从零实现深度学习框架——过拟合与欠拟合
Posted 愤怒的可乐
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从零实现深度学习框架——过拟合与欠拟合相关的知识,希望对你有一定的参考价值。
引言
本着“凡我不能创造的,我就不能理解”的思想,本系列文章会基于纯Python以及NumPy从零创建自己的深度学习框架,该框架类似PyTorch能实现自动求导。
要深入理解深度学习,从零开始创建的经验非常重要,从自己可以理解的角度出发,尽量不使用外部完备的框架前提下,实现我们想要的模型。本系列文章的宗旨就是通过这样的过程,让大家切实掌握深度学习底层实现,而不是仅做一个调包侠。
本文主要介绍机器学习中常见的过拟合和欠拟合的概念,最后用一个实例展示过拟合的现象。
拆分数据集
我们在前面已经了解了机器学习简单流程:
- 使用大量相关数据集训练模型
- 通过模型在数据集上的误差迭代训练模型,得到在数据集上拟合较好的模型
- 最后可能会将模型应用到真实场景中
该数据集有一些为训练而收集的样本组成,称为训练数据集(training dataset),或称为训练集(train set)。然后在训练数据上表现良好的模型,并不一定在新数据集上有同样的效果,这里的新数据集通常称为测试数据集(test dataset),或称为测试集(test set),测试集由随机选取的、未曾在训练集中出现的数据样本构成。
这样,训练集用于拟合模型参数,测试集用于评估拟合的模型,所谓的拟合是指模型对于测试集的适应效果怎么样。
机器学习的主要挑战是我们的模型必须能在之前未观测的新样本上表现良好,而不只是在训练集上表现良好。在之前未观测到的样本上表现良好的能力称为泛化(generalization)。
当我们训练机器学习模型时,我们可以使用某个训练集,在训练数集上计算得到的误差,称为训练误差(training error),学习的目标是降低训练误差。机器学习也希望泛化误差(generalization error,也被称为测试误差(test error)) 很低。泛化误差被定义为新输入样本的误差期望,期望的计算基于不同的可能输入,这些输入来自于模型在现实中遇到的分布。
问题是,我们永远不能准确地计算出泛化误差,因为真实环境具有无限多的数据样本。实际上,我们只能通过将模型应用于一个独立的测试集(test set) 来估计泛化误差。
我们在训练集上训练模型,然后在测试集上测试模型,用测试集上的误差假设为模型对真实场景中的泛化误差。因此,我们只需要让训练好的模型在测试集上误差最小即可。
这是比较常见的做法,但如果可以的话,我们还可以拆分出一个验证集(dev set,开发集)。
由于在训练的时候,模型不能“看”到测试集的数据,我们不能直接根据测试集来调整模型,因此我们可以在训练集上训练好后,然后在验证集上测试不同的思路(比如超参数、权重初始化方法等),从中选择一个,然后不断迭代去改善验证集上的表现,最后得到满意的模型,再去测试集上评估。
模型在验证集上的误差就是验证误差(validation error)。
但是在具体拆分数据集时,有一些要注意的事项,最重要的是验证集应该和测试集保持同一分布。
还有有了一批数据后,具体要如何拆分呢?
按照吴恩达老师的说法,数据量较少的时候,比如在十万级别以内的,可以用60%的数据作为训练集,20%的数据作为验证集,剩下20%的数据最为测试集;或者说你不想要验证集,那么建议70%的数据作为训练集,剩下30%的数据都作为测试集。
当数据量较大的时候,比如百万级以上,那么训练集/验证集/测试集按照98%/1%/1%的比例分就可以了。
用了这些数据集的概念后,我们就可以来了解过拟合和欠拟合问题了。
过拟合和欠拟合
我们说,训练集用于拟合模型参数,测试集用于评估拟合的模型。当一个模型在训练集上表现良好,但不能推广到测试集时(在测试集上拟合不好),我们说这个模型是过拟合(overfitting) 的。如果训练出来的模型表现不好(误差高),甚至在训练集上都表现不好,我们说这个模型是欠拟合(underfitting) 的。
通常我们可以通过比较训练误差和验证误差来判断模型训练的效果:
- 欠拟合 - 验证和训练误差都很高
- 过拟合 - 验证误差高,训练误差低
- 正常拟合 - 验证误差低,可以稍高于训练误差
最终,我们更关心验证误差,而不是训练误差和验证误差之间的差距。
是否过拟合或欠拟合可能取决于模型复杂性和可用训练集的大小。
有时没有拆分验证集,我们可以比较训练误差和测试误差。
模型复杂性
我们看一个经典的多项式例子。给定由单个特征
x
x
x和对应实数标签
y
y
y组成的训练数据,我们试图找到下面的
d
d
d阶多项式来估计标签
y
y
y:
y
^
=
∑
i
=
0
d
w
i
x
i
(1)
\\hat y = \\sum_i=0^d w_i x^i \\tag 1
y^=i=0∑dwixi(1)
这是一个线性回归问题,特征是
x
x
x的幂,权重是
w
i
w_i
wi,偏置是
w
0
w_0
w0(我们令
x
0
=
1
x^0=1
x0=1),由于是一个线性问题,我们可以使用均方误差作为损失函数。
高阶多项式函数比低阶多项式函数复杂得多。高阶多项式的参数较多,模型函数的选择范围较广。因此在训练集不变的情况下,高阶多项式通常比低阶多项式的训练误差更低。当数据样本包含了 x x x的不同值时,函数阶数等于数据样本数量的多项式函数可以完美拟合训练集。在下图中,我们直观地描述了多项式的阶数和欠拟合与过拟合之间的关系:
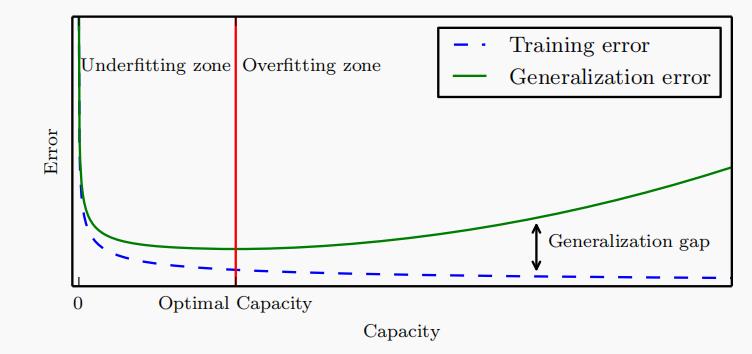
上图来自深度学习花书,横轴描述的是容量,我们可以理解为模型复杂度,纵轴表示误差。最佳复杂度在上图红线指向的位置。在红线左边属于欠拟合,红线右边属于过拟合。比较直观的就是,红线右边的泛化误差和训练误差的差距越来越大。
数据集大小
训练数据集中的样本越少,我们就越有可能过拟合。随着训练数据量的增加,泛化误差通常会减少。不管怎样,更多的数据不会有什么坏处,但是要注意训练数据集的数据分布和真实数据的分布问题。
通过实例理解过拟合与欠拟合
本例改自DIVE INTO DEEP LEARNING
本节我们通过多项式回归这个例子来理解过拟合与欠拟合。
给定
x
x
x,我们使用以下三阶多项式来生成训练和测试数据的标签:
y
=
5
+
1.2
x
−
3.4
x
2
2
!
+
5.6
x
3
3
!
+
ϵ
where
ϵ
∼
N
(
0
,
0.
1
2
)
(2)
y = 5 + 1.2x - 3.4\\fracx^22! + 5.6 \\fracx^33! + \\epsilon \\text where \\epsilon \\sim \\mathcalN(0, 0.1^2) \\tag 2
y=5+1.2x−3.42!x2+5.63!x3+ϵ where ϵ∼N(0,0.12)(2)
即真实多项式的最大阶数为3,最后的
ϵ
\\epsilon
ϵ是噪声项,服从均值为0标准差为0.1的正态分布。同时为了避免非常大的梯度,我们将特征从
x
i
x^i
xi调整为
x
i
i
!
\\fracx^ii!
i!xi,然后我们为训练集和测试集各生成100个样本:
import math
import numpy as np
max_degree = 30 # 多项式的最大阶数
n_train, n_test = 100, 100 # 训练和测试数据集大小
true_w = np.zeros(max_degree) # 分配大量的空间
# 真实w只有前4位有效
true_w[0:4] = np.array([5, 1.2, -3.4, 5.6])
features = np.random.normal(size=(n_train + n_test, 1))
np.random.shuffle(features)
# 多项式特征
poly_features = np.power(features, np.arange(max_degree).reshape(1, -1))
for i in range(max_degree):
poly_features[:, i] /= math.gamma(i + 1) # gamma(n)=(n-1)!
# labels的维度:(n_train+n_test,)
labels = np.dot(poly_features, true_w)
# 增加均值为0标准差为0.1正态分布的噪声项
labels += np.random.normal(scale=0.1, size=labels.shape)
然后我们从生成的数据集中看一下前2个样本:
print(f"features[:2]\\n poly_features[:2, :]\\n labels[:2]\\n")
[[-0.1746]
[ 0.0502]]
[[ 1. -0.1746 0.0152 -0.0009 0. -0. 0. -0. 0.
-0. 0. -0. 0. -0. 0. -0. 0. -0.
0. -0. 0. -0. 0. -0. 0. -0. 0.
-0. 0. -0. ]
[ 1. 0.0502 0.0013 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. ]]
[4.8674 4.8666]
然后我们定义训练函数:
def train(train_features, test_features, train_labels, test_labels, num_epochs=400):
loss = MSELoss(reduction=None)
input_shape = train_features.shape[-1]
# 不设置偏置,因为我们已经在多项式中实现了它
model = nn.Linear(input_shape, 1, bias=False)
batch_size = min(10, train_labels.shape[0])
opt = SGD(model.parameters(), lr=0.01)
animator = Animator(xlabel='epoch', ylabel='loss', yscale='log',
xlim=[1, num_epochs], ylim=[1e-3, 1e2],
legend=['train', 'test'])
train_labels, test_labels = train_labels.reshape(-1, 1), test_labels.reshape(-1, 1)
for epoch in range(num_epochs):
train_loss, _ = run_epoch(model, train_features, train_labels, loss, opt, batch_size)
if epoch == 0 or (epoch + 1) % 20 == 0:
with no_grad():
test_loss, _ = run_epoch(model, test_features, test_labels, loss, opt=None,
batch_size=batch_size)
animator.add(epoch + 1, (train_loss, test_loss))
plt.show()
print('weight:', model.weight.numpy())
该函数会进行多项式模型的训练,同时画出训练误差和验证误差,最后打印出模型训练得到的权重。
正常拟合
我们先看一下正常拟合,让它与生成数据的阶数相同相同,即三阶多项式,包含偏置。
# 从多项式特征中选择前4个维度,即1,x,x^2/2!,x^3/3!
train(poly_features[:n_train, :4], poly_features[n_train:, :4], labels[:n_train], labels[n_train:])
weight: [[ 5.0008 1.1922 -3.3991 5.6071]]
可以看到损失由100降低到了0.01级别,能有效降低训练损失和测试损失,学习到的模型参数也接近于真实 w = [ 5 , 1.2 , − 3.4 , 5.6 ] w=[5, 1.2, -3.4, 5.6] w=[5,1.2,−3.4,5.6]。
终于会画动图了😝 ,相关代码请参考源码
欠拟合
我们再看看没有多项式的线性函数拟合。
# 从多项式特征中选择前2个维度,即1和x
train(poly_features[:n_train, :2], poly_features[n_train:,:2],labels[:n_train], labels[n_train:])
weight: [[2.5748 4.6183]]

此时减少模型的训练损失很困难。在最后一个迭代完成后,训练损失仍然很高。
过拟合
我们尝试使用一个阶数过高的多项式来训练模型。
train(poly_features[:n_train, :], poly_features[n_train:, :],
labels[:n_train], labels[n_train:], num_epochs=1500)
weight: [[ 4.9733 1.239 -3.3014 5.4526 -0.3969 0.336 0.7446 0.0222 0.4165
-0.2525 -0.0321 0.1681 -0.1694 0.1181 0.0084 0.1117 -0.0924 0.0733
0.0274 0.2889 0.0242 -0.1679 0.1407 -0.3078 0.1213 0.1865 0.0977
-0.2631 0.0658 0.0718]]

此时,这个过于复杂的模型会受到训练数据中噪声的影响。虽然训练损失可以有效地降低,但测试损失仍然很高。结果表示,复杂模型对数据造成了过拟合。
References
- 吴恩达深度学习
- DIVE INTO DEEP LEARNING
- 深度学习花书
以上是关于从零实现深度学习框架——过拟合与欠拟合的主要内容,如果未能解决你的问题,请参考以下文章