基于FPGA的Yolov4 tiny目标检测网络加速器
Posted FPGA硅农
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于FPGA的Yolov4 tiny目标检测网络加速器相关的知识,希望对你有一定的参考价值。
简介
之前实现了基于FPGA的Winograd CNN加速器(VGG16)和基于FPGA的MobileNet v2加速器,但这两个算法在本质上区别不大:一个是VGG16,另一个是轻量级的MobileNet v2,所实现的功能都是图像分类。因此,为了尝试更多的应用,本文在FPGA上实现了一个目标检测网络----Yolov4 tiny。yolo4 tiny的结构是YOLOv4的精简版,属于轻量化模型,参数只有600万相当于原来的十分之一,这类网络不仅能实现对图像的分类任务,还可以找出目标的位置,因此,更加贴近实际应用中的需求,如行人检测、口罩检测等。
网络结构
对于该部分的内容,已经在博主的另一篇文章中进行了详细的介绍,此处略去。
FPGA IP核的设计
根据对网络结构的分析,我们发现,yolo4 tiny主要由以下几个计算组成:
1.3x3标准卷积
2.1x1point-wise卷积
3.上采样、下采样(2x2最大池化)
4.concat操作
我们将上述计算分成两类,第一类是需要重点加速的,如3x3标准卷积和1x1point-wise卷积,它们占网络总体计算量的95%以上,因此是我们需要重点关注的地方。第二类是一些轻量级的运算,如上采样、下采样和concat操作,其中concat可以通过设置起始地址偏移的方式实现,因此不予以考虑,而其他两个运算,计算量相对于整个网络来说,也是微乎其微的,因此简单的在FPGA上实现即可。
3x3标准卷积设计
关于这部分的设计,我们很大程度上参考了论文。
访存部分
由于FPGA片上存储资源(BRAM)十分有限,而卷积神经网络的权重以及中间计算结果特征图都具有较大的存储占用,因此,缓存整幅特征图显然是不现实的,因此,我们采取了循环分块策略。
具体如下:
假
设
输
入
特
征
图
I
为
N
×
H
i
n
×
W
i
n
,
权
重
为
M
×
N
×
K
×
K
(
K
=
3
)
,
输
出
特
征
图
O
为
M
×
H
×
W
,
假设输入特征图I为N\\times H_in\\times W_in,权重为M\\times N\\times K\\times K(K=3),输出特征图O为M\\times H\\times W,
假设输入特征图I为N×Hin×Win,权重为M×N×K×K(K=3),输出特征图O为M×H×W,令输入通道、输出通道、输出特征图高、宽的分块因子分别为
T
n
,
T
m
,
T
r
,
T
c
T_n,T_m,T_r,T_c
Tn,Tm,Tr,Tc,则每次计算的时候,我们加载
T
n
×
(
T
r
+
K
−
1
)
×
(
T
c
+
K
−
1
)
T_n\\times (T_r+K-1)\\times (T_c+K-1)
Tn×(Tr+K−1)×(Tc+K−1)大小的输入特征图块,
T
m
×
T
n
×
K
×
K
T_m\\times T_n \\times K \\times K
Tm×Tn×K×K大小的权重,然后进行卷积计算,得到
T
m
×
T
r
×
T
c
T_m\\times T_r\\times T_c
Tm×Tr×Tc大小的输出特征块(部分和或者最终结果),本次计算完成后,我们再读取下一块输入特征和权重,再进行计算。如下图所示(下图中load output feature maps可以省去,部分和一直存储在片上即可)

计算部分
计算部分就是一个标准的3x3卷积,而卷积运算的并行度共有4个维度,分别是
1.输入通道并行。即同时计算多个输入通道的特征图和权重的卷积。
2.输出通道并行。即同时计算多个输出特征图的结果或部分和。
3.卷积窗口内并行。即卷积窗口内
K
×
K
K\\times K
K×K个神经元和权重之间乘法的并行。
4.输出像素之间的并行。即同时计算输出特征图上多个神经元。
其中后两者的实现较为不易,例如3需要使用行缓冲,4的设计则更加复杂,因此,在本加速器的设计中,我们采用1,2这两种并行方式。假设并行度为
T
n
,
T
m
T_n,T_m
Tn,Tm,则有

不难想象,其硬件架构应该是一个并行乘法单元+一个加法树,如下图所示
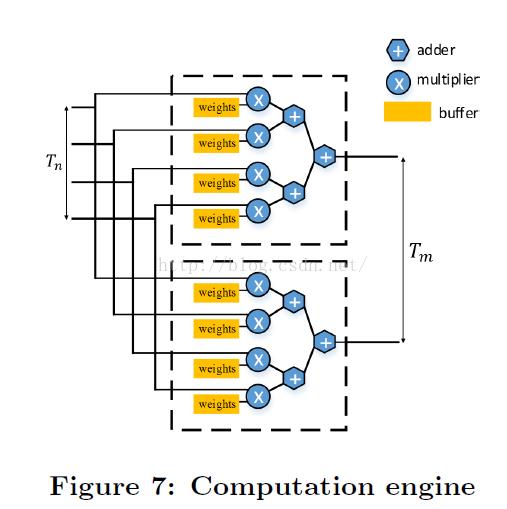
总结
上面已经分别讲了计算部分和访存部分的设计方式,因此可以得到整个加速过程,用伪代码表示,即
for(r=0;r<H;r+=Tr)
for(c=0;c<W;c+=Tc)
for(m=0;m<M;m+=Tm)
for(n=0;n<N;n+=Tn)
load I[n:n+Tn][r:r+Tr+K-1][c:c+Tc+K-1] to ifm_buff;
load W[m:m+Tm][n:n+Tn][:][:] to wt_buff; //片外访存
//片上计算
for(ii=0;ii<K;ii++)
for(jj=0;jj<K;jj++)
for(rr=0;rr<Tr;rr++)
for(cc=0;cc<Tc;cc++)
for(mm=0;mm<Tm;mm++)
for(nn=0;nn<Tn;nn++)
ofm_buff[mm][rr][cc]+=
ifm_buff[nn][rr+ii-1][cc+jj-1]*wt_buff[mm][nn][ii][jj];
store ofm_buff to O[m:m+Tm][r:r+Tr][c:c+Tc]; //片外访存
此外,为了进一步增大系统的吞吐率,我们还进行了乒乓操作,以掩盖数据的传输时间,如下图所示,这是一种以面积换速度的方法。
1x1 Point-Wise卷积设计
1x1卷积,实际上是一个矩阵乘法,因此设计相对比较简单,按照分块矩阵乘法进行设计即可。
分析:假设特征图为
N
×
H
×
W
N\\times H \\times W
N×H×W,权重为
M
×
N
M\\times N
M×N,则1x1卷积相当于矩阵
W
M
×
N
W_M\\times N
WM×N和矩阵
I
N
×
(
H
×
W
)
I_N\\times (H\\times W)
IN×(H×W)的乘积,因此,我们设置分块系数如下:
输出通道分块系数为
T
m
T_m
Tm,输入通道分块系数为
T
n
T_n
Tn,而二维特征图我们把它看成一维向量,其分块系数为
T
p
(
p
i
x
e
l
)
T_p(pixel)
Tp(pixel),然后进行分块矩阵乘法IP核的设计。
同3x3标准卷积的设计一样,我们也进行乒乓操作。
采样
上采样
在yolo4-tiny中,上采样操作是nearest模式的,具体可参见博客
HLS实现在此处略去,因为对最终加速器的吞吐率影响不大,下同。
下采样
在yolo4-tiny中,就是2x2的最大池化层。
CPU端设计
我们的方法是,在block design中例化卷积和采样IP核,然后通过在PS端多次调用PL端的IP核,来对yolo4 tiny进行加速。
CPU端代码的编写,我们采用的类的方法
class BasicConv
public:
int h;
int w;
int s;
int k;
int p;
int ch_in;
int ch_out;
data_t* weight;
data_t* bias;
;
class Resblock_body
public:
int h;
int w;
int ch_in;
int ch_out;
BasicConv* conv1;
BasicConv* conv2;
BasicConv* conv3;
BasicConv* conv4;
;
class CSPDarkNet
public:
BasicConv* basic_conv1;
BasicConv* basic_conv2;
BasicConv* basic_conv3;
Resblock_body* resblock1;
Resblock_body* resblock2;
Resblock_body* resblock3;
;
如上面的代码所示,有BasicConv类,Resblock_body类和CSPDarkNet类,其中BasicConv即一个卷积+BN层+leakyrelu层,Resblock_body为yolov4 tiny中的一个重要结构,共4个,最后,BasicConv和Resblock_body组成了yolo4 tiny的backbone:CSPDarkNet。
CSPDarkNet和FPN以及yolo_head,共同组成了yolov4 tiny网络:
class Yolo4_Tiny
public:
CSPDarkNet* backbone;
//conv_forP5
BasicConv* conv_forP5_conv;
//yolo_headP4
BasicConv* yolo_headP4_basic_conv1;
data_t* yolo_headP4_w2;
data_t* yolo_headP4_b2;
//yolo_headP5
BasicConv* yolo_headP5_basic_conv1;
data_t* yolo_headP5_w2;
data_t* yolo_headP5_b2;
//upsample
BasicConv* upsample_conv;
Yolo4_Tiny() //���캯��
this->backbone=new CSPDarkNet();
//conv_forP5
this->conv_forP5_conv=new BasicConv(13,13,1,1,0,512,256); //K=1
//yolo_headP4
this->yolo_headP4_basic_conv1=new BasicConv(26,26,3,1,1,384,256);
this->yolo_headP4_w2=new data_t[75*256*1*1]; //K=1
this->yolo_headP4_b2=new data_t[75];
//yolo_headP5
this->yolo_headP5_basic_conv1=new BasicConv(13,13,3,1,1,256,512);
this->yolo_headP5_w2=new data_t[75*512*1*1]; //K=1
this->yolo_headP5_b2=new data_t[75];
//upsample
this->upsample_conv=new BasicConv(13,13,1,1,0,256,128); //K=1
void load_weight(string dir)
this->backbone->load_weight(dir);
//conv_forP5
this->conv_forP5_conv->load_weight(dir+"\\\\conv_forP5");
//yolo_headP4
read_params(dir+"\\\\yolo_headP4\\\\w1.bin",this->yolo_headP4_basic_conv1->weight,256*384*3*3);
read_params(dir+"\\\\yolo_headP4\\\\b1.bin",this->yolo_headP4_basic_conv1->bias,256);
read_params(dir+"\\\\yolo_headP4\\\\w2.bin",this->yolo_headP4_w2,75*256*1*1);
read_params(dir+"\\\\yolo_headP4\\\\b2.bin",this->yolo_headP4_b2,75);
//yolo_headP5
read_params(dir+"\\\\yolo_headP5\\\\w1.bin",this->yolo_headP5_basic_conv1->weight,512*256*9);
read_params(dir+"\\\\yolo_headP5\\\\b1.bin",this->yolo_headP5_basic_conv1->bias,512);
read_params(dir+"\\\\yolo_headP5\\\\w2.bin",this->yolo_headP5_w2,75*512*1*1);
read_params(dir+"\\\\yolo_headP5\\\\b2.bin",this->yolo_headP5_b2,75);
//upsample
this->upsample_conv->load_weight(dir+"\\\\upsample");
//
void forward(data_t* in,data_t* out0,data_t* out1)
static data_t feat1[256*26*26];
static data_t feat2[512*13*13]