多标签文本分类SGM: Sequence Generation Model for Multi-Label Classification
Posted 征途黯然.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了多标签文本分类SGM: Sequence Generation Model for Multi-Label Classification相关的知识,希望对你有一定的参考价值。
·阅读摘要:
本文提出基于SGM模型,在Seq2Seq的基础上提出SGM模型应用于多标签文本分类。论文还提出了很多提升模型表现的细节,这是在Seq2Seq中没有的。
·参考文献:
[1] SGM: Sequence Generation Model for Multi-Label Classification
[2] Seq2Seq模型讲解,参考博客:【多标签文本分类】代码详解Seq2Seq模型
本文的亮点有很多:
1、对训练集的标签处理:高频标签放在前面,进而更好地指导整个标签的输出。此外,bos和eos符号分别添加到标签序列的头部和尾部;
2、SGM模型结构:编码器+注意力机制+解码器;
3、解码器预测生成词时,使用Masked Softmax防止重复预测;
4、上一步的生成词转为词向量,放入下一步的解码器时,采用Global Embedding全局嵌入;
5、选择生成出来的序列时,采用beam search波束搜索算法找出预测路径;
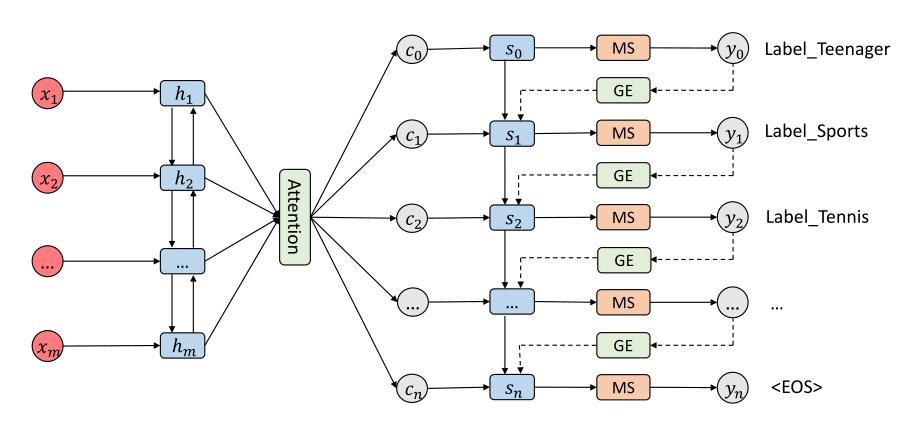
[1] SGM模型图
如下图,是论文中给的模型:
我给模型图加了一些注释,如下图:
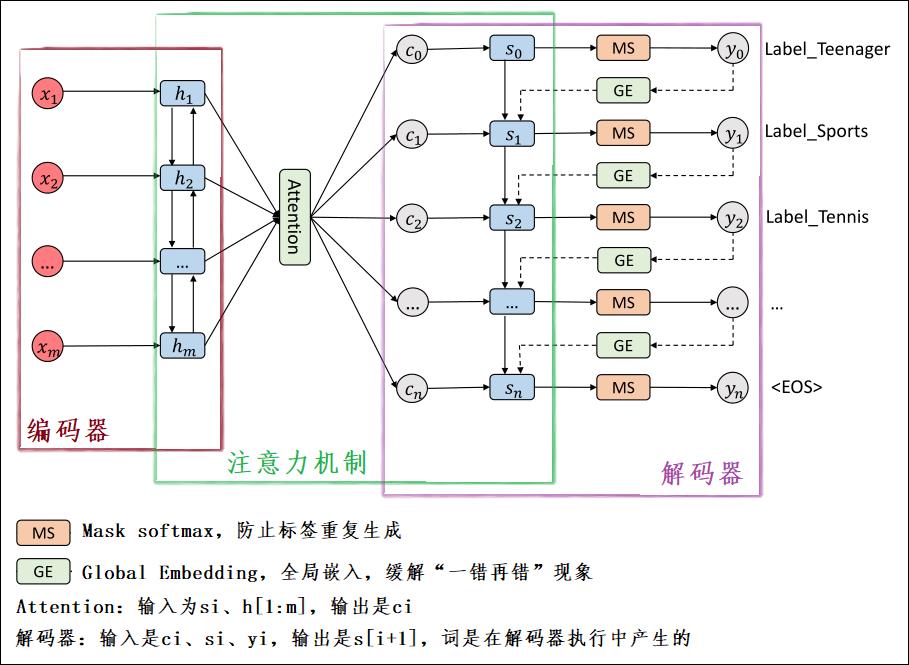
【注一】:模型介绍将以帮助理解为主,关于公式推导,可以参考论文原文
首先,模型架构可以分成3个部分:编码器、注意力机制、解码器。
1、编码器(Encoder):很简单,就是一个双向LSTM,输出是每一步的 H H H,即 h i h_i hi。
2、注意力机制(Attention):此层的目的是,在当前 s i s_i si下,挖掘 h 0 h_0 h0到 h m h_m hm中与 s i s_i si关系比较突出的向量表示,即 c i c_i ci。所以,此层的输入为 s i s_i si、 h [ 0 : m ] h[0:m] h[0:m],输出是 c i c_i ci。
【注二】: c i c_i ci将作为与 y i y_i yi同等地位的数据,两者拼接,作为解码器的输入。
3、解码器(Decoder):基础架构也是双向LSTM。但是在Seq2Seq模型中解码器的输入为(
s
i
,
y
i
s_i,y_i
si,yi),但是本文模型的解码器输入为(
s
i
,
[
c
i
,
g
(
y
i
)
]
s_i,[c_i,g(y_i)]
si,[ci,g(yi)]),
[
c
i
,
g
(
y
i
)
]
[c_i,g(y_i)]
[ci,g(yi)]表示是
c
i
c_i
ci、
g
(
y
i
)
g(y_i)
g(yi)两者的拼接,
g
(
y
i
)
g(y_i)
g(yi)中的函数
g
(
)
g()
g()就是上文提到的Global Embedding思想。除此之外,为了防止生成同样的标签,在解码器预测标签时,还使用了Masked Softmax思想。
【注三】:
Global Embedding、Masked Softmax会在下文阐述。
[2] 细节阐述
1、Masked Softmax解决多标签分类的输出重复问题。
解决方法: 作者在最终
s
o
f
t
m
a
x
softmax
softmax输出的时候引入了
I
t
I_t
It将已输出的标签剔除。
y
t
=
s
o
f
t
m
a
x
(
o
t
+
I
t
)
y_t = softmax(o_t + I_t)
yt=softmax(ot+It)
I
t
I_t
It的表示如下,如果标签已经被输出了,则
I
t
I_t
It为负无穷:

2、 Seq2Seq 中某时刻t 的输出对时刻t+1的输出影响很大,也就是说时刻t出错会对时刻 t+1之后的所有输出造成严重影响。论文称为exposure bias问题。
解决方法: 在多标签分类问题中,我们显然不想让标签间拥有如此强的关联性,于是作者提出 Global Embedding来解决这个问题。
3、beam search波束搜索算法找出预测路径,优化路径搜索算法。
g ( y i ) g(y_i) g(yi)是 label 的 embedding,这个 label 是在 y i y_i yi分布下的最高概率所对应标签得来的。可是,这个计算只是贪心的利用了 y i y_i yi的最大值。在论文提出的 SGM 模型中,基于先前预测的标签来产生下一个标签。因此,如果在第t-1时刻得到了错误的预测,然后就会在预测下一个标签的时候得到了一个错误的后继标签,这也叫做 exposure bias (错上加错)。这也是为什么采用贪心法在 decoder 部分不合适的地方,这个道理不仅适用于这篇论文的任务,对于机器翻译、自动摘要等任务,仍然适用。
所以,便有了 beam search 算法的产生。beam search 算法从一定程度上缓解了这个问题,有兴趣的可以自行去搜索下 beam search 算法的原理,但是它仍然不能从根本上解决这个问题,因为 exposure bias 可能会出现在所有的路径上。
4、提升模型小技巧
考虑到出现次数更多的标签在标签相关性训练中具有更强的作用,在训练时把标签按照其出现次数进行从高到低排序作为输出序列。这么做的好处是,出现次数更多的标签可以出现 LSTM 的前面,进而更好地指导整个标签的输出。
以上是关于多标签文本分类SGM: Sequence Generation Model for Multi-Label Classification的主要内容,如果未能解决你的问题,请参考以下文章