基础扫盲篇--强化学习自动股票交易算法
Posted mishidemudong
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基础扫盲篇--强化学习自动股票交易算法相关的知识,希望对你有一定的参考价值。
用算法自动交易股票?今天给大家分享最近学习的一篇ICAIF 2020会议论文,《Deep Reinforcement Learning for Automated Stock Trading: An Ensemble Strategy》——深度强化学习在股票自动交易中的应用。
背景
想象你现在手上有一笔钱要拿来炒股,怎样能在坎坷的股市里获利或者换句话说怎样让钱生钱?思考这个问题之前,先来看看我们是怎么玩超级玛丽的吧。“简单啊,先这样再这样最后就赢啦!”,别急先来个分解动作吧:
1. 我们的眼睛观察到了游戏界面:包括了马里奥的位置、障碍物的位置等等
2. 这个图像信息传送到我们的大脑,然后我们进行决策:在“上下左右等”可能的操作里面挑选一个方案
3. 然后用手实现这个操作,之后游戏界面刷新,我们看到了马里奥继续前进或者得了一个金币或者不小心掉进了坑里
4. 通过环境的反馈,我们调整了策略,如果是负向的反馈,我们下次可能就会尽量避免第2步时错误的决策,如果是正向的反馈,我们可能会继续沿用之前的策略等等,然后继续第1步直到游戏结束。
总结一下,玩超级玛丽这个过程有两个主体,一个是超级玛丽这个游戏本身,我们称之为环境,二是玩家。环境具备变化的状态,玩家可以在环境下进行操作,同时会得到奖励。最终目的在于玩家要在这个环境下拿到尽量多的奖励。
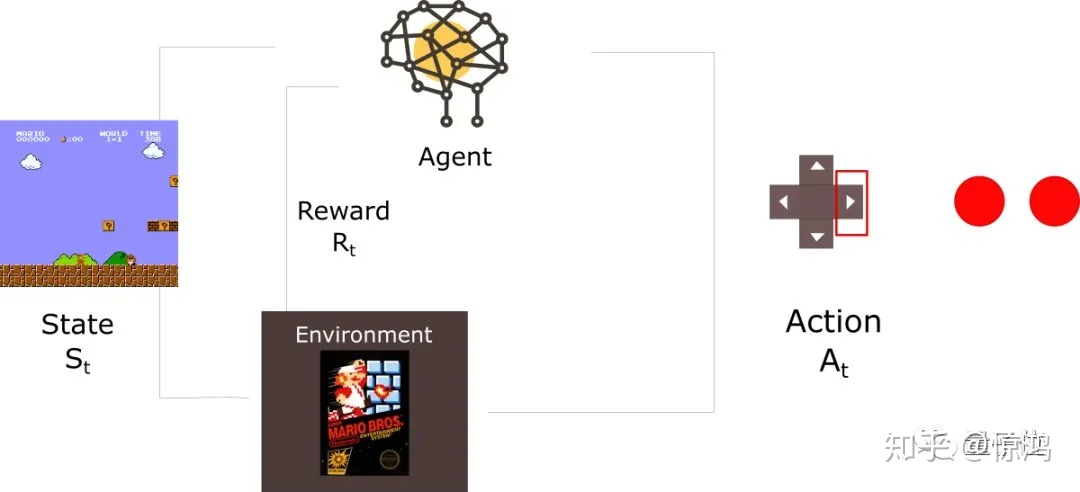
图片来自知乎-量子位
再回想一下,是不是像极了炒股,我们是股市这个”游戏“里的一个玩(jiu)家(cai),玩家可以在股市里操作,同时会得到收益(可正可负),我们的最终目的是尽量赚到更多的钱。
正好,强化学习就是为解决这一类”博弈“问题而生的,目前已经在很多领域得到了应用,比如自动驾驶、左右互博下围棋的alpha zero、王者荣耀的超强AI”绝悟“、推荐系统等等。那么今天我们就来看看强化学习在炒股领域的尝试吧!
基本思路
1. 首先是炒股的基本操作”买“、”卖“和”不买不卖“,但是还不够清晰,我们买卖什么?一方面我们有一系列的股票组合,比如这篇论文用到的是Dow Jones 30的30支股票,另一方面我们要在这些股票上面选择买和卖具体股的数目。
2. 其次是炒股的”环境“的状态,直观来讲就是随时间变化的股票的价格(股价),但是还不够全面,因为股票是存在于市场中的,说到底市场才是”环境“,通常我们会具体化为所谓的”技术面、信息面、基本面“,正确的决策往往需要全面而非片面的信息,但是为了简化起见,这篇论文用到除了股价之外的指标例如MACD、RSI、CCI、ADX等。
3. 然后是我们最关心的收益,同时也是算法要最大化的目标。单次操作带来的收益定义为(操作后的余额+操作后的股量*操作后的股价 之和)- (操作前的余额+操作前的股量*操作前的股价 之和)- (本次操作支付的交易费)。当然,我们的收益要定义为一系列收益的和,这样才是一个相对长期的目标,换句话说单次操作带来的收益只是一个短期效应,但是我们更希望关注长期效应:

以上公式就是数学定义,s是状态,a是操作,r是单次操作带来的收益,γ是一个衰减因子,衰减因子作用在未来的收益,因为我们关心这次操作带来的长远的影响,而这次带来的影响往往会逐渐衰弱。当然,这个只是一个数学的简化描述,也可以有其他形式。
4. 最后是玩家,这个玩家就用到强化学习了,就像是游戏里面的人机,算法通过与环境的交互,实现自身策略的进化,这篇论文用到了三个经典的强化学习算法,A2C、DDPG、PPO以及他们的集成策略,具体算法定义不在这里展开讲,有兴趣的话可以看最下方的参考链接。
5. 细节,考虑到实际可能出现的各种复杂因素,这篇论文给出了一些假设,比如假设改算法基本不会对股市造成影响、假设你的口袋里的钱不会赔的底朝天等;以及给出了特殊情况下,例如根据指标判断是否要崩盘,如果是,那么停止买入并且卖出所有股票。具体细节可以参考论文原文。
算法效果

图片来自论文
数据用到的是2009年1月1号至2020年8月5号的DJ30的30支股票,其中2009年1月1号至2015年10月1号用于训练,然后看2016年1月1号往后的效果。论文从多个角度评估了算法的效果,例如投资回报率、崩盘下的效果等,如下是累计回报率具体的曲线:

图片来自论文
可以看到PPO方法曲线回报率曲线最好,论文也提到了该方法的累计回报率达到了83%!
以上是关于基础扫盲篇--强化学习自动股票交易算法的主要内容,如果未能解决你的问题,请参考以下文章