英文文本分类实战之四——词典提取与词向量提取
Posted 征途黯然.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了英文文本分类实战之四——词典提取与词向量提取相关的知识,希望对你有一定的参考价值。
·请参考本系列目录:【英文文本分类实战】之一——实战项目总览
·下载本实战项目资源:神经网络实现英文文本分类.zip(pytorch)
[1] 提取词典
在这一步,我们需要把训练集train.csv、验证集dev.csv中的英文文本先清洗,然后分词,最后构建出词典,转存为pkl格式文件。
【注】:“清洗”可参见博客 【英文文本分类实战】之三——数据清洗。
1、为什么要提取词典,转存为pkl文件?
——运行神经网络模型需要用到词典,每构建一次词典,需要读取训练集train.csv、验证集dev.csv,当数据集较大时时间上难以接受,转存一次,之后直接读取就行。
2、什么是pkl文件?
——pkl文件是需要导入pickle库才能读取/保存的。pkl文件是一种保存数据的格式,与npz文件差不多,只需要会读取/保存操作就可以,比较简单。
3、怎么构建词典?
——我们在“【英文文本分类实战】之三——数据清洗”中提取出来所有的词典后,我们可以取前N个频率最高的词,放入词典。也可以使用机器学习中,CHI、TF-IDF等的概念为标准,来选取放入词典中的词。
【注】:TF-IDF是词频-逆文档频率,按这个标准选取出来的词,相当部分的词在数据集中出现占比不高,这就导致用词向量表示文本能力变差,会不会降低模型的准确率?(我没实验,网上应当有结论,我这仅仅是猜想。)
4、如果一个文本中的词不在构建的词典中,如何处理?
——假设一个文本为I love NLP,而构建的词典为I:0,love:1,我们通常会先在词典中加两个词<pad>和<unk>。其中<pad>表示当文本长度不够的补齐词,<unk>表示不在文本中的词。
——这样,词典变为I:0,love:1,<pad>:2,<unk>:3,当pad_len=3时,文本被表示成I love <unk> = [0,1,3];当pad_len=5时,文本被表示成I love <unk> <pad> <pad> = [0,1,3,2,2]。
代码如下:
# ## 进度条初始化
tqdm.pandas()
MAX_VOCAB_SIZE = 7000 # 词表长度限制
UNK, PAD = '<UNK>', '<PAD>' # 未知字,padding符号
def build_vocab(file_path, max_size, min_freq):
df = pd.read_csv(file_path, encoding='utf-8', sep=';')
# 转化为小写
sentences = df['content'].apply(lambda x: x.lower())
# 去除特殊字符
punct = "/-'?!.,#$%\\'()*+-/:;<=>@[\\\\]^_`|~" + '""“”’' + '∞θ÷α•à−β∅³π‘₹´°£€\\×™√²—–&'
punct_mapping = "‘": "'", "₹": "e", "´": "'", "°": "", "€": "e", "™": "tm", "√": " sqrt ", "×": "x", "²": "2",
"—": "-", "–": "-", "’": "'", "_": "-", "`": "'", '“': '"', '”': '"', '“': '"', "£": "e",
'∞': 'infinity', 'θ': 'theta', '÷': '/', 'α': 'alpha', '•': '.', 'à': 'a', '−': '-', 'β': 'beta',
'∅': '', '³': '3', 'π': 'pi',
sentences = sentences.apply(lambda x: clean_special_chars(x, punct, punct_mapping))
# 提取数组
sentences = sentences.progress_apply(lambda x: x.split()).values
vocab_dic =
for sentence in tqdm(sentences, disable=False):
for word in sentence:
try:
vocab_dic[word] += 1
except KeyError:
vocab_dic[word] = 1
vocab_list = sorted([_ for _ in vocab_dic.items() if _[1] >= min_freq], key=lambda x: x[1], reverse=True)[:max_size]
vocab_dic = word_count[0]: idx for idx, word_count in enumerate(vocab_list)
vocab_dic.update(UNK: len(vocab_dic), PAD: len(vocab_dic) + 1)
return vocab_dic
def build_dataset(config):
if os.path.exists(config.vocab_path):
vocab = pkl.load(open(config.vocab_path, 'rb'))
else:
vocab = build_vocab(config.train_path, max_size=MAX_VOCAB_SIZE, min_freq=1)
pkl.dump(vocab, open(config.vocab_path, 'wb'))
print(f"词典======== vocab")
if __name__ == "__main__":
class Config():
def __init__(self):
self.vocab_path = '../@_数据集/TLND/data/vocab.pkl'
self.train_path = '../@_数据集/TLND/data/train.csv'
self.dev_path = '../@_数据集/TLND/data/dev.csv'
self.test_path = '../@_数据集/TLND/data/test.csv'
self.pad_size = 14
build_dataset(Config())
代码只取了前7000个高频词,运行之后,会在指定位置生成vocab.pkl文件,我们随机打印vocab.pkl文件中的数据,如下:
'Insulated': 3, 'Mergers': 9, 'Acquisitions': 9
【注】:代码会默认在最后加上
<pad>和<unk>两个词。设置了MAX_VOCAB_SIZE = 7000后,其实词典长度为7002。
[2] 提取词向量
仔细观察之前下载预训练词向量的网站,如下图。图如提及每种词向量的词典大小为400k、1.9m、2.2m、1.2m。

而我们构建的词典大小只有7002,要怎么处理呢。
对于预训练词向量中,不包含的构建的词典中的词,我们直接弃之不要。只从预训练词向量找出,构建的词典中的词对应的词向量,按照构建的词典中的词的顺序一一存到一个数组里,最终会变成一个二维数组,然后使用numpy保存为npz文件。
【注】:这里的二维数组应当转为numpy数组格式再保存。
对于<pad>、<unk>以及从预训练词向量中找不到的词,可以赋值为零向量,或者随机初始化。这样,我们就从预训练词向量中提取出了我们需要的词向量,不必每次都加载大则上GB的预训练词向量文件。
代码如下:
# ## 加载预训练词向量
def load_embed(file):
def get_coefs(word, *arr):
return word, np.asarray(arr, dtype='float32')
if file == '../@_词向量/fasttext/wiki-news-300d-1M.vec':
embeddings_index = dict(get_coefs(*o.split(" ")) for o in open(file, encoding='utf-8') if len(o) > 100)
else:
embeddings_index = dict(get_coefs(*o.split(" ")) for o in open(file, encoding='latin'))
return embeddings_index
ebed = []
def get_embed(vocab_path, embed_path,dim):
vocab = pkl.load(open(vocab_path, 'rb'))
embed_glove = load_embed(embed_path)
for v in vocab:
if v not in embed_glove.keys():
ebed.append(np.asarray([0 for i in range(0,dim)], dtype='float32'))
else:
ebed.append(embed_glove[v])
return np.asarray(ebed, dtype='float32')
vocab_path = '../@_数据集/TLND/data/vocab.pkl'
embed_path = '../@_词向量/glove/glove.6B.300d.txt'
dim = 300
np.savez('../@_数据集/TLND/data/glove.6B.300d.npz',embeddings=get_embed(vocab_path, embed_path, dim))
运行之后,我们就能得到提取后的glove.6B.300d.npz文件。其中存储的数据格式为:
"embeddings":[
[……],
[……],
[……],
……
# 总共有n个dim维的向量,与vocab词典中的n个词一一对应
]
[3] 提取标签
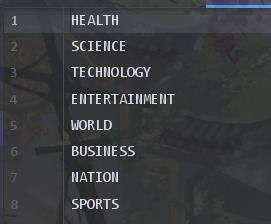
最后,我们提取数据集的标签,存放在class.txt中。很简单,对所有标签取个set()之类的,效果如图:
[4] 大功告成
最后,一切准备工作皆以就绪。我们来总结一下现有的文件:

· class.txt是提取出来的无重复标签,一个一行,顺序不限;
· train.csv、dev.csv、test.csv是分割好的数据集;
· labelled_newscatcher_dataset.csv是初始数据集,已经用不到了;
· vocab.pkl存放的是从数据集中提取的词典;
· glove.6B.50d、glove.6B.300d是提取的预训练词向量,对应50维、300维。
【注】:这里的文件位置不限,放在哪都可以,注意使用的时候写好路径即可。
大功告成!可以正式开始写pytorh的代码了!
[5] 进行下一篇实战
以上是关于英文文本分类实战之四——词典提取与词向量提取的主要内容,如果未能解决你的问题,请参考以下文章