五-上, Spark RDD 概述,五大属性,执行原理
Posted 菜菜的大数据开发之路
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了五-上, Spark RDD 概述,五大属性,执行原理相关的知识,希望对你有一定的参考价值。
五, Spark 核心编程
5.0 一个简单的分布式计算程序
在了解了分布式计算大概是个什么情况后, 我们来学习Spark
Spark计算框架为了能够进行高并发和高吞吐的数据处理, 封装了三大数据结构, 用于处理不同的应用场景,分别是:
- RDD: 弹性分布式数据集
- 累加器: 分布式共享只写变量
- 广播变量: 分布式共享只读变量
数据结构: 计算机存储和组织数据的方式
5.1 RDD (数据和逻辑, 最小的计算单元)
RDD: 代表着不可变的, 可以分区和并行计算的元素集合;
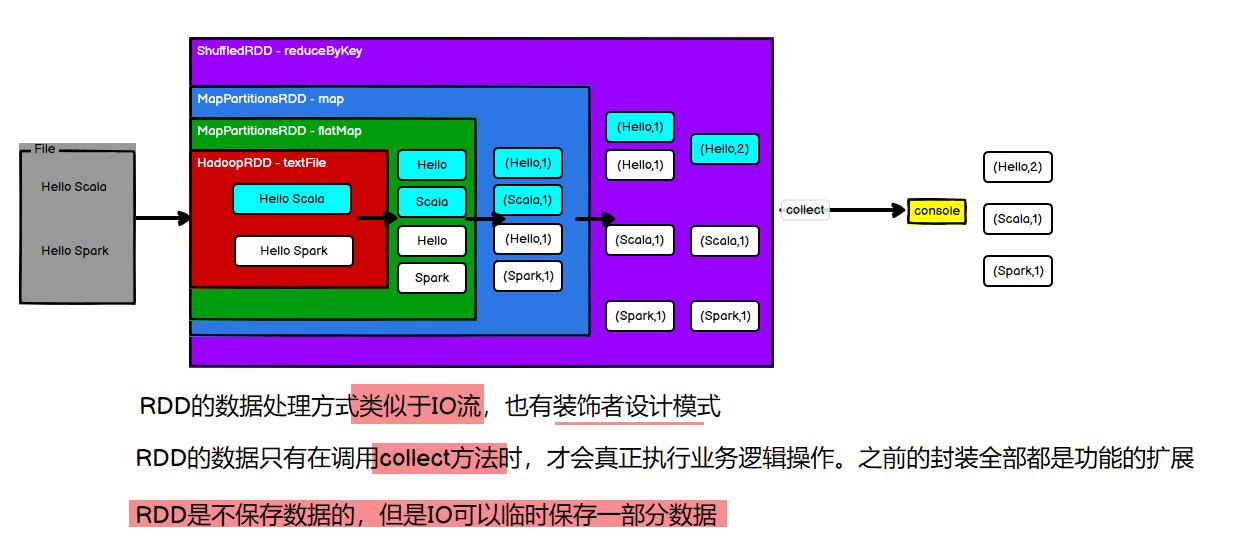
拿前篇文章中的wordcount为例, Spark中对数据的不同处理(在这里数据被指代为一个一个的RDD)是通过一层又一层的包装来实现的, 如何包装? 就是层层递进的进行传参;
比如, 我要在IO流中使用包装类去读取字节流, 字节流也需要文件对象file的传参, 所以可以写成下面的这种形式: (不理解的话可以先看看IO流那篇文章:点我)
//new BufferedInputStream(new FileInputStream(new File(path, 是否是追加操作), 字符集))
File file = new File(path);
FileInputStream fis = new FileInputStream(file);
BufferedInputStream bis = new BufferedStream(fis);
5.1.1 什么是RDD
- RDD(Resilient Distributed DataSet) 叫做弹性分布式数据集, 是Spark底层的分布式存储的数据结构, 可以说;
- 在代码中它代表着
弹性的,不可变的,可分布,里面的元素可并行计算的集合;
| 特性 | 解释 |
|---|---|
| 弹性 | 存储的弹性(内存与磁盘自动切换); 容错的弹性(数据丢失自动恢复); 计算的弹性(计算出错重试机制); 分片的弹性(根据需要重新分片) |
| 分布式 | 数据存储在大数据集群不同节点上 |
| 数据集 | RDD封装了计算逻辑, 不保存数据 |
| 数据抽象 | RDD是一个抽象类, 需要子类具体实现 |
| 不可变 | RDD 封装了计算逻辑,是不可以改变的,想要改变,只能产生新的 RDD,在新的 RDD 里面封装计算逻辑 |
| 可分区, 并行计算 | RDD 内部的数据集合在逻辑上和物理上被划分成多个小子集合,这些集合就是分区, 是并行计算的一个计算单元 |
5.1.2 RDD的五大核心属性
* Internally, each RDD is characterized by five main properties:
*
* - A list of partitions
* - A function for computing each split
* - A list of dependencies on other RDDs
* - Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
* - Optionally, a list of preferred locations to compute each split on (e.g. block locations for
* an HDFS file)
*
* All of the scheduling and execution in Spark is done based on these methods, allowing each RDD
1. A list of partitions (一个分区列表)
一个分区列表, 这里表示
一个RDD很多分区, 每一个分区内部是包含了该RDD的部分数据, Spark中任务是以Task线程的方式运行, 一个分区就对应一个Task线程, 分区列表是实现分布式并行计算的重要属性;
用户可以在创建RDD时指定RDD的分区个数, 如果没有指定, 那么就会采用默认值.
- rdd= sparkContext.textFile("/words.txt", 指定partitions)

分区数的默认值的计算公式如下:
- RDD的分区数 = max(文件的block个数, defaultMinPartitions)
- 通过Spark Context读取HDFS上的文件来计算分区数
2. A function for computing each split (作用分区中的函数)
一个计算每个分区的函数,这里表示Spark中RDD的计算是以分区为单位的,每个RDD都会实现compute计算函数以达到这个目的.
3. A list of dependencies on other RDDs (对其他RDD的依赖关系)
一个RDD会依赖于其他多个RDD, 这里涉及到RDD与RDD之间的依赖关系,
Spark 任务的容错机制就是根据这个特性(血统)而来;
- RDD 是计算模型的封装,当需求中需要将多个计算模型进行组合时,就需要将多个 RDD 建立依赖关系;
//rdd2依赖于rdd1,而rdd3依赖于rdd2
//rdd6依赖于rdd4、rdd5
val rdd1:RDD[String]=sc.textFile("/words.txt")
val rdd2:RDD[String]=rdd1.flatMap(x=>x.split(" "))
val rdd3:RDD[(String,Int)]=rdd2.Map(x=>(x,1))
val rdd6=rdd4.join(rdd5)
4. Optionally, a Partioner for key-value RDDs (针对k-v的分区器)
当数据为 KV 类型数据时,可以通过设定分区器(可选)自定义数据的分区

5. Optionally, a list of preferred locations to compute each split on (数据本地性)
一个列表,存储每个Partition的优先位置(可选项),这里涉及到数据的本地性,数据块位置最优。
- spark任务在调度的时候会优先考虑存有数据的节点开启计算任务,减少数据的网络传输,提升计算效率
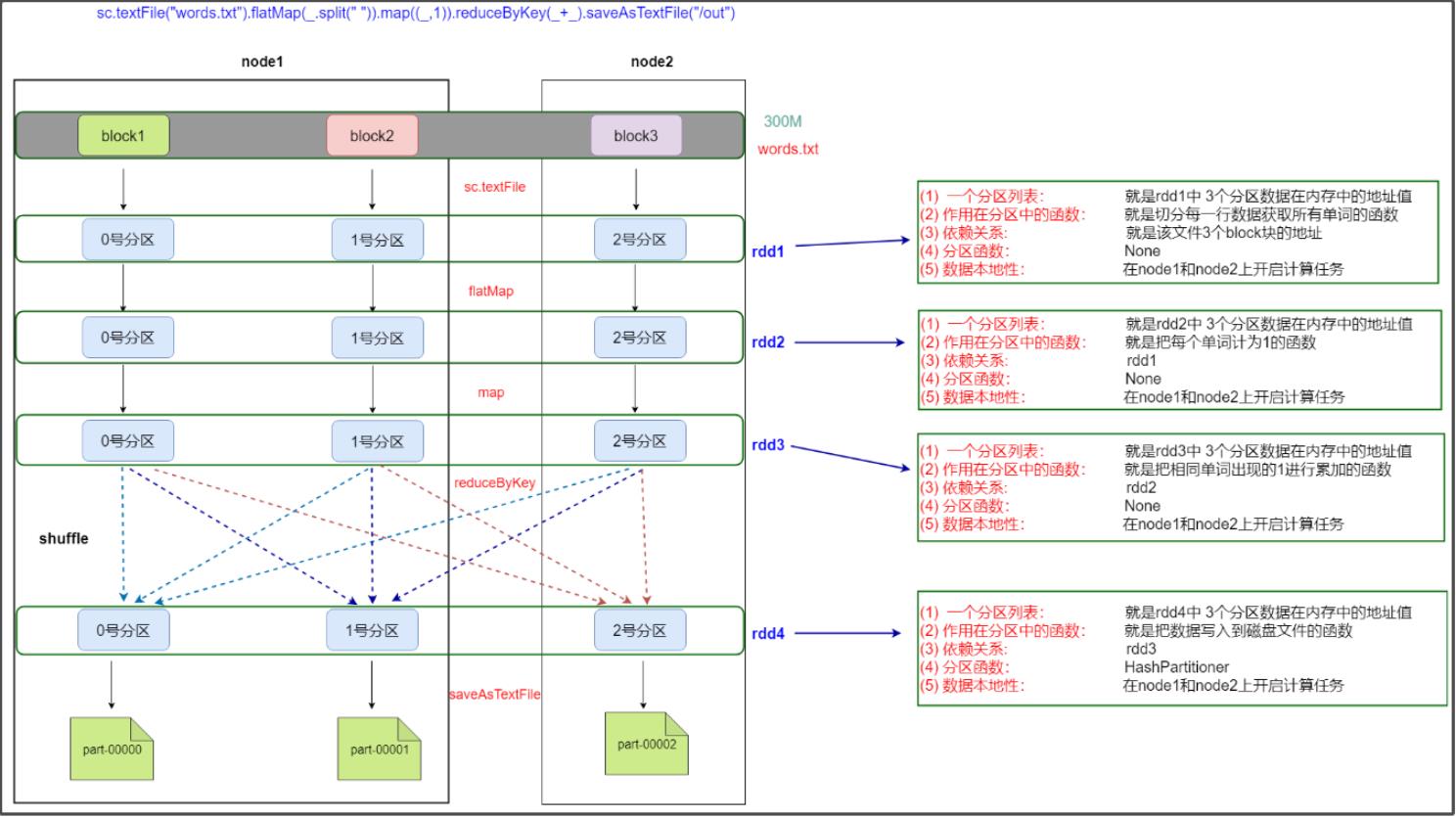
5.1.3 通过WordCount示例理解五大属性
[需求]
HDFS上有一个大小为300M的文件,通过spark实现文件单词统计,最后把结果数据保存到HDFS上
[凝练后的代码]
sc.textFile("/words.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).saveAsTextFile("/out")
[流程]
5.1.4 执行原理
- 从计算的角度来讲,数据处理过程中需要计算资源(内存 & CPU)和计算模型(逻辑)。执行时,需要将计算资源和计算模型进行协调和整合。
- Spark 框架在执行时,先申请资源,然后将应用程序的数据处理逻辑分解成一个一个的计算任务。然后将任务发到已经分配资源的计算节点上, 按照指定的计算模型进行数据计算。最后得到计算结果。
- RDD 是 Spark 框架中用于数据处理的核心模型,接下来我们看看,在 Yarn 环境中,RDD的工作原理:
- 启动 Yarn 集群环境
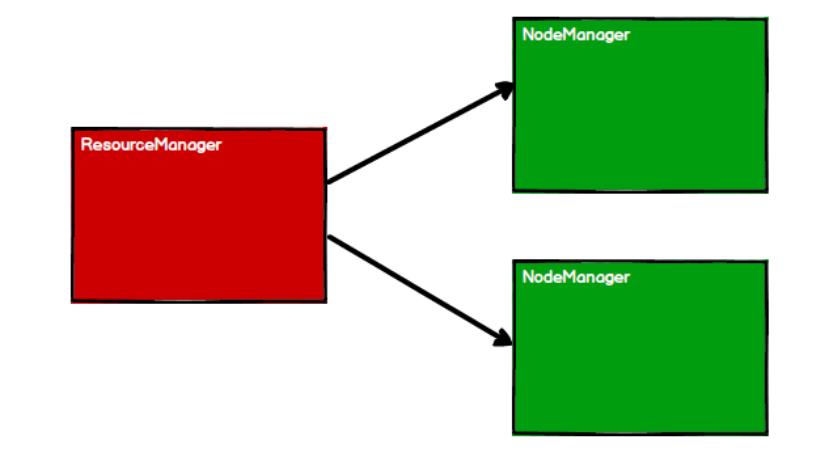
- Spark 通过申请资源创建
调度节点和计算节点
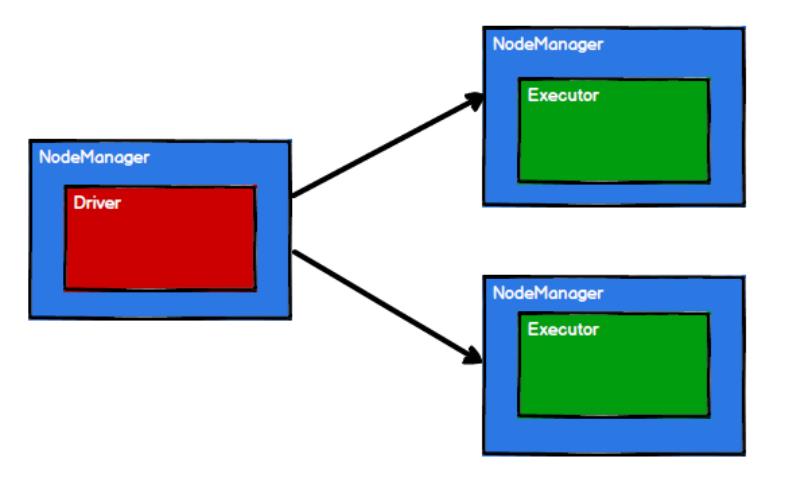
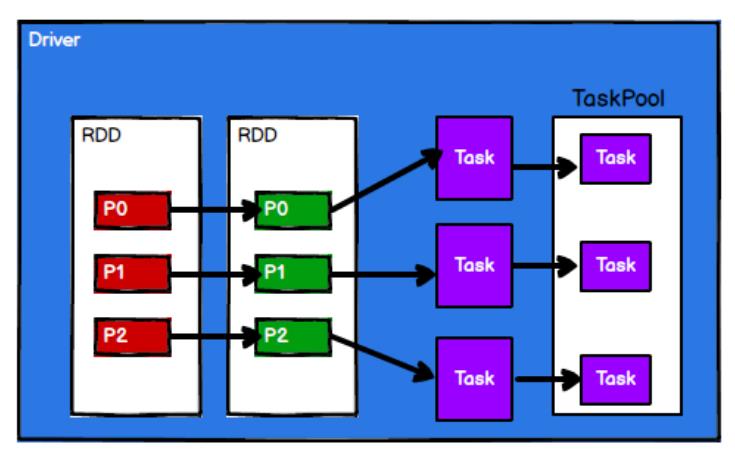
- Spark 框架根据需求将计算逻辑按照分区划分成不同的任务
- 调度节点将任务根据计算节点状态发送到对应的计算节点进行计算
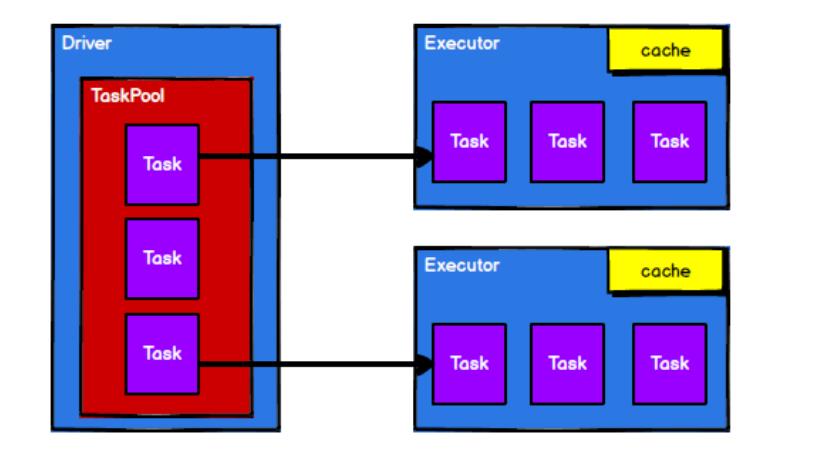
从以上流程可以看出 RDD 在整个流程中主要用于
将逻辑进行封装,并生成 Task 发送给 Executor 节点执行计算
- 参考文章: https://www.cnblogs.com/jimmy888/p/13551699.html
以上是关于五-上, Spark RDD 概述,五大属性,执行原理的主要内容,如果未能解决你的问题,请参考以下文章