基于PaddleX的岩石识别
Posted 沧夜2021
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于PaddleX的岩石识别相关的知识,希望对你有一定的参考价值。
文章目录
1. 项目背景
考虑到自己学习的是人工智能和油气的交叉学科,就想试试能不能从基本的岩石识别来做起,做一个岩石识别的小任务。
本次任务思路来源于AI达人创造营第二期,欢迎有兴趣的小伙伴们一起参加飞桨的开发活动!
也算是实现了自己的一个小目标。(人果然是被逼出来的)
1.1 岩石与油气
岩石的探测与识别是地质调查研究和矿产资源勘查的基础工作,岩石的精准识别与分类对地质的探测与识别极为重要,一般可通过多种方式进行鉴定,例如重磁、测井、地震、遥感、电磁、地球化学、手标本及薄片分析方法等方法。

1.2 日常的小细节
在日常生活中,当我们把少量的水洒到海绵上时,会发现水渗入海绵的孔隙中,且不会流出。与这种现象相似,石油和天然气是储存在岩石的孔隙和裂缝中的,储存油气的岩石叫储层。
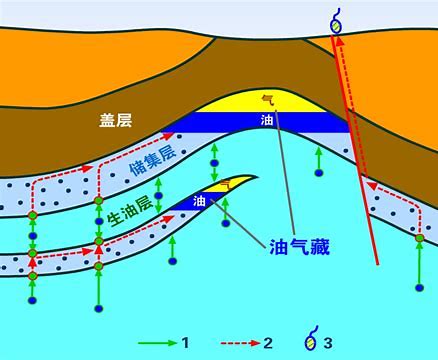
1.3 岩石的特性与石油的关系
岩石的种类多种多样,已经被人们认识的有近百种,但能够形成储层的岩石必须具备一定的孔隙性和渗透性。孔隙性的好坏直接决定岩层储存油气的数量,渗透性的好坏控制了储集层内所含油气的产能。我国已发现的储层类型是多种多样的,主要有砂岩储层、碳酸盐岩储层、火山岩储层、结晶岩储层和泥质岩储层。
1.4 现有的岩石识别系统
自然资源部中国地质调查局“地质云”矿物、岩石识别系统,是人工智能(AI)技术在地质信息化中的典型应用。基本原理是——采用人工智能方式,把已确认的矿物、岩石图片存放于地质云服务器中,建立识别模型,通过计算机深度学习方式,对新采集的矿物、岩石图像进行识别。这个系统是地质专业初学者及非地质工作人员快速了解和识别矿物、岩石的辅助工具。
来源:https://www.cgs.gov.cn/xwl/sp/yangshi/201810/t20181019_469426.html
1.5 自我感想
看到上面这个系统的时候,我就想着能不能自己做一个。他行我也行!我也是大天朝的研究生!我也是学AI的!况且百度飞桨的套件花样多,能够玩出花来!
2. 数据集选取
这个数据集其实是百度公开的数据集修改来的
原始数据集是这个:
https://aistudio.baidu.com/aistudio/datasetdetail/85829#/
修改折腾后了好几版,后来发现之前折腾的数据集被公开了还不能删除。。。私下想着,以后会不会有人看了看数据集,发现质量这么差会不会骂死我?
修改后的数据集3.0:
https://aistudio.baidu.com/aistudio/datasetdetail/129645
不过后期由于对数据集的认识不够,自己私下写了一些批量修改代码,批量重命名的程序,把图片都处理了一下。
这个数据集主要是集中基本的岩石类别,主要有“玄武岩”、“花岗岩”、“大理石”、“石英岩”、“煤”、“石灰石”、“砂岩” 共计7类。
每一个类别都是一个文件夹,推荐使用PaddleX来对这个数据集进行自动划分,贼方便有木有!
其中一个图片是这样子的:很黑吧!

当然黑了,这是煤!
#解压数据集
!unzip -oq data/data129645/RockData.zip -d data/
#查看数据集目录树
!tree data/RockData/
# 引入依赖库
import cv2
import os
import numpy as np
import matplotlib.pyplot as plt
#图片抽样
#读取数据集中一个文件夹的路径
file_dir = '/home/aistudio/data/RockData/Coal/'
#设立列表存储图片名
filesum = []
#读取图片名
for root, dirs, files in os.walk(file_dir):
filesum.append(files)
filesum = filesum[0]
#打印图片名看看效果符不符合预期
#print(filesum)
#定义画布大小
plt.figure(figsize=(8, 8))
#循环读取图片并显示
for i in range(1,5):
plt.subplot(2,2,i)
plt.title(filesum[i])
image = file_dir+filesum[i]
#print(f">>>image")
plt.imshow(cv2.imread(image,1))
plt.tight_layout()
plt.show()

3. PaddleX 安装
在这里我使用PaddleX套件,PaddleX套件在处理图像分类的问题上会大量节省开发效率,相关文档如下:
PaddleX项目官网:
https://www.paddlepaddle.org.cn/paddle/paddlex
PaddleX Github地址:
https://github.com/PaddlePaddle/PaddleX
PaddleX API开发模式快速上手:
https://github.com/PaddlePaddle/PaddleX/blob/develop/docs/quick_start_API.md
PaddleX指标及日志:
https://github.com/PaddlePaddle/PaddleX/blob/develop/docs/appendix/metrics.md
#使用pip安装方式安装2.1.0版本:
pip install paddlex==2.1.0 -i https://mirror.baidu.com/pypi/simple
#在模型进行训练时,我们需要划分训练集,验证集和测试集
#因此需要对如上数据进行划分,直接使用paddlex命令即可将数据集随机划分成70%训练集,20%验证集和10%测试集
#划分好的数据集会额外生成labels.txt, train_list.txt, val_list.txt, test_list.txt四个文件,之后可直接进行训练。
paddlex --split_dataset --format ImageNet --dataset_dir /home/aistudio/data/RockData --val_value 0.2 --test_value 0.1
3.1 MobileNetV3
模型使用的是MobileNetV3-百度改,是百度基于蒸馏方法得到的MobileNetV3预训练模型,模型结构与MobileNetV3一致,但精度更高。
3.2 MobileNetV3 的其他平台开源版本
(1)PyTorch实现1:https://github.com/xiaolai-sqlai/mobilenetv3
(2)PyTorch实现2:https://github.com/kuan-wang/pytorch-mobilenet-v3
(3)PyTorch实现3:https://github.com/leaderj1001/MobileNetV3-Pytorch
(4)Caffe实现:https://github.com/jixing0415/caffe-mobilenet-v3
(5)TensorFLow实现:https://github.com/Bisonai/mobilenetv3-tensorflow
3.3 主要内容
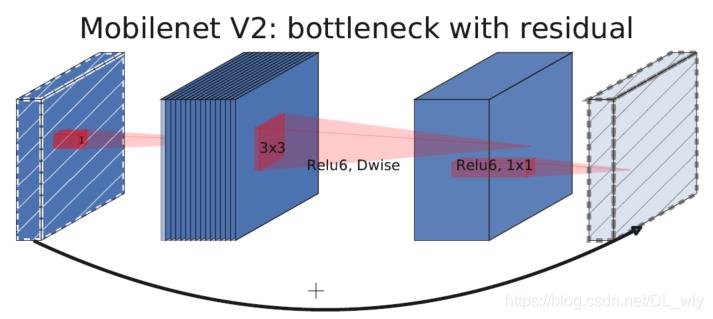
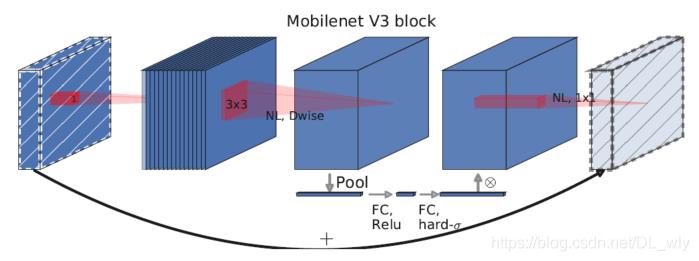
上面两张图是MobileNetV2和MobileNetV3的网络块结构。
MobileNetV3综合了以下三种模型的思想:
MobileNetV1的深度可分离卷积(depthwise separable convolutions)
MobileNetV2的具有线性瓶颈的逆残差结构(the inverted residual with linear bottleneck)
MnasNet的基于squeeze and excitation结构的轻量级注意力模型
详细的论文请参考:《Searching for MobileNetV3》
这里就不多赘述
4. 配置超参数并训练模型
#在训练和验证过程中,数据的处理
from paddlex import transforms as T
train_transforms = T.Compose([
#图片自由裁剪
T.RandomCrop(crop_size=224),
T.Normalize()])
eval_transforms = T.Compose([
#图片大小自定义
T.ResizeByShort(short_size=256),
T.CenterCrop(crop_size=224),
T.Normalize()
])
import paddlex as pdx
#定义数据集,pdx.datasets.ImageNet表示读取ImageNet格式的分类数据集:
train_dataset = pdx.datasets.ImageNet(
data_dir='/home/aistudio/data/RockData',
file_list='/home/aistudio/data/RockData/train_list.txt',
label_list='/home/aistudio/data/RockData/labels.txt',
transforms=train_transforms,
shuffle=True)
eval_dataset = pdx.datasets.ImageNet(
data_dir='/home/aistudio/data/RockData',
file_list='/home/aistudio/data/RockData/val_list.txt',
label_list='/home/aistudio/data/RockData/labels.txt',
transforms=eval_transforms)
2022-02-27 19:49:23 [INFO] Starting to read file list from dataset...
2022-02-27 19:49:23 [INFO] 1442 samples in file /home/aistudio/data/RockData/train_list.txt
2022-02-27 19:49:23 [INFO] Starting to read file list from dataset...
2022-02-27 19:49:23 [INFO] 408 samples in file /home/aistudio/data/RockData/val_list.txt
4.1 训练通用统计信息
以下字段会在输出时候显示,具体含义如下:
| 字段 | 示例 | 含义 |
|---|---|---|
| Epoch | Epoch=4/20 | [迭代轮数]所有训练数据会被训练20轮,当前处于第4轮 |
| Step | Step=62/66 | [迭代步数]所有训练数据被训练一轮所需要的迭代步数为66,当前处于第62步 |
| loss | loss=0.007226 | [损失函数值]参与当前迭代步数的训练样本的平均损失函数值loss,loss值越低,表明模型在训练集上拟合的效果越好(如上日志中第1行表示第4个epoch的第62个Batch的loss值为0.007226) |
| lr | lr=0.008215 | [学习率]当前模型迭代过程中的学习率 |
| time_each_step | time_each_step=0.41s | [每步迭代时间]训练过程计算得到的每步迭代平均用时 |
| eta | eta=0:9:44 | [剩余时间]模型训练完成所需剩余时间预估为0小时9分钟44秒 |
4.2 训练日志字段
分类任务的训练日志除了通用统计信息外,还包括acc1和acc5两个特有字段。
注: acck准确率是针对一张图片进行计算的:把模型在各个类别上的预测得分按从高往低进行排序,取出前k个预测类别,若这k个预测类别包含了真值类,则认为该图片分类正确。
上图中第1行中的acc1表示参与当前迭代步数的训练样本的平均top1准确率,值越高代表模型越优;acc5表示参与当前迭代步数的训练样本的平均top5(若类别数n少于5,则为topn)准确率,值越高代表模型越优。
例如:
[TRAIN] Epoch=1/10, Step=20/22, loss=1.064334, acc1=0.671875, acc5=0.968750, lr=0.025000, time_each_step=0.15s, eta=0:0:31
代表:
Epoch=1/10[迭代轮数]所有训练数据会被训练10轮,当前处于第1轮;
Step=20/22[迭代步数]所有训练数据被训练一轮所需要的迭代步数为22,当前处于第20步;
loss=1.064334[损失函数值]loss值为1.064334;
acc1=0.671875 acc1表示整个验证集的平均top1准确率为0.671875;
acc5=0.968750 acc5表示整个验证集的平均top5准确率为0.968750;
lr=0.025000[学习率]当前模型迭代过程中的学习率;
time_each_step=0.15s[每步迭代时间]训练过程计算得到的每步迭代平均用时;
eta=0:0:31[剩余时间]模型训练完成所需剩余时间预估为0小时9分钟44秒;
#使用百度基于蒸馏方法得到的MobileNetV3预训练模型,模型结构与MobileNetV3一致,但精度更高。
num_classes = len(train_dataset.labels)
model = pdx.cls.MobileNetV3_small(num_classes=num_classes)
model.train(num_epochs=10,
train_dataset=train_dataset,
train_batch_size=64,
eval_dataset=eval_dataset,
lr_decay_epochs=[4, 6, 8],
save_dir='output/mobilenetv3_small',
#训练的输出保存在output/mobilenetv3_small
use_vdl=True)
#use_vdl=True表示可以启动visualdl并查看可视化的指标变化情况。
2022-02-27 20:04:02 [INFO] Loading pretrained model from output/mobilenetv3_small/pretrain/MobileNetV3_small_x1_0_pretrained.pdparams
2022-02-27 20:04:03 [WARNING] [SKIP] Shape of pretrained params fc.weight doesn't match.(Pretrained: (1280, 1000), Actual: [1280, 7])
2022-02-27 20:04:03 [WARNING] [SKIP] Shape of pretrained params fc.bias doesn't match.(Pretrained: (1000,), Actual: [7])
......
poch=7, acc1=0.740327, acc5=0.979911 .
2022-02-27 20:04:42 [INFO] Current evaluated best model on eval_dataset is epoch_6, acc1=0.7425594925880432
2022-02-27 20:04:42 [INFO] Model saved in output/mobilenetv3_small/epoch_7.
2022-02-27 20:04:44 [INFO] [TRAIN] Epoch=8/10, Step=6/22, loss=0.568543, acc1=0.781250, acc5=0.984375, lr=0.000250, time_each_step=0.19s, eta=0:0:14
2022-02-27 20:04:45 [INFO] [TRAIN] Epoch=8/10, Step=16/22, loss=0.609234, acc1=0.796875, acc5=1.000000, lr=0.000250, time_each_step=0.15s, eta=0:0:10
2022-02-27 20:04:46 [INFO] [TRAIN] Epoch 8 finished, loss=0.5681447, acc1=0.79545456, acc5=0.99502844 .
2022-02-27 20:04:46 [INFO] Start to evaluate(total_samples=408, total_steps=7)...
2022-02-27 20:04:48 [INFO] [EVAL] Finished, Epoch=8, acc1=0.732143, acc5=0.982143 .
2022-02-27 20:04:48 [INFO] Current evaluated best model on eval_dataset is epoch_6, acc1=0.7425594925880432
2022-02-27 20:04:48 [INFO] Model saved in output/mobilenetv3_small/epoch_8.
2022-02-27 20:04:49 [INFO] [TRAIN] Epoch=9/10, Step=4/22, loss=0.511275, acc1=0.812500, acc5=1.000000, lr=0.000025, time_each_step=0.19s, eta=0:0:9
2022-02-27 20:04:50 [INFO] [TRAIN] Epoch=9/10, Step=14/22, loss=0.546328, acc1=0.796875, acc5=1.000000, lr=0.000025, time_each_step=0.15s, eta=0:0:6
2022-02-27 20:04:52 [INFO] [TRAIN] Epoch 9 finished, loss=0.5753054, acc1=0.8004261, acc5=0.9957386 .
2022-02-27 20:04:52 [INFO] Start to evaluate(total_samples=408, total_steps=7)...
2022-02-27 20:04:53 [INFO] [EVAL] Finished, Epoch=9, acc1=0.741071, acc5=0.982143 .
2022-02-27 20:04:53 [INFO] Current evaluated best model on eval_dataset is epoch_6, acc1=0.7425594925880432
2022-02-27 20:04:53 [INFO] Model saved in output/mobilenetv3_small/epoch_9.
2022-02-27 20:04:54 [INFO] [TRAIN] Epoch=10/10, Step=2/22, loss=0.833730, acc1=0.718750, acc5=1.000000, lr=0.000025, time_each_step=0.19s, eta=0:0:3
2022-02-27 20:04:56 [INFO] [TRAIN] Epoch=10/10, Step=12/22, loss=0.838117, acc1=0.750000, acc5=1.000000, lr=0.000025, time_each_step=0.15s, eta=0:0:1
2022-02-27 20:04:57 [INFO] [TRAIN] Epoch=10/10, Step=22/22, loss=0.532285, acc1=0.781250, acc5=1.000000, lr=0.000025, time_each_step=0.15s, eta=0:0:0
2022-02-27 20:04:57 [INFO] [TRAIN] Epoch 10 finished, loss=0.5774534, acc1=0.79616475, acc5=0.9957386 .
2022-02-27 20:04:58 [INFO] Start to evaluate(total_samples=408, total_steps=7)...
2022-02-27 20:04:59 [INFO] [EVAL] Finished, Epoch=10, acc1=0.745536, acc5=0.982143 .
2022-02-27 20:04:59 [INFO] Model saved in output/mobilenetv3_small/best_model.
2022-02-27 20:04:59 [INFO] Current evaluated best model on eval_dataset is epoch_10, acc1=0.7455357313156128
2022-02-27 20:04:59 [INFO] Model saved in output/mobilenetv3_small/epoch_10.
5. 测试模型效果
#模型在训练过程中,会每间隔一定轮数保存一次模型
#在验证集上评估效果最好的一轮会保存在save_dir目录下的best_model文件夹
#加载模型,进行预测:
import paddlex as pdx
model = pdx.load_model('output/mobilenetv3_small/best_model')
result = model.predict('/home/aistudio/data/RockData/Coal/Coal271.jpg')
#设置预测结果为标题
plt.title(result[0]['category'])
#显示预测的图像
plt.imshow(cv2.imread('/home/aistudio/data/RockData/Coal/Coal271.jpg',1))
#打印预测的结果
print("Predict Result: ", result)

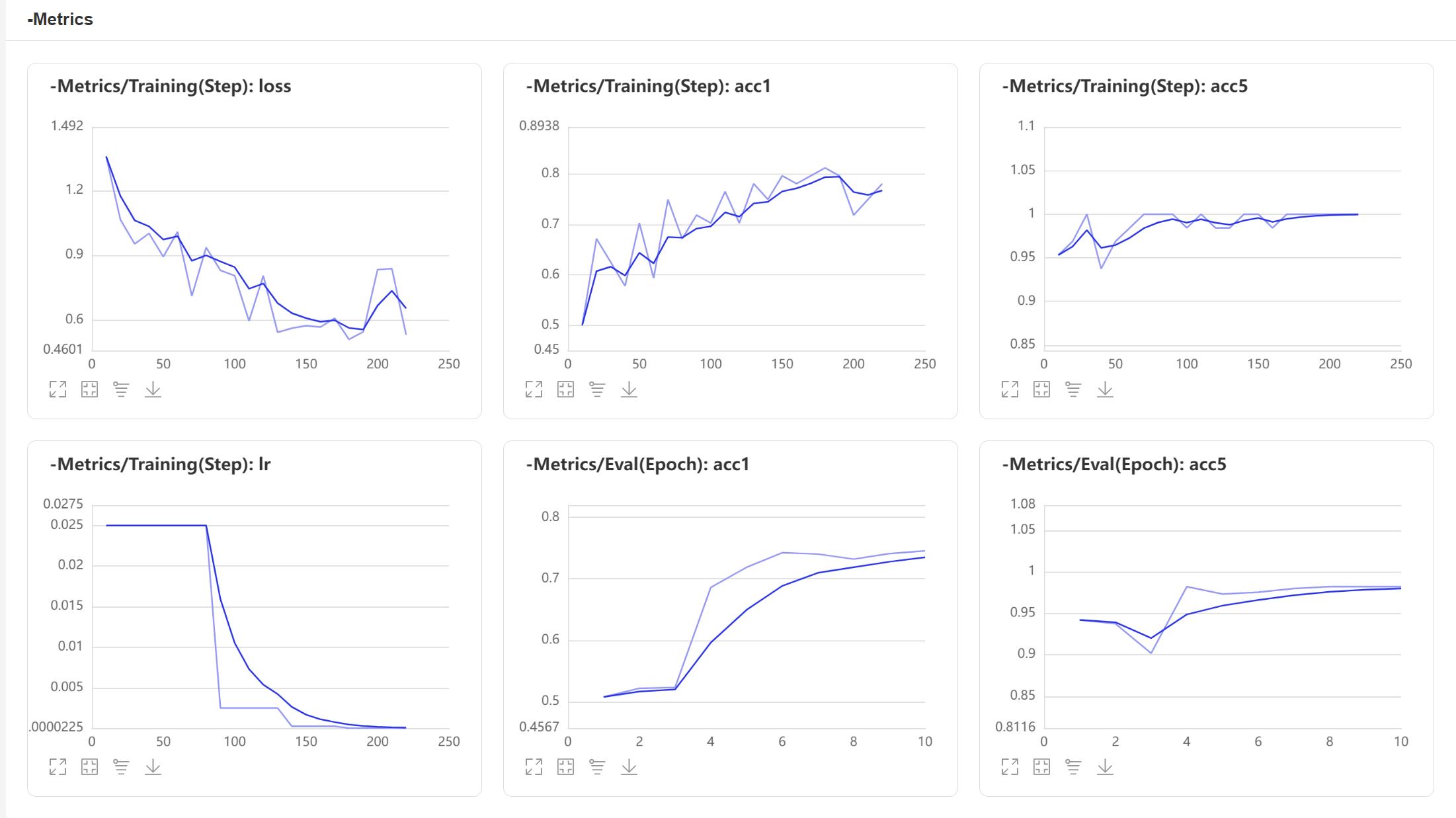
6. 可视化模型效果
点击AIstudio左侧工具栏倒数第五个:【数据模型可视化】
设置logdir为【!cat output/mobilenetv3_small/vdl_log/】
点击【启动VisualDL服务】
7. 总结
少年的心总是喜欢折腾的,要不然这个世界的历史就不会惊起波澜,后期打算自己组网实现这个任务,更深入了解AI训练过程中的点点滴滴,不过囿于现在的菜鸡本菜的水平,还是一步一步踏踏实实多多训练参数,多多看大佬们的项目来汲取养分,成长自己。
最重要的是,人真的是被逼出来的!不逼自己一把,你根本不会知道自己有多么厉害!
以上是关于基于PaddleX的岩石识别的主要内容,如果未能解决你的问题,请参考以下文章