好玩的ES---第一篇之安装和基本CRUD
Posted 大忽悠爱忽悠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了好玩的ES---第一篇之安装和基本CRUD相关的知识,希望对你有一定的参考价值。
好玩的ES---第一篇之安装和基本CRUD
全文检索
全文检索是计算机程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置。当用户查询时根据建立的索引查找,类似于通过字典的检索字表查字的过程。
索: 建立索引 文本---->切分 —> 词 文章出现过 出现多少次
检索: 查询 关键词—> 索引中–> 符合条件文章 相关度排序
全文检索(Full-Text Retrieval)以文本作为检索对象,找出含有指定词汇的文本。全面、准确和快速是衡量全文检索系统的关键指标。
只处理文本、不处理语义搜索时英文不区分大小写结果列表有相关度排序
简介
什么是ElasticSearch
ElasticSearch 简称 ES ,是基于Apache Lucene构建的开源搜索引擎,是当前最流行的企业级搜索引擎。Lucene本身就可以被认为迄今为止性能最好的一款开源搜索引擎工具包,但是lucene的API相对复杂,需要深厚的搜索理论。很难集成到实际的应用中去。ES是采用java语言编写,提供了简单易用的RestFul API,开发者可以使用其简单的RestFul API,开发相关的搜索功能,从而避免lucene的复杂性。
ElasticSearch诞生
多年前,一个叫做Shay Banon的刚结婚不久的失业开发者,由于妻子要去伦敦学习厨师,他便跟着也去了。在他找工作的过程中,为了给妻子构建一个食谱的搜索引擎,他开始构建一个早期版本的Lucene。
直接基于Lucene工作会比较困难,所以Shay开始抽象Lucene代码以便Java程序员可以在应用中添加搜索功能。他发布了他的第一个开源项目,叫做“Compass”。
后来Shay找到一份工作,这份工作处在高性能和内存数据网格的分布式环境中,因此高性能的、实时的、分布式的搜索引擎也是理所当然需要的。然后他决定重写Compass库使其成为一个独立的服务叫做Elasticsearch。
第一个公开版本出现在2010年2月,在那之后Elasticsearch已经成为Github上最受欢迎的项目之一,代码贡献者超过300人。一家主营Elasticsearch的公司就此成立,他们一边提供商业支持一边开发新功能,不过Elasticsearch将永远开源且对所有人可用。
Shay的妻子依旧等待着她的食谱搜索……
目前国内大厂几乎无一不用Elasticsearch,阿里,腾讯,京东,美团 等等 …
安装
- 传统方式安装 下载安装包—> 平台 window macos linux(ubuntu)
- Docker 方式安装 推荐
传统方式安装
# 0.环境准备
- centos7.x+、ubuntu、windows、macos
- 安装jdk11.0+ 并配置环境变量 jdk8
# 1.下载ES
- https://www.elastic.co/cn/start

# 2.ES为了安全不允许使用root用户启动

# 添加用户名
$ useradd chenyn
# 修改密码
$ passwd chenyn
# 普通用户登录
如果想要普通用户可以使用sudo命令,乌邦图系统需要作出下面的修改:
修改/etc/sudoers文件,进入超级用户,因为没有写权限,所以要先把写权限加上
chmod u+w /etc/sudoers
编辑/etc/sudoers文件,找到这一 行
root ALL=(ALL:ALL) ALL
在起下面添加
xxx ALL=(ALL:ALL) ALL(这里的xxx是你的用户名)
最后恢复没有写权限模式,撤销文件的写权限
chmod u-w /etc/sudoers
这样xxx用户可以采用sudo su切换到root用户了
# 3.解压缩ES安装包
$ tar -zxvf elasticsearch-7.14.0-linux-x86_64.tar.gz
$ ll
总用量 650168
drwxr-xr-x. 10 chenyn chenyn 167 8月 16 11:07 elasticsearch-7.14.0
# 4.查看ES解压包中目录结构
[chenyn@localhost elasticsearch-7.14.0]$ ll
- bin 启动ES服务脚本目录
- config ES配置文件的目录
- data ES的数据存放目录
- jdk ES提供需要指定的jdk目录
- lib ES依赖第三方库的目录
- logs ES的日志目录
- modules 模块的目录
- plugins 插件目录

# 5.启动ES服务
[chenyn@localhost ~]$ ./elasticsearch-7.14.0/bin/elasticsearch
./elasticsearch-7.14.0/bin/elasticsearch -d : -d表示是后台启动

- 这个错误时系统jdk版本与es要求jdk版本不一致,es默认需要jdk11以上版本,当前系统使用的jdk8,需要从新安装jdk11才行!
- 解决方案:
1.安装jdk11+ 配置环境变量、
2.ES包中jdk目录就是es需要jdk,只需要将这个目录配置到ES_JAVA_HOME环境变即可、
如果是普通用户没有操作当前文件权限,需要给其权限
sudo chmod 755 文件名
es自带了jdk11,在jdk目录下面
# 6.配置环境变量
$ vim /etc/profile
- export ES_JAVA_HOME=指定为ES安装目录中jdk目录
- source /etc/profile

vim /etc/environment ##打开这个这个文件
##打开之后把光标移动到文件的末尾,进行添加下面的命令:
PATH="/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games"
export ES_JAVA_HOME=/dhy/es/elasticsearch-7.14.0/jdk
刷新,使环境变量马上生效
source /etc/profile

如果出现下面这个问题:

es要求非root用户登录,但是放置jdk时忽略了这一点,给放在了root目录下,一直报错could not find java in JAVA_HOME or bundled at /root/jdk-11/bin/java
sudo chown -R dhy:dhy es
将当前用户变成es文件拥有者
# 7.从新启动ES服务

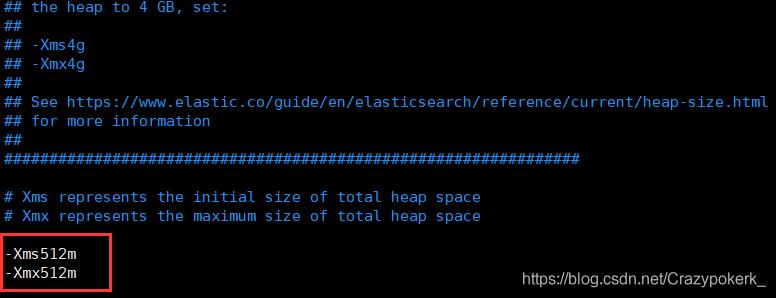
如果启动显示Killed,是因为es中的jvm配置文件中,配置了1g的堆大小,如果没有足够空间分配,es就启动不起来
解决办法
更改 jvm.options 文件:

改为合适的大小即可:
# 8.ES启动默认监听9200端口,访问9200
$ curl http://localhost:9200

开启远程访问
# 1.默认ES无法使用主机ip进行远程连接,需要开启远程连接权限
- 修改ES安装包中config/elasticsearch.yml配置文件
$ vim elasticsearch.yml
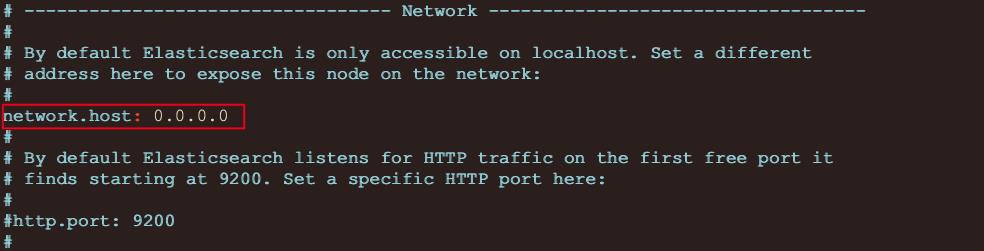
# 2.重新启动ES服务
- ./elasticsearch
# 错误主要是因为es默认是以集群方式启动
- 启动出现如下错误:
`bootstrap check failure [1] of [4]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65535]
`bootstrap check failure [2] of [4]: max number of threads [3802] for user [chenyn] is too low, increase to at least [4096]
`bootstrap check failure [3] of [4]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
`bootstrap check failure [4] of [4]: the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers

看你的系统报了哪几个错误,就修改对应的几个就可以了
# 3.解决错误-1
$ vim /etc/security/limits.conf
# 在最后面追加下面内容
* soft nofile 65536
* hard nofile 65536
* soft nproc 4096
* hard nproc 4096
# 退出重新登录检测配置是否生效:
ulimit -Hn
ulimit -Sn
ulimit -Hu
ulimit -Su
# 3.解决错误-2
#进入limits.d目录下修改配置文件。
$ vim /etc/security/limits.d/20-nproc.conf
# 修改为
启动ES用户名 soft nproc 4096

乌邦图系统只需要解决三和四错误即可
# 3.解决错误-3
# 编辑sysctl.conf文件
$ vim /etc/sysctl.conf
vm.max_map_count=655360 #centos7 系统
vm.max_map_count=262144 #ubuntu 系统
# 执行以下命令生效:
$ sysctl -p
# 3.解决错误-4
# 编辑elasticsearch.yml配置文件
#因为es默认以集群方式启动,所以我们需要先修改为单机节点启动
$ vim conf/elasticsearch.yml
cluster.initial_master_nodes: ["node-1"]

# 4.重启启动ES服务,并通过浏览器访问
"name": "localhost.localdomain",
"cluster_name": "elasticsearch",
"cluster_uuid": "OWh3xLYwR-6lZ_fQNhVY3A",
"version":
"number": "7.14.0",
"build_flavor": "default",
"build_type": "tar",
"build_hash": "dd5a0a2acaa2045ff9624f3729fc8a6f40835aa1",
"build_date": "2021-07-29T20:49:32.864135063Z",
"build_snapshot": false,
"lucene_version": "8.9.0",
"minimum_wire_compatibility_version": "6.8.0",
"minimum_index_compatibility_version": "6.0.0-beta1"
,
"tagline": "You Know, for Search"
Docker方式安装
# 1.获取镜像
- docker pull elasticsearch:7.14.0
# 2.运行es---单机模式启动--指定堆大小,防止因为内存不足,一启动就被关闭
- docker run -d -p 9200:9200 -p 9300:9300 -e ES_JAVA_OPTS="-Xms512m -Xmx512m" --name elasticsearch -e "discovery.type=single-node" elasticsearch:7.14.0
# 3.访问ES
- http://10.15.0.5:9200/
docker启动的es默认开启了远程访问
Kibana
简介
Kibana Navicat是一个针对Elasticsearch mysql的开源分析及可视化平台,使用Kibana可以查询、查看并与存储在ES索引的数据进行交互操作,使用Kibana能执行高级的数据分析,并能以图表、表格和地图的形式查看数据。
参考Mysql和Navicat的关系
安装
传统方式安装
# 1. 下载Kibana
- https://www.elastic.co/downloads/kibana
# 2. 安装下载的kibana
- $ tar -zxvf kibana-7.14.0-linux-x86_64.tar.gz
# 3. 编辑kibana配置文件
- $ vim /Kibana 安装目录中 config 目录/kibana/kibana.yml
# 4. 修改如下配置
- server.host: "0.0.0.0" # 开启kibana远程访问
- elasticsearch.hosts: ["http://localhost:9200"] #ES服务器地址
# 5. 启动kibana
- ./bin/kibana
# 6. 访问kibana的web界面
- http://10.15.0.5:5601/ #kibana默认端口为5601
Docker方式安装
# 1.获取镜像
- docker pull kibana:7.14.0
# 2.运行kibana
- docker run -d --name kibana -p 5601:5601 kibana:7.14.0
如果我们用docker方式启动kibana,需要先启动docker,然后进入启动的容器内部,修改配置文件,开启远程服务,并指定es服务的默认端口号
docker exec -it kibana bash
# 3.进入容器连接到ES,重启kibana容器,访问
- http://10.15.0.3:5601
# 4.基于数据卷加载配置文件方式运行
- a.从容器复制kibana配置文件出来
- b.修改配置文件为对应ES服务器地址
- c.通过数据卷加载配置文件方式启动
ocker run -d -v /dhy/es:/config/kibana.yml --name kibana -p 5601:5601 kibana:7.14.0
配置文件:
## Default Kibana configuration for docker target
server.host: "0"
server.shutdownTimeout: "5s"
elasticsearch.hosts: [ "http://110.40.155.17:9200" ]
monitoring.ui.container.elasticsearch.enabled: true
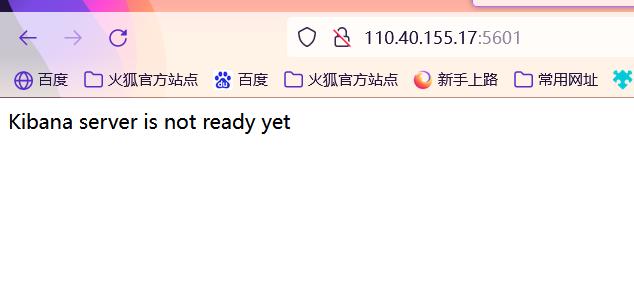
出现这个问题:
- 检查版本是否一致
- 配置文件中es的地址是否使用的是localhost,改为服务器真实ip
compose方式安装
version: "3.8"
volumes:
data:
config:
plugin:
networks:
es:
services:
#服务名
elasticsearch:
image: elasticsearch:7.14.0
ports:
- "9200:9200"
- "9300:9300"
#网络
networks:
- "es"
environment:
- "discovery.type=single-node"
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
volumes:
- data:/usr/share/elasticsearch/data
- config:/usr/share/elasticsearch/config
- plugin:/usr/share/elasticsearch/plugins
kibana:
image: kibana:7.14.0
ports:
- "5601:5601"
networks:
- "es"
volumes:
- ./kibana.yml:/usr/share/kibana/config/kibana.yml
# kibana配置文件 连接到ES
server.host: "0"
server.shutdownTimeout: "5s"
#es服务器地址,通过服务名访问,因为两者处于同一网络下面,可以通过服务名访问
elasticsearch.hosts: [ "http://elasticsearch:9200" ]
monitoring.ui.container.elasticsearch.enabled: true
核心概念
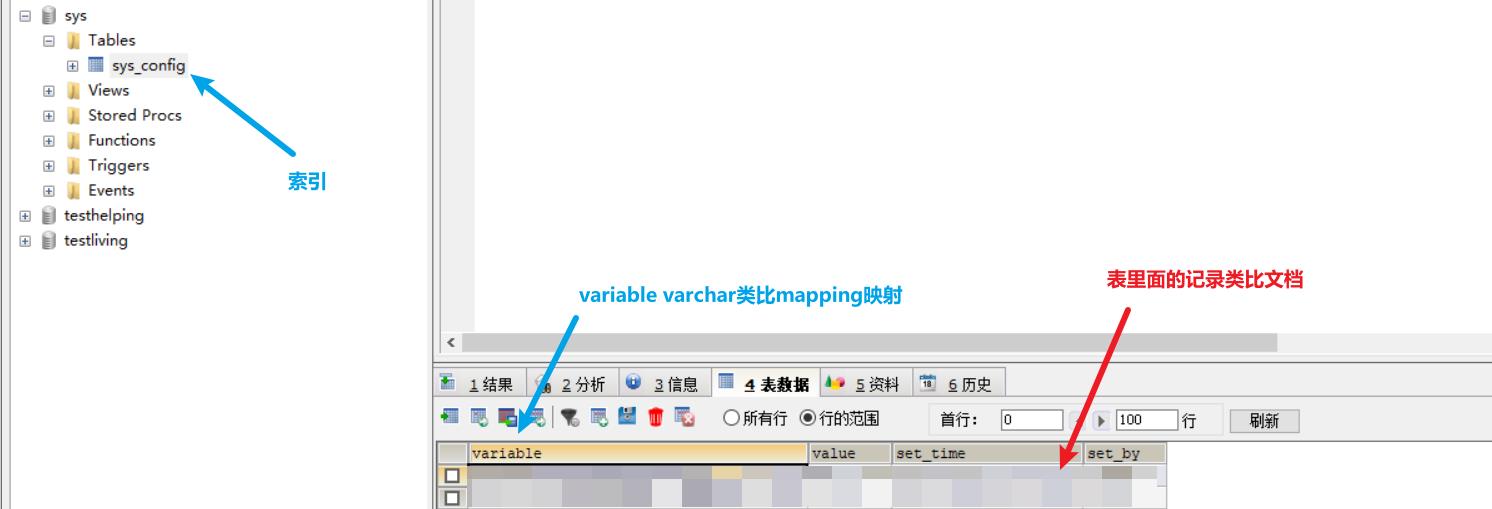
索引
一个索引就是一个拥有几分相似特征的文档的集合。比如说,你可以有一个商品数据的索引,一个订单数据的索引,还有一个用户数据的索引。一个索引由一个名字来标识(必须全部是小写字母的),并且当我们要对这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。
映射
映射是定义一个文档和它所包含的字段如何被存储和索引的过程。在默认配置下,ES可以根据插入的数据自动地创建mapping,也可以手动创建mapping。 mapping中主要包括字段名、字段类型等
文档
文档是索引中存储的一条条数据。一条文档是一个可被索引的最小单元。ES中的文档采用了轻量级的JSON格式数据来表示。
类比法:
基本操作
索引
创建
# 1.创建索引
- PUT /索引名 ====> PUT /products
- 注意:
1.ES中索引健康转态 red(索引不可用) 、yellow(索引可用,存在风险)、green(健康)
2.默认ES在创建索引时会为索引创建1个备份索引和一个primary索引
# 2.创建索引 进行索引分片配置
- PUT /products
"settings":
"number_of_shards": 1, #指定主分片的数量
"number_of_replicas": 0 #指定副本分片的数量

查询
# 查询索引
- GET /_cat/indices?v

删除
# 3.删除索引
- DELETE /索引名 =====> DELETE /products
- DELETE /* `*代表通配符,代表所有索引`

映射
创建
字符串类型: keyword 关键字 关键词 、text 一段文本
数字类型:integer long
小数类型:float double
布尔类型:boolean
日期类型:date
# 1.创建索引&映射
PUT /products
"settings":
"number_of_shards": 1,
"number_of_replicas": 0
,
"mappings":
"properties":
"title":
"type": "keyword"
,
"price":
"type": "double"
,
"created_at":
"type": "date"
,
"description":
"type": "text"

说明: ES中支持字段类型非常丰富,如:text、keyword、integer、long、ip 等。更多参见https://www.elastic.co/guide/en/elasticsearch/reference/7.15/mapping-types.html
查询
# 1.查看某个索引的映射
- GET /索引名/_mapping =====> GET /products/_mapping

文档
添加文档
POST /products/_doc/1 #指定文档id
"title":"iphone13",
"price":8999.99,
"created_at":"2021-09-15",
"description":"iPhone 13屏幕采用6.1英寸OLED屏幕。"
POST /products/_doc/ #自动生成文档id
"title":"iphone14",
"price":8999.99,
"created_at":"2021-09-15",
"description":"iPhone 13屏幕采用6.8英寸OLED屏幕"
"_index" : "products",
"_type" : "_doc",
"_id" : "sjfYnXwBVVbJgt24PlVU",
"_version" : 1,
"result" : "created",
"_shards" :
"total" : 1,
"successful" : 1,
"failed" : 0
,
"_seq_no" : 3,
"_primary_term" : 1
查询文档
GET /products/_doc/1
"_index" : "products",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 1,
"found" : true,
"_source" :
"title" : "iphone13",
"price" : 8999.99,
"created_at" : "2021-09-15",
"description" : "iPhone 13屏幕采用6.1英寸OLED屏幕"
删除文档
DELETE /products/_doc/1
"_index" : "products",
"_type" : "_doc",
"_id" : "1",
"_version" : 2,
"result" : "deleted",
"_shards" :
"total" : 1,
"successful" : 1,
"failed" : 0
,
"_seq_no" : 2,
"_primary_term" : 1
更新文档
PUT /products/_doc/sjfYnXwBVVbJgt24PlVU
"title":"iphon15"
说明: 这种更新方式是先删除原始文档,在将更新文档以新的内容插入。
POST /products/_doc/sjfYnXwBVVbJgt24PlVU/_update
"doc" :
"title" : "iphon15"
说明: 这种方式可以将数据原始内容保存,并在此基础上更新。
批量操作
POST /products/_doc/_bulk #批量索引两条文档
"index":"_id":"1"
"title":"iphone14","price":8999.99,"created_at":"2021-09-15","description":"iPhone 13屏幕采用6.8英寸OLED屏幕"
"index":"_id":"2"
"title":"iphone15","price":8999.99,"created_at":"2021-09-15","description":"iPhone 15屏幕采用10.8英寸OLED屏幕"
POST /products/_doc/_bulk #更新文档同时删除文档
"update":"_id":"1"
"doc":"title":"iphone17"
"delete":"_id":2
"index":
"title":"iphone19","price":8999.99,"created_at":"2021-09-15","description":"iPhone 19屏幕采用61.8英寸OLED屏幕"
index是新增文档,update是更新文档,delete是删除文档
说明:批量时不会因为一个失败而全部失败,而是继续执行后续操作,在返回时按照执行的状态返回!
批量操作不能回车和换行,一条数据必须在同一行

基操整理
#1.创建索引
PUT /dhylikexpy
"settings":
"number_of_shards": 1
, "number_of_replicas": 0
#2.查询所有所有索引
GET /_cat/indices?v
#3.删除索引
DELETE /dhylikexpy
#4.创建索引时指定映射关系
PUT /dhylikexpy
"settings":
"number_of_shards": 1,
"number_of_replicas": 0
, "mappings":
"properties":
"id":
"type":"integer"
,
"name":
"type":"keyword"
,
"wish":
"type":"text"
,
"create_time":
"type":"date"
#5.查看索引的映射
GET /dhylikexpy/_mapping
#6.添加文档---自动生成id
POST /dhylikexpy/_doc/
"id": 1,
"name": "大忽悠",
"wish": "希望小朋友永远快乐",
"create_time": "2022-03-03"
#指定文档id
POST /dhylikexpy/_doc/1
"id": 1,
"name": "大忽悠嘻嘻",
"wish": "大忽悠嘿嘿",
"create_time": "2022-03-03"
#7.查询某个索引下面的文档
GET /dhylikexpy/_doc/2
#8.删除文档
DELETE /dhylikexpy/_doc/3
#9.更新文档--先删除后插入
PUT /dhylikexpy/_doc/1
"id": 520,
"name": "dhy"
#在原始内容上进行更新操作
POST /dhylikexpy/_doc/1/_update
"doc":
"id": 520,
"name": "dhyLikeXpy"
#10.批量插入两条索引记录
POST /dhylikexpy/_doc/_bulk
"index":"_id":2
"id":521,"name":"xpyLikeDhyToo"
"index":"_id":3
"id":522,"name":"xpy"
#11.插入,更新,删除一起的批量操作
POST /dhylikexpy/_doc/_bulk
"index":"_id":4
"id":522,"name":"CJDHY"
"update":"_id":"2"
"doc"以上是关于好玩的ES---第一篇之安装和基本CRUD的主要内容,如果未能解决你的问题,请参考以下文章