我懵了,那个听起来很厉害的微内核架构是个什么鬼?
Posted 飘渺Jam
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了我懵了,那个听起来很厉害的微内核架构是个什么鬼?相关的知识,希望对你有一定的参考价值。
大家好,我是飘渺!
咱们经常在一些中间件架构设计中听到 “微内核架构“ 这个词,不知道各位第一次听到这个词是什么感觉,反正我是一脸懵逼,两脸茫然。
那究竟什么是 “微内核架构” ,我们又应该如何实现它?今天让我们揭开微内核架构的神秘面纱!
什么是微内核架构?
微内核是一种典型的架构模式 ,区别于普通的设计模式,架构模式是一种高层模式,用于描述系统级的结构组成、相互关系及相关约束。微内核架构在开源框架中的应用非常广泛,比如常见的 ShardingSphere 还有Dubbo都实现了自己的微内核架构。那么,在介绍什么是微内核架构之前,我们有必要先阐述这些开源框架会使用微内核架构的原因。
为什么要使用微内核架构?
微内核架构本质上是为了提高系统的扩展性 。所谓扩展性,是指系统在经历不可避免的变更时所具有的灵活性,以及针对提供这样的灵活性所需要付出的成本间的平衡能力。也就是说,当在往系统中添加新业务时,不需要改变原有的各个组件,只需把新业务封闭在一个新的组件中就能完成整体业务的升级,我们认为这样的系统具有较好的可扩展性。
就架构设计而言,扩展性是软件设计的永恒话题。而要实现系统扩展性,一种思路是提供可插拔式的机制来应对所发生的变化。当系统中现有的某个组件不满足要求时,我们可以实现一个新的组件来替换它,而整个过程对于系统的运行而言应该是无感知的,我们也可以根据需要随时完成这种新旧组件的替换。
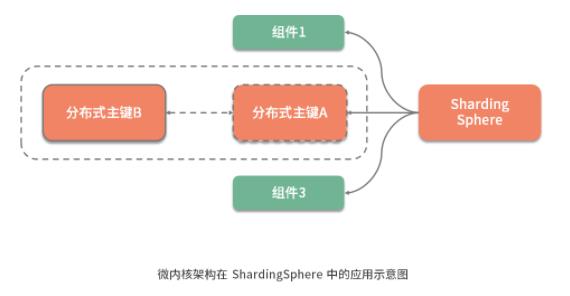
比如在 ShardingSphere 中提供的分布式主键功能,分布式主键的实现可能有很多种,而扩展性在这个点上的体现就是, 我们可以使用任意一种新的分布式主键实现来替换原有的实现,而不需要依赖分布式主键的业务代码做任何的改变 。
微内核架构模式为这种实现扩展性的思路提供了架构设计上的支持,ShardingSphere 基于微内核架构实现了高度的扩展性。在介绍如何实现微内核架构之前,我们先对微内核架构的具体组成结构和基本原理做简要的阐述。
什么是微内核架构?
从组成结构上讲, 微内核架构包含两部分组件:内核系统和插件 。这里的内核系统通常提供系统运行所需的最小功能集,而插件是独立的组件,包含自定义的各种业务代码,用来向内核系统增强或扩展额外的业务能力。在 ShardingSphere 中,前面提到的分布式主键就是插件,而 ShardingSphere 的运行时环境构成了内核系统。
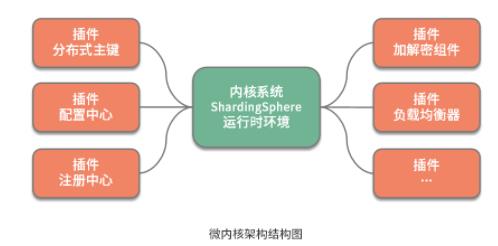
那么这里的插件具体指的是什么呢?这就需要我们明确两个概念,一个概念就是经常在说的 API ,这是系统对外暴露的接口。而另一个概念就是 SPI(Service Provider Interface,服务提供接口),这是插件自身所具备的扩展点。就两者的关系而言,API 面向业务开发人员,而 SPI 面向框架开发人员,两者共同构成了 ShardingSphere 本身。
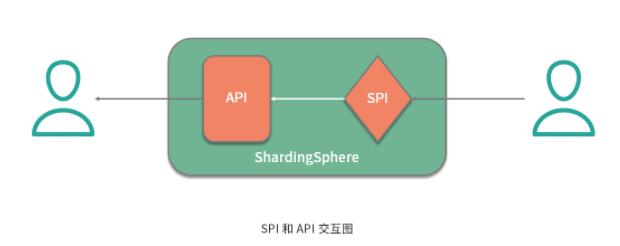
可插拔式的实现机制说起来简单,做起来却不容易,我们需要考虑两方面内容。一方面,我们需要梳理系统的变化并把它们抽象成多个 SPI 扩展点。另一方面, 当我们实现了这些 SPI 扩展点之后,就需要构建一个能够支持这种可插拔机制的具体实现,从而提供一种 SPI 运行时环境 。
如何实现微内核架构?
事实上,JDK 已经为我们提供了一种微内核架构的实现方式,就是JDK SPI。这种实现方式针对如何设计和实现 SPI 提出了一些开发和配置上的规范,ShardingSphere、Dubbo 使用的就是这种规范,只不过在这基础上进行了增强和优化。所以要理解如何实现微内核架构,我们不妨先看看JDK SPI 的工作原理。
JDK SPI
SPI(Service Provider Interface)主要是被框架开发人员使用的一种技术。例如,使用 Java 语言访问数据库时我们会使用到 java.sql.Driver 接口,不同数据库产品底层的协议不同,提供的 java.sql.Driver 实现也不同,在开发 java.sql.Driver 接口时,开发人员并不清楚用户最终会使用哪个数据库,在这种情况下就可以使用 Java SPI 机制在实际运行过程中,为 java.sql.Driver 接口寻找具体的实现。
下面我们通过一个简单的示例演示一下JDK SPI的使用方式:
首先我们定义一个生成id键的接口,用来模拟id生成
public interface IdGenerator
/**
* 生成id
* @return
*/
String generateId();
然后创建两个接口实现类,分别用来模拟uuid和序列id的生成
public class UuidGenerator implements IdGenerator
@Override
public String generateId()
return UUID.randomUUID().toString();
public class SequenceIdGenerator implements IdGenerator
private final AtomicLong atomicId = new AtomicLong(100L);
@Override
public String generateId()
long leastId = this.atomicId.incrementAndGet();
return String.valueOf(leastId);
在项目的
resources/META-INF/services目录下添加一个名为com.github.jianzh5.spi.IdGenerator的文件,这是 JDK SPI 需要读取的配置文件,内容如下:
com.github.jianzh5.spi.impl.UuidGenerator
com.github.jianzh5.spi.impl.SequenceIdGenerator创建main方法,让其加载上述的配置文件,创建全部IdGenerator 接口实现的实例,并执行生成id的方法。
public class GeneratorMain
public static void main(String[] args)
ServiceLoader<IdGenerator> serviceLoader = ServiceLoader.load(IdGenerator.class);
Iterator<IdGenerator> iterator = serviceLoader.iterator();
while(iterator.hasNext())
IdGenerator generator = iterator.next();
String id = generator.generateId();
System.out.println(generator.getClass().getName() + " >>id:" + id);
执行结果如下:

JDK SPI 源码分析
通过上述示例,我们可以看到 JDK SPI 的入口方法是 ServiceLoader.load() 方法,在这个方法中首先会尝试获取当前使用的 ClassLoader,然后调用 reload() 方法,调用关系如下图所示:

public void reload()
providers.clear();
lookupIterator = new LazyIterator(service, loader);
在前面的示例中,main() 方法中使用的迭代器底层就是调用了 ServiceLoader.LazyIterator 实现的。Iterator 接口有两个关键方法:hasNext() 方法和 next() 方法。这里的 LazyIterator 中的 next() 方法最终调用的是其 nextService() 方法,hasNext() 方法最终调用的是 hasNextService() 方法,我们来看看 hasNextService()方法的具体实现:
private static final String PREFIX = "META-INF/services/";
Enumeration<URL> configs = null;
Iterator<String> pending = null;
String nextName = null;
private boolean hasNextService()
if (nextName != null)
return true;
if (configs == null)
try
//META-INF/services/com.github.jianzh5.spi.IdGenerator
String fullName = PREFIX + service.getName();
if (loader == null)
configs = ClassLoader.getSystemResources(fullName);
else
configs = loader.getResources(fullName);
catch (IOException x)
fail(service, "Error locating configuration files", x);
// 按行SPI遍历配置文件的内容
while ((pending == null) || !pending.hasNext())
if (!configs.hasMoreElements())
return false;
// 解析配置文件
pending = parse(service, configs.nextElement());
// 更新 nextName字段
nextName = pending.next();
return true;
在 hasNextService() 方法中完成 SPI 配置文件的解析之后,再来看 LazyIterator.nextService() 方法,该方法负责实例化 hasNextService() 方法读取到的实现类,其中会将实例化的对象放到 providers 集合中缓存起来,核心实现如下所示:
private S nextService()
String cn = nextName;
nextName = null;
// 加载 nextName字段指定的类
Class<?> c = Class.forName(cn, false, loader);
if (!service.isAssignableFrom(c)) // 检测类型
fail(service, "Provider " + cn + " not a subtype");
S p = service.cast(c.newInstance()); // 创建实现类的对象
providers.put(cn, p); // 将实现类名称以及相应实例对象添加到缓存
return p;
以上就是在 main() 方法中使用的迭代器的底层实现。最后,我们再来看一下 main() 方法中使用 ServiceLoader.iterator() 方法拿到的迭代器是如何实现的,这个迭代器是依赖 LazyIterator 实现的一个匿名内部类,核心实现如下:
public Iterator<S> iterator()
return new Iterator<S>()
// knownProviders用来迭代providers缓存
Iterator<Map.Entry<String,S>> knownProviders
= providers.entrySet().iterator();
public boolean hasNext()
// 先走查询缓存,缓存查询失败,再通过LazyIterator加载
if (knownProviders.hasNext())
return true;
return lookupIterator.hasNext();
public S next()
// 先走查询缓存,缓存查询失败,再通过 LazyIterator加载
if (knownProviders.hasNext())
return knownProviders.next().getValue();
return lookupIterator.next();
// 省略remove()方法
;
JDK SPI 在 JDBC 中的应用
了解了 JDK SPI 实现的原理之后,我们再来看实践中 JDBC 是如何使用 JDK SPI 机制加载不同数据库厂商的实现类。
JDK 中只定义了一个 java.sql.Driver 接口,具体的实现是由不同数据库厂商来提供的。这里我们就以 mysql 提供的 JDBC 实现包为例进行分析。
在 mysql-connector-java-*.jar 包中的 META-INF/services 目录下,有一个 java.sql.Driver 文件中只有一行内容,如下所示:
com.mysql.cj.jdbc.Driver在使用 mysql-connector-java-*.jar 包连接 MySQL 数据库的时候,我们会用到如下语句创建数据库连接:
String url = "jdbc:xxx://xxx:xxx/xxx";
Connection conn = DriverManager.getConnection(url, username, pwd);DriverManager 是 JDK 提供的数据库驱动管理器,其中的代码片段,如下所示:
static
loadInitialDrivers();
println("JDBC DriverManager initialized");
在调用 getConnection() 方法的时候,DriverManager 类会被 Java 虚拟机加载、解析并触发 static 代码块的执行;在 loadInitialDrivers()方法中通过 JDK SPI 扫描 Classpath 下 java.sql.Driver 接口实现类并实例化,核心实现如下所示:
private static void loadInitialDrivers()
String drivers = System.getProperty("jdbc.drivers")
// 使用 JDK SPI机制加载所有 java.sql.Driver实现类
ServiceLoader<Driver> loadedDrivers =
ServiceLoader.load(Driver.class);
Iterator<Driver> driversIterator = loadedDrivers.iterator();
while(driversIterator.hasNext())
driversIterator.next();
String[] driversList = drivers.split(":");
for (String aDriver : driversList) // 初始化Driver实现类
Class.forName(aDriver, true,
ClassLoader.getSystemClassLoader());
在 MySQL 提供的 com.mysql.cj.jdbc.Driver 实现类中,同样有一段 static 静态代码块,这段代码会创建一个 com.mysql.cj.jdbc.Driver 对象并注册到 DriverManager.registeredDrivers 集合中(CopyOnWriteArrayList 类型),如下所示:
static
java.sql.DriverManager.registerDriver(new Driver());
在 getConnection() 方法中,DriverManager 从该 registeredDrivers 集合中获取对应的 Driver 对象创建 Connection,核心实现如下所示:
private static Connection getConnection(String url, java.util.Properties info, Class<?> caller) throws SQLException
// 省略 try/catch代码块以及权限处理逻辑
for(DriverInfo aDriver : registeredDrivers)
Connection con = aDriver.driver.connect(url, info);
return con;
小结
本文我们详细讲述了微内核架构的一些基本概念并通过一个示例入手,介绍了 JDK 提供的 SPI 机制的基本使用,然后深入分析了 JDK SPI 的核心原理和底层实现,对其源码进行了深入剖析,最后我们以 MySQL 提供的 JDBC 实现为例,分析了 JDK SPI 在实践中的使用方式。
新开了一个纯技术交流群,群里氛围还不错,无广告,无套路,单纯的吹牛逼,侃人生,想进的可以通过下方二维码加我微信,备注进群。


SpringBoot中如何实现全链路调用日志跟踪?这种方法才叫优雅!




以上是关于我懵了,那个听起来很厉害的微内核架构是个什么鬼?的主要内容,如果未能解决你的问题,请参考以下文章