浅谈对linux性能监控命令top的理解
Posted EbowTang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了浅谈对linux性能监控命令top的理解相关的知识,希望对你有一定的参考价值。
一,top:动态查看进程变化,监控linux的系统状况。

VIRT — 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES
RES — 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA
S — 进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程
二,top命令重要的CPU负荷参数

top -c //每隔5秒显式进程的资源占用情况,并显示进程的命令行参数(默认只有进程名)
top -p 12345 -p 6789//每隔5秒显示pid是12345和pid是6789的两个进程的资源占用情况
top -d 2 -c -p 123456 //每隔2秒显示pid是12345的进程的资源使用情况,并显式该进程启动的命令行参数
shift +i,可以切换cpu的显示方式为经典百分比(不在显示200%的利用率数据)
三, 关于load average负荷参数含义

一句话而言之:
1,系统平均负载是指在特定时间间隔内运行队列中的平均进程数(即为CPU任务数)。
2,系统平均负载高并不代表服务器负荷高,还需要结合CPU实际利用率来评估
下图是load average超高的案例,就是因为该段时间内服务器CPU运行的进程数过多导致(但是服务器CPU实际利用率并不高):下图load average高的原因是smbd进程(过多客户端访问服务器上的共享目录)过多造成
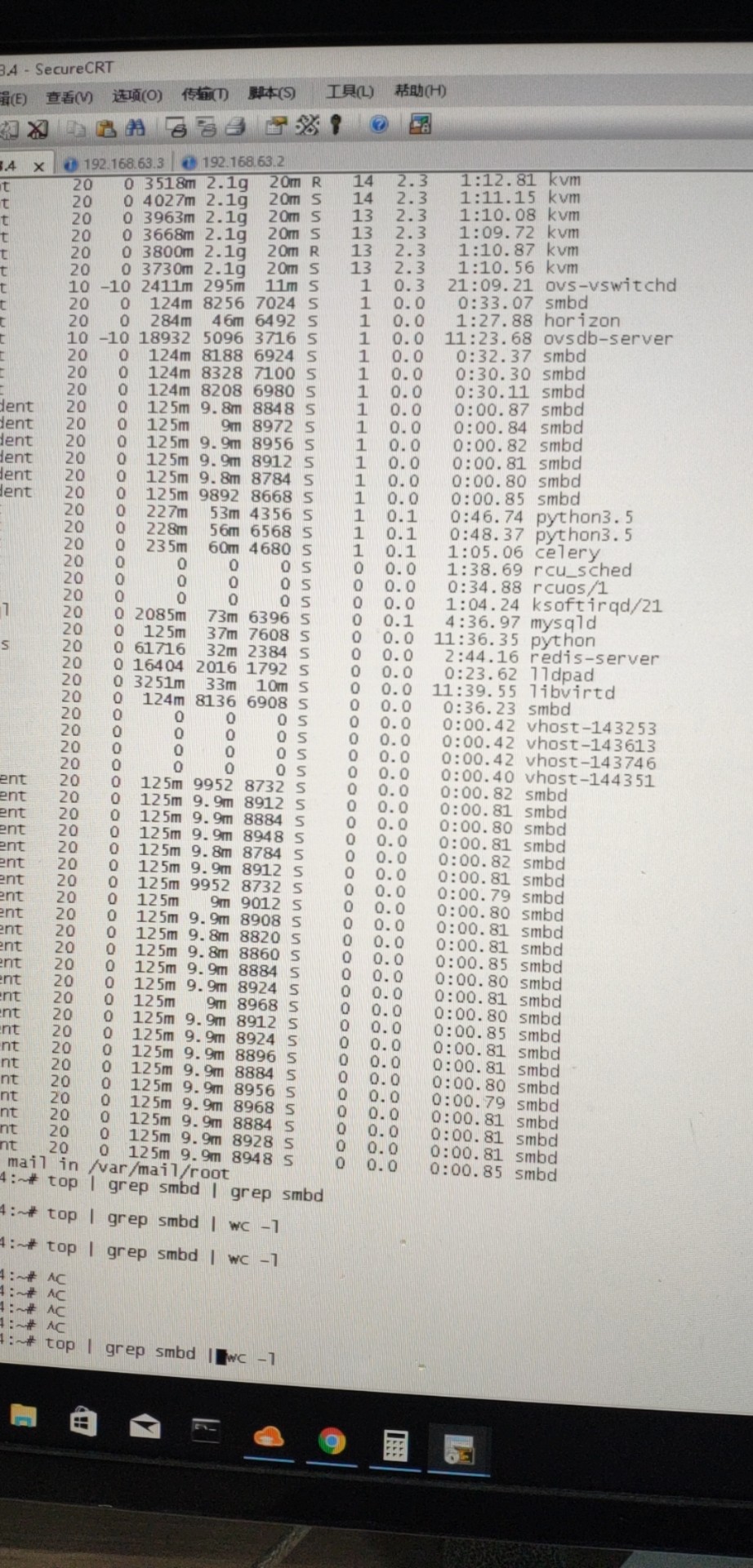
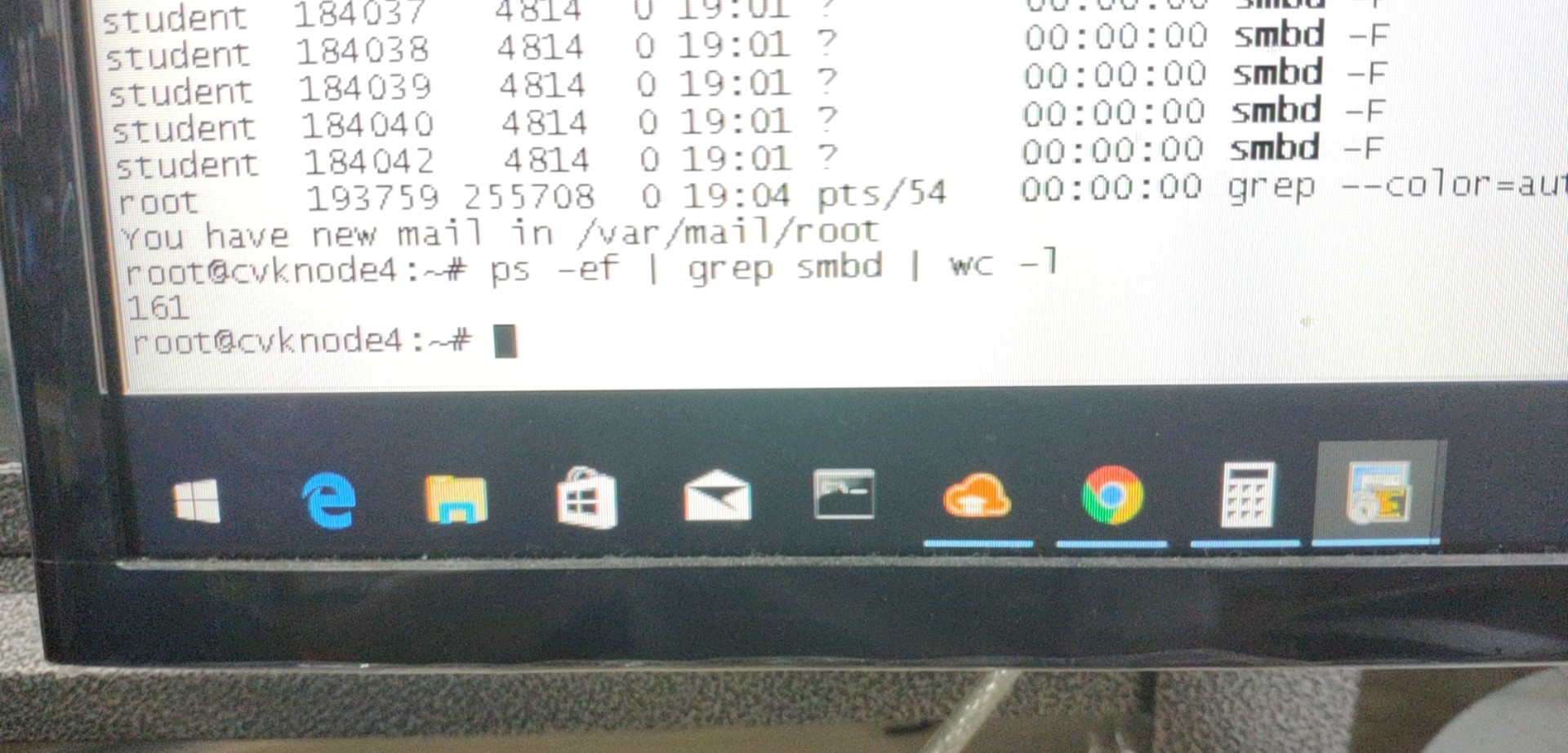
以上是关于浅谈对linux性能监控命令top的理解的主要内容,如果未能解决你的问题,请参考以下文章