python调用IE浏览器进行数据批量下载小技巧
Posted 空中旋转篮球
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python调用IE浏览器进行数据批量下载小技巧相关的知识,希望对你有一定的参考价值。
一、为什么要使用浏览器下载?
使用场景:已经有了大量的数据下载链接信息,这些保存在txt文本中,每一行是一个完整的下载链接地址,很多人首先就会想到,直接使用迅雷批量下载就好了,确实如此,这也是最简单的办法。然而问题在于需要下载的这些资源需要代理网络才能下载,迅雷不能直接顺利下载下来。迅雷软件其实也提供了代理设置,如下图:

然而设置代理的时候都不能生效,依旧不能正常下载资源,因此,考虑使用python调用浏览器进行数据下载,前提是所使用的浏览器能够正常使用代理,从而顺利下载资源。
有同学也会说使用python做脚本下载,使用脚本批量下载,当然也是可以的,但是会复杂一些。
二、python调用浏览器打开资源自动下载
使用浏览器是IE浏览器
代码如下:
import os
import time
#from selenium import webdriver #导入selenium包
f=open("C:/Users/RS/Desktop/数据下载链接.txt","r") #txt文件中每一行是完整的下载链接地址
line=f.readline()
def sleeptime(hour,min,sec):
return hour*3600 + min*60 + sec
second=sleeptime(0,15,59) #这是根据文件下载完成的平均之间设置较好
while line:
print(line)
command1 = '"C:\\Program Files\\Internet Explorer\\iexplore.exe" %s' % line #启动IE浏览器 IE11.0
#driver = webdriver.Firefox()#初始化浏览器实例driver,默认浏览器安装位置,若自定义浏览器安装位置,可定制
#driver.get(line) #报错Unable to find a matching set of capabilities
#driver.quit() #注释部分是调用火狐浏览器,之前试过失败了,有点问题!
os.system(command1)
time.sleep(second)
line=f.readline()
f.close代码总体比较简单,运行之后会打开浏览器进行下载,记得将浏览器下载地址提前配置好,并且取消弹出选择路径窗口。
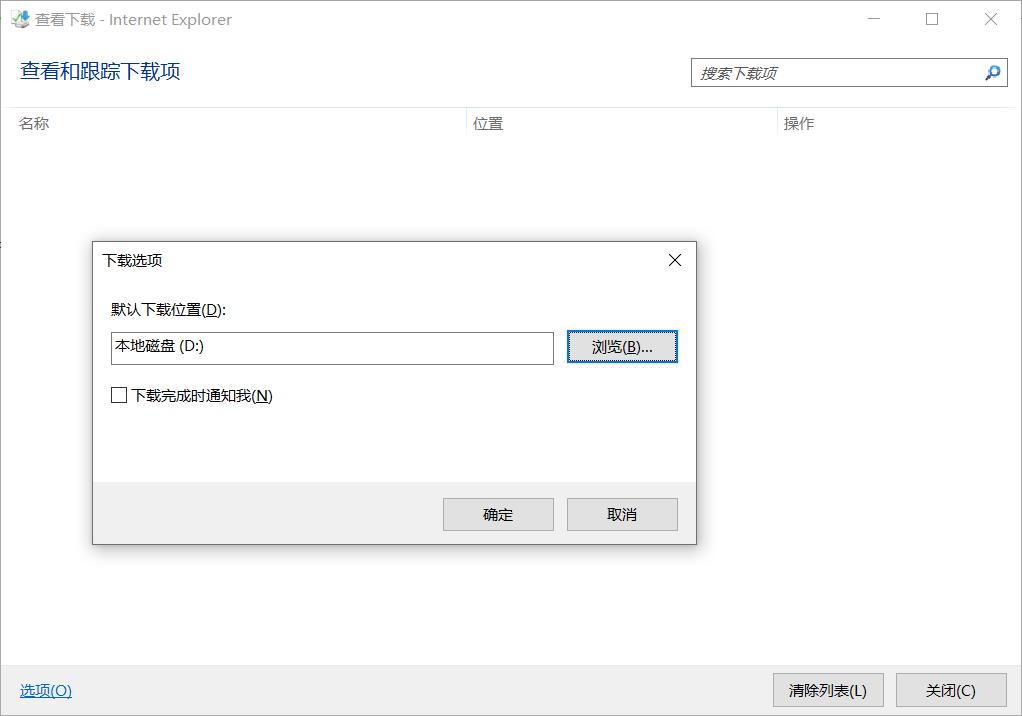
需要注意的几个地方:
1.下载间隔时间不能过短,不然一下次多次链接下载资源会被服务器临时拒绝访问。
2.打开浏览器下载后,浏览器下载查看窗口中有一个保存按钮,可以直接点击,也可以后面一次性点击,记得点击保存(实际上数据已经在后台下载缓存下来了,刚弹出来就点击可以看到下载进度)为了实现批量下载,实际上只要过一段时间一次性点击保存一下就行了。
3.IE浏览器不支持断点续传,资源数据比较大的情况容易中断,就会比较麻烦了,火狐浏览器支持断点续传。
以上是关于python调用IE浏览器进行数据批量下载小技巧的主要内容,如果未能解决你的问题,请参考以下文章