深度学习多框架多平台推理引擎工具
Posted 踟蹰横渡口,彳亍上滩舟。
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习多框架多平台推理引擎工具相关的知识,希望对你有一定的参考价值。
一种深度学习推理引擎工具,支持多框架、支持多平台推理
项目下载地址:下载地址
支持的计算平台:
- Windows 10 (Visual Studio 2019 x64)
- Linux (x64, armv7, aarch64)
- android (armeabi-v7a, arm64-v8a)
支持的模型框架:
- TensorFlow Lite
- TensorFlow Lite with delegate (XNNPACK, GPU, EdgeTPU, NNAPI)
- TensorRT (GPU, DLA)
- OpenCV(dnn)
- OpenCV(dnn) with GPU
- OpenVINO with OpenCV (xml+bin)
- ncnn
- ncnn with Vulkan
- MNN (with Vulkan)
- SNPE (Snapdragon Neural Processing Engine SDK (Qualcomm Neural Processing SDK for AI v1.51.0))
- Arm NN
- NNabla
- NNabla with CUDA
下载相关库:
Download prebuilt libraries
- sh third_party/download_prebuilt_libraries.sh
配置编译参数:
-
Deep learning framework:
- You can enable multiple options althoguh the following example enables just one option
# OpenCV (dnn), OpenVINO cmake .. -DINFERENCE_HELPER_ENABLE_OPENCV=on # Tensorflow Lite cmake .. -DINFERENCE_HELPER_ENABLE_TFLITE=on # Tensorflow Lite (XNNPACK) cmake .. -DINFERENCE_HELPER_ENABLE_TFLITE_DELEGATE_XNNPACK=on # Tensorflow Lite (GPU) cmake .. -DINFERENCE_HELPER_ENABLE_TFLITE_DELEGATE_GPU=on # Tensorflow Lite (EdgeTPU) cmake .. -DINFERENCE_HELPER_ENABLE_TFLITE_DELEGATE_EDGETPU=on # Tensorflow Lite (NNAPI) cmake .. -DINFERENCE_HELPER_ENABLE_TFLITE_DELEGATE_NNAPI=on # TensorRT cmake .. -DINFERENCE_HELPER_ENABLE_TENSORRT=on # ncnn, ncnn + vulkan cmake .. -DINFERENCE_HELPER_ENABLE_NCNN=on # MNN (+ Vulkan) cmake .. -DINFERENCE_HELPER_ENABLE_MNN=on # SNPE cmake .. -DINFERENCE_HELPER_ENABLE_SNPE=on # Arm NN cmake .. -DINFERENCE_HELPER_ENABLE_ARMNN=on # NNabla cmake .. -DINFERENCE_HELPER_ENABLE_NNABLA=on # NNabla with CUDA cmake .. -DINFERENCE_HELPER_ENABLE_NNABLA_CUDA=on -
Enable/Disable preprocess using OpenCV:
- By disabling this option, InferenceHelper is not dependent on OpenCV
cmake .. -INFERENCE_HELPER_ENABLE_PRE_PROCESS_BY_OPENCV=off
APIs
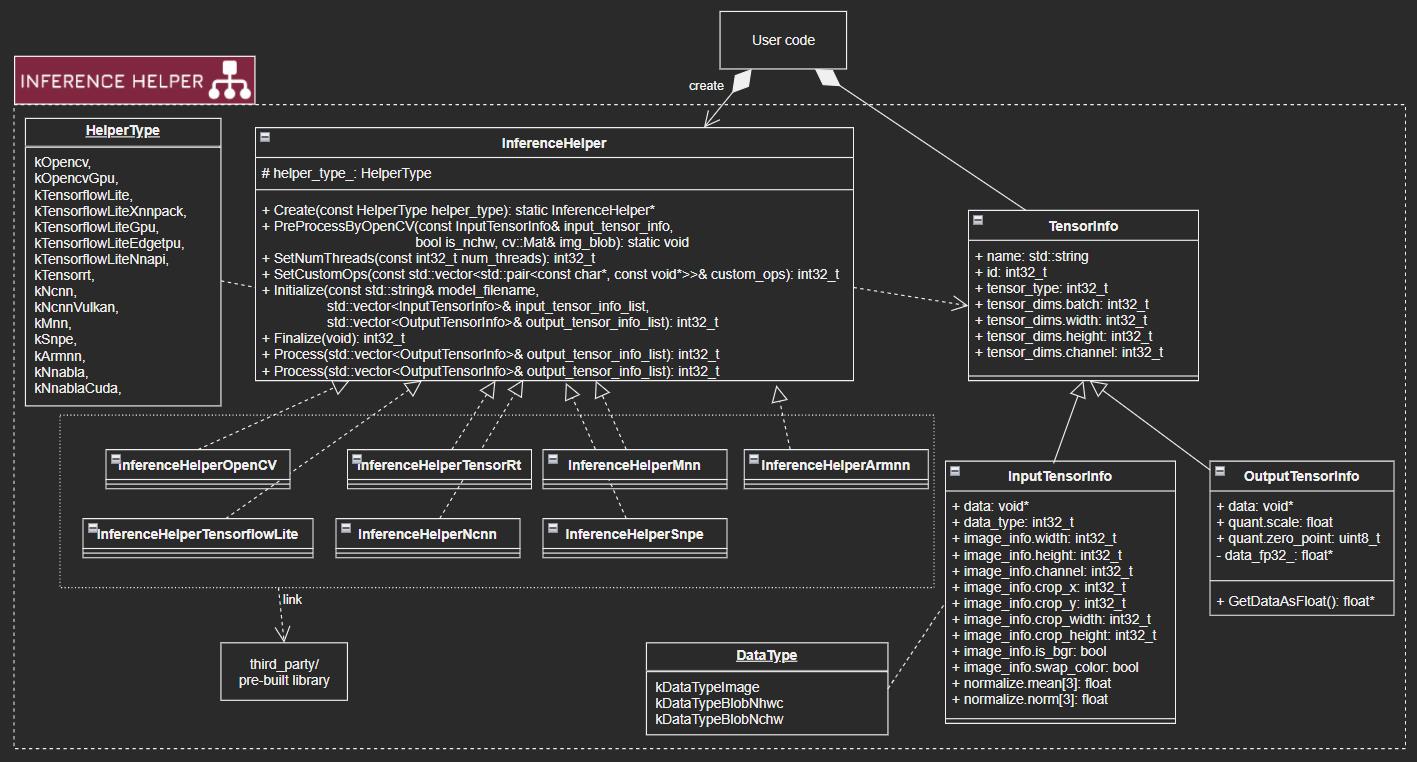
InferenceHelper
Enumeration
typedef enum
kOpencv,
kOpencvGpu,
kTensorflowLite,
kTensorflowLiteXnnpack,
kTensorflowLiteGpu,
kTensorflowLiteEdgetpu,
kTensorflowLiteNnapi,
kTensorrt,
kNcnn,
kNcnnVulkan,
kMnn,
kSnpe,
kArmnn,
kNnabla,
kNnablaCuda,
HelperType;
static InferenceHelper* Create(const HelperType helper_type)
- Create InferenceHelper instance for the selected framework
std::unique_ptr<InferenceHelper> inference_helper(InferenceHelper::Create(InferenceHelper::kTensorflowLite));
static void PreProcessByOpenCV(const InputTensorInfo& input_tensor_info, bool is_nchw, cv::Mat& img_blob)
- Run preprocess (convert image to blob(NCHW or NHWC))
- This is just a helper function. You may not use this function.
- Available when
INFERENCE_HELPER_ENABLE_PRE_PROCESS_BY_OPENCV=on
- Available when
InferenceHelper::PreProcessByOpenCV(input_tensor_info, false, img_blob);
int32_t SetNumThreads(const int32_t num_threads)
- Set the number of threads to be used
- This function needs to be called before initialize
inference_helper->SetNumThreads(4);
int32_t SetCustomOps(const std::vector<std::pair<const char*, const void*>>& custom_ops)
- Set custom ops
- This function needs to be called before initialize
std::vector<std::pair<const char*, const void*>> custom_ops;
custom_ops.push_back(std::pair<const char*, const void*>("Convolution2DTransposeBias", (const void*)mediapipe::tflite_operations::RegisterConvolution2DTransposeBias()));
inference_helper->SetCustomOps(custom_ops);
int32_t Initialize(const std::string& model_filename, std::vector& input_tensor_info_list, std::vector& output_tensor_info_list)
- Initialize inference helper
- Load model
- Set tensor information
std::vector<InputTensorInfo> input_tensor_list;
InputTensorInfo input_tensor_info("input", TensorInfo::TENSOR_TYPE_FP32, false); /* name, data_type, NCHW or NHWC */
input_tensor_info.tensor_dims = 1, 224, 224, 3 ;
input_tensor_info.data_type = InputTensorInfo::kDataTypeImage;
input_tensor_info.data = img_src.data;
input_tensor_info.image_info.width = img_src.cols;
input_tensor_info.image_info.height = img_src.rows;
input_tensor_info.image_info.channel = img_src.channels();
input_tensor_info.image_info.crop_x = 0;
input_tensor_info.image_info.crop_y = 0;
input_tensor_info.image_info.crop_width = img_src.cols;
input_tensor_info.image_info.crop_height = img_src.rows;
input_tensor_info.image_info.is_bgr = false;
input_tensor_info.image_info.swap_color = false;
input_tensor_info.normalize.mean[0] = 0.485f; /* https://github.com/onnx/models/tree/master/vision/classification/mobilenet#preprocessing */
input_tensor_info.normalize.mean[1] = 0.456f;
input_tensor_info.normalize.mean[2] = 0.406f;
input_tensor_info.normalize.norm[0] = 0.229f;
input_tensor_info.normalize.norm[1] = 0.224f;
input_tensor_info.normalize.norm[2] = 0.225f;
input_tensor_list.push_back(input_tensor_info);
std::vector<OutputTensorInfo> output_tensor_list;
output_tensor_list.push_back(OutputTensorInfo("MobilenetV2/Predictions/Reshape_1", TensorInfo::TENSOR_TYPE_FP32));
inference_helper->initialize("mobilenet_v2_1.0_224.tflite", input_tensor_list, output_tensor_list);
int32_t Finalize(void)
- Finalize inference helper
inference_helper->Finalize();
int32_t PreProcess(const std::vector& input_tensor_info_list)
- Run preprocess
- Call this function before invoke
- Call this function even if the input data is already pre-processed in order to copy data to memory
- Note : Some frameworks don’t support crop, resize. So, it’s better to resize image before calling preProcess.
inference_helper->PreProcess(input_tensor_list);
int32_t Process(std::vector& output_tensor_info_list)
- Run inference
inference_helper->Process(output_tensor_info_list)
TensorInfo (InputTensorInfo, OutputTensorInfo)
Enumeration
enum
kTensorTypeNone,
kTensorTypeUint8,
kTensorTypeInt8,
kTensorTypeFp32,
kTensorTypeInt32,
kTensorTypeInt64,
;
Properties
std::string name; // [In] Set the name_ of tensor
int32_t id; // [Out] Do not modify (Used in InferenceHelper)
int32_t tensor_type; // [In] The type of tensor (e.g. kTensorTypeFp32)
std::vector<int32_t> tensor_dims; // InputTensorInfo: [In] The dimentions of tensor. (If empty at initialize, the size is updated from model info.)
// OutputTensorInfo: [Out] The dimentions of tensor is set from model information
bool is_nchw; // [IN] NCHW or NHWC
InputTensorInfo
Enumeration
enum
kDataTypeImage,
kDataTypeBlobNhwc, // data_ which already finished preprocess(color conversion, resize, normalize_, etc.)
kDataTypeBlobNchw,
;
Properties
void* data; // [In] Set the pointer to image/blob
int32_t data_type; // [In] Set the type of data_ (e.g. kDataTypeImage)
struct
int32_t width;
int32_t height;
int32_t channel;
int32_t crop_x;
int32_t crop_y;
int32_t crop_width;
int32_t crop_height;
bool is_bgr; // used when channel == 3 (true: BGR, false: RGB)
bool swap_color;
image_info; // [In] used when data_type_ == kDataTypeImage
struct
float mean[3];
float norm[3];
normalize; // [In] used when data_type_ == kDataTypeImage
OutputTensorInfo
Properties
void* data; // [Out] Pointer to the output data_
struct
float scale;
uint8_t zero_point;
quant; // [Out] Parameters for dequantization (convert uint8 to float)
float* GetDataAsFloat()
- Get output data in the form of FP32
- When tensor type is INT8 (quantized), the data is converted to FP32 (dequantized)
const float* val_float = output_tensor_list[0].GetDataAsFloat();
推理库引用:
- tensorflow
- https://github.com/tensorflow/tensorflow
- Copyright 2019 The TensorFlow Authors
- Licensed under the Apache License, Version 2.0
- Modification: no
- Pre-built binary file is generated from this project
- libedgetpu
- https://github.com/google-coral/libedgetpu
- Copyright 2019 Google LLC
- Licensed under the Apache License, Version 2.0
- Modification: yes
- Pre-built binary file is generated from this project
- TensorRT
- https://github.com/nvidia/TensorRT
- Copyright 2020 NVIDIA Corporation
- Licensed under the Apache License, Version 2.0
- Modification: yes
- Some code are retrieved from this repository
- ncnn
- https://github.com/Tencent/ncnn
- Copyright (C) 2017 THL A29 Limited, a Tencent company. All rights reserved.
- Licensed under the BSD 3-Clause License
- https://github.com/Tencent/ncnn/blob/master/LICENSE.txt
- Modification: no
- Pre-built binary file is generated from this project
- MNN
- https://github.com/alibaba/MNN
- Copyright (C) 2018 Alibaba Group Holding Limited
- Licensed under the Apache License, Version 2.0
- Modification: no
- Pre-built binary file is generated from this project
- SNPE
- https://developer.qualcomm.com/software/qualcomm-neural-processing-sdk
- Copyright (c) 2017-2020 Qualcomm Technologies, Inc.
- Arm NN
- https://github.com/Arm-software/armnn
- Copyright (c) 2017 ARM Limited.
- NNabla
- https://github.com/sony/nnabla
- https://github.com/sony/nnabla-ext-cuda
- Copyright 2018,2019,2020,2021 Sony Corporation.
- Licensed under the Apache License, Version 2.0```
以上是关于深度学习多框架多平台推理引擎工具的主要内容,如果未能解决你的问题,请参考以下文章