ShardingJDBC第二篇:读写分离与分布式事务
Posted 毛奇志
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ShardingJDBC第二篇:读写分离与分布式事务相关的知识,希望对你有一定的参考价值。
文章目录
一、前言
本文主要介绍了ShardingJDBC读写分离与分布式事务,本文代码如下:
springboot集成shardingJDBC实现读写分离工程源码
springboot集成shardingJDBC实现分布式事务工程源码
二、Sharding-JDBC读写分离
2.1 读写分离
读写分离理论基础:分为master库和slave库,insert/update/delete操作路由到master库,select操作路由到slave库,slave库通过binlog日志(canal组件)同步master库的数据。
mysql读写分离的配置
(1) 开启master服务器的binlog日志并允许slave节点来读取这个binlog日志(mysql默认不开启binlog)
(2) slave节点 ,指定某个binlog文件,以及同步的offset
- 指定master节点的ip
- 执行master节点的用户名和密码
我们搭建一个一主一从的数据库模式,演示一下数据库主从搭建的配置过程,先准备两台服务器,并提前安装好mysql8.0 。
2.2 读写分离实践
2.2.1 master节点配置
开启master服务器的binlog日志并允许slave节点来读取这个binlog日志
第一步:编辑mysql的my.inf文件(因为mysql默认不开启binlog日志,所以需要手动开启master服务器的binlog日志)
vim /etc/my.inf
log-bin=/var/lib/mysql/mysql-bin
server-id=1001
第二步:使用如下命令重启mysql
systemctl restart mysqld
第三步:启动成功后,可以在 /var/lib/mysql/mysql-bin 目录下生成两个文件。
[root@localhost ~]# ls /var/lib/mysql/mysql-bin.
mysql-bin.000001 mysql-bin.index
第四步:可以通过下面的语句看到bin-log开启情况
show variables like 'log_bin%';
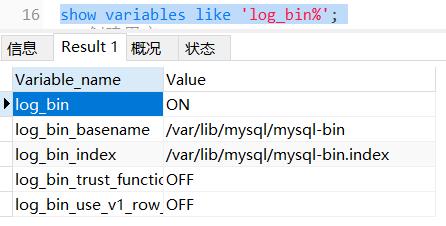
第五步:在Master库创建一个具有指定库数据复制权限的用户,slave库在访问数据连接时,需要用到该账户进行连接,执行授权操作并刷新权限信息
-- replication slave 表示授权复制 -- *.* 表示所有的库和表
-- 创建用户,其中repl表示用户名,192.168.100.137表示slave库的ip地址,
-- 也就是只允许这个ip通过repl用户访问master库
grant replication slave on *.* to 'repl'@'192.168.100.137'
identified by '123456' with grant option;
-- 刷新权限信息
flush privileges;
2.2.2 slave节点配置
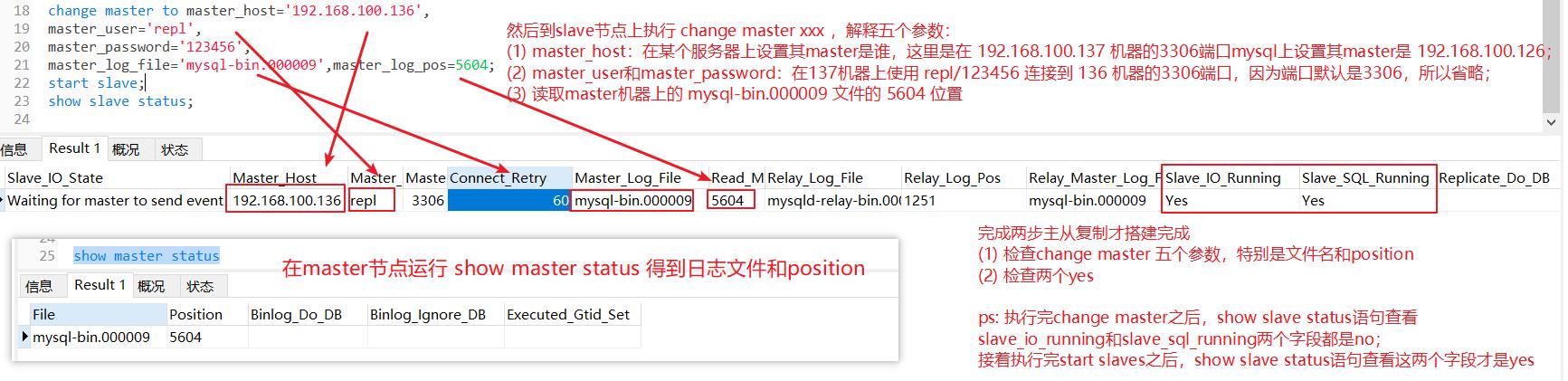
第一步:在master节点,通过下面的命令了解master节点的状态,如下:
show master status

第二步:在slave节点执行如下命令
change master to master_host='192.168.100.136',
master_user='repl',
master_password='123456',
master_log_file='mysql-bin.000009',master_log_pos=5604;
master_log_file是第一步得到的file名称
master_log_pos是第一步得到的同步位置点
端口默认值是3306,所以这里就没有指定master节点的
第三步:启动slave同步
start slave;
第四步:测试,查看同步状态,如下图,表示主从同步搭建成功,然后在master节点新建一个表,插入一条数据,slave节点也就有这个表了。
show slave status

至此,mysql的主从结构部署好了,让select路由到从库,insert/update/delete路由到主库就好了。
eg1: 也可以使用canal组件监听master节点binlog日志的变动来实现
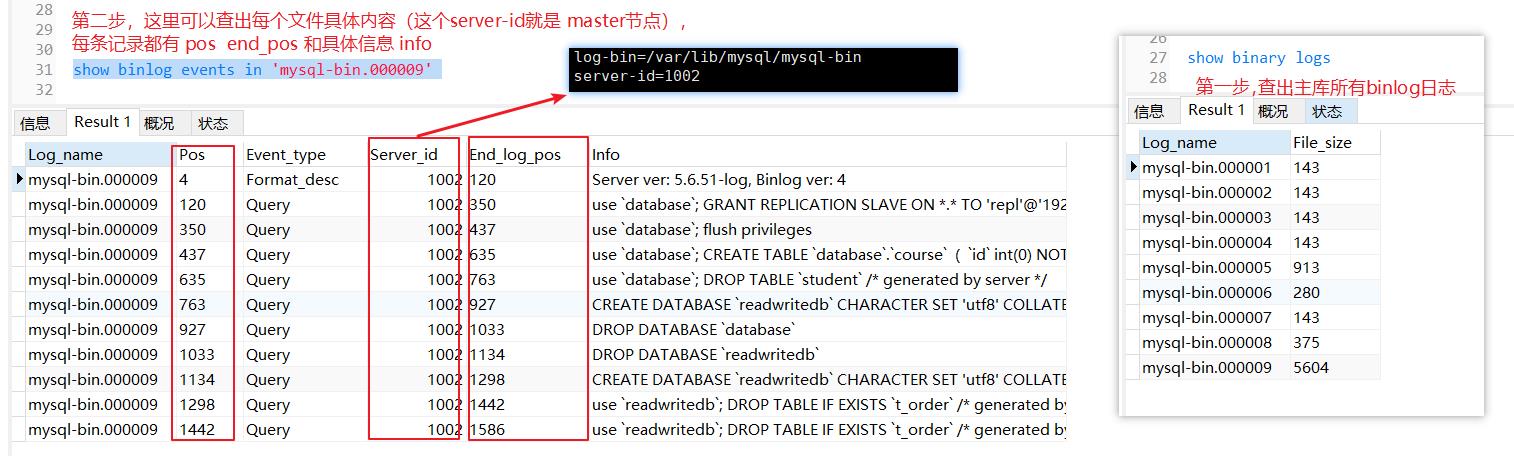
如果想查看主库的binlog,可以如下操作
show binary logs
show binlog events in 'mysql-bin.000009'
新建数据库和新建表之前,检查两点
(1) 从节点上,io和sql都是yes
(2) 从节点上,监听的binlong文件名和offset和主节点当前binlong文件名和offset是一致的
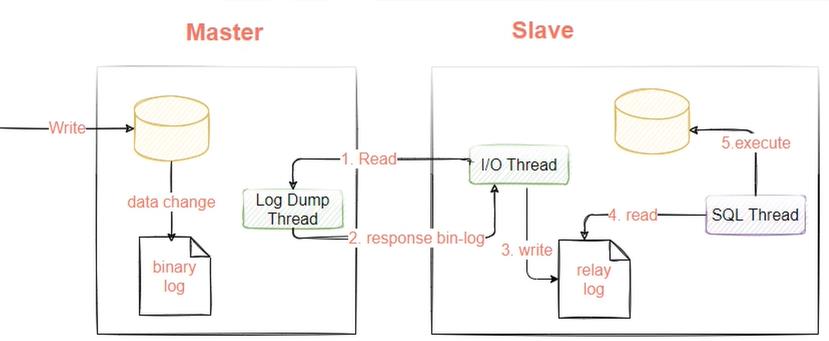
因为主从复制的原理是两个日志文件,三个线程,主节点binlog日志和log Dump Thread线程,从节点relay log日志和I/O Thread、SQL Thread线程,所以从节点必须保证io和sql都是yes,如下图:
从节点上,监听的binlong文件名和offset和主节点当前binlong文件名和offset是一致的,就是从节点监听的文件和文件当前位置一定要从主节点一致,才能读取主节点next操作,如下图:
保证了以上两点,才可以正常主从复制,即主节点新建数据库readwritedb,从节点刷新一下,也会有一个readwritedb,主节点在readwritedb上新建一个t_order表,从节点的readwritedb上也会有一个t_order表。
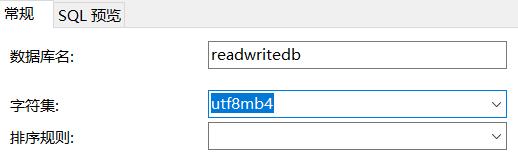
注意1:主节点新建readwritedb的时候,使用utf8mb4字符集,排序规则不填,如图:
注意2:主节点新建t_order表的时候,执行下面一个即可
DROP TABLE IF EXISTS `t_order`;
CREATE TABLE `t_order` (
`order_id` bigint NOT NULL AUTO_INCREMENT,
`user_id` int NOT NULL,
`address_id` bigint NOT NULL,
`status` varchar(50) DEFAULT NULL,
PRIMARY KEY (`order_id`)
) ENGINE=InnoDB AUTO_INCREMENT=624279674839085057 DEFAULT CHARSET=utf8mb4;
2.3 将不同请求路由到不同数据库中
新建springboot工程,controller类接口如下:

配置文件如下:
运行,chrome浏览器访问 http://localhost:8080/swagger-ui.html,然后选择接口controller类进去就好
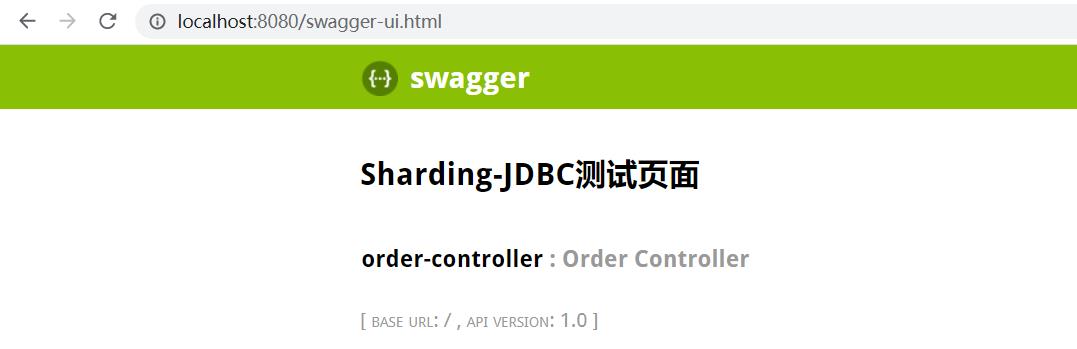
在swagger上发送请求,测试post接口
测试get接口
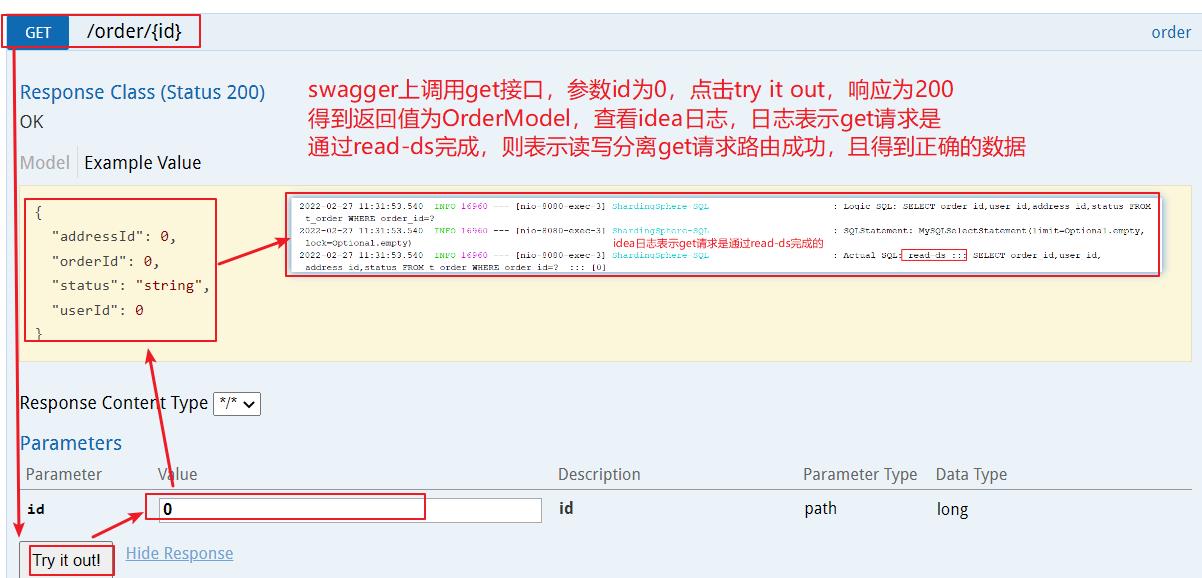
eg1: master和slave设置了之后,无法自动切换角色
2.4 搭建主从复制心得(需要注意的事项/常见坑)
如下操作是指使用vmware,使用centos7.iso新建两个虚拟机,给每个安装上mysql,192.168.100.136为master,192.168.100.137为slave
2.4.1 vmware最小化安装centos7两步骤
vmware最小化安装centos7两步骤:
(1) 最小化安装:先到官网 https://www.centos.org/download/ 下载centos.iso
直接选阿里云镜像就好 http://mirrors.aliyun.com/centos/7.9.2009/isos/x86_64/
具体安装可以参见 https://www.cnblogs.com/liuhui-xzz/p/10155511.html
其实没这么麻烦,只需要配置磁盘这个必选就好了,其他都不用配置
(2) 配置静态ip:最小化安装之后ping www.baidu.com失败,需要配置静态ip
输入 vi /etc/sysconfig/network-scripts/ifcfg-ens33 然后按照如下图编辑,最后 service network restart 保存即可
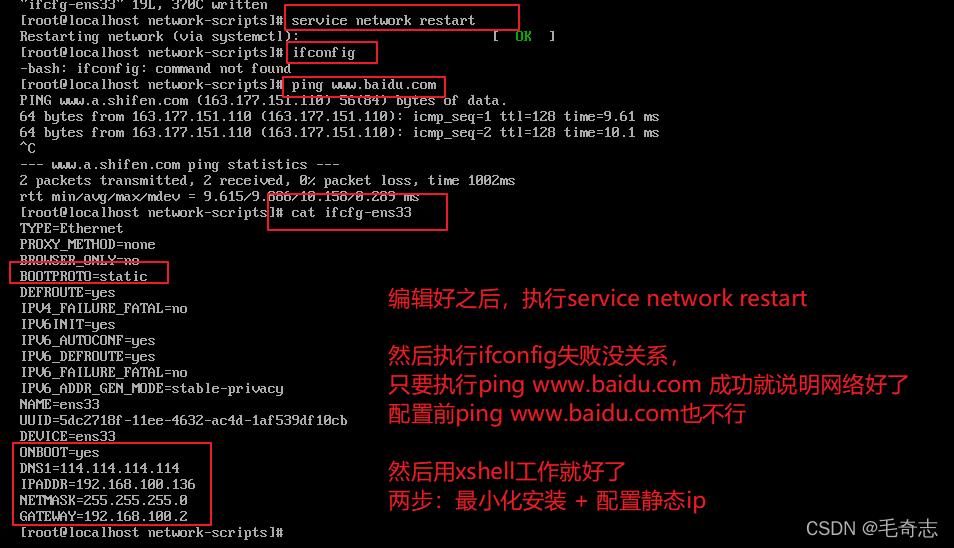
解释一下,BOOTPROTO=static ONBOOT=yes DNS1=114.114.114.114 这三个是写死的,那么其他三个ip 子网掩码 网关是如何确定的呢?这个和本机的ip无关,只和vmware的虚拟网络编辑器有关。
vware的虚拟网络编辑器,需要配置子网掩码、子网ip、网关ip
首先是子网掩码,一般都是C类,配置为 255.255.255.0 ,没什么好说的,然后是子网ip,这个子网ip要受到子网掩码的限制,只有前面三个字节,最后一个字节为0,一般是 xxx.xxx.xxx.0,这里子网IP配置为192.168.100.0,然后再是网关(就是虚拟网络编辑器的ip),网关ip又受到子网ip的限制,前面三个字节需要和子网ip一样,表示是这个子网段内的ip,这里配置为192.168.100.2,其他可以配置为该子网内任意一个 192.168.100.1 - 192.168.100.127,如下图:
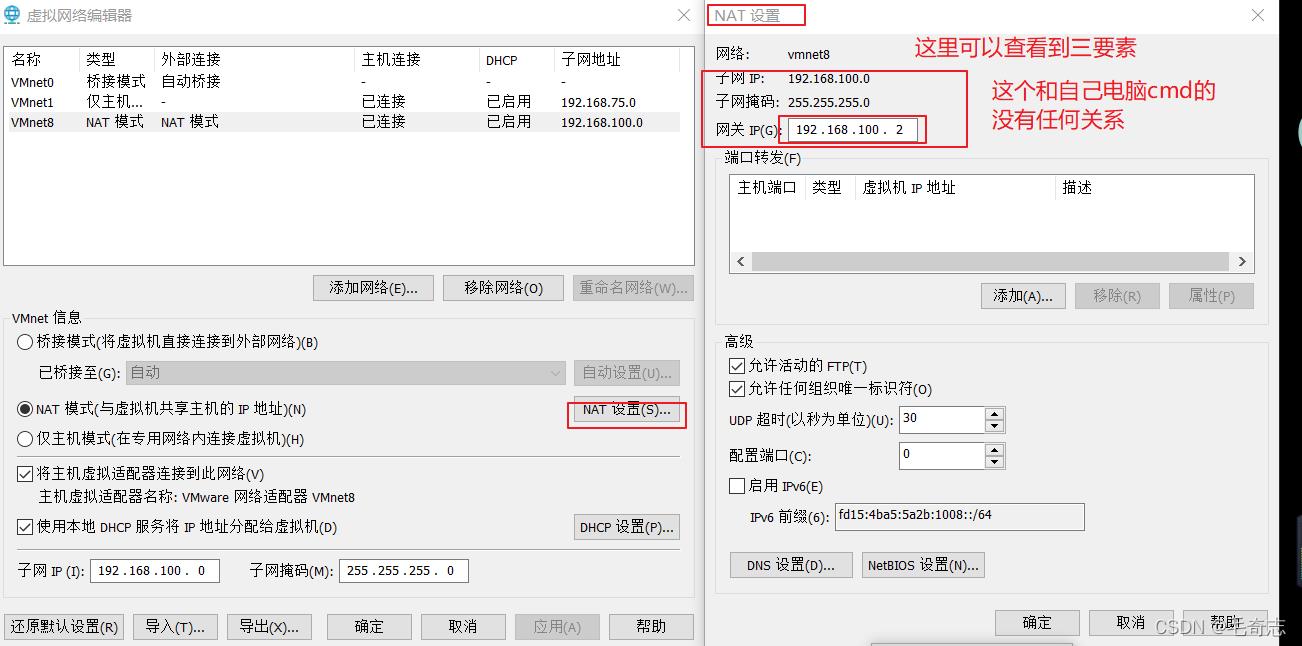
配置好虚拟网络编辑器之后,再来看静态ip的三个字段,NETMASK=255.255.255.0 没问题,c类都是这样配置,然后是网关ip GATEWAY,这里必须和虚拟网络编辑器的那个网关ip一致就是192.168.100.2,所以配置GATEWAY=192.168.100.2,然后就是自己的IPADDR了,要保证两点,在子网段内 且 不和网关ip及该子网段内其他ip冲突,在子网段内就是 192.168.100 开头,不和网关ip及该子网段内其他ip冲突,就是最后一个不能为 2 或者其他用过的,所以一个是 136 一个是137,即 192.168.100.136 和 192.168.100.137 。
配置静态ip之后,就可以用xshell连接并操作了,不用再使用vmware敲命令,也有yum命令,缺少什么都可以随时下载,比如最小安装没有wget命令,可以yum -y install wget。
2.4.2 centos上安装mysql步骤
centos上安装mysql步骤:
(1) 下载 wget http://repo.mysql.com/mysql-community-release-el7-5.noarch.rpm
(2) 安装rpm -ivh mysql-community-release-el7-5.noarch.rpm
(3) 正式安装 yum install mysql-server
(4) 重启 service mysqld restart
(5) 设置密码:因为默认的root是没有密码的,输入# mysql -uroot可以直接登录,设置密码的时候,一定记得用password()函数加密,连接上mysql输入 set password = password('123456');
(6) 设置权限:因为默认root是本地navicat无法访问的,所以设置权限并刷新
grant all privileges on *.* to 'root'@'%' identified by '123456' with grant option; flush privileges;
(7) 关闭防火墙:systemctl stop firewalld.service
也可以使用docker安装
2.4.3 /etc目录下找不到配置文件my.cnf
主节点需要打开binlog,就要修改 /etc/my.cnf 配置文件,但是有时候 /etc 目录下找不到配置文件 my.cnf
两种可能以及解决方案:
可能1:可能是安装的问题,即mysql /etc下面有这个my.cnf文件的,但是因为安装的不好就没有;
解决1:重新新建虚拟机再来一次,或者卸载centos上的mysql再来一次,有的时候在重新安装一次就有了;
可能2:mysql版本问题,高版本的mysql为了安全没有这个文件了;
解决2:需要将 /usr/share/mysql 目录下的 my-default.cnf 复制移动到 /etc 目录下,通过查询的方式配置好四个属性,然后配置好 server-id=xxx 和 log-bin=/var/lib/mysql/mysql-bin 就好,参见 MySQL没有my.cnf配置文件如何解决
2.4.4 change master to xxx 系列问题
change master to xxx 系列问题
(1) 这句在slave节点上执行,目的是设置这个节点的主节点是哪个;
(2) 这句执行完成后 show slave status; slave_io_running 和 slave_sql_runing 两个字段为no,必须执行 start slave; 这两个字段才为yes,才算完事;
(3) 必须在stop slave;停止之后执行,否则报错;
(4) master_log_file 文件名 和 master_log_pos 位置一定要对上,对不上无法实现主库新建数据库新建表,从库同步,且不报错,很隐晦找不到原因;
(5) /etc/my.cnf主节点必须配上bin-log和server-id,从节点必须配上server-id:如果从节点不配置server-id
执行 change master to xxx 报错,报错信息为 Slave is not configured or failed to initialize property. You must at least set --server-id to enable either a master or a slave. Additional error messages can be found in the MySQL error log.
(6) 各个节点的server-id一定要不相同,即主从节点的server-id一定要不相同:如果存在相同,执行 change master to xxx 报错,报错信息为 Fatal error: The slave I/O thread stops because master and slave have equal MySQL server ids;
(7) 各个节点的server-uuid一定要不相同,如果存在相同,执行 change master to xxx 报错,报错信息为 Fatal error: The slave I/O thread stops because master and slave have equal MySQL server UUIDs; these UUIDs must be different for replication to work. 如果直接copy data文件夹后server_uuid是相同的,存在这种问题,可以使用 show variables like '%server_uuid%'; 查看节点uuid.
2.4.5 centos上可以启动并使用mysql,但是本地navicat连不上mysql
问题:centos上可以启动并使用mysql,但是本地navicat连不上mysql
解决:linux可以启动mysql,说明安装好了,额外需要两步,本地才可以连上
(1) 开防火墙 systemctl stop firewalld
(2) 开放远程权限 grant all privileges on *.* to 'root'@'%' identified by '123456' with grant option; ``flush privileges;
完成这两步骤之后,本地Navicat就可以连上,无需再次重启mysql service mysqld restart
三、ShardingJDBC分布式事务
3.1 分布式事务
事务包括两种,一个是本地事务,一个是分布式事务,而分布式事务又分为两种,强一致性的XA事务和最终一致性的柔性事务,官网 https://shardingsphere.apache.org/document/current/cn/features/transaction/,如下:
对应的代码

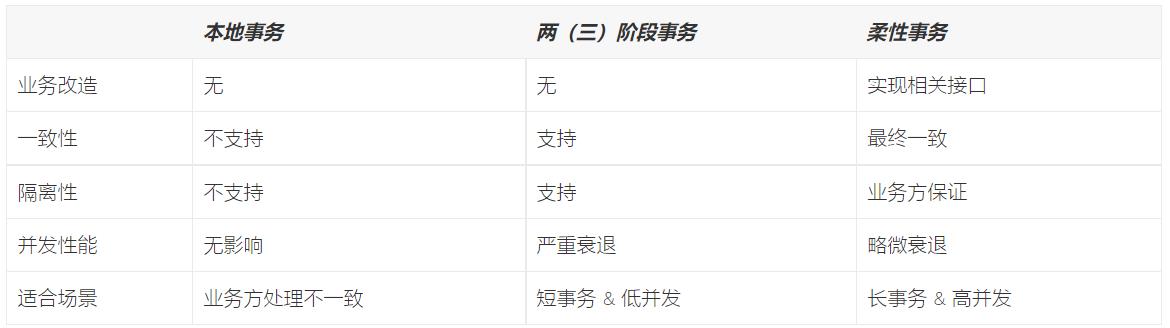
如果将实现了 ACID 的事务要素的事务称为刚性事务的话,那么基于 BASE 事务要素的事务则称为柔性事务。

BASE 是基本可用、柔性状态和最终一致性这三个要素的缩写。
基本可用(Basically Available)保证分布式事务参与方不一定同时在线;
柔性状态(Soft state)则允许系统状态更新有一定的延时,这个延时对客户来说不一定能够察觉;
最终一致性(Eventually consistent)通常是通过消息传递的方式保证系统的最终一致性。
在 ACID 事务中对隔离性的要求很高,在事务执行过程中,必须将所有的资源锁定。 柔性事务的理念则是通过业务逻辑将互斥锁操作从资源层面上移至业务层面。 通过放宽对强一致性要求,来换取系统吞吐量的提升。
3.2 强一致性的XA事务
3.2.1 全局事务
全局事务是一个DTP模型的事务,所谓DTP模型指的是 X/Open DTP (X/Open Distributed Transaction
Processing Reference Model),是 X/Open 这个组织定义的一套分布式事务的标准,
X/Open,即现在的open group,是一个独立的组织,主要负责制定各种行业技术标准。官网地
址:http://www.opengroup.org/。X/Open组织主要由各大知名公司或者厂商进行支持,这些组
织不光遵循X/Open组织定义的行业技术标准,也参与到标准的制定。
小结:X/Open 是一个组织名,DTP模型是这个组织提出的分布式事务标准,仅仅是提供一个标准,具体实现由厂商自己决定。
X/Open了定义了规范和API接口,由这个厂商进行具体的实现,这个标准提出了使用二阶段提交(2PC –Two-Phase-Commit)来保证分布式事务的完整性。后来J2EE也遵循了X/OpenDTP规范,设计并实现了java里的分布式事务编程接口规范-JTA,如下图,表示一个X/Open DTP模型。
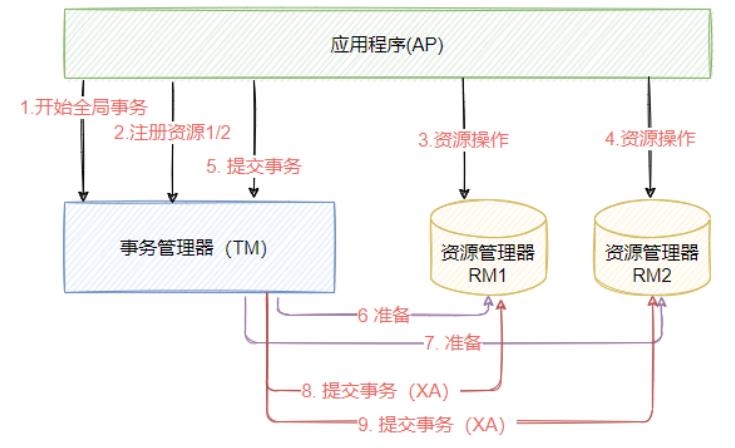
X/Open DTP模型定义了三个角色和两个协议,其中三个角色分别如下:
AP(Application Program),表示应用程序,也可以理解成使用DTP模型的程序
RM(Resource Manager),资源管理器,这个资源可以是数据库, 应用程序通过资源管理器对
资源进行控制,资源管理器必须实现XA定义的接口
TM(Transaction Manager),表示事务管理器,负责协调和管理全局事务,事务管理器控制整
个全局事务,管理事务的生命周期,并且协调资源。
两个协议分别是:
XA协议: XA 是X/Open DTP定义的资源管理器和事务管理器之间的接口规范,TM用它来通知和协
调相关RM事务的开始、结束、提交或回滚。目前Oracle、Mysql、DB2都提供了对XA的支持; XA接口是双向的系统接口,在事务管理器(TM ) 以及多个资源管理器之间形成通信的桥梁(XA不能自动 提交)XA协议的语法,主流的数据库都支持 XA协议,从而能够实现跨数据库事务。
TX协议: 全局事务管理器与资源管理器之间通信的接口。在分布式系统中,每一个机器节点虽然都能够明确知道自己在进行事务操作过程中的结果是成功还是失败,但却无法直接获取到其他分布式节点的操作结果。因此当一个事务操作需要跨越多个分布式节点的时候,为了保持事务处理的ACID特性,就需要引入一个“协调者”(TM)来统一调度所有分布式节点的执行逻辑,这些被调度的分布式节点被称为AP。TM负责调度AP的行为,并最终决定这些AP是否要把事务真正进行提交到(RM)。
3.2.2 2pc提交协议
在X/OpenDTP模型中,一个分布式事务所涉及的SQL逻辑都执行完成,并到了(RM)要最后提交事务的关键时刻,为了避免分布式系统所固有的不可靠性导致提交事务意外失败,TM 果断决定实施两步走的方案,这个就称为二阶提交。
eg: XA事务又称为两阶段事务,是同一个东西,就是强一致性分布式事务,两阶段按照它的实现方式命名的。
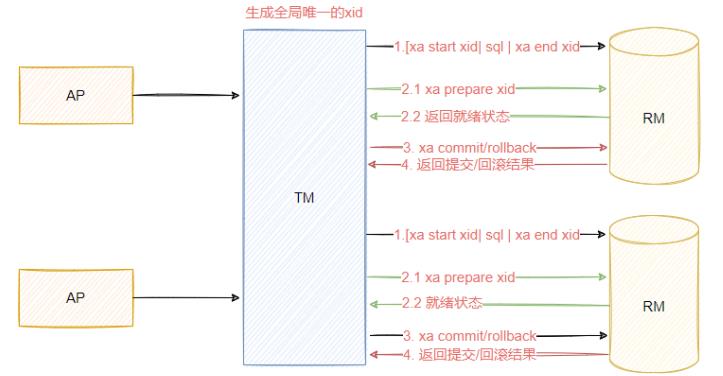
二阶段提交,是计算机网络尤其是在数据库领域内,为了使基于分布式系统架构下的所有节点在进行事务处理过程中能够保持原子性和一致性而设计的一种算法。通常,二阶段提交协议也被认为是一种一致性协议,用来保证分布式系统数据的一致性。目前,绝大部分的关系型数据库都是采用二阶段提交协议来完成分布式事务处理的,利用该协议能够非常方便地完成所有分布式事务AP的协调,统一决定事务的提交或回滚,从而能够有效保证分布式数据一致性,因此2pc也被广泛运用在许多分布式系统中。
-- 启动一个XA事务 (xid 必须是一个唯一值; [JOIN|RESUME] 字句不被支持)
mysql> XA START 'xatest';
Query OK, 0 rows affected (0.00 sec)
mysql> INSERT INTO mytable (i) VALUES(10);
Query OK, 1 row affected (0.04 sec)
-- 结束一个XA事务 ( [SUSPEND [FOR MIGRATE]] 字句不被支持)
mysql> XA END 'xatest';
Query OK, 0 rows affected (0.00 sec)
-- 准备 此动作会把这个事务的redo日志写入innodb redo log,只要这一阶段是成功的,那么后续 XACommit一定会成功
mysql> XA PREPARE 'xatest';
Query OK, 0 rows affected (0.00 sec)
--提交XA事务
mysql> XA COMMIT 'xatest';
Query OK, 0 rows affected (0.00 sec)
3.2.3 XA事务存在的问题
基于XA协议的全局事务,是属于强一致性事务,因为在全局事务中,只要有任何一个RM出现异
常,都会导致全局事务回滚。同时,本地事务在Prepare阶段锁定资源时,如果有其他事务要要修改相
同的数据,就必须要等待前面的事务完成,这本身是无可厚非的设计,但是由于多个RM节点是跨网
络,一旦出现网络延迟,就导致该事务一直占用资源使得整体性能下降。
3.3 实践:强一致性的XA事务
controller类接口

配置文件
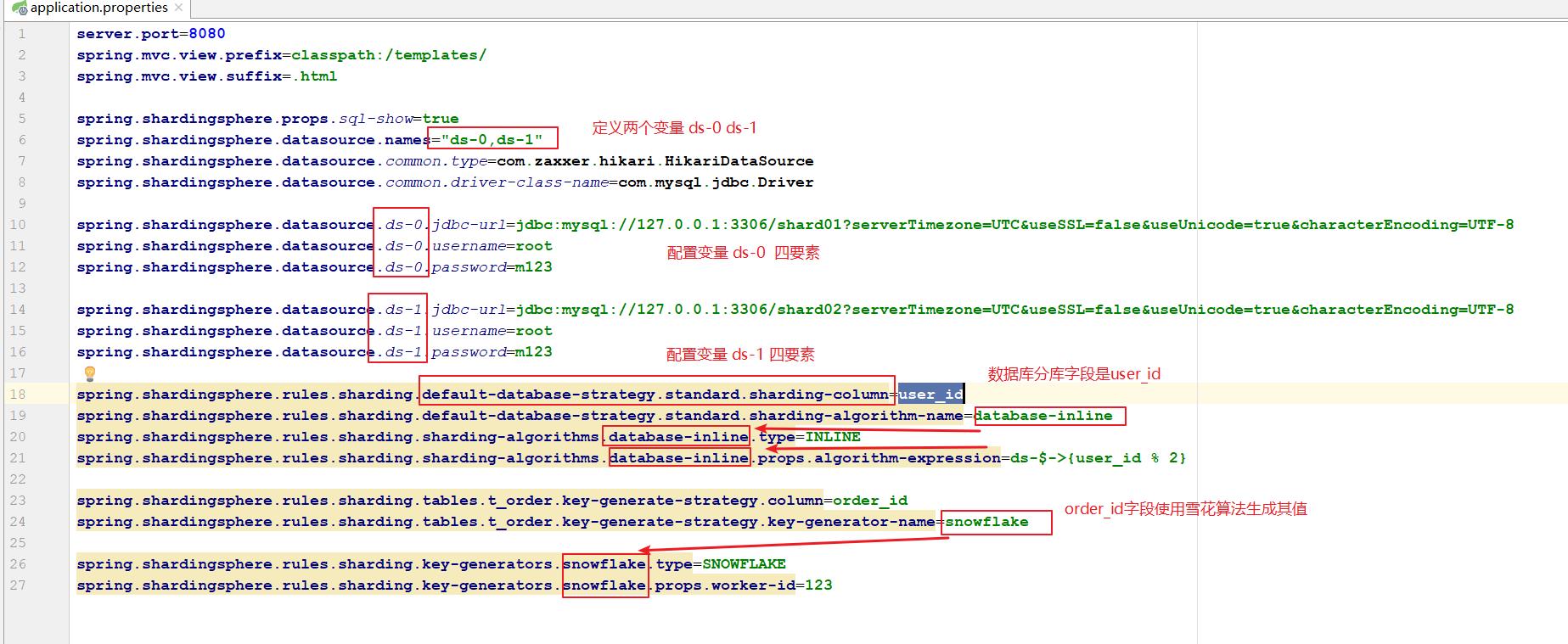
service类方法
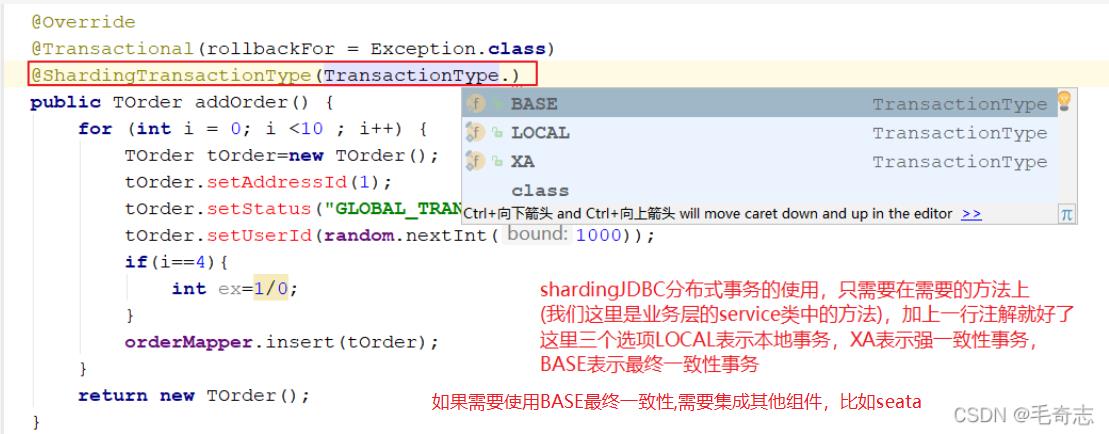
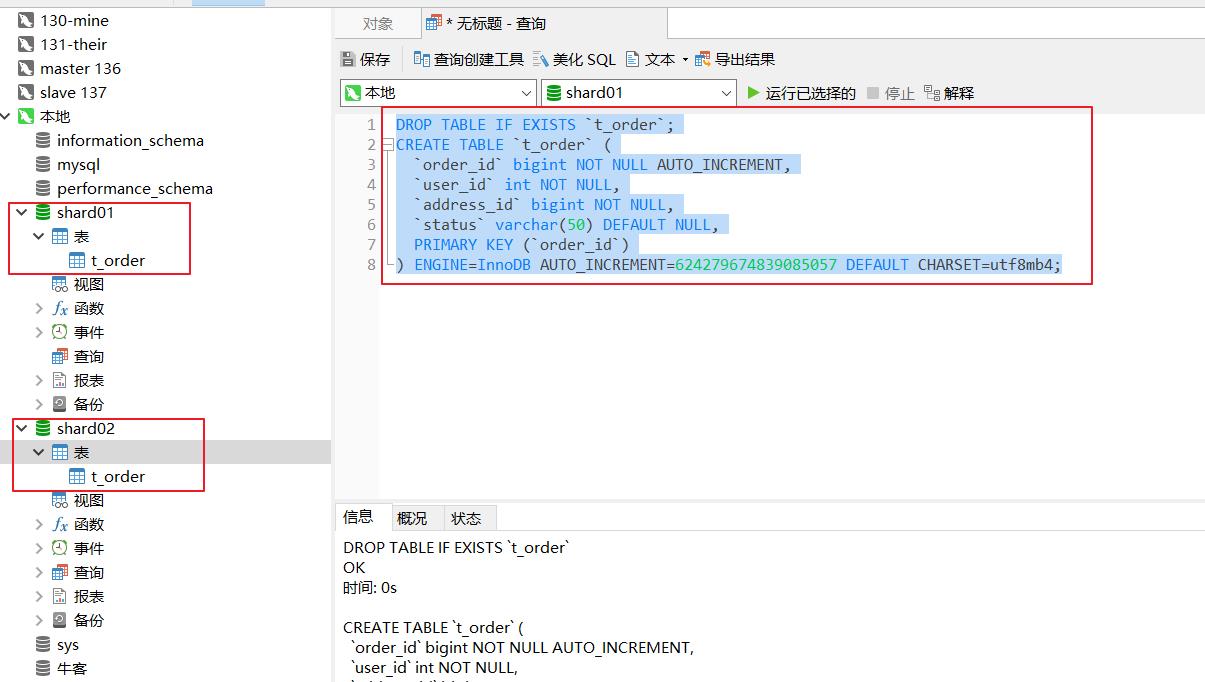
现在数据库中新建好表
DROP TABLE IF EXISTS `t_order`;
CREATE TABLE `t_order` (
`order_id` bigint NOT NULL AUTO_INCREMENT,
`user_id` int NOT NULL,
`address_id` bigint NOT NULL,
`status` varchar(50) DEFAULT NULL,
PRIMARY KEY (`order_id`)
) ENGINE=InnoDB AUTO_INCREMENT=624279674839085057 DEFAULT CHARSET=utf8mb4;
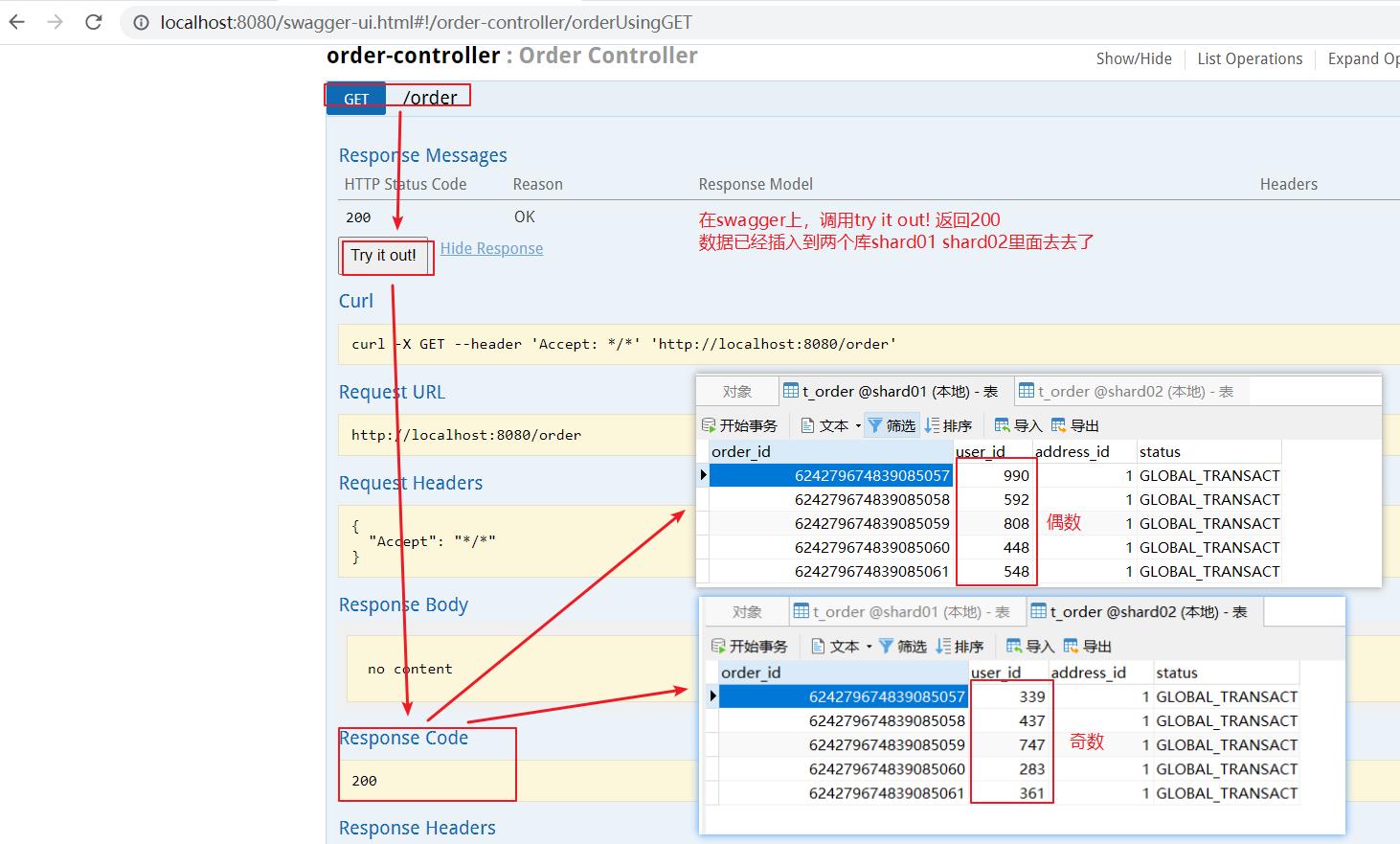
正常运行:
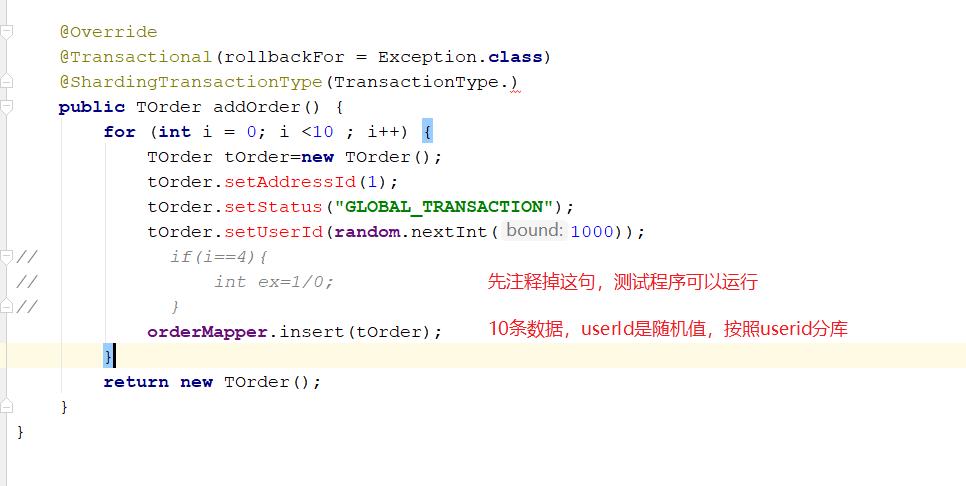
启动,并在 http://localhost:8080/swagger-ui.html 发送请求
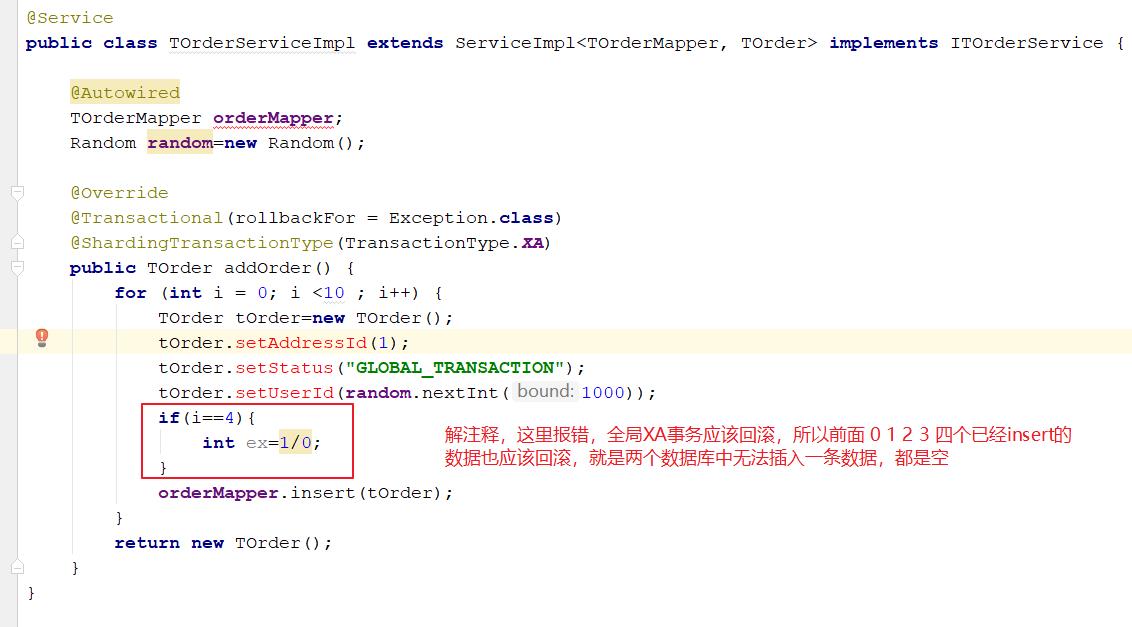
修改程序
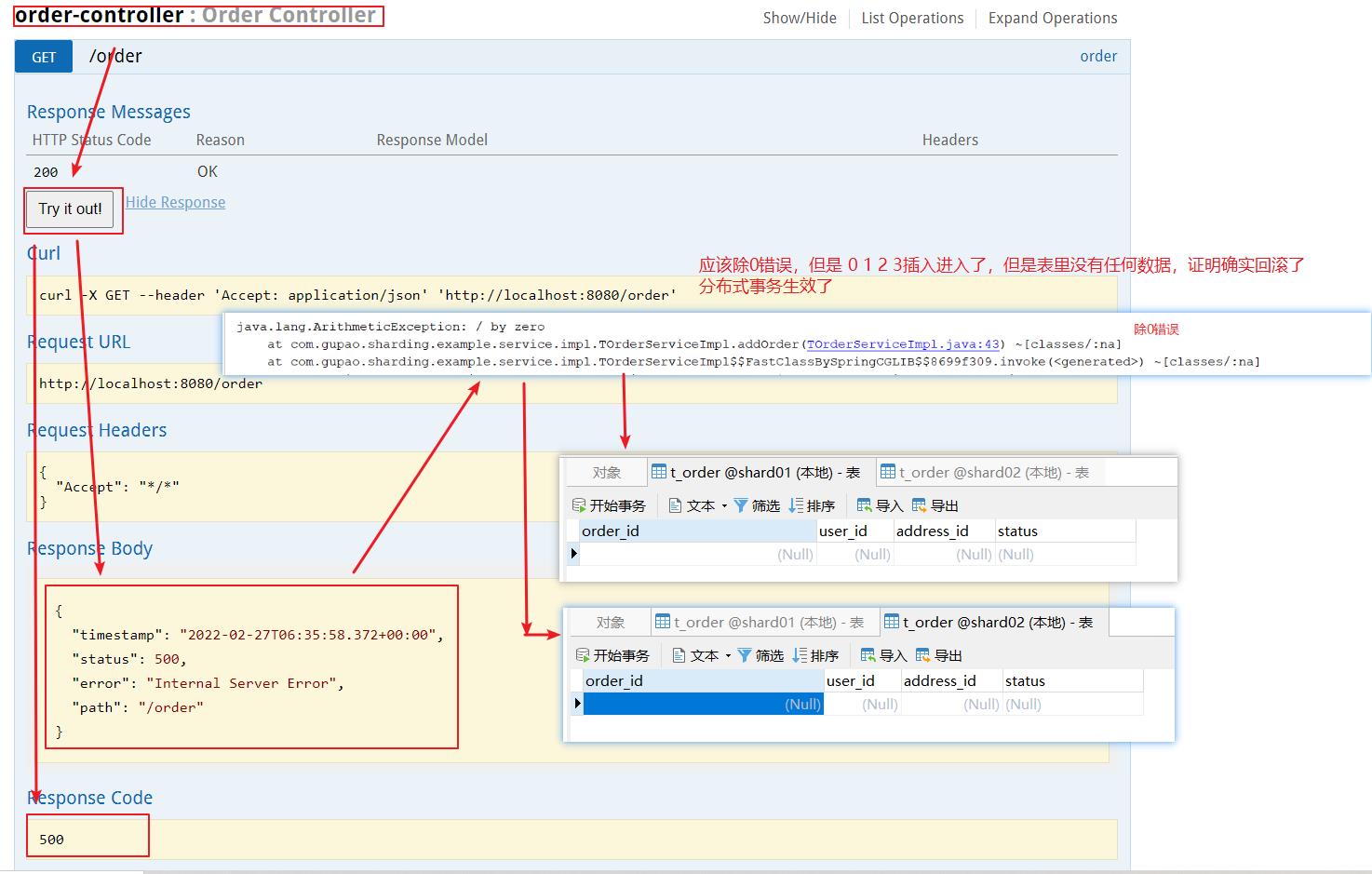
重新启动,swagger发送请求
四、尾声
本文主要介绍了ShardingJDBC读写分离与分布式事务,本文代码如下:
springboot集成shardingJDBC实现读写分离工程源码
springboot集成shardingJDBC实现分布式事务工程源码
天天打码,天天进步!!
以上是关于ShardingJDBC第二篇:读写分离与分布式事务的主要内容,如果未能解决你的问题,请参考以下文章