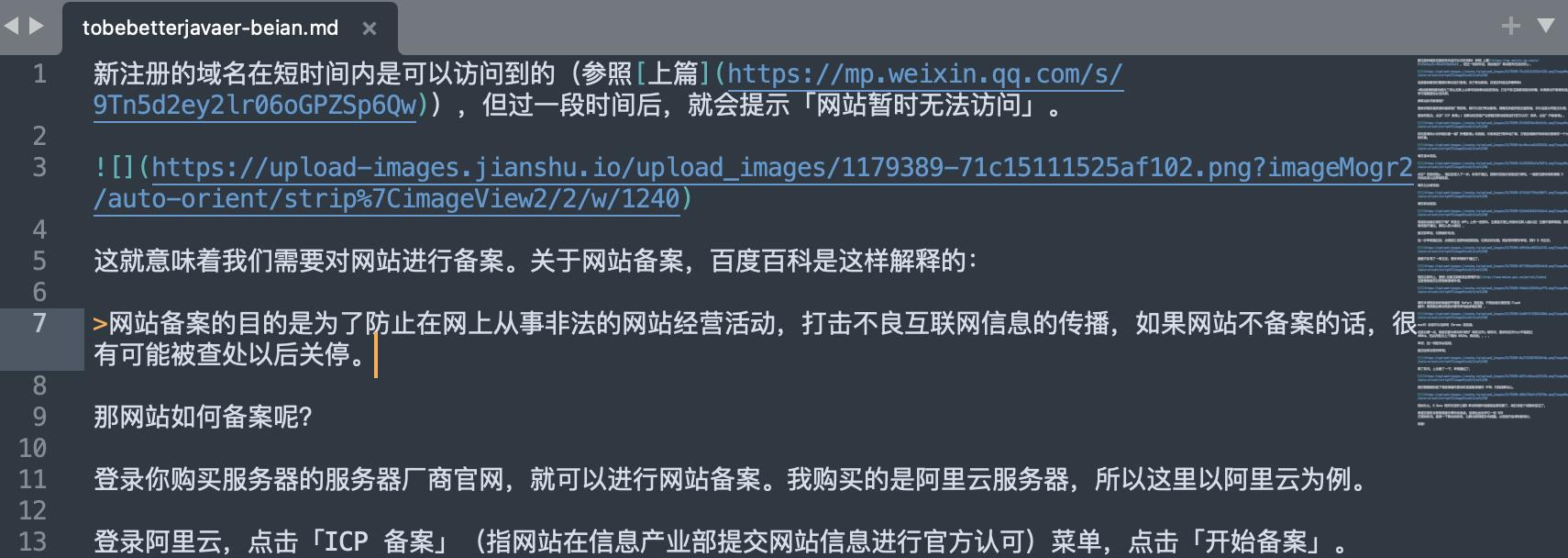
运行代码转换后,发现图片地址已经变成 jsDelivr CDN 图库了。

使用 GitHub 桌面版把图片和 MD 文档提交到 GitHub 仓库后,就可以看到图片已经加载完成可以访问了。

六、一点小心得
不得不说,懂点技术,还是非常爽的。撸了几行代码,解放了双手,可以干点正经事了(狗头)。
这不,重新把《Java 程序员进阶之路》的小破站整理排版了一下,新增了不少优质的内容。学习 Java 的小伙伴可以开卷了,有需要增加的内容也欢迎提交 issue 啊!
再次感谢各位小伙伴的厚爱,我也会一如既往地完善这个专栏,我们下期见~
以上是关于撸了几行骚代码,解放了双手的主要内容,如果未能解决你的问题,请参考以下文章