云服务器搭建 hadoop集群(全过程详解&解决碰到的问题)
Posted Object_in_java
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了云服务器搭建 hadoop集群(全过程详解&解决碰到的问题)相关的知识,希望对你有一定的参考价值。
该hadoop集群
采用三台真实的部署在公网的服务器(系统为centos)进行分布式搭建。(两台腾讯云,一台阿里云)
过程中遇到问题可以翻到最下方,或者评论区留言。
先建立ip映射,由于是云端服务器,则直接使用真实的公网ip。每台服务器内均配置此文件。
vim /etc/host

(ps:对应的服务器对自己操作时最好用自己的内网ip,例如centos01的配置文件:
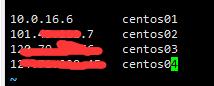
此处的10.0.16.6为云服务器商提供的内网地址
如果不改可能导致namenode无法启动。因为对内操作要用内网地址。
)
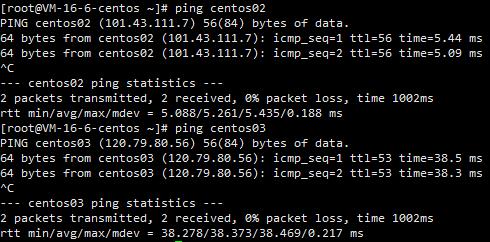
ping一下其他两个设备,发现没有问题。可以-n指定包数,也可以ctrl+c手动终止。
创建两个文件夹,softwares用于存储压缩包。moudules存储解压后的文件(jdk,hadoop)
sudo mkdir /opt/softwares
sudo mkdir /opt/modules
查看全局配置文件(添加环境变量)
vim /etc/profile
配置文件如下(每台服务器内均配置此文件。)

export JAVA_HOME=/opt/modules/jdk1.8.0_241
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$JAVA_HOME/bin:$PATH
export HADOOP_HOME=/opt/modules/hadoop-2.10.0
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
先修改centos01配置文件如下

再传给centos02,03
注意:如果如果用的不是hadoop用户记得更改用户名(例如root)

配置文件具体如下:
/opt/modules/hadoop-2.10.0/hadoop 目录下
向hadoop-env.sh、mapred-env.sh、yarn-env.sh文件中 添加jdk环境变量
export JAVA_HOME=/opt/modules/jdk1.8.0_241
export JAVA_HOME=/opt/modules/jdk1.8.0_241
hadoop集群又分为HDFS集群、YARN集群
具体可参考hadoop集群概述,我的另一篇博客。
然后我们分别配置HDFS集群、YARN集群。
配置HDFS集群
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://centos01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/modules/hadoop-2.10.0/tmp</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permission.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/modules/hadoop-2.10.0/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/modules/hadoop-2.10.0/tmp/dfs/data</value>
</property>
</configuration>
slaves
centos01
centos02
centos03
配置YARN集群
复制mapred-site.xml.template文件并重命名为mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
在文件mapred-site.xml插入如下内容
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>centos01:8032</value>
</property>
</configuration>
在centos01中配置完成后,并且配置文件传给centos02,centos03后,
分别查看三台服务器的jdk和hadoop是否安装成功。
java -version
hadoop version
centos01
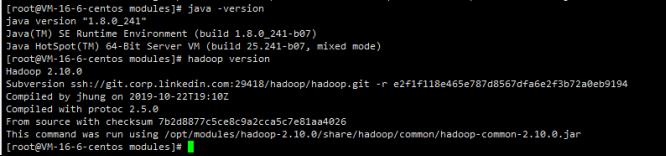
centos02

centos03

发现没有问题。
在centos01节点下格式化NameNode
hdfs namenode -format
格式化完毕后用如下命令
start-all.sh
启动所有节点
结果如下图

最后
jps查看各服务器状态
centos01
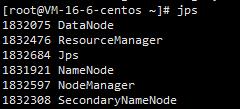
centos02(最下面那个和本次实验无关)
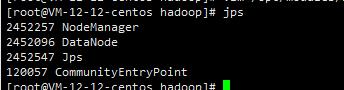
centos03

done!
ps:
中间也出现了需多问题,可以看看你是否也有相同问题
1.Exception in thread “main” java.lang.RuntimeException: com.ctc.wstx.exc.WstxParsingException: Illegal to have multiple roots (start tag in epilog?).
at [row,col,system-id]: [21,2,“file:/opt/modules/hadoop-2.10.0/etc/hadoop/yarn-site.xml”]
这个问题时configuration过多,更改配置不是像改配置文件向配置文件中添加环境变量一样在最下方添加即可,而是要加在configuration标签之间(或者dn(行数)d删除掉原本的configuration,然后直接粘贴全部配置),要符合xml格式也要符合这个规则。
2
类似于如下报错的
centos03***************
caused by ****** /opt/modules/hadoop-2.10.0/etc/hadoop: No such file or directory
这种原因则是因为传输时导致文件缺失,传输中断等原因。
我一开始使用xftp传输到centos03(边scp到02,这样快),但这么做会有权限问题,chmod -R 777后 解决权限问题,但是依然缺少路径,所以我又使用了centos02的方法 scp****,最后断网后传输好像中断了,又传输了一遍,终于启动后没有这个报错了,我在centos03中直接cd 报错的路径也是没有问题了。
3
其他无法启动或启动失败的问题
可以考虑删除core配置文件下配置的hadoop的临时文件,然后重新装配NameNode。
再启动
4
Caused by: java.net.BindException: Cannot assign requested address: JVM_Bind
一开始namenode无法启动,查看日志后发现了这个错误,这个错误主要是ip问题或者端口问题。
我这边是修改了hosts文件centos01的ip地址为自己的内网ip。就可以正常启动了。
云服务器相关问题
1
ping 不通
可能是因为安全组没有开放ICMP协议,或者某个端口没开放(只有华为云有这个问题),我开放了全部安全组后就可以ping通了。
2
使用xftp 这种linux->linux,windows->linux的文件传输软件时,要考虑权限问题。有时chmod -R 777 dir 能解决问题,有时不能。
3
以上是关于云服务器搭建 hadoop集群(全过程详解&解决碰到的问题)的主要内容,如果未能解决你的问题,请参考以下文章
hadoop集群搭建在阿里云服务器上 云服务器配置要求是多少
Hadoop详解——ZooKeeper详解,ZooKeeper伪分布搭建和集群搭建,Hadoop集群搭建,sqoop工具的使用
阿里云ECS服务器部署HADOOP集群:ZooKeeper 完全分布式集群搭建